") 強(qiáng)化學(xué)習(xí)泡沫之后,人工智能的終極答案是什么?
強(qiáng)化學(xué)習(xí)泡沫之后,人工智能的終極答案是什么?
一、深度強(qiáng)化學(xué)習(xí)的泡沫
2015 年,DeepMind 的 Volodymyr Mnih 等研究員在《自然》雜志上發(fā)表論文 Human-level control through deep reinforcement learning[1],該論文提出了一個(gè)結(jié)合深度學(xué)習(xí)(DL)技術(shù)和強(qiáng)化學(xué)習(xí)(RL)思想的模型 Deep Q-Network(DQN),在 Atari 游戲平臺(tái)上展示出超越人類水平的表現(xiàn)。自此以后,結(jié)合 DL 與 RL 的深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, DRL)迅速成為人工智能界的焦點(diǎn)。
過去三年間,DRL 算法在不同領(lǐng)域大顯神通:在視頻游戲 [1]、棋類游戲上打敗人類頂尖高手 [2,3];控制復(fù)雜的機(jī)械進(jìn)行操作 [4];調(diào)配網(wǎng)絡(luò)資源 [5];為數(shù)據(jù)中心大幅節(jié)能 [6];甚至對(duì)機(jī)器學(xué)習(xí)算法自動(dòng)調(diào)參 [7]。各大高校和企業(yè)紛紛參與其中,提出了眼花繚亂的 DRL 算法和應(yīng)用。可以說,過去三年是 DRL 的爆紅期。DeepMind 負(fù)責(zé) AlphaGo 項(xiàng)目的研究員 David Silver 喊出“AI = RL + DL”,認(rèn)為結(jié)合了 DL 的表示能力與 RL 的推理能力的 DRL 將會(huì)是人工智能的終極答案。
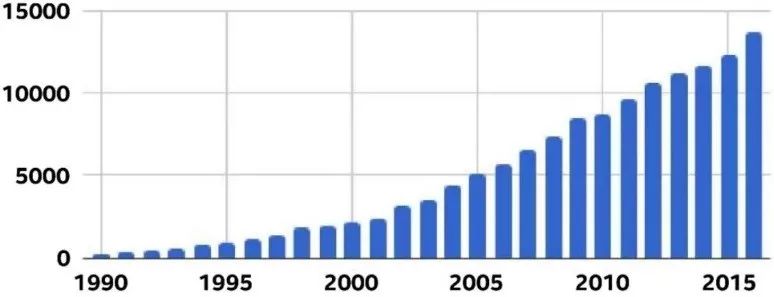
RL 論文數(shù)量迅速增長 [8]
1.1 DRL 的可復(fù)現(xiàn)性危機(jī)
然而,研究人員在最近半年開始了對(duì) DRL 的反思。由于發(fā)表的文獻(xiàn)中往往不提供重要參數(shù)設(shè)置和工程解決方案的細(xì)節(jié),很多算法都難以復(fù)現(xiàn)。2017 年 9 月,著名 RL 專家 Doina Precup 和 Joelle Pineau 所領(lǐng)導(dǎo)的的研究組發(fā)表了論文 Deep Reinforcement Learning that Matters[8],直指當(dāng)前 DRL 領(lǐng)域論文數(shù)量多卻水分大、實(shí)驗(yàn)難以復(fù)現(xiàn)等問題。該文在學(xué)術(shù)界和工業(yè)界引發(fā)熱烈反響。很多人對(duì)此表示認(rèn)同,并對(duì) DRL 的實(shí)際能力產(chǎn)生強(qiáng)烈懷疑。
其實(shí),這并非 Precup& Pineau 研究組第一次對(duì) DRL 發(fā)難。早在 2 個(gè)月前,該研究組就通過充足的實(shí)驗(yàn)對(duì)造成 DRL 算法難以復(fù)現(xiàn)的多個(gè)要素加以研究,并將研究成果撰寫成文 Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control[9]。同年 8 月,他們?cè)?ICML 2017 上作了題為“Reproducibility of Policy Gradient Methods for Continuous Control”的報(bào)告 [10],通過實(shí)例詳細(xì)展示了在復(fù)現(xiàn)多個(gè)基于策略梯度的算法的過程中,由于種種不確定性因素導(dǎo)致的復(fù)現(xiàn)困難。12 月,在萬眾矚目的 NIPS 2017 DRL 專題研討會(huì)上,Joelle Pineau 受邀作了題為“Reproducibility of DRL and Beyond”的報(bào)告 [11]。