 人工智能使用的數據集多存在性別歧視和種族主義
人工智能使用的數據集多存在性別歧視和種族主義
編者按:上個月,李飛飛曾推薦斯坦福學者發表在Nature上的一則短文,文章指出現在人工智能使用的數據集多存在性別歧視和種族主義:“醫生”是男性,“護士”是女性,維基百科人物詞條中只有18%是女性,而這些女性的事跡會被頻繁鏈接到男性事跡中。這個問題的解決辦法有兩個,一是規范數據集制作,二是開發納入約束機制的算法。本文介紹的Quicksilver就是其中的第一種方法。
生成示例:Andrej Karpathy
是的,你沒看錯,作為計算機視覺和深度學習領域的頂級專家之一,特斯拉人工智能與自動駕駛視覺總監,李飛飛高徒,維基百科沒有收錄Andrej Karpathy本人的詞條。
以下是Quicksilver為它編寫的詞條內容(英語直譯):
Andrej Karpathy是特斯拉研究員1,2,人工智能和深度學習領域的專家3,4。
Andrej Karpathy是加利福尼亞州斯坦福大學的計算機科學博士生,研究方向是用于語言建模的自然語言處理(NLP)和循環神經網絡(RNN)5。他主要在學術界工作,但去年9月,他作為研究科學家加入了特斯拉的人工智能部門OpenAI6。Karpathy的大部分研究都圍繞圖像識別和圖像理解7。他的Reddit用戶名badmephisto,同樣也是他的YouTube賬號名,來自他致力于解決的問題——魔方7。
事跡
如何實現完美自拍,基于200萬張圖像的研究——2015年10月30日 這些是Karpathy在研究中挑選出的頂級自拍圖像,原圖來自網絡。斯坦福大學計算機科學畢業生Andrej Karpathy使用來自網絡的200萬張自拍圖像,訓練了一個人工神經網絡,用來區分哪些是好自拍,哪些是差自拍。他的神經網絡包含1.4億個不同的參數,可以為輸入的數百萬張圖像輸出結果。他得出的結論是:自拍的好壞很大程度上取決于圖像風格,而不僅僅是人的外貌。10
特斯拉聘請深度學習專家Andrej Karpathy領導Autopilot——2017年6月21日 ……(略)
上任兩年后,特斯拉的Autopilot首席執行官辭職——2018年4月26日 ……(略)
引用
A.I. Researchers Leave Elon Musk Lab to Begin Robotics Start-UpNew York Times,2017-11-07
A.I. Researchers Are Making More Than $1 Million, Even at a NonprofitNew York Times,2018-04-19 ……
維基百科的問題
每當我們在Google上搜索著名人物時,維基百科通常是第一個彈出來的頁面。現如今,從查找作業資料的學生,到搜集資料的編輯記者,這個免費的數字百科全書已經成為各個年齡段的首選工具。但近期人們卻發現,維基百科也出現了令人不安的趨勢。
不少人指出,維基百科正顯示出性別歧視,簡而言之,即很多著名女性人物沒有她們的專屬頁面。以Mirian Adelson為例,她是一名多才多藝的醫生,一生發表過上百篇關于生理成癮和治療的研究論文,她在拉斯維加斯經營著一家備受矚目的藥物濫用診所,她也是以色列最大報紙的出版商、著名慈善家。但維基百科并沒有收錄她的詞條(8月4日更新后新增了)。
擁有相同遭遇的還有MIT MechE的部門的新負責人Evelyn Wang,她致力于為沙漠地區居民研究生成飲用水的設備。如果說維基百科在收錄女性詞條上更苛刻,但它其實對看似被“優待”的男性也不完全友好。研究人員統計了30000名計算機科學家,發現維基百科只收錄了其中的15%。
換言之,面對不斷更新的信息,維基百科在時效性和完備性上仍面對重大挑戰。
事實上,除了以上提及的缺漏現象,維基百科在現有詞條維護上也有些力不從心,以華盛頓大學校長Ana Mari Cauce為例。自從特朗普政府宣布啟動延遲兒童入境行動(DACA)以來,Cauce多次聲明華盛頓大學會繼續向移民學生提供各項福利,這在美國產生極大影響,但他的詞條內容卻遲遲沒有更新。
