 Dave Smith使用Excel電子表格深入淺出地講解了SVD++的原理
Dave Smith使用Excel電子表格深入淺出地講解了SVD++的原理
編者按:Dave Smith使用Excel電子表格深入淺出地講解了SVD++(基于協同過濾的推薦算法)的原理。
網絡貨架無窮無盡,尋找想看的影視劇可能讓你筋疲力竭。幸運的是,對抗選擇疲憊是Netflix的工作……它干得不錯。干得太好了。
Netflix魔法般地向你推薦完美的電影,讓你的眼睛緊緊地粘在屏幕上,將你的拖延變為沙發上的放縱。
該死的Netflix。你有什么秘密?你怎么能如此了解我們?
Netflix又勝利了……
其實這“魔法”驚人地簡單,這篇教程將通過循序漸進的電子表格揭示這一秘密。你可以下載Excel格式的電子表格(推薦),或者使用Google Sheets(運算較慢,由于兼容性問題,缺了一張圖):
https://drive.google.com/open?id=1y4X8H56TS6M7AXAU7yIm0EyxhqNUy1sz
如果無法訪問Google網盤,可以在論智公眾號(ID: jqr_AI)后臺留言excel獲取替代下載地址。
盡管自從Netflix Prize competition競賽之后,出現了一大堆關于推薦系統的論文和視頻,但其中的大部分要么對初學者而言技術性過強,要么過于抽象,難以實踐。
在本文中,我們將從頭創建一個電影推薦系統,僅僅使用直白的英語解釋和你可以在Excel中操作的公式。所有梯度下降通過手工推導得到,你可以使用Excel微調模型的超參數,加深你的直觀理解。
你將學習:
實現SVD++的一個版本的精確步驟,SVD++曾贏得一百萬美元的Netflix大獎。
機器到底是如何學習的(梯度下降)。看看Netflix是如何在你沒有明確告知的情況下學習你的電影品味的。
超參數調整。看看如何調整模型超參數(學習率、L2正則化、epoch數、權重初始化)得到更好的預測。
模型評估和可視化。學習訓練數據和測試數據的不同,如何預防過擬合,如何可視化模型特征。
在簡短地介紹推薦系統之后,我將帶領你創建一個預測一些好萊塢明星的電影評分的模型,整個過程共分為四部分:
模型概覽
觀看魔法秀(權重初始化、訓練)
魔法揭秘(梯度下降、導數)
我將逐步講解機器學習魔法背后的數學,我將使用實數作為例子代入批量梯度下降的公式(不會使用“宏”或者Excel求解器之類的東西隱藏細節)。

模型評估和可視化
本文適合哪些人?
想要入門推薦系統的人。
Fast.AI的深度學習課程的學生。
充滿好奇心,對機器學習感興趣的人。
特別感謝Fast.AI的Jeremy Howard和Rachel Thomas。這里的電子表格受到了他們的協同過濾課程的啟發(相關代碼見git.io/fNVW9)。他們呈現的電子表格依賴Excel內置的求解器進行幕后的優化計算;而我這里的電子表格展示了梯度下降計算的每一步,并允許你微調模型的超參數。
如果這份電子表格對你有幫助,請注冊我創建的郵件列表,注冊后可以收到更多后續的電子表格,幫助你入門機器學習和創建神經網絡。
excelwithml.com
推薦系統簡介
電影推薦系統可以簡化為兩大類:
協同過濾(詢問密友)
和
基于內容的過濾(標簽匹配)
協同過濾
協同過濾基于類似行為進行推薦。
如果Ross和Rachel過去喜歡類似的東西,那么我們將Rachel喜歡而Ross沒看過的電影向Ross推薦。你可以將他們看成是“協同”過濾網絡貨架上的噪音的“品味分身”。如果兩個用戶的評分有強相關性,那么我們就認定這兩個用戶“相似”。評分可以是隱式的,也可以是顯示的:
隱式(沉溺)—— 整個周末,Ross和Rachel都沉溺于老劇《老友記》。盡管他們沒人點贊,但我們相當確定他們喜歡《老友記》(以及他們可能有點自戀)。
顯式(喜歡)—— Ross和Rachel都點了贊。
協同過濾有兩種:近鄰方法和潛因子模型(矩陣分解的一種形式)。本文將聚焦一種稱為SVD++的潛因子模型。
基于內容的過濾
基于你過去喜歡的內容的明確標簽(類型、演員,等等),Netflix向你推薦具有類似標簽的新內容。
一萬美元大獎得主是……
在電影推薦的場景下,當數據集足夠大的時候,協同過濾(CF)輕而易舉就能擊敗基于內容的過濾。
雖然有無數混合這兩大類的變體,但出人意料的是,當CF模型足夠好時,加上元數據并沒有幫助。
為什么會這樣?