報(bào)告中,Pineau 先介紹了當(dāng)前科研領(lǐng)域的“可復(fù)現(xiàn)性危機(jī)” :在《自然》雜志的一項(xiàng)調(diào)查中,90% 的被訪者認(rèn)為“可復(fù)現(xiàn)性”問題是科研領(lǐng)域存在的危機(jī),其中,52% 的被訪者認(rèn)為這個(gè)問題很嚴(yán)重。在另一項(xiàng)調(diào)查中,不同領(lǐng)域的研究者幾乎都有很高的比例無法復(fù)現(xiàn)他人甚至自己過去的實(shí)驗(yàn)。可見“可復(fù)現(xiàn)性危機(jī)”有多么嚴(yán)峻!Pineau 針對(duì)機(jī)器學(xué)習(xí)領(lǐng)域發(fā)起的一項(xiàng)調(diào)研顯示,同樣有 90% 的研究者認(rèn)識(shí)到了這個(gè)危機(jī)。
機(jī)器學(xué)習(xí)領(lǐng)域存在嚴(yán)重的“可復(fù)現(xiàn)性危機(jī)”[11]
隨后,針對(duì) DRL 領(lǐng)域,Pineau 展示了該研究組對(duì)當(dāng)前不同 DRL 算法的大量可復(fù)現(xiàn)性實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,不同 DRL 算法在不同任務(wù)、不同超參數(shù)、不同隨機(jī)種子下的效果大相徑庭。在報(bào)告后半段,Pineau 呼吁學(xué)界關(guān)注“可復(fù)現(xiàn)性危機(jī)”這一問題,并根據(jù)她的調(diào)研結(jié)果,提出了 12 條檢驗(yàn)算法“可復(fù)現(xiàn)性”的準(zhǔn)則,宣布計(jì)劃在 ICLR 2018 開始舉辦“可復(fù)現(xiàn)實(shí)驗(yàn)挑戰(zhàn)賽”(“可復(fù)現(xiàn)危機(jī)”在其他機(jī)器學(xué)習(xí)領(lǐng)域也受到了關(guān)注,ICML 2017 已經(jīng)舉辦了 Reproducibility in Machine Learning Workshop,并將在今年繼續(xù)舉辦第二屆),旨在鼓勵(lì)研究者做出真正扎實(shí)的工作,抑制機(jī)器學(xué)習(xí)領(lǐng)域的泡沫。Pineau & Precup 研究組的這一系列研究獲得了廣泛關(guān)注。
Pineau 基于大量調(diào)查提出的檢驗(yàn)算法“可復(fù)現(xiàn)性”準(zhǔn)則 [11]
1.2 DRL 研究存在多少坑?
同樣在 12 月,Reddit 論壇上也開展了關(guān)于機(jī)器學(xué)習(xí)不正之風(fēng)的熱烈討論 [12]。有人點(diǎn)名指出,某些 DRL 代表性算法之所以在模擬器中取得了優(yōu)秀卻難以復(fù)現(xiàn)的表現(xiàn),是因?yàn)樽髡邆兩嫦釉趯?shí)驗(yàn)中修改模擬器的物理模型,卻在論文中對(duì)此避而不談。
對(duì)現(xiàn)有 DRL 算法的批判浪潮仍舊不斷涌來。2018 年的情人節(jié)當(dāng)天,曾經(jīng)就讀于伯克利人工智能研究實(shí)驗(yàn)室(Berkeley Artificial Intelligence Research Lab, BAIR)的 Alexirpan 通過一篇博文 Deep Reinforcement Learning Doesn't Work Yet[13] 給 DRL 圈送來了一份苦澀的禮物。他在文中通過多個(gè)例子,從實(shí)驗(yàn)角度總結(jié)了 DRL 算法存在的幾大問題:
樣本利用率非常低;
最終表現(xiàn)不夠好,經(jīng)常比不過基于模型的方法;
好的獎(jiǎng)勵(lì)函數(shù)難以設(shè)計(jì);
難以平衡“探索”和“利用”, 以致算法陷入局部極小;
對(duì)環(huán)境的過擬合;
災(zāi)難性的不穩(wěn)定性…
