 DMA控制器硬件結構與DMA通道使用的地址
DMA控制器硬件結構與DMA通道使用的地址
DMA是一種無需CPU的參與就可以讓外設和系統內存之間進行雙向數據傳輸的硬件機制。使用DMA可以使系統CPU從實際的I/O數據傳輸過程中擺脫出來,從而大大提高系統的吞吐率。DMA經常與硬件體系結構特別是外設的總線技術密切相關。
一、DMA控制器硬件結構
DMA允許外圍設備和主內存之間直接傳輸 I/O 數據, DMA 依賴于系統。每一種體系結構DMA傳輸不同,編程接口也不同。
數據傳輸可以以兩種方式觸發:一種軟件請求數據,另一種由硬件異步傳輸。
a --軟件請求數據
調用的步驟可以概括如下(以read為例):
(1)在進程調用 read 時,驅動程序的方法分配一個 DMA 緩沖區,隨后指示硬件傳送它的數據。進程進入睡眠。(2)硬件將數據寫入 DMA 緩沖區并在完成時產生一個中斷。
(3)中斷處理程序獲得輸入數據,應答中斷,最后喚醒進程,該進程現在可以讀取數據了。
b --由硬件異步傳輸
在 DMA 被異步使用時發生的。以數據采集設備為例:
(1)硬件發出中斷來通知新的數據已經到達。(2)中斷處理程序分配一個DMA緩沖區。(3)外圍設備將數據寫入緩沖區,然后在完成時發出另一個中斷。(4)處理程序利用DMA分發新的數據,喚醒任何相關進程。
網卡傳輸也是如此,網卡有一個循環緩沖區(通常叫做 DMA 環形緩沖區)建立在與處理器共享的內存中。每一個輸入數據包被放置在環形緩沖區中下一個可用緩沖區,并且發出中斷。然后驅動程序將網絡數據包傳給內核的其它部分處理,并在環形緩沖區中放置一個新的 DMA 緩沖區。
驅動程序在初始化時分配DMA緩沖區,并使用它們直到停止運行。
二、DMA通道使用的地址
DMA通道用dma_chan結構數組表示,這個結構在kernel/dma.c中,列出如下:
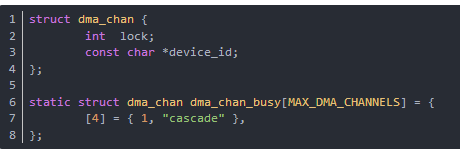
如果dma_chan_busy[n].lock != 0表示忙,DMA0保留為DRAM更新用,DMA4用作級聯。DMA 緩沖區的主要問題是,當它大于一頁時,它必須占據物理內存中的連續頁。
由于DMA需要連續的內存,因而在引導時分配內存或者為緩沖區保留物理 RAM 的頂部。在引導時給內核傳遞一個"mem="參數可以保留 RAM 的頂部。例如,如果系統有 32MB 內存,參數"mem=31M"阻止內核使用最頂部的一兆字節。稍后,模塊可以使用下面的代碼來訪問這些保留的內存:
dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