人會說謊,行動不會。讓數據自己說話
人們聲稱自己喜歡什么(用戶設置,調查,等等)和他們的行為之間有一道巨大的鴻溝。最好讓人們的觀看行為自己說話。(竅門:想要改善Netflix推薦?訪問/WiViewingActivity清理你的觀看記錄,移除你不喜歡的項。)
2009年,Netflix獎勵了一隊研究人員一百萬美元,這個團隊開發了一個算法,將Netflix的預測精確度提升了10%. 盡管獲勝算法實際上是超過100種算法的集成,SVD++(一種協同過濾算法)是其中最關鍵的算法之一,貢獻了大多數收益,目前仍在生產環境中使用。
我們將創建的SVD++模型(奇異值分解逼近)和Simon Funk的博客文章Netflix Update: Try This at Home中提到差不多。這篇不出名的文章是2006年Simon在Netflix競賽開始時寫的,首次提出了SVD++模型。在SVD++模型成功之后,幾乎所有的Netflix競賽參加者都用它。
SVD++關鍵想法:
奇異值(電影評價)可以被“分解”,也就是由一組潛因子(用戶偏好和電影特征)決定,直覺上,潛因子表示類型、演員之類的特征。
可以通過梯度下降和已知電影評價迭代學習潛因子。
影響某人評價的用戶/電影偏置同樣可以學習。
簡單而強大。讓我們深入一點。
1.1 數據
出于簡單性,本文的模型使用了30項虛假的評價(5用戶 x 6電影)。
1.2 分割數據——訓練集和測試集
我們將使用25項評價來訓練模型,剩下5項評價測試模型的精確度。
我們的目標是創建一個在25項已知評價(訓練數據)上表現良好的系統,并希望它在5項隱藏(但已知)評價(測試數據)上做出良好的預測。
如果我們有更多數據,我們本可以將數據分為3組——訓練集(約70%)、驗證集(約20%)、測試集(約10%)。
1.3 評價預測公式
評價預測是用戶/電影特征的矩陣乘法(“點積”)加上用戶偏置,再加上電影偏置。
形式化定義:

上式中,等式左側表示用戶i對電影j的預測評價。u1、u2、u3為用戶潛因子,m1、m2、m3為電影潛因子,ubias為用戶偏置,mbias為電影偏置。
1.3.1 用戶/電影特征
直覺上說,這些特征表示類型、演員、片長、導演、年代等因素。盡管我們并不清楚每項特征代表什么,但是當我們將其可視化后(見第四部分)我們可以憑直覺猜測它們可能代表什么。
出于簡單性,我使用了3項特征,但實際的模型可能有50、100乃至更多特征。特征過多時,模型將“過擬合/記憶”你的訓練數據,難以很好地推廣到測試數據的預測上。
如果用戶的第1項特征(讓我們假定它表示“喜劇”)值較高,同時電影的“喜劇”特征的值也很高,那么電影的評價會比較高。
1.3.2 用戶/電影偏置
用戶偏置取決于評價標準的寬嚴程度。如果Netflix上所有的平均評分是3.5,而你的所有評分的均值是4.0,那么你的偏置是0.5. 電影偏置同理。如果《泰坦尼克號》的所有用戶的評分均值為4.25,那么它的偏置是0.75(= 4.25 - 3.50)。
1.4 RMSE —— 評估預測精確度
RMSE = Root Mean Squared Error (均方根誤差)
RMSE是一個數字,嘗試回答以下問題“平均而言,預測評價和實際平均差了幾顆星(1-5)?”