雖然作者在文章結(jié)尾試著提出 DRL 下一步應(yīng)該解決的一系列問題,很多人還是把這篇文章看做 DRL 的“勸退文”。幾天后,GIT 的博士生 Himanshu Sahni 發(fā)表博文 Reinforcement Learning never worked, and 'deep' only helped a bit 與之呼應(yīng) [14],在贊同 Alexirpan 的觀點(diǎn)同時(shí),指出好的獎(jiǎng)勵(lì)函數(shù)難以設(shè)計(jì)和難以平衡“探索”和“利用”以致算法陷入局部極小是 RL 的固有缺陷。
另一位 DRL 研究者 Matthew Rahtz 則通過講述自己試圖復(fù)現(xiàn)一個(gè) DRL 算法的坎坷歷程來回應(yīng) Alexirpan,讓大家深刻體會(huì)了復(fù)現(xiàn) DRL 算法有多么難 [15]。半年前,Rahtz 出于研究興趣,選擇對(duì) OpenAI 的論文 Deep Reinforcement Learning from Human Preferences 進(jìn)行復(fù)現(xiàn)。在復(fù)現(xiàn)的過程中,幾乎踩了 Alexirpan 總結(jié)的所有的坑。他認(rèn)為復(fù)現(xiàn) DRL 算法與其是一個(gè)工程問題,更不如說像一個(gè)數(shù)學(xué)問題。“它更像是你在解決一個(gè)謎題,沒有規(guī)律可循,唯一的方法是不斷嘗試,直到靈感出現(xiàn)徹底搞明白。……很多看上去無關(guān)緊要的小細(xì)節(jié)成了唯一的線索……做好每次卡住好幾周的準(zhǔn)備。”Rahtz 在復(fù)現(xiàn)的過程中積累了很多寶貴的工程經(jīng)驗(yàn),但整個(gè)過程的難度還是讓他花費(fèi)了大量的金錢以及時(shí)間。他充分調(diào)動(dòng)不同的計(jì)算資源,包括學(xué)校的機(jī)房資源、Google 云計(jì)算引擎和 FloydHub,總共花費(fèi)高達(dá) 850 美元。可就算這樣,原定于 3 個(gè)月完成的項(xiàng)目,最終用了 8 個(gè)月,其中大量時(shí)間用在調(diào)試上。
復(fù)現(xiàn) DRL 算法的實(shí)際時(shí)間遠(yuǎn)多于預(yù)計(jì)時(shí)間 [15]
Rahtz 最終實(shí)現(xiàn)了復(fù)現(xiàn)論文的目標(biāo)。他的博文除了給讀者詳細(xì)總結(jié)了一路走來的各種寶貴工程經(jīng)驗(yàn),更讓大家從一個(gè)具體事例感受到了 DRL 研究實(shí)際上存在多大的泡沫、有多少的坑。有人評(píng)論到,“DRL 的成功可能不是因?yàn)槠湔娴挠行В且驗(yàn)槿藗兓舜罅狻!?/p>
很多著名學(xué)者也紛紛加入討論。目前普遍的觀點(diǎn)是,DRL 可能有 AI 領(lǐng)域最大的泡沫。機(jī)器學(xué)習(xí)專家 Jacob Andreas 發(fā)了一條意味深長的 tweet 說:
Jacob Andreas 對(duì) DRL 的吐槽
DRL 的成功歸因于它是機(jī)器學(xué)習(xí)界中唯一一種允許在測試集上訓(xùn)練的方法。
從 Pineau & Precup 打響第一槍到現(xiàn)在的 1 年多時(shí)間里,DRL 被錘得千瘡百孔,從萬眾矚目到被普遍看衰。就在筆者準(zhǔn)備投稿這篇文章的時(shí)候,Pineau 又受邀在 ICLR 2018 上作了一個(gè)題為 Reproducibility, Reusability, and Robustness in DRL 的報(bào)告 [16],并且正式開始舉辦“可復(fù)現(xiàn)實(shí)驗(yàn)挑戰(zhàn)賽”。看來學(xué)界對(duì) DRL 的吐槽將會(huì)持續(xù),負(fù)面評(píng)論還將持續(xù)發(fā)酵。那么, DRL 的問題根結(jié)在哪里?前景真的如此黯淡嗎?如果不與深度學(xué)習(xí)結(jié)合,RL 的出路又在哪里?
