 基于CNN的方法在代表性的公共數據集上的性能優于其他方法
基于CNN的方法在代表性的公共數據集上的性能優于其他方法
摘要:隨著攝像機在智能車輛中的普遍應用,視覺位置識別已經成為智能車輛定位中的一個主要問題。傳統的解決方案是使用手工制作的位置圖像進行視覺描述來匹配位置,但是這種描述方法對于極端的變異性卻效果不大,尤其是季節變換的時候。本文提出了一種基于卷積神經網絡( CNN )的新方法,通過將圖像放入預先訓練的網絡模型中自動獲取圖像描述符,并通過匯集、融合和二值化操作對其進行優化,然后根據位置序列的漢明距離給出位置識別的相似結果。在實驗部分,我們將我們的方法與一些最先進的算法FABMAP,ABLE-M和SeqSLAM進行比較,以說明其優勢。實驗結果表明,基于CNN的方法在代表性的公共數據集上的性能優于其他方法。
Ⅰ.介紹
在不斷變化的環境中長期導航[2]是當今機器人技術面臨的主要挑戰之一,因此視覺定位的主要問題之一是在長期和大規模環境中進行位置識別。然而,這是一項艱巨的挑戰,因為一些地方不得不應對在不同周、不同月和不同的季節,甚至是一天中不同時間的重大變化。這些條件變化是由外部環境引起的,如光照、天氣和季節。諸如快速外觀映射(FAB-MAP)[1]等方法已被證明可以映射大型、具有挑戰性的環境。最近,名為SeqSLAM [ 3 ]和ABLE - M [ 4 ]的算法定義了匹配序列圖像的方法,以提高一些條件變化的魯棒性。這些位置識別技術依賴于手工制作的功能,例如SIFT或LDB [4],非常不適合處理劇烈的視覺變化,例如從白天到夜晚,從一個季節到另一個季節,或從晴朗天氣到雨。 圖1給出了不同季節的例子。
圖1.視覺位置識別系統必須能夠( a )成功地匹配同一位置的感知上非常不同的圖像,同時( b )也拒絕不同位置的相似圖像對之間的不正確匹配。
最近深度學習技術和卷積神經網絡的發展為理解位置識別問題提供了另一種方法。AlexNet [ 5 ]顯示,從CNNs中提取的特征經過充分有效的訓練,在分類任務上比手工制作的特征獲得更好的結果。[ 7 ]提出了一個有效的深度學習框架來生成用于快速圖像檢索的二進制哈希代碼。考慮到位置識別[8]與圖像檢索相似,我們有理由期望利用基于CNN的特征的力量來設計位置識別問題的解決方案。然而,在視覺定位中,除了對目標識別[9]的一些研究外,深度學習并沒有得到充分的應用。在本論文中,我們提出了一種簡單而有效的方法,利用改進的CNN模型提取圖像描述符,增強圖像序列的匹配以進行視覺位置識別。所提出的方法如圖2所示,并將在后面的章節中詳細介紹。我們的方法具有以下特點:
首先,我們提出了一個基于VGG16-Places365[10]改進的CNN架構。我們的模型適用于通過添加,刪除和融合圖層來提取圖像特征的要求。
其次,我們將CNN層獲得的特征轉換為二進制表示,從而降低計算復雜度。其中一個主要的好處是他們可以使用漢明距離匹配位置。
第三,我們提出了一種算法,根據SeqSLAM和ABLE - m的一些思路,基于一系列圖像來計算匹配最佳候選位置。
論文的其余部分如下所示。我們在第Ⅱ節中簡要回顧了位置識別算法和CNN模型的相關工作;我們方法的細節將在第III節中介紹;第Ⅳ節給出了三個數據集的實驗結果,比較了所提出方法的性能;最后,我們在第V節中總結了本文,并討論了未來的工作。
II.相關工作
A.卷積神經網絡(CNN)
卷積神經網絡可以從訓練數據庫中學習圖像特征。在過去的五年里,隨著CNNs在計算機視覺領域變得越來越重要,人們已經做出了許多嘗試來改進AlexNet [ 5 ]的原始架構,以獲得更高的準確性,比如VGG 11、GoogLeNet 6、ResNet 10等。考慮到位置識別與圖像檢索相似,而且它是獨立的,K. Lin等人[ 7 ]提出了一個有效的深度學習框架來生成用于快速圖像檢索的二進制哈希代碼。
場景識別是另一個與視覺位置識別非常相似的領域,盡管這是深度學習中的一項分類任務。位置[10]包含超過1000萬個包含365個獨特場景類別的圖像,是用于訓練場景識別CNN模型的數據集。基于Places數據集和最先進的CNNs,許多研究人員培訓了一些CNNs模型,并將其展示給其他研究人員使用。位置識別可以被看作是圖像相似性匹配的一項任務,一些研究人員通過預先訓練的CNNs模型來實現。從深度學習的進步中得到啟發,我們提出了一個問題,我們可以利用深度CNN來實現視覺位置識別嗎?
