 一種具有混合精度的高度可擴展的深度學習訓練系統
一種具有混合精度的高度可擴展的深度學習訓練系統
編者按:昨天,騰訊和香港浸會大學的研究人員在arxiv上發表了一篇文章,介紹了一種具有混合精度的高度可擴展的深度學習訓練系統。或許是覺得這個名字不夠吸引人,他們又在后面加了一個頗具標題黨意味的后綴——“4分鐘訓練ImageNet”。那么這樣的措辭是否夸大其詞了呢?讓我們來讀讀他們的論文。

現狀
現如今,隨著數據集和大型深度神經網絡規模不斷擴大,研究人員訓練模型使用的時間也在不斷延長,短則幾天,長則幾周,但過長的訓練時間會給研發進度帶來阻礙。由于計算資源有限,針對這個問題,現在一種常見解決方案是使用分布式同步隨機梯度下降(SGD),它可以跨硬件作業,前提是必須給每個GPU分配合理的樣本數量。
雖然這種做法可以利用系統的總吞吐量和較少的模型更新來加速訓練,但它也存在兩個不可忽視的問題:
較大的mini-batch由于存在泛化誤差,會導致較低的測試精度:
如果增加mini-batch里的樣本個數,我們確實可以通過計算平均值來減少梯度變化,從而提供更準確的梯度估計,此時模型采用的步長更大,優化算法速度也更快。但正如ImageNet training in minutes這篇論文所論證的,一旦mini-batch的大小增加到64K,ResNet-50在測試集上的準確率會從75.4%下降到73.2%,這達不到基線模型的精度要求。
當使用大型GPU集群時,訓練速度并不會隨著GPU數量的增加而呈線性上升趨勢,尤其是對于計算通信比較高的模型:
訓練模型時,分布式訓練系統會為每個GPU分配訓練任務,然后在每個訓練步之間插入一個梯度聚合步驟,GPU數量越多,這個梯度聚合步就越容易成為系統瓶頸。假設GPU數量N固定,如果要提升系統總吞吐量T,我們就要同時提高單個GPU的吞吐量S和它的縮放效率e,但這兩者提升需要額外的算力資源,這就和N固定有矛盾。
實驗結果
在介紹研究成果前,我們先來看看最引人注意的“4分鐘訓練ImageNet”。
根據論文實驗部分的內容,研究人員選取的模型是AlexNet和ResNet-50,它們各自代表一種典型的CNN。AlexNet的參數數量是ResNet-50的2.5倍,而ResNet-50的計算卻是前者的5.6倍。因此它們的瓶頸分別是通信和計算,這正代表上節提出的兩個問題。
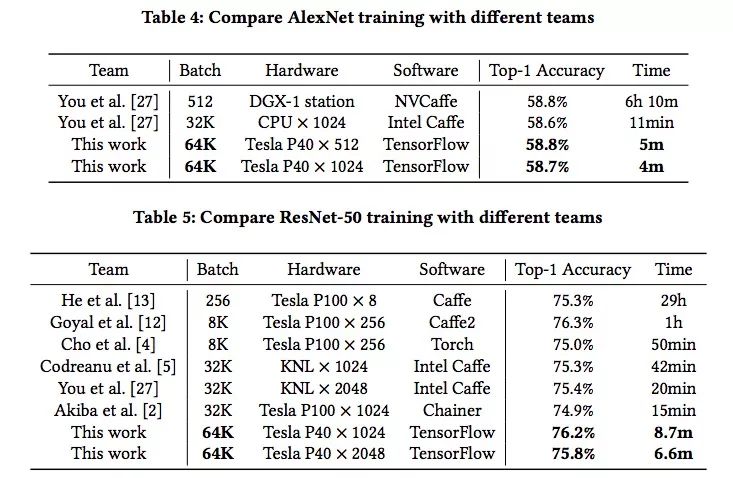
上表是兩個模型的訓練結果和對比,可以發現,在ImageNet數據集上,研究人員用4分鐘訓練好AlexNet,又用6.6分鐘訓練好ResNet-50,batch size非常大,但精度卻和其他模型沒什么區別。從數據角度看,這確實是個歷史性的突破。
而根據騰訊機智團隊自己的介紹,在這之前,業界最好的水平來自:日本Perferred Network公司Chainer團隊,他們用15分鐘就訓練好了ResNet-50;UC Berkely等高校的團隊,他們用11分鐘訓練好AlexNet。相較之下,騰訊和香港浸會大學的這個成果創造了AI訓練的世界新紀錄。
但顯然,他們在寫論文標題的時候也漏掉了重要內容,就是這個速度背后是2000多塊GPU,相信這個真相會讓一些研究人員興奮,也會讓大批學者和實驗室感到內心拔涼。
研究成果概述
關于論文技術的詳細細節,騰訊技術工程官方已經有長文分析,所以這里只根據論文內容的一點簡介(才不說是寫完才發現人家已經發了呢)。
這篇論文為為密集GPU集群構建了一個高度可擴展的深度學習訓練系統,它很好地解決了上述兩個問題,下圖是它結構概覽:
從圖中我們可以看到,這個系統可以大致分為三個模塊:輸入管道模塊、訓練模塊和通信模塊。
輸入管道負責在當前步驟完成之前就為下一步提供數據,它使用pipelining來最小化CPU和GPU的閑置時間。
訓練模塊包括模型構建和變量管理。在這個模塊中,研究人員結合了各類優化方法,如使用混合精度訓練前向/反向傳播和用LARS更新模型。
通信模塊使用tensor fusion和論文提出的混合Allreduce,根據張量大小和GPU集群大小優化縮放效率。
1. 提出了一種混合精度訓練方法,可以顯著提高單個GPU的訓練吞吐量而不會降低精度。
