 介紹用遷移學習處理NLP任務的大致思路
介紹用遷移學習處理NLP任務的大致思路
編者按:遷移學習在CV領域的應用已經取得不小的進步了,而在自然語言處理(NLP)領域,很多任務還在使用詞嵌入。嵌入的確是種更豐富的表現單詞的形式,但是隨著任務種類的增多,嵌入也有了局限。本文將介紹用遷移學習處理NLP任務的大致思路,以下是論智的編譯。
通用語言建模
遷移學習在計算機視覺領域已經有了很多應用,最近幾年也做出了許多不錯的成果。在一些任務中,我們甚至能以超越人類精確度的水平完成某項任務。最近,很少能看到用無需預訓練的權重輸出頂尖結果的模型。事實上,當人們生產它們時,經常會用遷移學習或某種微調的方法。遷移學習在計算機視覺領域有很大的影響,為該領域的發展做出了巨大貢獻。
但是直到現在,遷移學習對計算機視覺還有些許限制,最近的研究表明,這種限制可以擴展到多個方面,包括自然語言處理和強化學習。最近的幾篇論文表明,NLP領域中的遷移學習和微調的結果也很不錯。
最近,OpenAI舉辦了一場Retro競賽,其中參賽者要創建多個智能體,在玩游戲時不能接觸環境,而是利用遷移學習進行訓練。現在,我們可以探索這種方法的潛力了。
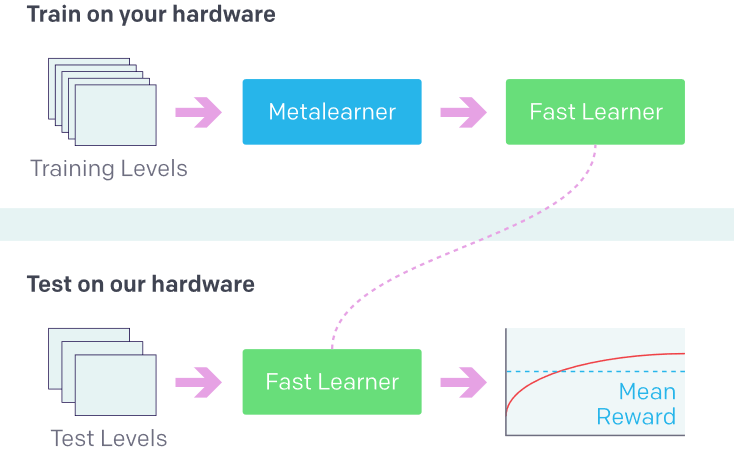
利用之前的經驗學習新事物(強化學習中的新環境)。來源:OpenAI Retro Contest
此前在計算機視覺領域關于漸進式學習的研究給模型進行了概括,因為這是保證神經網絡在學習時穩定的最重要因素之一。想實現這一目的的論文就是Universal Language Model Fine-tuning for Text Classification。
文本分類是NLP領域重要的部分,它與現實生活中的場景密切相關,例如機器人、語音助手、垃圾或詐騙信息監測、文本分類等等。這項技術的用途十分廣泛,幾乎可以用在任意語言模型上。本論文的作者進行的是文本分類,直到現在,很多學術研究人員仍然用詞嵌入訓練模型,例如word2vec和GloVe。
詞嵌入的局限
詞嵌入是單詞的密集表示,通過用轉換成張量的真實數字轉化而來。在模型中,嵌入需要用特殊順序排列,這樣模型才能學會詞語和語境中的語法和語義關系。
進行可視化時,有相近語義的單詞的嵌入也會更近,這樣每個單詞也會有不同的向量表示。
詞匯表中的不常見詞
處理數據集時,我們經常會碰到生僻詞語。