RMSE越低,意味著預測越準……
上圖為RMSE計算過程示意圖。左側為三個用戶,“Actual Ratings”為用戶的實際評分,“Predictions”為預測評分。計算共分4步:
計算誤差(預測 - 實際)
對誤差取平方
計算平方誤差的均值
取均值的平方根
觀察:
我們只在意絕對值差異。相比實際評分高估了1分的預測,和相比實際評分低估了1分的預測,誤差相等,均為1。
RMSE是誤差同數量級的平均,而不是誤差絕對值的平均。在我們上面的例子中,誤差絕對值的平均是0.75(1 + 1 + 0.25 = 2.25,2.25 / 3 = 0.75),但RMSE是0.8292. RMSE給較大的誤差更高的權重,這很有用,因為我們更不希望有較大的誤差。
RMSE形式化定義:

同樣,上式中i表示用戶,j表示電影。戴帽的r表示預測評價,r表示實際評價。
1.5 超參數調整
通過電子表格的下拉過濾器,可以調整模型的3個超參數。你應該測試下每種超參數,看看它們對誤差的影響。
訓練epoch數—— 1個epoch意味著整個訓練集都過了一遍
學習率—— 控制調整權重/偏置的速度
L2(lambda)懲罰因子—— 幫助模型預防過擬合訓練數據,以更好地概括未見測試數據
模型超參數
現在,讓我們看一場魔法秀,看看模型是如何從隨機權重開始,學習最優權重的。
觀看梯度下降如何運作感覺就像看了一場大衛·布萊恩的魔術秀。
他到底是怎么知道我會在52張牌中選這張的呢?
等等,他剛剛是不是浮空了?
最后你深感敬畏,想要知道魔術是如何變的。我會分兩步演示,接著揭露魔法背后的數學。
2.1 “抽一張卡,隨便抽一張”(權重初始化)
在訓練開始,用戶/電影特征的權重是隨機分配的,接著算法在訓練中學習最佳的權重。
為了揭示這看起來有多么“瘋狂”,我們可以隨機猜測數字,然后讓計算機學習最佳數字。下面是兩種權重初始化方案的比較:
簡單—— 用戶特征我隨機選擇了0.1、0.2、0.3,剩下的特征都分配0.1.
Kaiming He—— 更正式、更好的初始化方法,從高斯分布(“鐘形曲線”)中隨機抽樣作為權重,高斯分布的均值為零,標準差由特征個數決定(細節見后)。
2.2 “觀賞魔術”(查看訓練誤差)
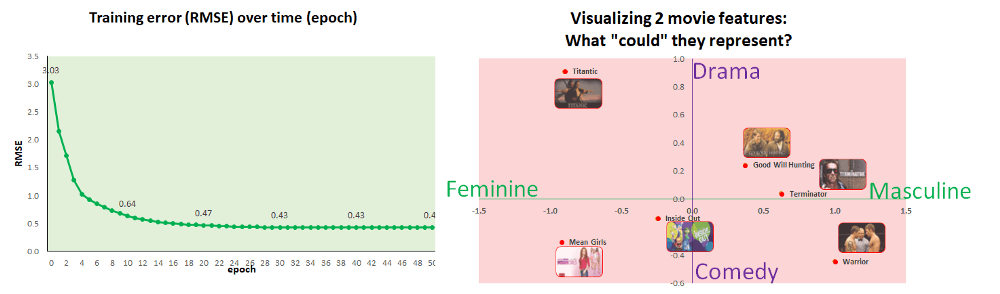
看看使用以上兩種方案學習權重最佳值的效果,從開始(epoch 0)到結束(epoch 50),RMSE訓練誤差是如何變化的:
如你所見,兩種權重初始化方案在訓練結束后都收斂到相似的“誤差”(0.12和0.17),但Kaiming He方法收斂得更快。
關鍵點:無論我們開始的權重是什么樣的,機器將隨著時間推移學到良好的值。
注意:如果你想要試驗其他初始化權重,可以在電子表格的“hyperparametersandinitial_wts”表的G3-J7、N3-Q8單元格中輸入你自己的值。權重取值范圍為-1到1.