之前,Micikevicius等人已經在研究中提出過在訓練階段使用半精度(FP16)有助于降低內存壓力并增加計算吞吐量的想法,前者可以通過把相同數量的值儲存進更少的bit來實現,后者則可以降低數學精度,讓處理器提供更高的吞吐量。
而Yang You等人提出了一種為分布式培訓提供更大mini-batch的算法——LARS(自適應速率縮放),它會為每一層引入局部學習率,也就是用系數η加權的L2正則化權重和梯度權重的比率,能大幅度提高大batch size場景下的訓練精度。
這兩個成果非常互補,但它們不能直接結合使用,因為會導致梯度消失。為了融合兩種思想,研究人員做出的改進是用LARS進行混合精確訓練,如下圖所示,當進行前向傳播和反向傳播時,系統先把參數和數據轉成半精度浮點數,然后再做訓練,而訓練權重和梯度時,參數和數據則是單精度浮點數。
2. 提出了一種針對超大型mini-batch(最大64k)的優化方法,可以在ImageNet數據集上訓練CNN模型而不會降低精度。
模型架構改進是提高模型性能的一種常見手段,在論文中,研究人員從以下兩個方面改進了模型架構:1)消除偏差和batch normalization的權重衰減;2)為AlexNet增加了一個batch normalization層。
除了這一點,深度學習中耗時占比較重的還有超參數調整。為了優化這一過程,研究人員的思路是:
參數步長由粗到細:調優參數值先以較大步長進行劃分,可以減少參數組合數量,當確定大的最優范圍之后再逐漸細化調整。
低精度調參:分析相關數據,放大低精度表示邊緣數值,保證參數的有效性。
初始化數據的調參:根據輸入輸出通道數的范圍來初始化初始值,一般以輸入通道數較為常見;對于全連接網絡層則采用高斯分布即可;對于shortcut的batch norm,參數gamma初始化為零(也可以先訓練一個淺層網絡,再通過參數遞進初始化深層網絡參數)。
3. 提出了一種高度優化的allreduce算法,使用這種算法后,相比NCCL計算框架,AlexNet和ResNet-50在包含1024個Tesla P40 GPU的集群上的訓練速度分別提高了3倍和11倍。
在張量足夠多的情況下,Ring Allreduce可以最大化利用網絡,但工作效率和速度都不如張量少的情況。針對這種現象,研究人員利用分層同步和梯度分段融合優化Ring Allreduce
分層同步與Ring Allreduce有機結合:對集群內GPU節點進行分組,減少GPU數量對整體訓練用時的影響。
梯度融合,多次梯度傳輸合并為一次:根據具體模型設置合適的Tensor size閾值,將多次梯度傳輸合并為一次,同時超過閾值大小的Tensor不再參與融合;這樣可以防止Tensor過度碎片化,從而提升了帶寬利用率,降低了傳輸耗時。
GDR技術加速Ring Allreduce:在前述方案的基礎上,將GDR技術應用于跨節點Ring,這減少了主存和顯存之間的Copy操作,同時為GPU執行規約計算提供了便利。
這三大成果的直接效果是在不降低分類準確率的同時,把AlexNet和ResNet-50訓練時所用的mini-batch size擴大至64K。同時,通過優化All-reduce算法,并讓系統支持半精度訓練,研究人員最后構建了一個高吞吐量分布式深度學習訓練系統,可以在GPU數量N不變的情況下,提高單個GPU性能S和縮放效率e。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
gpu
+關注
關注
28文章
4700瀏覽量
128696 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:騰訊&浸大最新研究:在4分鐘內完成ImageNet訓練(如果你有2000個GPU)
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Nanopi深度學習之路(1)深度學習框架分析
【HarmonyOS HiSpark AI Camera】基于深度學習的目標檢測系統設計
labview深度學習檢測藥品兩類缺陷
探索一種降低ViT模型訓練成本的方法
什么是深度學習?使用FPGA進行深度學習的好處?
基于一種航資系統綜合訓練裝置設計
一種新的目標分類特征深度學習模型
混合精度訓練的優勢!將自動混合精度用于主流深度學習框架
一種基于深度學習的地下淺層震源定位方法







 工商網監
工商網監
評論