 一種新穎而高效的增強校準度量方法用于二值前景圖的評估
一種新穎而高效的增強校準度量方法用于二值前景圖的評估
圖像分割是以人眼識別為基礎,而人眼識別是從整體到局部的分割方式。本文首次提出了一種模擬人眼判別的新指標,結果遠優于現有方法,并證明其與人眼判別結果更加一致。
圖像分割往往是以人眼識別為基礎的,而人眼識別是從整體到局部的分割方式。本文從整體和局部兩個方向出發,提出了一種新穎而高效的增強校準度量方法(E-measure)用于二值前景圖的評估, 通過簡單地結合局部信息與全局信息得到了非常可靠的評價結果。
對于GT(GroundTruth,真值圖)與分割算法預測的FM (ForegroundMap,前景圖),圖像評價指標的意義即為計算FM與GT的相似度,為介于0-1之間的值(可以看作概率),1表示完全一樣,而0則根據不同的算法有不同的結果,認為是完全不一樣(或者與GT正好相反)。GT往往是研究人員手工標注的,
一般認為GT代表的是人眼分割的結果。而評價指標算法的目標,就是取得跟人眼進行圖像分類一樣的結果。而目前廣泛使用的IOU是基于局部信息的誤差度量(像素級別),而忽略了圖像的全局信息,從而導致其評估不準確。
E-measure是基于局部像素信息差別與全局均值信息的評估方法,我們在5個基準數據集上采用5個元度量證明了E-measure遠遠優于已有的度量方法,并且在我們提出的人眼排序數據集上取得了最好的結果,證明其與和人的主觀評價具有高度一致性。
問題引出:管中窺豹,只可見一斑
評價指標的合理與否對一個領域中模型的發展起到決定性的作用,現有的前景圖檢測中應用最廣泛的評價指標為IOU(Intersection-Over-Union,交并集),如圖1, IOU的公式可表示為公式1。
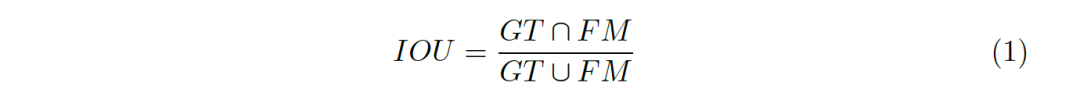
圖1:IOU的形象化表示
不難看出IOU是基于局部像素差異的評估方法,缺失了全局信息。如圖2所示,(d)中所示不過是噪聲圖,很明顯(c)中的圖與(b) 中GT更相似,而(d)實際上可能只與全白或者全黑的前景圖結果差不多,而對于全白或全黑圖,我們可以認為是不相似的(但是并非相似度值為0,事實上為0一般表示完全相反)。而在通過IOU算法的結果卻告訴我們,(d)比(c)更好!這顯然是不合理的。
圖2:不同類型前景圖FM的評價對比
只基于局部像素差異對計算機來說或許是有效的,但是不符合人眼分割圖像的機制。我們來實驗分析一個簡單的例子,如圖3,藍色范圍為GT,紅色為FM。可以看出,(a)和(b)的FM形狀差別很大,但是其與GT的交卻完全一樣,導致得到完全一樣的結果。
圖3:IOU簡單分析,藍色范圍為GT,紅色為檢FM,(a)與(b)中交集面積一樣
因為IOU只基于局部像素差異進行評估,導致其只能得到一個局部最優結果,而很難得到全面的評估結果。我們需要一個全面的,符合人眼視覺的評價指標。
解決方案:眼觀六路,耳聽八方
由于當前的評價指標都是考慮單個像素點的誤差,缺少全局信息的考量,從而導致評估不準確。為此,我們考慮將局部信息與全局信息結合進行度量。
圖4:(b)是原始圖像(a)的分割結果,Map1(c)和Map2(d)分別為兩個算法分割的結果
我們先來看一個例子,從圖4中兩個分割算法檢測的結果Map1和Map2中,我們判斷其結果與GT的相似度會考慮到全局的相似度,如整個鹿的身體部分。通過這一判斷,感知兩者的相似度差異較小。進而進行局部的細節判斷(見圖 5})。我們發現與Map1相比,Map2分割結果包含了更多細節(腳),從而,如圖 6所示,我們會認為Map2的的分割結果優于Map1。
