 以百度Apollo平臺為例 揭開自動駕駛算法的神秘面紗
以百度Apollo平臺為例 揭開自動駕駛算法的神秘面紗
自動駕駛是人工智能當前最熱門的方向之一,也是未來將對人類生活會產生重大影響的方向。機器學習在自動駕駛中有舉足輕重的地位,從環境感知到策略控制,都有它的身影。在本文中,SIGAI以百度阿波羅平臺為例,介紹機器學習在自動駕駛系統中的應用,揭開自動駕駛算法的神秘面紗。
自動駕駛簡介
自動駕駛的目標是讓交通工具能夠自主行駛,典型的是飛行器和車輛,這是人類長期以來追求的目標。飛機的自動駕駛在多年前已經實現,空中的障礙物、交通情況比地面簡單很多,而且有雷達等手段精確定位。現階段的重點是車輛的自動駕駛,目前,Google、百度、特斯拉等公司都投入大量資源在這個領域進行研發,也取得了一些重要進展。
目前的自動駕駛系統由攝像機,激光雷達等傳感器,控制器,GPS定位系統,數字地圖,算法等多個部件構成,在這里我們重點介紹算法部分,尤其是機器學習技術在其中的應用情況。
無人駕駛為什么需要機器學習?
很多人可能不理解為什么自動駕駛需要機器學習技術,讓我們首先來看人是怎么駕駛車輛的。現在要開車從清華大學東門去北京首都機場T3航站樓,你作為司機要完成這一次駕駛任務。接下來你會怎么做?
首先,你要知道本次行駛的起始地和目的地。如果是老司機,你會知道按照什么樣的路線開到機場去;如果不是,則需要借助導航軟件,它將為你計算出一條最優的行駛路徑。下面是搜狗地圖為我們計算出來的路徑:
這里涉及到定位,路徑規劃的問題。前者可以通過GPS或其他技術手段來實現,后者也有成熟的算法,如Dijkstra或者A*搜索算法,學過數據結構和算法的同學對Dijkstra算法都不會陌生,它給出了計算圖的兩個節點之間最短距離的方案。目前,這一問題已經很好的解決了,而且計算機比人要強。
接下來,你就要啟動汽車開始行駛了。首先你要知道的是:路在什么地方?應該上哪個車道?
這就是機器學習登場的時候了,它要解決路面和車道線檢測問題。目前主流的自動駕駛系統一般都采用了激光雷達+攝像機+其他傳感器相結合的方案。無論是激光雷達掃描得到的3D距離數據,還是攝像機成像的2D數據,我們都要對它們進行分析,以準確的確定路面的位置,車道線和每個車道的范圍。
在找到了道路和車道之后,我們就要開始行駛了,你要控制油門,剎車,方向盤。現在問題又來了,怎么開?
你得知道路上有沒有車,有沒有人,有多少車,有多少人,以及其他障礙物,它們在路面的什么地方。這又是機器學習和機器視覺要解決的問題,同樣是檢測問題。我們需要對激光雷達或者攝像機的圖像進行分析,得到這些障礙物的準確位置。
行駛過程中,你遇到的這些行人,車輛都是移動的,因此你必須要對他們的運動趨勢做出預判。你前面的車輛、后面的車輛的行駛速度和軌跡都會影響你要采取的動作。如果有人要過馬路,距離你還有30米,你是停下來等他過去,還是慢速行駛過去?
這是機器視覺中的目標跟蹤問題,我們要準確的跟蹤出人,車輛,動物等移動目標的運動軌跡,估計出他們的運動速度與方向,以便于做出決策。
行駛一會兒之后,你遇到了第一個十字路口,這里有紅綠燈,當前是紅燈,因此你需要停下來等待,而不是硬闖過去,這又涉及到一個問題,你怎么知道這些交通燈?