想要了解更多關于Kaiming He初始化的內容,請接著讀下去;否則,可以直接跳到第3部分學習算法的數學。
Kaiming He權重初始化
權重 = 正態分布隨機抽樣,分布均值為0,標準差為(=SquareRoot(2/特征數))
電子表格中的值由以下公式得到:=NORMINV(RAND(),0,SQRT(2/3))
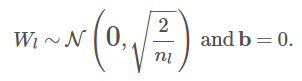
現在,是時候書呆一點,一步一步地了解梯度下降的數學了。
如果你不是真想知道魔法是如何起效的,那么可以跳過這一部分,直接看第4部分。
梯度下降是在訓練時使用的迭代算法,通過梯度下降更新電影特征、用戶偏好的權重和偏置,以做出更好的預測。
梯度下降的一般周期為:
定義一個最小化權重的代價/損失函數
計算預測
計算梯度(每個權重的代價變動)
在最小化代價的方向上“一點點地”(學習率)更新每個權重
重復第2-4步
你可以訪問電子表格的“training”(訓練)表,其中第11-16行是更新Tina Fey的第一項用戶特征的過程。
由于數據集很小,我們將使用批量梯度下降。這意味著我們在訓練時將使用整個數據集(在我們的例子中,一個用戶的所有電影),而不是像隨機梯度下降之類的算法一樣每次迭代一個樣本(在我們的例子中,一個用戶的一部電影),當數據集較大時,隨機梯度下降更快。
3.1 定義最小化的代價函數
我們將使用下面的公式,我們的目標是找到合適的潛因子(矩陣U、M)的值,以最小化SSE(平方誤差之和)加上一個幫助模型提升概括性的L2權重懲罰項。
下面是Excel中的代價函數計算。計算過程忽略了1/2系數,因為它們僅用于梯度下降以簡化數學。
L2正則化和過擬合
我們加入了權重懲罰(L2正則化或“嶺回歸”)以防止潛因子值過高。這確保模型沒有“過擬合”(也就是記憶)訓練數據,否則模型在未見的測試電影上表現不會好。
之前,我們沒有使用L2正則化懲罰(系數為0)的情況下訓練模型,50個epoch后,RMSE訓練誤差為0.12.
但是模型在測試數據上的表現如何呢?
在上圖中,我們看到,測試集上的RMSE為2.54,顯然我們的模型過擬合了訓練數據。
我們將L2懲罰系數從0.000改為0.300后,模型在未見測試數據上的表現好一點了:
3.2 計算預測
我們將計算Tina的電影預測。我們將忽略《泰坦尼克號》,因為它在測試數據集中,不在訓練數據集中。
我們之前給出過預測的計算公式(1.3節),為了便于查看,這里再重復一遍:

3.3 計算梯度
目標是找到誤差對應于將更新的權重的梯度(“坡度”)。
得出梯度之后,稍微將權重“移動一點點”,沿著梯度的反方向“下降”,在對每個權重進行這一操作后,下一epoch的代價應該會低一些。
“移動一點點”具體移動多少,取決于學習率。在得到梯度(3.3)之后,會用到學習率。
梯度下降法則:將權重往梯度的反方向移動,以減少誤差
第1步:計算Tina Fey的第一個潛因子的代價梯度(u1)。
1.1 整理代價目標函數,取代價在Tina Fey的第一個潛因子(u1)上的偏導數。
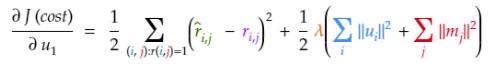

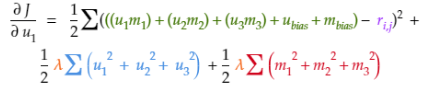
1.3 將公式每部分中的u1視為常數,取u1在公式每部分的代價上的偏導數。
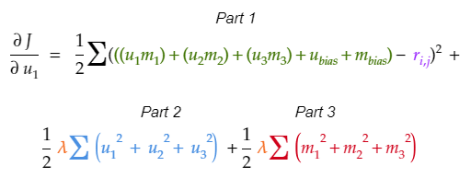
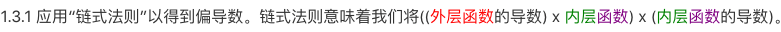

1.3.2 應用“冪法則”以得到偏導數。根據冪法則,指數為2,所以將指數降1,并乘上系數1/2. u2和u3視作常數,變為0.