圖5:(b)是原始圖像(a)的分割結果,Map1(c)和Map2(d)分別為兩個算法分割的結果
圖6:(b)是原始圖像(a)的分割結果,Map1(c)和Map2(d)分別為兩個算法分割的結果
1、結合全局信息與局部信息
我們考慮將圖像級的統計信息納入考量范圍,選擇全局的像素均值μ作為圖像級的統計信息,因為全局均值能代表圖像全局的信息而且計算簡單。如圖7中(c)(d)所示,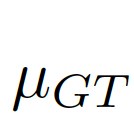
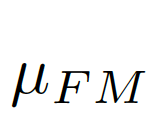
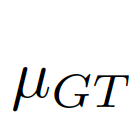 ,
,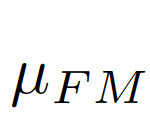 之差作為結合全局信息的偏差矩陣
之差作為結合全局信息的偏差矩陣
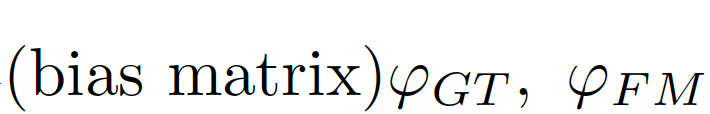
。
2、誤差估計
計算偏差矩陣(bias matrix)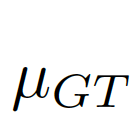
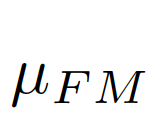
偏差矩陣為[0-1]之間的連續值,我們使用對齊矩陣(alignment matrix)ξ來評價偏差矩陣間的誤差:
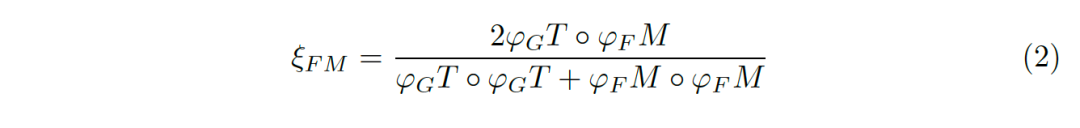
圖片7:結合全局信息與局部信息。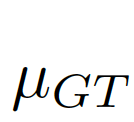
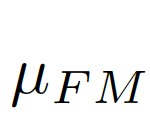
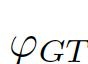 ,
,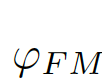 為結合全局信息與局部信息的偏差矩陣(bias matrix)
為結合全局信息與局部信息的偏差矩陣(bias matrix)
其中 為哈達瑪乘,分子
為哈達瑪乘,分子
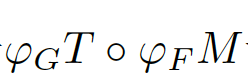
價誤差,而
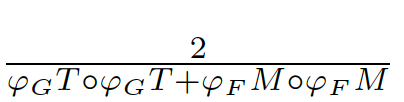
將評估結果縮放到[-1,1]之間,其中-1表示完全相反,而1表示完全相同。即對于每個包含全局信息的局部值誤差,我們可以計算出一個[-1,1]之間的誤差估計。
3、非線性變換
我們需要一個[0,1]之間的評價指標,因此需要將[-1,1]的值域縮放到[0,1]之間。對于一個隨機分類器輸出的二分類結果,即隨機生成的FM,其與GT的誤差應該是均勻的,即其誤差應該均勻地分布在[-1.1] 之間,這樣我們可以直接使用線性的變換將其值域縮放到[0,1](例如采用
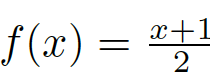
)。
但是事實上,所有的分類器應該都要比隨機分類器要好得多,也就是說許多方法的輸出FM都是與GT相似而極少相反,即評價得分絕大部分集中于[0,1]之間而只有極少部分出現在[-1,0],在此情況下繼續采用線性函數進行值域縮放就不再合適,因為這會導致絕大部分的結果集中到0.5以上的結果而導致缺乏區分度。其次,人眼評估的結果是評估FM與GT的相似度的,而非不相似度(或者負相似度),這也說明再使用線性縮放是不合適的。而簡單地將所有[-1,0]之間的值置為0(如神經網絡中非常著名的relu激活函數)會丟失一些評估結果,因此不可取。