分配 DMA 空間的方法,代碼調用kmalloc(GFP_ATOMIC)直到失敗為止,然后它等待內核釋放若干頁面,接下來再一次進行分配。最終會發現由連續頁面組成的DMA 緩沖區的出現。
一個使用 DMA 的設備驅動程序通常會與連接到接口總線上的硬件通訊,這些硬件使用物理地址,而程序代碼使用虛擬地址。基于 DMA 的硬件使用總線地址而不是物理地址,有時,接口總線是通過將 I/O 地址映射到不同物理地址的橋接電路連接的。甚至某些系統有一個頁面映射方案,能夠使任意頁面在外圍總線上表現為連續的。
當驅動程序需要向一個 I/O 設備(例如擴展板或者DMA控制器)發送地址信息時,必須使用 virt_to_bus 轉換,在接受到來自連接到總線上硬件的地址信息時,必須使用 bus_to_virt 了。
三、DMA操作函數
寫一個DMA驅動的主要工作包括:DMA通道申請、DMA中斷申請、控制寄存器設置、掛入DMA等待隊列、清除DMA中斷、釋放DMA通道
因為 DMA 控制器是一個系統級的資源,所以內核協助處理這一資源。內核使用DMA 注冊表為 DMA 通道提供了請求/釋放機制,并且提供了一組函數在 DMA 控制器中配置通道信息。
以下具體分析關鍵函數(linux/arch/arm/mach-s3c2410/dma.c)

四、DMA映射
一個DMA映射就是分配一個 DMA 緩沖區并為該緩沖區生成一個能夠被設備訪問的地址的組合操作。一般情況下,簡單地調用函數virt_to_bus 就設備總線上的地址,但有些硬件映射寄存器也被設置在總線硬件中。映射寄存器(mapping register)是一個類似于外圍設備的虛擬內存等價物。在使用這些寄存器的系統上,外圍設備有一個相對較小的、專用的地址區段,可以在此區段執行 DMA。通過映射寄存器,這些地址被重映射到系統 RAM。映射寄存器具有一些好的特性,包括使分散的頁面在設備地址空間看起來是連續的。但不是所有的體系結構都有映射寄存器,特別地,PC 平臺沒有映射寄存器。
在某些情況下,為設備設置有用的地址也意味著需要構造一個反彈(bounce)緩沖區。例如,當驅動程序試圖在一個不能被外圍設備訪問的地址(一個高端內存地址)上執行 DMA 時,反彈緩沖區被創建。然后,按照需要,數據被復制到反彈緩沖區,或者從反彈緩沖區復制。
根據 DMA 緩沖區期望保留的時間長短,PCI 代碼區分兩種類型的 DMA 映射:
a -- 一致 DMA 映射