B.視覺位置識別
與其他傳感器相比,視覺傳感器具有價格低廉、體積小等優點,正成為當今最受歡迎的機器人傳感器。循環閉包檢測的一種流行方法是基于快速外觀的映射(FAB-MAP)[1]。所提出的FAB-MAP使用單個關鍵點描述符,即尺度不變特征變換(SIFT),以及用于界標描述的離線詞袋描述符(BoW)和用于預測循環閉包候選的貝葉斯過濾器。然而,FAB-MAP有一些不足之處,需要提前離線訓練,并且在環境變化劇烈的場景中具有較差的穩健性。
如今,視覺定位面臨的主要挑戰是在長期大規模環境中的位置識別。為了在長期環境中提高拓撲定位的效率,許多其他技術被提了出來。在這方面,一個成功的方法是SeqSLAM,它在相同的路線下被評估為具有挑戰性的條件。它引入了使用序列圖像而不是單個圖像來確定位置的思想,以改善長期方案的性能。
使用序列而不是單一圖像利用了移動相機獲取的視覺數據的時間一致性,從而減少了自我相似環境識別中的誤報數量,并提高了對局部場景變化的容忍度。這個思想被ABLE-M [4]算法使用,它基本上減少了處理后的圖像,并將全局二進制描述符與漢明距離的快速計算進行了比較。
深度學習技術和卷積神經網絡的最新發展為理解位置識別問題提供了一種替代方法。Z. Chen, 等人[8]結合CNNs提取的有效特征,提出了一種基于Overfeat的視覺場所識別方法;X. Gao等人提出了一種新穎的方法,該方法采用改進的堆疊去噪自動編碼器(SDA)來解決視覺SLAM系統的閉環檢測問題;D. Bai等人[13]給出了一種融合AlexNet和SeqSLAM來檢測循環閉包的方法。最近的建議啟發了我們目前的工作,旨在提供一種基于改進和簡化的CNN特征的更穩健和有效的位置識別算法。
III.我們的方法
在這一部分,我們描述了我們提出的方法的主要特征:CNN模型、提取圖像描述符和相似性匹配。圖2顯示出了所提出的框架。
A.CNN模型
在第Ⅱ節A部分中,我們討論了今年麻省理工學院計算機科學和人工智能實驗室提出的Places數據集,實驗室現在正根據數據集舉辦2017年地方挑戰賽[15]。他們希望更多的研究人員使用他們的數據集來訓練CNN用于場景識別任務,并提供基于CNN模型的Places365-CNN,例如AlexNet,VGG,GoogLeNet,ResNet在他們的數據集上訓練。根據論文的實驗結果,我們選擇VGG16-Places365作為位置識別的基本模型,在多個數據集上具有最佳性能。
從LeNet-5 [16]開始,卷積神經網絡通常具有標準的結構堆疊卷積層(可選地,隨后是批量歸一化和最大池化)之后是一個或多個完全連接的層。VGG 16 - Place 335與VGG具有相同的結構,它具有16個重量層,包括13個卷積層和3個完全連接的層。Places數據集包含超過1000萬個包含365個唯一場景類別的圖像,因此最后一個完全連接的圖層的尺寸應修改為365。這13個卷積層被劃分為5個部分,其中一個部分的每一層都有相同的數據維度。每個部分后面都有一個最大匯集層,該層通過2 x2像素窗口執行,跨距為2。卷積層的堆疊之后是三個完全連接的( FC )層:前兩個層各有4096個信道,第三個層執行365路位置分類,因此包含365個信道(每類一個)。除了這些層之外,最后一層是soft-max層,并且所有隱藏層都配備有整流(ReLU)非線性。表1給出了VGG16-Places365網絡的權重層和池化層的輸出尺寸。
圖2.視覺位置識別方法的全局系統架構。(從Nordland數據集的兩個原因捕獲圖像,我們將序列定義為i和j。最后,圖片是相似度矩陣的可視化。)
通過深層架構,CNN能夠在不同的抽象層次上學習高級語義特性。有了深度架構,CNN能夠在不同抽象級別學習高級語義特征。然而,圖像的空間信息通過完全連接的層丟失,這在視覺位置識別等應用中可能是不理想的。在[ 8 ] [ 13 ]的實驗結果表明,在卷積層產生的基于CNN的深層特征,在環路閉合檢測中比全連接層特征獲得更好的性能。根據這些,我們選擇VGG16-Places365的三個層'conv3_3','conv4_3'和'conv5_3'來提取我們任務的圖像特征。此外,我們對CNN模型進行了大量修改,包括添加幾個池層和刪除完全連接的層,以減少特征尺寸并節省圖像處理時間。然后,在將三層的特征調整為一維后,我們使用連接[ 17 ]的操作來融合它們。我們做了很多實驗來調整增加的池化層的網絡參數,您可以在第Ⅳ節中看到實驗細節。最終的模型結構如圖3所示。