這依然是機器視覺要解決的問題,即準確的檢測出圖像中的交通燈,并知道它們當前的狀態。除了紅綠燈之外,還有其他交通標志需要我們識別,比如速度限制、是否允許調頭等。
還有一個問題沒有解決,在知道這些環境參數之后,我們該怎么行駛?即根據環境參數得到要執行的動作,在這里是車輛行駛的速度(速度是一個矢量,具有大小和方向)。最簡單的做法是用規則來做決策,我們總結出人駕駛車輛的經驗,前面沒有車,后面沒有車的時候該怎么行駛;前面有2輛車,后面有3輛車的時候該怎么行駛.....。問題是:各種情況實在是太多了,我們無法窮舉出所有的情況。
對于這個問題的一個解決方案是深度強化學習,和AlphaGo類似的一種技術,這也是一種機器學習算法。它的思路是根據環境的參數預測出要執行的動作,我們用一些數據進行訓練,得到這樣一個模型,也就是人開車時的經驗,然后用它來做決策。但是這種方法有一個嚴重的問題,神經網絡的預測結果不具有可解釋性,有時候會出現莫名其妙的結果,這會嚴重影響安全性。關注過AlphaGo的同學都知道,在一次對戰中,它下出了一個完全無法理解的棋,對于自動駕駛來說,這可能是一個災難。
在列出了自動駕駛中所需要用機器學習解決的問題之后,接下來我們將以百度阿波羅平臺為例,看看這些問題是怎么解決的。
百度阿波羅平臺簡介
阿波羅(Apollo)是百度的無人駕駛開放平臺,和當年的阿波羅登月計劃同名,對于這一計劃,時任美國總統約翰肯尼迪有一句經典的名言:
我們選擇在這個10年登上月球并完成其他計劃,并不是因為它容易完成,而是因為它充滿挑戰,因為(登月)這一目標可以整合并檢驗我們最出色的能力和技能。
在2017年百度已經宣布阿波羅開源,目前有大量的廠商已經接該平臺進行合作。我們可以通過閱讀它的源代碼和文檔來了解其所采用的技術。
阿波羅的官網地址是:
http://apollo.auto/
源代碼,文檔與數據下載地址為:
https://github.com/apolloauto
在這里需要申明的是,SIGAI的作者與百度以及阿波羅平臺沒有任何商業和其他關系,我們純粹是站在技術和產品角度,以第三方的視角來分析他們的技術。
先看看阿波羅官方對目前狀態的整體介紹:
阿波羅2.5版本的目標是用低成本的傳感器實現自動駕駛。它能讓車輛保持在某一車道上,并與前面最近的車輛保持距離,這通過一個前視攝像頭,以及前視雷達來實現。對攝像頭圖像的分析采用了深度神經網絡,隨著樣本數據的累積,神經網絡的預測將越來越準。官方說明,目前不支持在高度彎曲,沒有車道線標志的道路上行駛。
首先來看它軟件部分的整體結構(下圖截取自阿波羅官網):
在這里,我們重點關注的是感知模塊,其他模塊以后有機會的話會寫文章分別介紹。
感知模塊
首先來看感知模塊,它為我們提供了類似人類眼睛所提供的視覺功能,即理解我們所處的駕駛環境。首先來看阿波羅官方對感知模塊的介紹(以下兩段話引用了他們的原文):
“Apollo 2.0感知模塊包括障礙物檢測識別和紅綠燈檢測識別兩部分。障礙物檢測識別模塊通過輸入激光雷達點云數據和毫米波雷達數據,輸出基于兩種傳感器的障礙物融合結果,包括障礙物的位置、形狀、類別、速度、朝向等信息。紅綠燈檢測識別模塊通過輸入兩種焦距下的相機圖像數據,輸出紅綠燈的位置、顏色狀態等信息。上述兩大感知功能,使無人車具備在簡單城市道路自動駕駛的能力,希望能夠對無人駕駛社區有幫助。如果對算法細節有興趣,請查閱github上的技術文檔。”
“通過安裝在車身的各類傳感器如激光雷達、攝像頭和毫米波雷達等獲取車輛周邊的環境數據。利用多傳感器融合技術,車端感知算法能夠實時計算出環境中交通參與者的位置、類別和速度朝向等信息。背后支持這套自動駕駛感知系統的是多年積累的大數據和深度學習技術,海量的真實路測數據經過專業人員的標注變成機器能夠理解的學習樣本,大規模深度學習平臺和GPU集群將離線學習大量數據所耗費的時間大幅縮短,訓練好的最新模型通過在線更新的方式從云端更新到車載大腦。人工智能+數據驅動的解決方案使百度無人車感知系統能夠持續不斷的提升檢測識別能力,為自動駕駛的決策規劃控制模塊提供準確、穩定、可靠的輸入。”
從這里可以看到,他們采用了攝像機,激光雷達,毫米波雷達等多種傳感器,用深度學習技術對這些傳感器采集的數據進行分析,以確定車輛當前所處環境中的交通參與者,這里的參與者是指人,車等重要目標。