它們存在于驅動程序的生命周期內。一個被一致映射的緩沖區必須同時可被 CPU 和外圍設備訪問,這個緩沖區被處理器寫時,可立即被設備讀取而沒有cache效應,反之亦然,使用函數pci_alloc_consistent建立一致映射。
b -- 流式 DMA映射
流式DMA映射是為單個操作進行的設置。它映射處理器虛擬空間的一塊地址,以致它能被設備訪問。應盡可能使用流式映射,而不是一致映射。這是因為在支持一致映射的系統上,每個 DMA 映射會使用總線上一個或多個映射寄存器。具有較長生命周期的一致映射,會獨占這些寄存器很長時間――即使它們沒有被使用。使用函數dma_map_single建立流式映射。
1、建立一致 DMA 映射
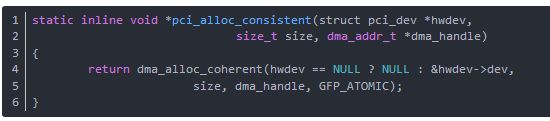
函數pci_alloc_consistent處理緩沖區的分配和映射,函數分析如下(在include/asm-generic/pci-dma-compat.h中):
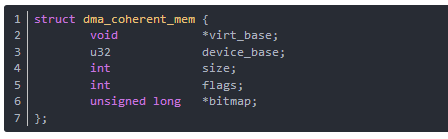
結構dma_coherent_mem定義了DMA一致性映射的內存的地址、大小和標識等。結構dma_coherent_mem列出如下(在arch/i386/kernel/pci-dma.c中):
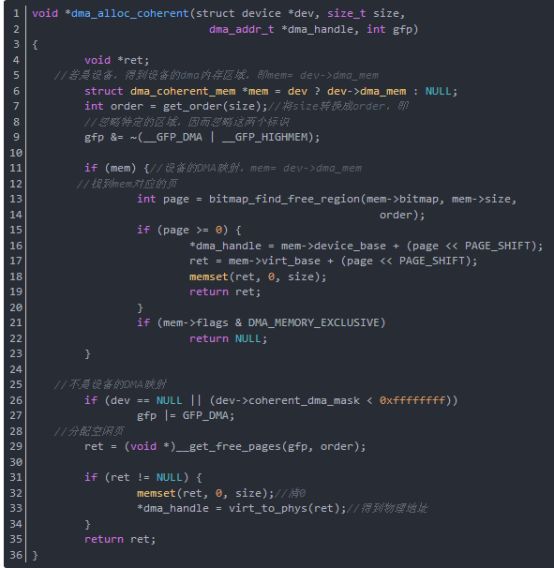
函數dma_alloc_coherent分配size字節的區域的一致內存,得到的dma_handle是指向分配的區域的地址指針,這個地址作為區域的物理基地址。dma_handle是與總線一樣的位寬的無符號整數。 函數dma_alloc_coherent分析如下(在arch/i386/kernel/pci-dma.c中):
當不再需要緩沖區時(通常在模塊卸載時),應該調用函數 pci_free_consitent 將它返還給系統。
2、建立流式 DMA 映射
在流式 DMA 映射的操作中,緩沖區傳送方向應匹配于映射時給定的方向值。緩沖區被映射后,它就屬于設備而不再屬于處理器了。在緩沖區調用函數pci_unmap_single撤銷映射之前,驅動程序不應該觸及其內容。
在緩沖區為 DMA 映射時,內核必須確保緩沖區中所有的數據已經被實際寫到內存。可能有些數據還會保留在處理器的高速緩沖存儲器中,因此必須顯式刷新。在刷新之后,由處理器寫入緩沖區的數據對設備來說也許是不可見的。
如果欲映射的緩沖區位于設備不能訪問的內存區段時,某些體系結構僅僅會操作失敗,而其它的體系結構會創建一個反彈緩沖區。反彈緩沖區是被設備訪問的獨立內存區域,反彈緩沖區復制原始緩沖區的內容。