B.用于位置識別的特征描述符
視覺特征是影響圖像匹配準確性的最重要因素之一。我們的方法使用從上面給出的CNN模型中提取的CNN特征,而不是傳統手工制作的特征來計算圖像之間的相似性。浮點是我們最終從模塊中獲取的CNN功能的類型。我們將該特征命名為Fcnn,其尺寸為1×100352。降低圖像匹配的計算成本的實用方法是將特征向量轉換為二進制代碼,這可以使用漢明距離快速比較。我們首先將其每個元素標準化為8位整數(0~255),然后得到整數特征如(2)所示。然后,可以很容易地轉換為二進制特征。
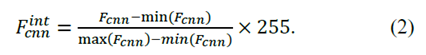
C.二值化的有效匹配
使用二進制描述符匹配漢明距離比使用L2范數匹配描述符更快更有效,并且在此用于計算圖像之間的距離。在很多研究中,我們注意到他們通過匹配單個圖像來計算兩幀的相似度。如果我們將兩個圖像的特征描述符定義為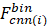 和
和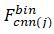 ,我們可以計算它們的漢明距離HmDij來表示相似性。計算過程如(3)所示。
,我們可以計算它們的漢明距離HmDij來表示相似性。計算過程如(3)所示。
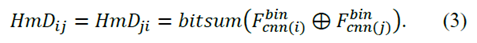
因為在長期和大規模的環境中表現更好,所以像[ 3 ] [ 4 ]等作品中介紹的那樣,位置被認為是圖像序列而不是單個圖像。在我們的方法中,我們將Slength定義為匹配當前幀的圖像序列長度。因此,第i幀的圖像序列由范圍(i - Slength+1,i)中的連續圖像組成,并且我們將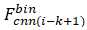 ,
,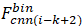 ,...,
,...,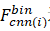 連接為用于匹配的最終特征Fi。在這種情況下,我們可以使用(4)的序列信息來獲得圖像之間的距離。該距離是不同地方的相似度得分,我們將其保持在相似度矩陣(M)中。如果我們發現兩幀之間的距離小于給定的閾值,那么這些位置就會被成功識別。
連接為用于匹配的最終特征Fi。在這種情況下,我們可以使用(4)的序列信息來獲得圖像之間的距離。該距離是不同地方的相似度得分,我們將其保持在相似度矩陣(M)中。如果我們發現兩幀之間的距離小于給定的閾值,那么這些位置就會被成功識別。

表一. VGG16 - Place335網絡各層的輸出尺寸
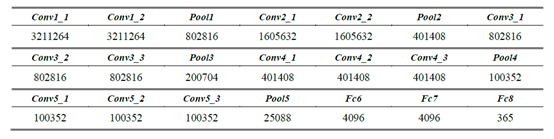
圖3.基于vg16 - place 335的CNN模型用于視覺位置識別。(所有完全連接的層都被移除,三個名為pool 3 _ fuse、pool 4 _ fuse、pool 5 _ fuse的池層分別被添加到Conv 3 _ 3、Conv 4 _ 3和Conv 5 _ 3的背面。三個輪詢層的輸出被融合為最終的CNN特征。)
IV.績效評估
在本節中,演示了一組離線實驗來評估我們方法的性能。我們的實現是一個基于Caffe [18]的python程序,它是一個開源的深度學習框架。我們首先介紹數據集和評估指標,然后與公共數據集上的幾種著名算法的性能進行比較。
A.數據集和評估指標