整個感知模塊的結構如下圖所(該圖來自阿波羅在github上的公開文檔):
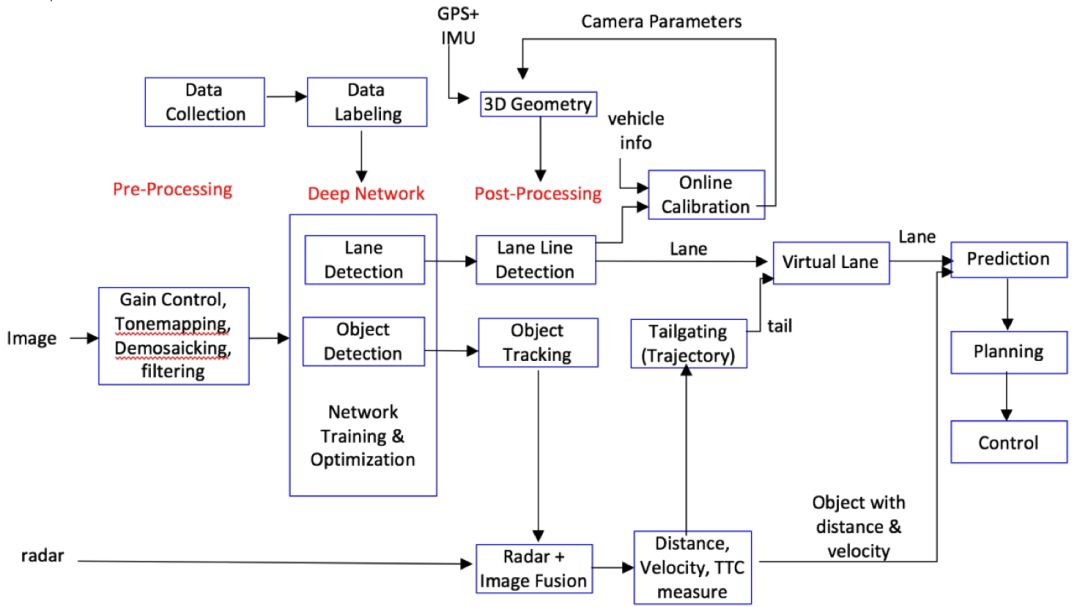
從上圖可以看出,核心的算法包括:
車道檢測
目標檢測
車道線檢測
目標跟蹤
軌跡管理
相機標定
預測算法
規劃算法
在這里我們重點介紹前面4個算法。
道路和車道線識別
車道線屬于靜態目標,不會移動。準確的確定車道線,不僅對車輛的縱向控制有用,還對橫向控制有用。車道線由一系列的線段集合來表示。首先,用卷積神經網絡對攝像機采集的圖像進行處理,預測出車道線的概率圖,即每一點處是車道線的概率。然后,對這種圖進行二值化,得到分割后的二值圖像。接下來計算二值圖像的聯通分量,檢測出所有的內輪廓,然后根據輪廓邊緣點得到車道的標志點。從他們的描述文檔看,核心的一步是用卷積神經網絡預測出圖像每一點是車道線的概率。
障礙物檢測識別
下面來看官方對障礙物 檢測模塊的描述:
“障礙物模塊包括基于激光雷達點云數據的障礙物檢測識別、基于毫米波雷達數據的障礙物檢測識別以及基于兩種傳感器的障礙物結果融合。基于激光雷達點云數據的障礙物檢測識別,通過線下訓練的卷積神經網絡模型,學習點云特征并預測障礙物的相關屬性(比如前景物體概率、相對于物體中心的偏移量、物體高度等),并根據這些屬性進行障礙物分割。基于毫米波雷達數據的障礙物檢測識別,主要用來對毫米波雷達原始數據進行處理而得到障礙物結果。該算法主要進行了ID擴展、噪點去除、檢測結果構建以及ROI過濾。多傳感器障礙物結果融合算法,用于將上述兩種傳感器的障礙物結果進行有效融合。該算法主要進行了單傳感器結果和融合結果的管理、匹配以及基于卡爾曼濾波的障礙物速度融合。具體算法請參閱github技術文檔。”
從這里可以看出,對障礙物的檢測與車道線檢測不同,這里采用的是基于激光雷達和毫米波雷達的數據。這是出于安全的考慮,如果采用攝像機,在惡劣天氣如雨雪,以及極端光照條件下,圖像將無法有效的分析,另外,激光雷達和毫米波雷達給出了物體準確的距離數據,這對安全的行駛至關重要,而單純靠圖像數據分析則很難做到。
接下來我們看他們對神經網絡實現方案的描述:
“Deep network ingests an image and provides two detection outputs, lane lines and objects for Apollo 2.5. There is an ongoing debate on individual task and co-trained task for deep learning. Individual networks such as a lane detection network or an object detection network usually perform better than one co-trained multi-task network. However, with given limited resources, multiple individual networks will be costly and consume more time in processing. Therefore, for the economic design, co-train is inevitable with some compromise in performance. In Apollo 2.5, YOLO [1][2] was used as a base network of object and lane detection. The object has vehicle, truck, cyclist, and pedestrian categories and represented by a 2-D bounding box with orientation information. The lane lines are detected by segmentation using the same network with some modification.”