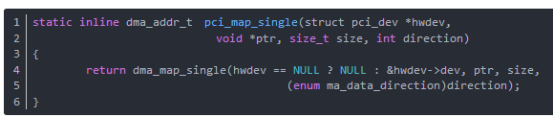
函數pci_map_single映射單個用于傳送的緩沖區,返回值是可以傳遞給設備的總線地址,如果出錯的話就為 NULL。一旦傳送完成,應該使用函數pci_unmap_single 刪除映射。其中,參數direction為傳輸的方向,取值如下:
PCI_DMA_TODEVICE 數據被發送到設備。PCI_DMA_FROMDEVICE如果數據將發送到 CPU。PCI_DMA_BIDIRECTIONAL數據進行兩個方向的移動。PCI_DMA_NONE 這個符號只是為幫助調試而提供。
函數pci_map_single分析如下(在arch/i386/kernel/pci-dma.c中)
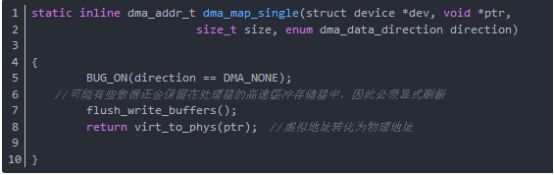
函數dma_map_single映射一塊處理器虛擬內存,這塊虛擬內存能被設備訪問,返回內存的物理地址,函數dma_map_single分析如下(在include/asm-i386/dma-mapping.h中):
3、分散/集中映射
分散/集中映射是流式 DMA 映射的一個特例。它將幾個緩沖區集中到一起進行一次映射,并在一個 DMA 操作中傳送所有數據。這些分散的緩沖區由分散表結構scatterlist來描述,多個分散的緩沖區的分散表結構組成緩沖區的struct scatterlist數組。
分散表結構列出如下(在include/asm-i386/scatterlist.h):
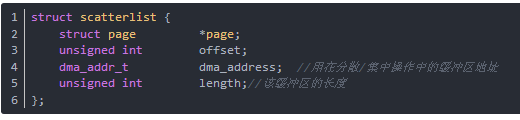
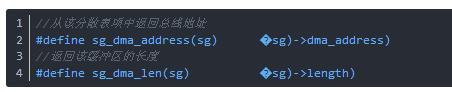
每一個緩沖區的地址和長度會被存儲在 struct scatterlist 項中,但在不同的體系結構中它們在結構中的位置是不同的。下面的兩個宏定義來解決平臺移植性問題,這些宏定義應該在一個pci_map_sg被調用后使用:
函數pci_map_sg完成分散/集中映射,其返回值是要傳送的 DMA 緩沖區數;它可能會小于 nents(也就是傳入的分散表項的數量),因為可能有的緩沖區地址上是相鄰的。一旦傳輸完成,分散/集中映射通過調用函數pci_unmap_sg 來撤銷映射。 函數pci_map_sg分析如下(在include/asm-generic/pci-dma-compat.h中):
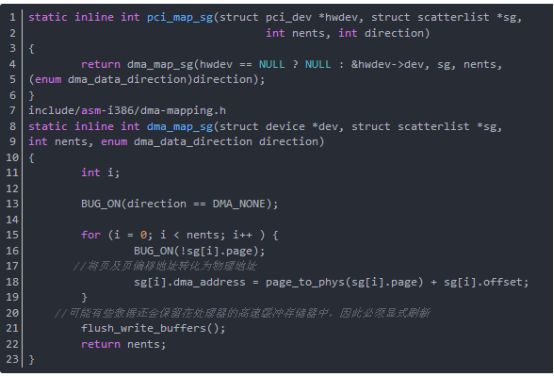
五、DMA池