在大家紛紛吐槽 DRL 的時(shí)候,著名的優(yōu)化專家 Ben Recht,從另一個(gè)角度給出一番分析。
二、免模型強(qiáng)化學(xué)習(xí)的本質(zhì)缺陷
RL 算法可以分為基于模型的方法(Model-based)與免模型的方法(Model-free)。前者主要發(fā)展自最優(yōu)控制領(lǐng)域。通常先通過高斯過程(GP)或貝葉斯網(wǎng)絡(luò)(BN)等工具針對(duì)具體問題建立模型,然后再通過機(jī)器學(xué)習(xí)的方法或最優(yōu)控制的方法,如模型預(yù)測控制(MPC)、線性二次調(diào)節(jié)器(LQR)、線性二次高斯(LQG)、迭代學(xué)習(xí)控制(ICL)等進(jìn)行求解。而后者更多地發(fā)展自機(jī)器學(xué)習(xí)領(lǐng)域,屬于數(shù)據(jù)驅(qū)動(dòng)的方法。算法通過大量采樣,估計(jì)代理的狀態(tài)、動(dòng)作的值函數(shù)或回報(bào)函數(shù),從而優(yōu)化動(dòng)作策略。
基于模型 vs. 免模型 [17]
從年初至今,Ben Recht 連發(fā)了 13 篇博文,從控制與優(yōu)化的視角,重點(diǎn)探討了 RL 中的免模型方法 [18]。Recht 指出免模型方法自身存在以下幾大缺陷:
免模型方法無法從不帶反饋信號(hào)的樣本中學(xué)習(xí),而反饋本身就是稀疏的,因此免模型方向樣本利用率很低,而數(shù)據(jù)驅(qū)動(dòng)的方法則需要大量采樣。比如在 Atari 平臺(tái)上的《Space Invader》和《Seaquest》游戲中,智能體所獲得的分?jǐn)?shù)會(huì)隨訓(xùn)練數(shù)據(jù)增加而增加。利用免模型 DRL 方法可能需要 2 億幀畫面才能學(xué)到比較好的效果。AlphaGo 最早在 Nature 公布的版本也需要 3000 萬個(gè)盤面進(jìn)行訓(xùn)練。而但凡與機(jī)械控制相關(guān)的問題,訓(xùn)練數(shù)據(jù)遠(yuǎn)不如視頻圖像這樣的數(shù)據(jù)容易獲取,因此只能在模擬器中進(jìn)行訓(xùn)練。而模擬器與現(xiàn)實(shí)世界間的 Reality Gap,直接限制了訓(xùn)練自其中算法的泛化性能。另外,數(shù)據(jù)的稀缺性也影響了其與 DL 技術(shù)的結(jié)合。
免模型方法不對(duì)具體問題進(jìn)行建模,而是嘗試用一個(gè)通用的算法解決所有問題。而基于模型的方法則通過針對(duì)特定問題建立模型,充分利用了問題固有的信息。免模型方法在追求通用性的同時(shí)放棄這些富有價(jià)值的信息。
基于模型的方法針對(duì)問題建立動(dòng)力學(xué)模型,這個(gè)模型具有解釋性。而免模型方法因?yàn)闆]有模型,解釋性不強(qiáng),調(diào)試?yán)щy。
相比基于模型的方法,尤其是基于簡單線性模型的方法,免模型方法不夠穩(wěn)定,在訓(xùn)練中極易發(fā)散。
為了證實(shí)以上觀點(diǎn),Recht 將一個(gè)簡單的基于 LQR 的隨機(jī)搜索方法與最好的免模型方法在 MuJoCo 實(shí)驗(yàn)環(huán)境上進(jìn)行了實(shí)驗(yàn)對(duì)比。在采樣率相近的情況下,基于模型的隨機(jī)搜索算法的計(jì)算效率至少比免模型方法高 15 倍 [19]。

基于模型的隨機(jī)搜索方法 ARS 吊打一眾免模型方法 [19]
通過 Recht 的分析,我們似乎找到了 DRL 問題的根結(jié)。近三年在機(jī)器學(xué)習(xí)領(lǐng)域大火的 DRL 算法,多將免模型方法與 DL 結(jié)合,而免模型算法的天然缺陷,恰好與 Alexirpan 總結(jié)的 DRL 幾大問題相對(duì)應(yīng)(見上文)。