這里他們考慮了兩種方案:車道線檢測和障礙物檢測使用同一個神經網絡,以及各自使用一個神經網絡。后者的準確率更高,但更耗費計算資源,而且處理時間可能會更長。最后選用的是第一種方案。具體的,采用了YOLO[1][2]作為基礎網絡來進行目標和車道檢測。目前區分的目標有汽車,自行車,行人。這些目標都用一個2D的矩形框表示,并且帶有朝向信息。車道線用同一個網絡的輸出得到,使用了圖像分割技術。在之前的SIGAI公眾號文章“基于深度學習的目標檢測算法綜述”中已經簡單介紹了YOLO和其他主要的算法,感興趣的讀者可以閱讀,如有需要。實現時,使用了Caffe。
阿波羅將目標分為兩種類型,靜態的和動態的,下面來看他們的描述:
“In a traffic scene, there are two kinds of objects: stationary objects and dynamic objects. Stationary objects include lane lines, traffic lights, and thousands of traffic signs written in different languages. Other than driving, there are multiple landmarks on the road mostly for visual localization including streetlamp, barrier, bridge on top of the road, or any skyline. For stationary object, we will detect only lane lines in Apollo 2.5.”
靜態的目標包括車道線,交通燈,其他各種寫有文字的交通標志。除此之外,路上還有一些標志可用于視覺定位,包括路燈,柵欄,天橋,地平線等。
下面來看對動態目標的描述:
“Among dynamic objects, we care passenger vehicles, trucks, cyclists, pedestrians, or any other object including animal or body parts on the road. We can also categorize object based on which lane the object is in. The most important object is CIPV (closest object in our path). Next important objects would be the one in neighbor lanes.”
動態目標目前關注的是車輛,自行車,行人,動物等。在這些目標中,最重要的是道路上離我們最近的物體,其次是相鄰車道上的物體。
“Given a 2D box, with its 3D size and orientation in camera, this module searches the 3D position in a camera coordinate system and estimates an accurate 3D distance using either the width, the height, or the 2D area of that 2D box. The module works without accurate extrinsic camera parameters.”
目標跟蹤
在檢測出各個運動目標之后,接下來需要準確的跟蹤這些目標,得到他們的運動參數和軌跡。目標跟蹤是一個狀態估計問題,這里的狀態就是目標的位置,速度,加速度等參數。跟蹤算法可以分為單目標跟蹤和多目標跟蹤兩類,前者只跟蹤單個目標,后者可以同時跟蹤多個目標。
跟蹤算法的數據來源是目標檢測的輸出結果,即在每一個時刻先檢測出路上的移動目標,得到他們的位置,大小等信息,然后對不同時刻的這些數據進行分析,得到目標的狀態和運動軌跡。
單目標跟蹤算法的核心是估計出單個目標的位置,速度,加速度等狀態信息,典型的算法有卡爾曼濾波,粒子濾波等。
和單個目標跟蹤不同,多目標跟蹤需要解決數據關聯問題,即上一幀的每個目標和下一幀的哪個目標對應,還要解決新目標出現,老目標消失問題。多目標的跟蹤的一般流程為每一時刻進行目標檢測,然后進行數據關聯,為已有目標找到當前時刻的新位置,在這里,目標可能會消失,也可能會有新目標出現,另外目標檢測結果可能會存在虛警和漏檢測。聯合概率濾波,多假設跟蹤,線性規劃,全局數據關聯,MCMC馬爾可夫鏈蒙特卡洛算法先后被用于解決數據關聯問題來完成多個目標的跟蹤。
首先我們定義多目標跟蹤的中的基本概念,目標是我們跟蹤的對象,每個目標有自己的狀態,如大小、位置、速度。觀測是指目標檢測算法在當前幀檢測出的目標,同樣的,它也有大小、位置、速度等狀態值。在這里,我們要建立目標與觀測之間的對應關系。下面是一個數據關聯示意圖:
在上圖中,第一列圓形為跟蹤的目標,即之前已經存在的目標;第二列圓為觀測值,即當前幀檢測出來的目標。在這里,第1個目標與第2個觀察值匹配,第3個目標與第1個觀測值匹配,第4個目標與第3個觀測值匹配。第2個和第5個目標沒有觀測值與之匹配,這意味著它們在當前幀可能消失了,或者是當前幀沒漏檢,沒有檢測到這兩個目標。類似的,第4個觀測值沒有目標與之匹配,這意味著它是新目標,或者虛警。
下面我們看對阿波羅官方對跟蹤的描述:
“The object tracking module utilizes multiple cues such as 3D position, 2D image patches, 2D boxes, or deep learning ROI features. The tracking problem is formulated ase multiple hypothesis data association by combining the cues efficiently to provide the most correct association between tracks and detected object, thus obtaining correct ID association for each object.”