許多驅動程序需要又多又小的一致映射內存區域給DMA描述子或I/O緩存buffer,這使用DMA池比用dma_alloc_coherent分配的一頁或多頁內存區域好,DMA池用函數dma_pool_create創建,用函數dma_pool_alloc從DMA池中分配一塊一致內存,用函數dmp_pool_free放內存回到DMA池中,使用函數dma_pool_destory釋放DMA池的資源。
結構dma_pool是DMA池描述結構,列出如下:
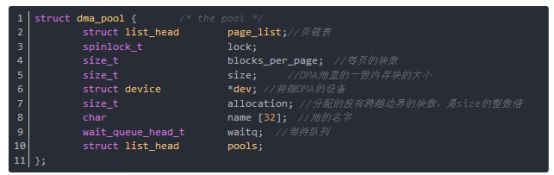
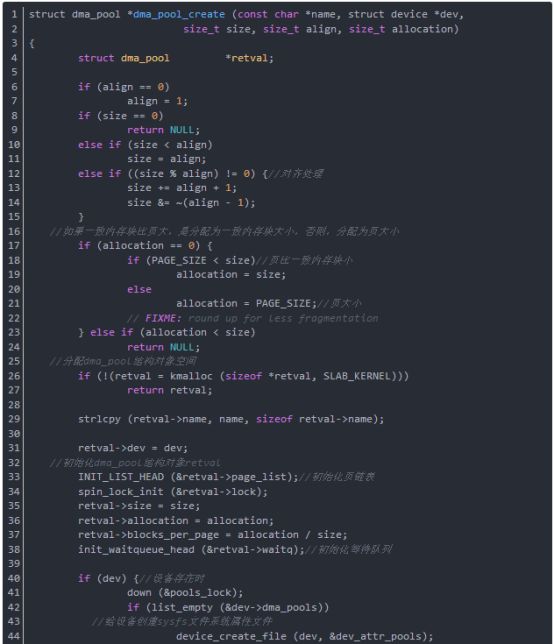
函數dma_pool_create給DMA創建一個一致內存塊池,其參數name是DMA池的名字,用于診斷用,參數dev是將做DMA的設備,參數size是DMA池里的塊的大小,參數align是塊的對齊要求,是2的冪,參數allocation返回沒有跨越邊界的塊數(或0)。
函數dma_pool_create返回創建的帶有要求字符串的DMA池,若創建失敗返回null。對被給的DMA池,函數dma_pool_alloc被用來分配內存,這些內存都是一致DMA映射,可被設備訪問,且沒有使用緩存刷新機制,因為對齊原因,分配的塊的實際尺寸比請求的大。如果分配非0的內存,從函數dma_pool_alloc返回的對象將不跨越size邊界(如不跨越4K字節邊界)。這對在個體的DMA傳輸上有地址限制的設備來說是有利的。
函數dma_pool_create分析如下(在drivers/base/dmapool.c中):
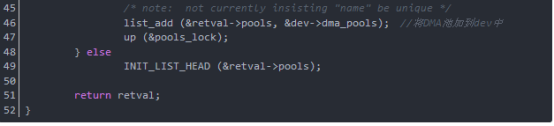
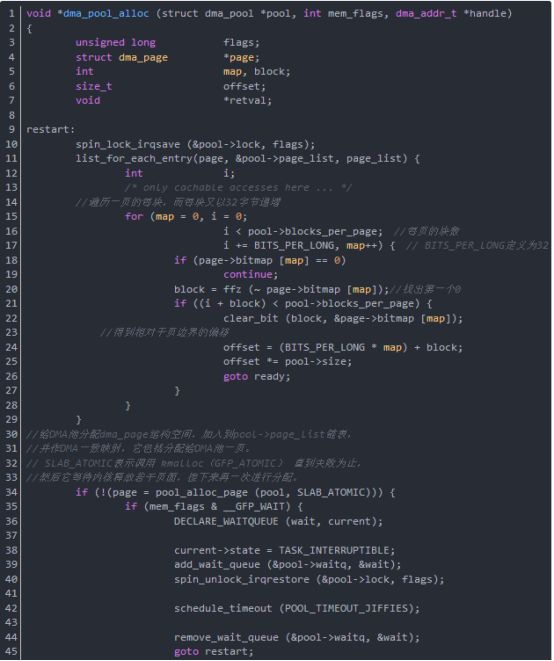
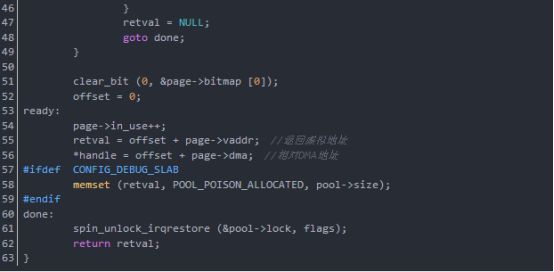
函數dma_pool_alloc從DMA池中分配一塊一致內存,其參數pool是將產生塊的DMA池,參數mem_flags是GFP_*位掩碼,參數handle是指向塊的DMA地址,函數dma_pool_alloc返回當前沒用的塊的內核虛擬地址,并通過handle給出它的DMA地址,如果內存塊不能被分配,返回null。
函數dma_pool_alloc包裹了dma_alloc_coherent頁分配器,這樣小塊更容易被總線的主控制器使用。這可能共享slab分配器的內容。
函數dma_pool_alloc分析如下(在drivers/base/dmapool.c中):
六、一個簡單的使用DMA 例子