看來,DRL 的病根多半在采用了免模型方法上。為什么多數(shù) DRL 的工作都是基于免模型方法呢?筆者認(rèn)為有幾個(gè)原因。第一,免模型的方法相對(duì)簡單直觀,開源實(shí)現(xiàn)豐富,比較容易上手,從而吸引了更多的學(xué)者進(jìn)行研究,有更大可能做出突破性的工作,如 DQN 和 AlphaGo 系列。第二,當(dāng)前 RL 的發(fā)展還處于初級(jí)階段,學(xué)界的研究重點(diǎn)還是集中在環(huán)境是確定的、靜態(tài)的,狀態(tài)主要是離散的、靜態(tài)的、完全可觀察的,反饋也是確定的問題(如 Atari 游戲)上。針對(duì)這種相對(duì)“簡單”、基礎(chǔ)、通用的問題,免模型方法本身很合適。最后,在“AI = RL + DL”這一觀點(diǎn)的鼓動(dòng)下,學(xué)界高估了 DRL 的能力。DQN 展示出的令人興奮的能力使得很多人圍繞著 DQN 進(jìn)行拓展,創(chuàng)造出了一系列同樣屬于免模型的工作。
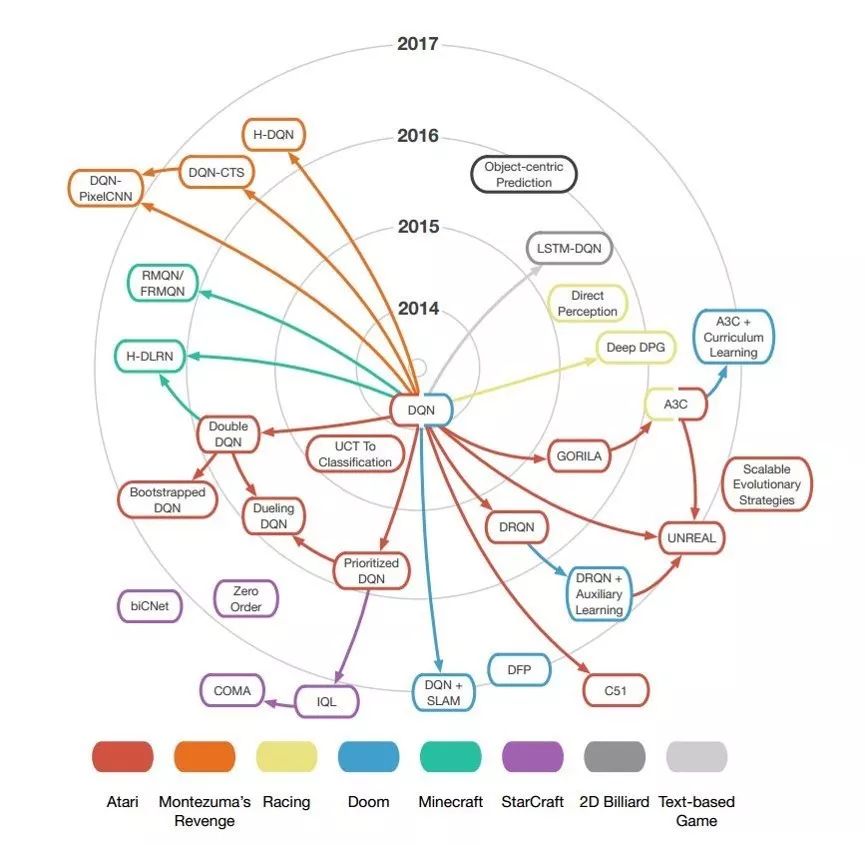
絕大多數(shù) DRL 方法是對(duì) DQN 的擴(kuò)展,屬于免模型方法 [20]
那么,DRL 是不是應(yīng)該拋棄免模型方法,擁抱基于模型的方法呢?
三、基于模型或免模型,問題沒那么簡單
3.1 基于模型的方法,未來潛力巨大
基于模型的方法一般先從數(shù)據(jù)中學(xué)習(xí)模型,然后基于學(xué)到的模型對(duì)策略進(jìn)行優(yōu)化。學(xué)習(xí)模型的過程和控制論中的系統(tǒng)參數(shù)辨識(shí)類似。因?yàn)槟P偷拇嬖冢谀P偷姆椒梢猿浞掷妹恳粋€(gè)樣本來逼近模型,數(shù)據(jù)利用率極大提高。基于模型的方法則在一些控制問題中,相比于免模型方法,通常有 10^2 級(jí)的采樣率提升。此外,學(xué)到的模型往往對(duì)環(huán)境的變化魯棒, 當(dāng)遇到新環(huán)境時(shí),算法可以依靠已學(xué)到的模型做推理,具有很好的泛化性能。
基于模型的方法具有更高采樣率 [22]
此外,基于模型的方法還與潛力巨大的預(yù)測學(xué)習(xí)(Predictive Learning)緊密相關(guān)。由于建立了模型,本身就可以通過模型預(yù)測未來,這與 Predictive Learning 的需求不謀而合。其實(shí),Yann LeCun 在廣受關(guān)注的 NIPS 2016 主題報(bào)告上介紹 Predictive Learning 時(shí),也是以基于模型的方法作為例子的 [21]。筆者認(rèn)為,基于模型的 RL 方法可能是實(shí)現(xiàn) Predictive Learning 的重要技術(shù)之一。
這樣看來,基于模型的方法似乎更有前途。但天下沒有免費(fèi)的午餐,模型的存在也帶來了若干問題。
3.2 免模型方法,依舊是第一選擇
基于模型的 DRL 方法相對(duì)而言不那么簡單直觀,RL 與 DL 的結(jié)合方式相對(duì)更復(fù)雜,設(shè)計(jì)難度更高。目前基于模型的 DRL 方法通常用高斯過程、貝葉斯網(wǎng)絡(luò)或概率神經(jīng)網(wǎng)絡(luò)(PNN)來構(gòu)建模型,典型的如 David Silver 在 2016 年提出的 Predictron 模型 [23]。另外一些工作,如 Probabilistic Inference for Learning COntrol (PILCO)[24],本身不基于神經(jīng)網(wǎng)絡(luò),不過有與 BN 結(jié)合的擴(kuò)展版本。而 Guided Policy Search (GPS) 雖然在最優(yōu)控制器的優(yōu)化中使用了神經(jīng)網(wǎng)絡(luò),但模型并不依賴神經(jīng)網(wǎng)絡(luò) [25]。此外還有一些模型將神經(jīng)網(wǎng)絡(luò)與模型耦合在一起 [26]。這些工作不像免模型 DRL 方法那樣直觀且自然,DL 所起的作用也各有不同。