標記化(Tokenization)。這些詞語都是常見詞,但是有了類似這樣的嵌入就會很難處理
對于某些只出現很少幾次的詞語,模型就要花大量時間弄清楚它的語義,所以人們專門建立了一個詞匯集來處理這一問題。Word2vec無法處理未知詞語。當模型不認識某個詞時,它的向量就不能被確切地分解,所以它必須隨意地進行初始化操作。關于嵌入,常見的問題有:
處理共享表示(shared representations)
詞語表示的另一個問題是,在子字詞中沒有一個共同的表示。英文中的前綴和后綴通常會改變詞語的意思。由于每個向量都是獨立的,詞語間的語義關系就不能完全被理解。
共現統計(co-occurrence statistics)
分布式詞向量模型能夠捕捉到詞語中共現統計的某些方面。在單詞共現上訓練的嵌入可以捕捉單詞語義之間的相似性,所以可以在單詞相似性的任務上進行評估。
如果某個特殊的語言模型用char-based輸入,并且無法從與訓練中受益,那么就需要對詞嵌入進行隨機處理。
支持新語言
嵌入的使用在面對其他語言時,會出現不穩定的情況。新語言需要新的嵌入矩陣,無法使用共同的參數,所以模型不能用于多語言任務。
詞嵌入可以被連接起來,但是用于訓練的模型必須從新開始處理嵌入。預訓練嵌入被看成是固定參數。這樣的模型在漸進式學習中是沒有用的。
計算機視覺已經表明,hypercolumns和其他常用的訓練方法相比,并不實用。在CV中,一個像素的hypercolumn是該像素之上,所有卷積網絡單元中的活動向量。
平均隨機梯度方法,權重下降LSTM
這個研究中所用模型的靈感來自論文:Regularizing and Optimizing LSTM Language Models。它使用權重下降的LSTM,LSTM利用DropConnect作為循環正則化形式。DropConnect是在神經網絡中對大型完全連接層進行規范化的泛化。
用Dropout訓練時,一個隨機選擇的子集在每層中被設置為0.DropConnect設置了一個隨機選擇的權重子集,每個單元從其中接收從上一層來的輸入。
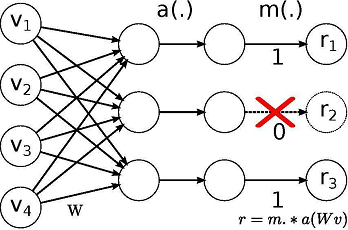
Dropout網絡和DropConnect網絡的不同
通過在hidden-to-hidden權重矩陣上使用DropConnect,可以避免LSTM循環連接中的過度擬合。這一正則化技術還可以防止其他循環神經網絡中的循環權重矩陣的過度擬合現象。
通常所用的值為:
dropouts = np.array([0.4,0.5,0.05,0.3,0.1]) x 0.5
這里的×0.5是一個超參數,雖然數組中的比列已經達到很好的平衡,但是用0.5進行調整可能也是需要的。
由于同樣的權重可能在不同階段重復使用,同樣的權重會在全部過程中保持下降。結果和variational dropout非常像,它運用了相同的dropout掩碼,只是應用在了循環權重上。
通用語言模型
一個三層的LSTM結構以及經過調整的dropout參數能比其他文本分類任務表現得更好。主要用到的有三種技術。
三角變化學習速率(STLR)
最初我使用Adam優化算法和權重衰減,但是優化器又很有限制。如果模型在下鞍點卡住,同時生成的梯度很小,那么模型就很難生成足夠的梯度走出非凸區域。
Leslie Smith提出的循環學習速率(CLR)解決了這一問題。使用了CLR之后,精確度提高了10%。
學習速率決定了在目前的權重上應用多少損失梯度,這一方法和熱啟動的隨機梯度很像。

簡單地說,選擇初始學習速率和學習速率調度表比較困難,因為有時并不能分辨那種情況更好。
但是可以給每個參數應用靈活的學習速率,例如Adam、Adagrad和RMSprop等優化器可以在訓練時對每個參數的學習速率進行調整。
論文Cyclical Learning Rates for Training Neural Networks用簡潔優雅的方法解決了上述常見問題。
循環學習速率(CLR)為學習速率的值創建了高低兩個界限。它可以和適應性學習速率結合,但是和SGDR很相似,同時所需計算力并不多。
如果在最低點停滯,可以使用更高的學習速率讓模型走出此區域,但如果位置過于低,那么傳統的改變學習速率的方法就無法生成足夠的梯度。
非凸函數
周期性的更高學習速率可以更流利、更快地穿過此區域。
最優學習速率將處于最大和最低界限之間。
所以有了遷移學習在A上運用的模型可以遷移到B上提到其表現力。語言模型有著用于CV分類的所有功能:它了解語言、理解層次關系,能夠進行長時間應用,可進行情感分析。
ULMFiT和CV一樣有三個階段。