維基百科是學界重要的語料來源之一,但它卻展示出非常嚴重的滯后性和偏見,可想而知,我們不能指望用它來構建合理模型。
Quicksilver如何運作
從自然語言處理角度看,用模型自動生成維基百科風格詞條是可能的。對于這類問題,現在采取的普遍方法是多本文摘要:給定一組包含有關實體信息的參考文檔,生成實體的摘要。
前人的研究
其實早在十年前,Biadsy等人就已經嘗試過生成類似人物介紹,他們提出的算法是對源文本中的相關句子進行排序和剪切,然后再拼湊成最終文本。這樣做的優點是語句十分連貫,因為它們都由人類編寫。但它的局限也很大,就是機器只能組合人類寫過的內容,無法自己創作。
近年來,研究人員開始由上述提取式生成轉向抽象概括,這種技術使用神經語言模型來動態生成文本,缺點是模型為了“連貫性”會生成不少無意義內容。對此,斯坦福大學的See等人提出指針生成器網絡,它可以為抽象模型提供一個信息提取回退的選項,有機結合了提取式和抽象概括式兩種方法。
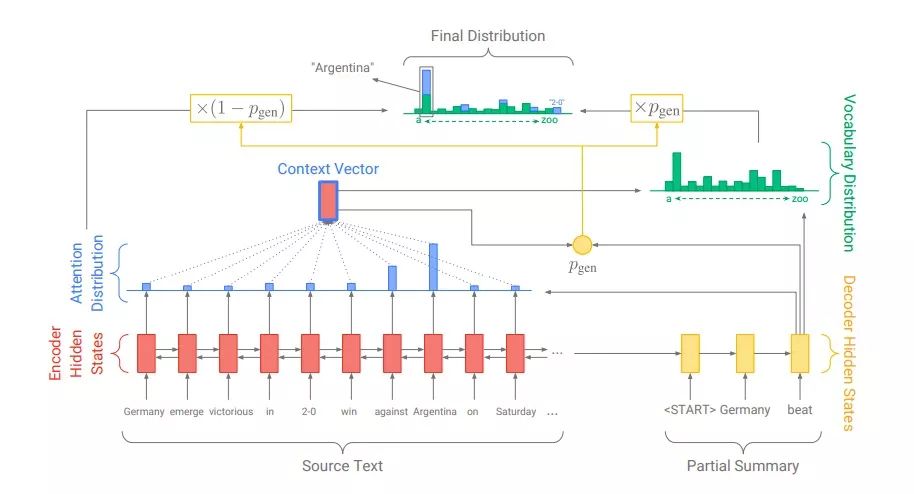
為了避免從源文本中引用重復內容,See等人提出的指針生成器網絡可以通過指向復制單詞,從固定詞匯表生成單詞,從而糾正提取式摘要的表述
基于上述研究,今年Google AI的Peter Liu團隊在ICLR上展示了一篇論文:Generating WIKIPEDIA by Summarizing Long Sequences。他們先把提取式摘要作為約束輸入文本的第一步,再對輸出文本進行抽樣概括,這樣做形成的文本非常驚艷,它們既保留了人類編寫的流暢性,也出現了大量模型“自創”的表述。
Quicksilver
Quicksilver是美國創業公司Primer開發的一款軟件,它沿用了Google AI的基礎架構,但目的更加簡單實在,就是開發一個可用于構建和維護維基百科等知識庫的系統,而不是將維基百科作為文本摘要算法的學術測試平臺。除了生成連貫文本,Quicksilver還需要能追蹤數據來源,以便最終輸出的任何語句都能指示其引用來源。
簡單來看,它的基本思路就是通過交叉引用維基百科詞條和從學術搜索引擎(文中稱為語義學者)中抽取的作者列表,來檢測其中和詞條人物有關的信息。提取這些信息并進行組合,最后用只包含一個解碼器的抽象概括模塊使輸出文本更連貫。
為了追求時效性,研究人員基于維基數據,制作了一個和seq2seq模型相結合的知識庫。對于了解科學家的生平事跡,使用維基數據的結構數據是一個關鍵突破,它既做到了映射新聞文檔,又可以通過添加遠程監督機制,讓知識庫實現自我更新。
以下是Quicksilver的具體流程:
目前,Quicksilver已經在3萬份科學家數據中經過訓練,并生成了40000余份維基百科風格的人物簡介,其中有多篇已被維基百科收錄。它也重點關照了女性詞條缺失的現象,在2小時內為70名女科學家更新了她們的詞條。
小結
維基百科的受歡迎程度和它對社會造成的影響息息相關,學界呼吁一個更具代表性的數據集,我們也期望一本剔除了不平等思維的百科全書。Quicksilver讓我們看到了用機器學習技術糾正偏見思維的可能性,這項研究不僅有助于把代表性不足的科學家群體置于燈光下,它也成了后期ML研究的一個光輝榜樣。
Quicksilver背后的算法不難理解,但它的設計依然非常復雜。除了學術上的啟示,從工業角度看,這種技術在中文維基百科和國內其他百科的維護上都有用武之地,值得進行嘗試。
-
算法
+關注
關注
23文章
4600瀏覽量
92646 -
人工智能
+關注
關注
1791文章
46866瀏覽量
237589 -
機器學習
+關注
關注
66文章
8378瀏覽量
132415
原文標題:告別歧視和偏見,用AI自動生成維基百科詞條
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論