用于實驗的第一個數據集是FAB-MAP最初使用的City Center [1]數據集。它是一個基本的數據集,廣泛應用于閉環檢測和位置識別研究實驗,因此我們使用它來調整和優化網絡模型。然后我們使用Nordland[2]數據集進行了測試,這些數據集是使用單目攝像機在長期條件下記錄的。根據CNN模型的參數設置,我們將在每張圖像進入網絡之前對其進行224×224的新尺寸預處理。最常用的位置識別算法評估方法是繪制Precision-Recall(PR)曲線,該曲線提供了算法性能的更多信息。其主要要素定義如下:精度定義為檢測總數的真正位置數;Recall被定義為真實地點的數量與地面真實地點的數量之比。(5)顯示了計算過程。我們通過掃描不同的距離閾值θ來獲得PR曲線,如(6)所示。
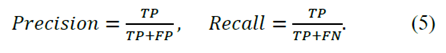
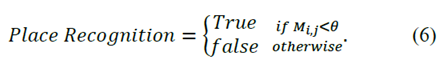
B.城市中心數據集中的結果
第一個數據集,城市中心[1],在康明斯和紐曼市中心附近的公共道路上收集。它包含1237對大小為640×480的圖像,由兩個攝像頭(左和右)在機器人上拍攝,機器人以每1.5米一個圖像的頻率穿過環境。這些圖像包括動態物體,此外,它是在有陽光的大風天收集的,這使得豐富的樹葉和陰影特征不穩定,如圖4 ( b )和4 ( c )所示。提供了數據集GPS信息和地面實況。機器人繞一個環路行進兩次,總路徑長度為2 km,當機器人繞第二個環路運行時,我們可以在這些位置實現位置識別,標記為紅色曲線,如圖4(a)所示。
圖4.城市中心數據集。( ( a )是GPS信息的可視化,紅色曲線是機器人運行的第二個環,我們應該在這些位置進行位置識別。( b )和( c )是該數據集的兩對代表性圖片。)
由于網絡的輸入只能是一個圖像,我們只將左攝像頭的圖像作為我們的測試集。我們還在機器人退出循環后修改了一些地面實況值,因為當雙目機器人在相同位置向后移動時,一個攝像機的圖像完全不同。在這種情況下,不可能實現位置識別。
首先,我們在VGG16-Places365的每一層上做一些實驗,PR曲線如圖5(a)所示。如預期的,結果證明提取卷積特征獲得了最佳效果,并且每一層的性能都優于FABMAP算法的開放工具箱open FABMAP [ 20 ]。圖5的其他部分分別給出了添加的匯集層的實驗結果,“pool3_fuse”,“pool4_fuse”和“pool5_fuse”。通過調整這些層的類型,MAX或AVE,以及濾波器的尺寸,2×2、4×4、7×7、8×8或14×14,我們在綜合考慮實時性和準確性的情況下獲得了每一層的最佳參數設置。當特征維數小于某個值時,算法的效果急劇惡化,當濾波器的大小變大時,最大濾波器優于平均濾波器。pool5_fuse圖層使用大小為2×2的平均過濾器,pool3_fuse圖層和pool4_fuse圖層都使用大小為4×4的最大過濾器。此外,我們給出了通過這些設置的多層特征融合方法獲得的實驗結果,它們也在圖5中示出。很容易看出融合方法比單層獲得了更好的結果,我們認為原因是多層的特征融合包含更多的空間信息。我們將此作為最終的CNN模型,如最后的第3接A部分所述。
C.Nordland數據集的結果
Nordland 數據集 [ 2 ]記錄了挪威北部728公里的火車旅程,在四個不同的季節,火車前方的同一視角。因此,數據集可以被認為包含一個循環,并遍歷四次。如圖6所示,風景已經發生了巨大的變化,從冬天的積雪覆蓋到春天和夏天的新鮮植被和綠色植被,再到秋天的彩色樹葉。大多數旅程都是通過自然風光,但火車也經過市區,偶爾停留在火車站或信號站。這可能是目前用于長期視覺位置識別評估的最長和最具挑戰性的數據集。在處理之后,數據被確定為25fps并且大小為1920×1080,并且圖像序列被同步,即,在相同時間點數據處的每個序列表示相同的位置。
圖5.城市中心數據集的實驗結果。(關于VGG16-Places365的不同層的曲線顯示在(a)中。(b),(c),(d)顯示了添加的具有不同設置的池層的結果)