第一階段,語言模型的預訓練。語言模型在通用數據集上訓練,它從中學習到通用特征,了解語義關系,就像ImageNet。
第二階段,語言模型的微調。用不同的微調方法和三角形可變學習速率,從而使模型適應不同的任務。
第三階段,分類器微調。對分類器進行調整,逐步解鎖進行微調,用STLP保存低水平表示,同時對高層次進行調整。
總之,ULMFiT可以看做是模型的主干,上面添加了一個分類器。它用的是在通用語料上訓練過的模型。在之后的任務上可以進行微調以達到文本分類的最佳水平。
ULMFiT可以解決的問題
這一方法之所以通用,是因為它對數據集沒有要求。任何長度的文件和數據集都能用它解決。它使用單一的結構(在這個案例中是AWD-LSTM,和CV中的ResNet一樣)。無需特殊定制,也不需要額外的文本使其適應不同的任務。
該模型還可以用注意力進行進一步改善提高,如有需要還可以加入跳躍式連接(skip connection)。
不同情況下的微調
神經網絡的每個圖層都捕捉到不同的信息。在CV中,初始層捕捉到的是廣泛的、明顯的特征。越深的圖層捕捉到的特征就越復雜、具體。利用同樣的規則,這種方法會在語言模型的不同圖層提出不同的調整方法。為了達到這一目的,每一層的學習速率都不相同,這樣一來人們可以決定每一層的參數如何優化。
參數θ將會分成一系列參數,并作用在l個圖層上{θ1,…,θL},同時學習速率也可以做出同樣的操作,隨機梯度下降可以表示成:
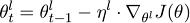
不同任務權重下對分類器的微調
之后會添加兩個線性模塊,每個模塊利用批歸一化和較低值的dropout。在模塊之間,ReLU用來作為激活函數。這些分類器圖層并不會從預訓練中延續某種特征,而是從零開始訓練。在搭建模塊之前,會對上一個隱藏層進行池化,然后輸入到第一個線性層中。
trn_ds = TextDataset(trn_clas, trn_labels)
val_ds = TextDataset(val_clas, val_labels)
trn_samp = SortishSampler(trn_clas, key=lambda x: len(trn_clas[x]), bs=bs//2)
val_samp = SortSampler(val_clas, key=lambda x: len(val_clas[x]))
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=1, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=1, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
dropouts = np.array([0.4,0.5,0.05,0.3,0.4])*0.5
m = get_rnn_classifer(bptt, 20*70, c, vs, emb_sz=em_sz, n_hid=nh, n_layers=nl, pad_token=1,
layers=[em_sz*3, 50, c], drop=[dropouts[4], 0.1],
dropouti=dropouts[0], wdrop=dropouts[1], dropoute=dropouts[2], dropouth=dropouts[3])
Concat池化
注意循環模型的狀態通常是很重要的,并且要保留有用的狀態,釋放沒有用的并且限制內存的狀態。但是隱藏包含了許多信息,而需要保留的權重都在隱藏層。為了做到這一點,我們將最后一步的隱藏層和隱藏層最大和平均池化的表示連接起來,這樣可以適應GPU的內存。
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=1, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=1, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