除此之外,基于模型的方法也還存在若干自身缺陷:
針對(duì)無法建模的問題束手無策。有些領(lǐng)域,比如 NLP,存在大量難以歸納成模型的任務(wù)。在這種場景下,只能通過諸如 R-max 算法這樣的方法先與環(huán)境交互,計(jì)算出一個(gè)模型為后續(xù)使用。但是這種方法的復(fù)雜度一般很高。近期有一些工作結(jié)合預(yù)測學(xué)習(xí)建立模型,部分地解決了建模難的問題,這一思路逐漸成為了研究熱點(diǎn)。
建模會(huì)帶來誤差,而且誤差往往隨著算法與環(huán)境的迭代交互越來越大,使得算法難以保證收斂到最優(yōu)解。
模型缺乏通用性,每次換一個(gè)問題,就要重新建模。
針對(duì)以上幾點(diǎn),免模型方法都有相對(duì)優(yōu)勢:對(duì)現(xiàn)實(shí)中非常多的無法建模的問題以及模仿學(xué)習(xí)問題,免模型算法仍是最好的選擇。并且,免模型方法在理論上具備漸近收斂性,經(jīng)過無數(shù)次與環(huán)境的交互可以保證得到最優(yōu)解,這是基于模型的方法很難獲得的結(jié)果。最后,免模型最大的優(yōu)勢就是具備非常好的通用性。事實(shí)上,在處理真正困難的問題時(shí),免模型方法的效果通常更好。Recht 也在博文中指出,控制領(lǐng)域很有效的 MPC 算法其實(shí)與 Q-Learning 這樣的免模型方法非常相關(guān) [18]。
基于模型的方法與免模型的方法的區(qū)別其實(shí)也可以看做基于知識(shí)的方法與基于統(tǒng)計(jì)的方法的區(qū)別。總體來講,兩種方法各有千秋,很難說其中一種方法優(yōu)于另一種。在 RL 領(lǐng)域中,免模型算法只占很少一部分,但基于歷史原因,當(dāng)前免模型的 DRL 方法發(fā)展迅速數(shù)量龐大,而基于模型的 DRL 方法則相對(duì)較少。筆者認(rèn)為,我們可以考慮多做一些基于模型的 DRL 方面的工作,克服當(dāng)前 DRL 存在的諸多問題。此外,還可以多研究結(jié)合基于模型方法與免模型方法的半模型方法,兼具兩種方法的優(yōu)勢。這方面經(jīng)典的工作有 RL 泰斗 Rich Sutton 提出的 Dyna 框架 [27] 和其弟子 David Silver 提出的 Dyna-2 框架 [28]。
通過以上討論,我們似乎對(duì) DRL 目前的困境找到了出路。但其實(shí),造成當(dāng)前 DRL 困境的原因遠(yuǎn)不止這些。
3.3 不僅僅是模型與否的問題
上文提到 Recht 使用基于隨機(jī)搜索的方法吊打了免模型方法,似乎宣判了免模型方法的死刑。但其實(shí)這個(gè)對(duì)比并不公平。
2017 年 3 月,機(jī)器學(xué)習(xí)專家 Sham Kakade 的研究組發(fā)表文章 Towards Generalization and Simplicity in Continuous Control,試圖探尋針對(duì)連續(xù)控制問題的簡單通用的解法 [29] 。他們發(fā)現(xiàn)當(dāng)前的模擬器存在非常大的問題,經(jīng)過調(diào)試的線性策略就已經(jīng)可以取得非常好的效果——這樣的模擬器實(shí)在過于粗糙,難怪基于隨機(jī)搜索的方法可以在同樣的模擬器上戰(zhàn)勝免模型方法!