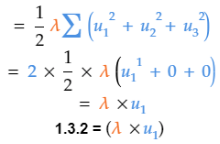
1.3.3 應用“常數法則”以得到偏導數。
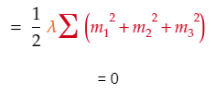
由于u1對這些項毫無影響,結果是0.1.3.3 = 01.4 結合1.3.1、1.3.2、1.3.3得到代價在u1上的偏導數。
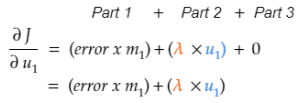
第2步:對訓練集中Tina看過的每部電影,利用前面的公式計算梯度,接著計算Tina看過的所有電影的平均梯度。
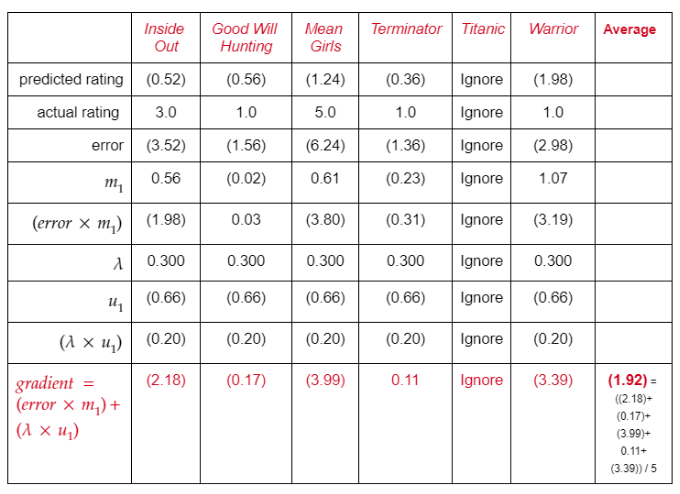
3.4 更新權重


“training”(訓練)表的X11-X16單元格對應上面的計算過程。
你可以看到,電影特征和用戶/電影偏置以類似的方式更新。
每一個訓練epoch更新所有的電影/用戶特征及偏置。
現在我們已經訓練好了模型,讓我們可視化電影的2個潛因子。
如果我們的模型更復雜,包括10、20、50+潛因子,我們可以使用一種稱為“主成分分析(PCA)”的技術提取出最重要的特征,接著將其可視化。
相反,我們的模型僅僅包括3項特征,所以我們將可視化其中的2項特征,基于學習到的特征將每部電影繪制在圖像上。繪制圖像之后,我們可以解釋每項特征“可能代表什么”。
從直覺出發,電影特征1可能解釋為悲劇與喜劇,而電影特征3可能解釋為男性向與女性向。
這不是完美的解釋,但還算一種合理的解釋。《勇士》(warrior)一般歸為劇情片,而不是喜劇片。不過其他電影基本符合以上解釋。
總結
電影評價由一個電影向量和一個用戶向量組成。在你評價了一些電影之后(顯式或隱式),推薦系統將利用群體的智慧和你的評價預測你可能喜歡的其他電影。向量(或“潛因子”)的維度取決于數據集的大小,可以通過試錯法確定。
我鼓勵你實際操作下電子表格,看看改變模型的超參數會帶來什么改變。
-
Excel
+關注
關注
4文章
218瀏覽量
55455 -
SVD
+關注
關注
0文章
21瀏覽量
12157 -
機器學習
+關注
關注
66文章
8378瀏覽量
132412
原文標題:使用Excel實現推薦系統
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論