訓練分類器(逐步解鎖)
如果直接對分類器進行微調,則有可能導致嚴重的遺忘出現,而緩慢地微調可能會導致過度擬合和收斂。所以我們認為不能直接對所有圖層進行微調,而是要每次只調一個圖層,逐步進行。
在文本分類上進行逐步反向傳播(BPTT)
BPTT經常用于RNN中處理序列數據,每一步都有一個輸入、一個網絡的復制版本和一個輸出。同時每一步還會生成網絡的錯誤并集合在一起。
模型在上一批處理的最后階段進行初始化。平均和最大池化的隱藏狀態同樣被追蹤下去。模型的核心使用了可變長度的序列,以下是用PyTorch進行采樣的一小片段:
classSortishSampler(Sampler):
def __init__(self, data_source, key, bs):
self.data_source,self.key,self.bs = data_source,key,bs
def __len__(self): return len(self.data_source)
def __iter__(self):
idxs = np.random.permutation(len(self.data_source))
sz = self.bs*50
ck_idx = [idxs[i:i+sz] for i in range(0, len(idxs), sz)]
sort_idx = np.concatenate([sorted(s, key=self.key, reverse=True) for s in ck_idx])
sz = self.bs
ck_idx = [sort_idx[i:i+sz] for i in range(0, len(sort_idx), sz)]
max_ck = np.argmax([self.key(ck[0]) for ck in ck_idx]) # find the chunk with the largest key,
ck_idx[0],ck_idx[max_ck] = ck_idx[max_ck],ck_idx[0] # then make sure it goes first.
sort_idx = np.concatenate(np.random.permutation(ck_idx[1:]))
sort_idx = np.concatenate((ck_idx[0], sort_idx))
return iter(sort_idx)
結果
這一方法比其他依靠嵌入或其他遷移學習的NLP方法優秀得多。通過逐漸解鎖并且用新的方法訓練分類器,四次迭代后可以達到94.4的精確度,比其他方法都準確。
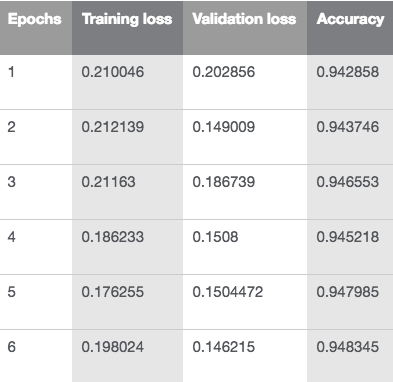
用ULMFiT進行文本分類時的損失和精確度
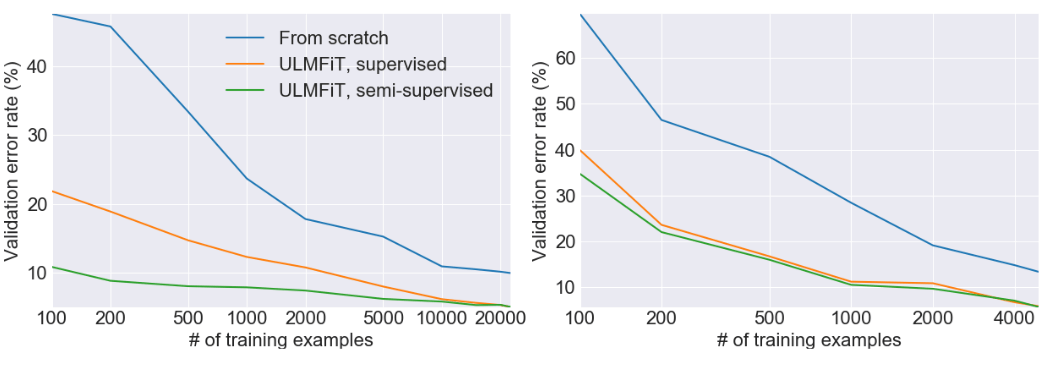
驗證錯誤率
-
計算機視覺
+關注
關注
8文章
1696瀏覽量
45928 -
強化學習
+關注
關注
4文章
266瀏覽量
11217 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13511
原文標題:概覽遷移學習在NLP領域中的應用
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NLP多任務學習案例分享:一種層次增長的神經網絡結構
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

OpenAI介紹可擴展的,與任務無關的的自然語言處理(NLP)系統

面向NLP任務的遷移學習新模型ULMFit

如何學習自然語言處理NLP詳細學習方法說明
8個免費學習NLP的在線資源
NLP遷移學習面臨的問題和解決
如何利用機器學習思想,更好地去解決NLP分類任務






 工商網監
工商網監
評論