可見目前 RL 領(lǐng)域的實(shí)驗(yàn)平臺(tái)還非常不成熟,在這樣的測試環(huán)境中的實(shí)驗(yàn)實(shí)驗(yàn)結(jié)果沒有足夠的說服力。很多研究結(jié)論都未必可信,因?yàn)楹眯阅艿娜〉没蛟S僅僅是因?yàn)槔昧四M器的 bugs。此外,一些學(xué)者指出當(dāng)前 RL 算法的性能評(píng)判準(zhǔn)則也不科學(xué)。Ben Recht 和 Sham Kakade 都對(duì) RL 的發(fā)展提出了多項(xiàng)具體建議,包括測試環(huán)境、基準(zhǔn)算法、衡量標(biāo)準(zhǔn)等 [18,29]。可見 RL 領(lǐng)域還有太多需要改進(jìn)和規(guī)范化。
那么,RL 接下來該如何突破呢?
四、重新審視強(qiáng)化學(xué)習(xí)
對(duì) DRL 和免模型 RL 的質(zhì)疑與討論,讓我們可以重新審視 RL,這對(duì) RL 今后的發(fā)展大有裨益。
4.1 重新審視 DRL 的研究與應(yīng)用
DQN 和 AlphaGo 系列工作給人留下深刻印象,但是這兩種任務(wù)本質(zhì)上其實(shí)相對(duì)“簡單”。因?yàn)檫@些任務(wù)的環(huán)境是確定的、靜態(tài)的,狀態(tài)主要是離散的、靜態(tài)的、完全可觀察的,反饋是確定的,代理也是單一的。目前 DRL 在解決部分可見狀態(tài)任務(wù)(如 StarCraft),狀態(tài)連續(xù)的任務(wù)(如機(jī)械控制任務(wù)),動(dòng)態(tài)反饋任務(wù)和多代理任務(wù)中還沒取得令人驚嘆的突破。
DRL 取得成功的任務(wù)本質(zhì)上相對(duì)簡單 [30]
當(dāng)前大量的 DRL 研究,尤其是應(yīng)用于計(jì)算機(jī)視覺領(lǐng)域任務(wù)的研究中,很多都是將計(jì)算機(jī)視覺的某一個(gè)基于 DL 的任務(wù)強(qiáng)行構(gòu)造成 RL 問題進(jìn)行求解,其結(jié)果往往不如傳統(tǒng)方法好。這樣的研究方式造成 DRL 領(lǐng)域論文數(shù)量暴增、水分巨大。作為 DRL 的研究者,我們不應(yīng)該找一個(gè) DL 任務(wù)強(qiáng)行將其 RL 化,而是應(yīng)該針對(duì)一些天然適合 RL 處理的任務(wù),嘗試通過引入 DL 來提升現(xiàn)有方法在目標(biāo)識(shí)別環(huán)節(jié)或函數(shù)逼近環(huán)節(jié)上的能力。
在計(jì)算機(jī)視覺任務(wù)中,通過結(jié)合 DL 獲得良好的特征表達(dá)或函數(shù)逼近是非常自然的思路。但在有些領(lǐng)域,DL 未必能發(fā)揮強(qiáng)大的特征提取作用,也未必被用于函數(shù)逼近。比如 DL 至今在機(jī)器人領(lǐng)域最多起到感知作用,而無法取代基于力學(xué)分析的方法。雖然有一些將 DRL 應(yīng)用于物體抓取等現(xiàn)實(shí)世界的機(jī)械控制任務(wù)上并取得成功的案例,如 QT-Opt[70],但往往需要大量的調(diào)試和訓(xùn)練時(shí)間。我們應(yīng)該清晰地認(rèn)識(shí) DRL 算法的應(yīng)用特點(diǎn):因?yàn)槠漭敵龅碾S機(jī)性,當(dāng)前的 DRL 算法更多地被用在模擬器而非真實(shí)環(huán)境中。而當(dāng)前具有實(shí)用價(jià)值且只需運(yùn)行于模擬器中的任務(wù)主要有三類,即視頻游戲、棋類游戲和自動(dòng)機(jī)器學(xué)習(xí)(AutoML,比如谷歌的 AutoML Vision)。
這并不是說 DRL 的應(yīng)用被困在模擬器中——如果能針對(duì)某一具體問題,解決模擬器與真實(shí)世界間的差異,則可以發(fā)揮 DRL 的強(qiáng)大威力。最近 Google 的研究員就針對(duì)四足機(jī)器人運(yùn)動(dòng)問題,通過大力改進(jìn)模擬器,使得在模擬器中訓(xùn)練的運(yùn)動(dòng)策略可以完美遷移到真實(shí)世界中,取得了令人驚艷的效果 [71]。不過,考慮到 RL 算法的不穩(wěn)定性,在實(shí)際應(yīng)用中不應(yīng)盲目追求端到端的解決方案,而可以考慮將特征提取(DL)與決策(RL)分開,從而獲得更好的解釋性與穩(wěn)定性。此外,模塊化 RL(將 RL 算法封裝成一個(gè)模塊)以及將 RL 與其他模型融合,將在實(shí)際應(yīng)用中有廣闊前景。而如何通過 DL 學(xué)習(xí)一個(gè)合適于作為 RL 模塊輸入的表示,也值得研究。