在我們的方法中,我們關注匹配圖像序列的問題,而不是識別位置的單一圖像。在Nordland數據集中,我們首先通過比較春季和秋季之間的序列來進行不同長度圖像序列的實驗。該方法可以在長期和大規模的視覺位置識別中獲得更好的結果,如圖7所示。注意圖片中的PR曲線,我們可以發現,隨著Slength的增加,算法的效果越來越好,這證明了我們想法的正確性。但是當Slength大于200時,算法的效果開始受到限制。我們分析當Slength足夠長以包含一些無法匹配的特定位置時會發生這種情況,可以將其視為噪聲。考慮到準確性和復雜性,25 fps數據的最佳序列長度配置為200。因此,我們在其他實驗中使用Slength= 200。然后,我們將我們的方法的性能與主要的最新工作進行比較,包括FAB-MAP,SeqSLAM和ABLE-M算法。由于OpenFABMAP [20],OpenSeqSLAM [2]和OpenABLE [21]的作者開發的源代碼,實現了評估。如果我們不指定任何參數,我們將使用開源代碼中的默認設置。
圖6.每個季節的Nordland 數據集的示例圖像。
圖7.不同Slength的PR曲線。
圖8. Nordland數據集的實驗結果。
現在,我們處理了六種組合的結果,春天對比夏天,春天對比秋天,春天對比冬天,夏天對比秋天,夏天對比冬天,秋天對比冬天,對應的序列。這些評估由圖8中所示的PR曲線描述,其中我們可以觀察到不同季節對位置識別性能的影響。值得注意的是,沒有匹配圖像序列的OpenFABMAP已經取得了比其他方法更差的結果。除了位置識別,準確率為100 %的Recall也是一個很好的性能指標。以100%的精度,我們的方法比其他方法實現了更好的Recall。應該注意到,受開始時序列的影響并不完整,基于序列的方法實現100%Recall是一個限制。在相同條件下,冬季實驗表現較差,因為積雪增加了識別難度。
D.討論
從以上三部分的實驗中,我們可以看到,與傳統的使用手工特征描述圖像的方法相比,我們基于CNN的方法在位置識別任務中具有很大的優勢。我們給出如下原因:
(1)通過CNN對大量數據進行學習的圖像描述符可以更準確地描述圖像之間的差異,
(2)通過融合三個最佳CNN層保留更多圖像空間信息的特征,
(3)基于圖像序列的識別消除了噪聲場所的影響。
此外,在上述實驗中,我們的方法在某些地方沒有取得好的識別結果。例如,在連續多幀圖像中,大部分區域被移動的物體覆蓋,或者被天空和地面積雪占據。目前,所有識別算法的性能都很差,這是長期和大規模環境下視覺位置識別最難解決的問題。
V.結論
在這項工作中,我們提出了一個簡單有效的基于VGG的CNN框架來提取用于位置識別的圖像描述符。我們在卷積層“conv3_3”,“conv4_3”和“conv5_3”后面添加了三個具有合適濾波器的池化層,并將它們的輸出融合為描述符組合二值化。此外,用于描述地點的最終二進制字符串是從圖像序列而不是單個圖像中提取的,并且通過漢明距離進行匹配以進行識別。本文的想法來自我們之前關于大規模交通場景的工作[19]。我們的方法已經證明,它可以通過與其他最先進的方法(如FABMAP,ABLE-M或SeqSLAM)在季節、環境或視點發生極端變化的具有代表性的公共數據集上進行比較,成功地實現長期和大規模的視覺位置識別。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000
原文標題:基于CNN的長期和大規模環境中的視覺位置識別
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TF之CNN:CNN實現mnist數據集預測
LED獲得白色光的方法
有沒有其他方法在潘多拉開發板上能夠實現網絡播放功能
有沒有其他方法在潘多拉開發板上能夠實現網絡播放功能呢
有沒有其他方法可以訪問an5471設備上的引導加載程序呢?
有其他方法可以獲取設備rpmsg_sdb嗎?
基于卷積神經網絡CNN的車牌字符識別方法
基于CNN的圖文融合媒體的情感分析方法
在情感分析中使用知識的一些代表性工作
基于LSTM和CNN融合的深度神經網絡個人信用評分方法

實現關鍵性電流節省的其他方法是什么
新華三入選 “代表性中國數據庫廠商”
為什么傳統CNN在紋理分類數據集上的效果不好?






 工商網監
工商網監
評論