示例:下面是一個簡單的使用DMA進行傳輸的驅動程序,它是一個假想的設備,只列出DMA相關的部分來說明驅動程序中如何使用DMA的。
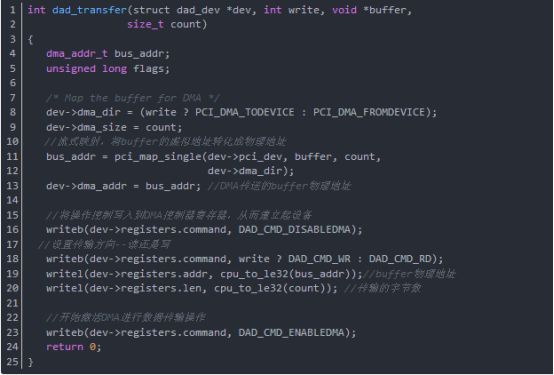
函數dad_transfer是設置DMA對內存buffer的傳輸操作函數,它使用流式映射將buffer的虛擬地址轉換到物理地址,設置好DMA控制器,然后開始傳輸數據。
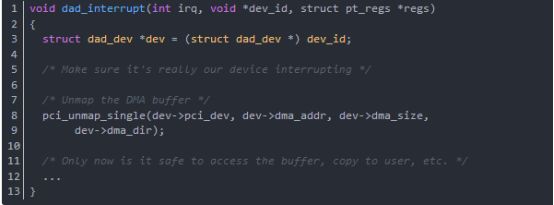
函數dad_interrupt是中斷處理函數,當DMA傳輸完時,調用這個中斷函數來取消buffer上的DMA映射,從而讓內核程序可以訪問這個buffer。
函數dad_open打開設備,此時應申請中斷號及DMA通道
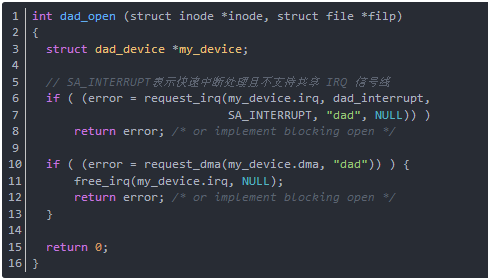
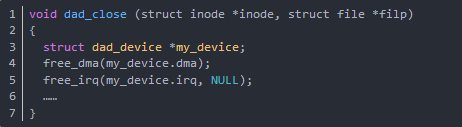
在與open 相對應的 close 函數中應該釋放DMA及中斷號。
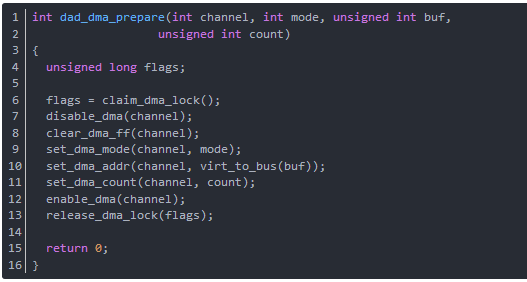
函數dad_dma_prepare初始化DMA控制器,設置DMA控制器的寄存器的值,為 DMA 傳輸作準備。
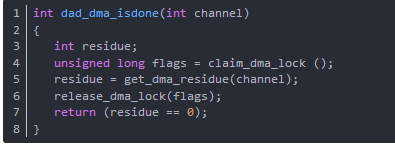
函數dad_dma_isdone用來檢查 DMA 傳輸是否成功結束。
-
控制器
+關注
關注
112文章
16214瀏覽量
177483 -
寄存器
+關注
關注
31文章
5325瀏覽量
120054 -
dma
+關注
關注
3文章
559瀏覽量
100447
原文標題:關于嵌入式Linux下的DMA技術,你需要知道的都在這里了
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ZYNQ開發案例之DMA控制器系統設計
DMA與DMA控制器
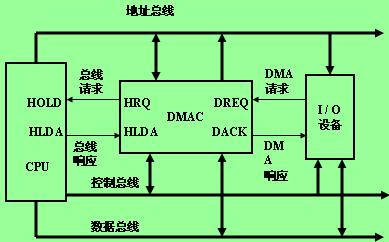
基于DMA控制器的UART串行通信設計

LED顯示系統DMA控制器的設計
實時圖像處理系統的DMA控制器設計
dma控制器芯片8257資料介紹
dma控制器由什么組成
基于SystemC的可配置多通道DMA控制器的設計
dma控制器的組成
MCU學習筆記_DMA原理

基于STM32F407的DMA解析-ADC單通道DMA讀取數據

Xilinx高性能PCIe DMA控制器IP,8個DMA通道





 工商網監
工商網監
評論