基于上述分析,我們提出非線性的變換函數:
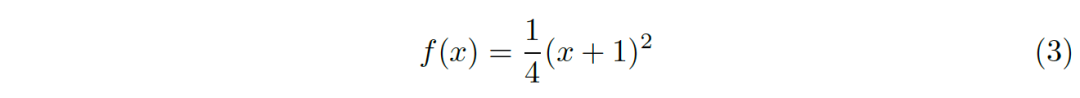
該函數其實只是對上述函數
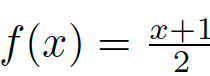
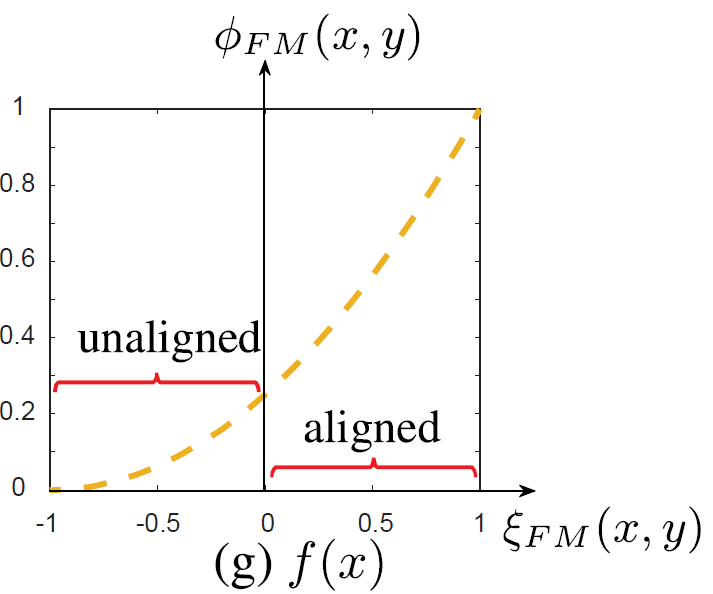
圖8:非線性變換函數,其將[-1,0]之間的值縮放到一個較小的范圍,而將[0,1]之間的值縮放到較大的范圍
4、綜合估計
我們將所有的誤差縮放到[0,1]之間,便得到符合范圍的誤差結果(4):
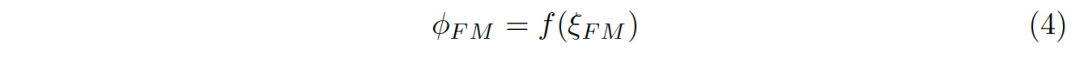
E-measure定義為所有位置誤差結果的綜合:
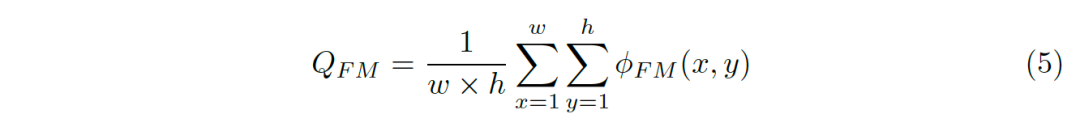
元度量實驗證明有效性
為了證明指標的有效性和可靠性,研究人員采用元度量的方法來進行實驗。通過提出一系列合理的假設,然后驗證指標符合這些假設的程度就可以得到指標的性能。簡而言之,元度量就是一種評測指標的指標。實驗采用了5個元度量:
元度量1:應用排序
推動模型發展的一個重要原因就是應用需求,因此一個指標的排序結果應該和應用的排序結果具有高度的一致性。即,將一系列前景圖輸入到應用程序中,由應用程序得到其標準前景圖的排序結果,一個優秀的評價指標得到的評價結果應該與其應用程序標準前景圖的排序結果具有高度一致性。如下圖9所示。
圖9
元度量2:最新水平 vs.通用結果
一個指標的評價原則應該傾向于選擇那些采用最先進算法得到的檢測結果而不是那些沒有考慮圖像內容的通用結果(例如中心高斯圖)。如下圖10所示。
圖10
元度量3:最新水平 vs.隨機結果
一個指標的評價原則應該傾向于選擇那些采用最先進算法得到的檢測結果而不是那些沒有考慮圖像內容的隨機結果(例如高斯噪聲圖)。如圖2所示。
元度量4:人工排序
人作為高級靈長類動物,擅長捕捉對象的結構,因此前景圖檢測的評價指標的排序結果,應該和人的主觀排序具有高度一致性。我們通過從所有數據集中按比例,通過人隨機選擇符合人眼排序的前景圖組,組成人工排序數據集FMDatabase。如下圖11所示。
圖11
元度量5:參考GT隨機替換
原來指標認定為檢測結果較好的模型,在參考的Ground-truth替換為錯誤的Ground-truth時,分數應該降低。如圖12所示。
圖12
實驗結果
本文在5個具有不同特點的、具有挑戰性數據集上進行了廣泛的測試,以驗證指標的穩定性、魯棒性。

圖13
實驗結果表明:我們的指標分別在PASCAL, ECSSD, SOD 和HKU-IS數據集上具有更強的魯棒性和穩定性。同時在FMDatabase(MM4)上,我們的指標也具有最好的結果。
-
圖像分割
+關注
關注
4文章
182瀏覽量
17977 -
數據集
+關注
關注
4文章
1205瀏覽量
24643
原文標題:【圖像分割里程碑】南開提出首個人眼模擬分割指標,性能當前最優
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
實例分析:分享一種新穎實用的異常信號捕獲方法
基于助聽器開發的一種高效的語音增強神經網絡
一種基于高效采樣算法的時序圖神經網絡系統介紹
一種基于圖聚類的安全態勢評估方法
一種新穎的精密陀螺電源

一種新穎、高效且易于計算的結構性度量來評估非二進制前景圖







 工商網監
工商網監
評論