這里采用了多種線索來跟住目標,包括3D坐標,2D圖像塊,2D包圍盒,以及通過深度學習得到的ROI特征。對于多目標跟蹤,這里采用了多假設跟蹤算法[3],這種算法最早用于雷達數據的跟蹤,如果對它感興趣,可以閱讀參考文獻。
紅綠燈檢測識別
下面來看對紅綠燈檢測算法的描述:
“紅綠燈模塊根據自身的位置查找地圖,可以獲得前方紅綠燈的坐標位置。通過標定參數,可以將紅綠燈從世界坐標系投影到圖像坐標系,從而完成相機的自適應選擇切換。選定相機后,在投影區域外選取一個較大的感興趣區域,在其中運行紅綠燈檢測來獲得精確的紅綠燈框位置,并根據此紅綠燈框的位置進行紅綠燈的顏色識別,得到紅綠燈當前的狀態。得到單幀的紅綠燈狀態后,通過時序的濾波矯正算法進一步確認紅綠燈的最終狀態。我們提出的基于CNN的紅綠燈的檢測和識別算法具有極高的召回率和準確率,可以支持白天和夜晚的紅綠燈檢測識別。具體算法請參閱github技術文檔。”
模型數據
下圖是感知模塊中的一些模型和參數:
cnn_segmentation目錄下是用于車道線分割的模型。traffic_light目錄下有交通燈檢測模型。yolo_camera_detector目錄下有YOLO檢測器的配置文件。感興趣的讀者可以進一步閱讀。
參考文獻
[1] J Redmon, S Divvala, R Girshick, A Farhadi, "You only look once: Unified, real-time object detection," CVPR 2016.
[2] J Redmon, A Farhadi, "YOLO9000: Better, Faster, Stronger," arXiv preprint.
[3] Donald B Reid. An algorithm for tracking multiple targets. 1979, IEEE Transactions on Automatic Control.
-
機器學習
+關注
關注
66文章
8382瀏覽量
132443 -
自動駕駛
+關注
關注
783文章
13694瀏覽量
166166 -
Apollo
+關注
關注
5文章
340瀏覽量
18409
原文標題:機器學習在自動駕駛中的應用-以百度Apollo平臺為例
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
百度“蘿卜快跑”自動駕駛服務將試水香港
Apollo自動駕駛開放平臺10.0版即將全球發布

FPGA在自動駕駛領域有哪些應用?
禾賽科技獨供百度Apollo新一代無人車主激光雷達
單車4臺AT128!禾賽科技獲得百度蘿卜快跑新一代無人駕駛平臺主激光雷達獨家定點

百度發布全球首個L4級自動駕駛大模型
百度Apollo計劃年內部署千臺無人車
百度發布全球首個L4級自動駕駛大模型Apollo ADFM
特斯拉與百度合作掃清自動駕駛關鍵障礙
發展新質生產力,百度蘿卜快跑開啟大興機場的自動駕駛接駁路線

百度王云鵬:自動駕駛終于迎來“曙光初現”
百度“蘿卜快跑”首批獲準在京開展大興機場自動駕駛載人示范應用
百度發布Apollo開放平臺9.0
重構12萬行代碼、開發者3倍增速,Apollo開放平臺9.0重磅發布






 工商網監
工商網監
評論