4.2 重新審視 RL 的研究
機(jī)器學(xué)習(xí)是個(gè)跨學(xué)科的研究領(lǐng)域,而 RL 則是其中跨學(xué)科性質(zhì)非常顯著的一個(gè)分支。RL 理論的發(fā)展受到生理學(xué)、神經(jīng)科學(xué)和最優(yōu)控制等領(lǐng)域的啟發(fā),現(xiàn)在依舊在很多相關(guān)領(lǐng)域被研究。在控制理論、機(jī)器人學(xué)、運(yùn)籌學(xué)、經(jīng)濟(jì)學(xué)等領(lǐng)域內(nèi)部,依舊有很多的學(xué)者投身 RL 的研究,類似的概念或算法往往在不同的領(lǐng)域被重新發(fā)明,起了不同的名字。
RL 的發(fā)展受到多個(gè)學(xué)科的影響 [31]
Princeton 大學(xué)著名的運(yùn)籌學(xué)專家 Warren Powell 曾經(jīng)寫了一篇題為 AI, OR and Control Theory: A Rosetta Stone for Stochastic Optimization 的文章,整理了 RL 中同一個(gè)概念、算法在 AI、OR(運(yùn)籌學(xué))和 Control Theory(控制理論)中各自對(duì)應(yīng)的名稱,打通了不同領(lǐng)域間的隔閡 [32] 。由于各種學(xué)科各自的特點(diǎn),不同領(lǐng)域的 RL 研究又獨(dú)具特色,這使得 RL 的研究可以充分借鑒不同領(lǐng)域的思想精華。
在這里,筆者根據(jù)自身對(duì) RL 的理解,試著總結(jié)一些值得研究的方向:
基于模型的方法。如上文所述,基于模型的方法不僅能大幅降低采樣需求,還可以通過學(xué)習(xí)任務(wù)的動(dòng)力學(xué)模型,為預(yù)測學(xué)習(xí)打下基礎(chǔ)。
提高免模型方法的數(shù)據(jù)利用率和擴(kuò)展性。這是免模型學(xué)習(xí)的兩處硬傷,也是 Rich Sutton 的終極研究目標(biāo)。這個(gè)領(lǐng)域很艱難,但是任何有意義的突破也將帶來極大價(jià)值。
更高效的探索策略(Exploration Strategies)。平衡“探索”與“利用”是 RL 的本質(zhì)問題,這需要我們?cè)O(shè)計(jì)更加高效的探索策略。除了若干經(jīng)典的算法如 Softmax、?-Greedy[1]、UCB[72] 和 Thompson Sampling[73] 等,近期學(xué)界陸續(xù)提出了大批新算法,如 Intrinsic Motivation [74]、Curiosity-driven Exploration[75]、Count-based Exploration [76] 等。其實(shí)這些“新”算法的思想不少早在 80 年代就已出現(xiàn) [77],而與 DL 的有機(jī)結(jié)合使它們重新得到重視。此外,OpenAI 與 DeepMind 先后提出通過在策略參數(shù) [78] 和神經(jīng)網(wǎng)絡(luò)權(quán)重 [79] 上引入噪聲來提升探索策略, 開辟了一個(gè)新方向。
與模仿學(xué)習(xí)(Imitation Learning, IL)結(jié)合。機(jī)器學(xué)習(xí)與自動(dòng)駕駛領(lǐng)域最早的成功案例 ALVINN[33] 就是基于 IL;當(dāng)前 RL 領(lǐng)域最頂級(jí)的學(xué)者 Pieter Abbeel 在跟隨 Andrew Ng 讀博士時(shí)候, 設(shè)計(jì)的通過 IL 控制直升機(jī)的算法 [34] 成為 IL 領(lǐng)域的代表性工作。2016 年,英偉達(dá)提出的端到端自動(dòng)駕駛系統(tǒng)也是通過 IL 進(jìn)行學(xué)習(xí) [68]。而 AlphaGo 的學(xué)習(xí)方式也是 IL。IL 介于 RL 與監(jiān)督學(xué)習(xí)之間,兼具兩者的優(yōu)勢,既能更快地得到反饋、更快地收斂,又有推理能力,很有研究價(jià)值。關(guān)于 IL 的介紹,可以參見 [35] 這篇綜述。
獎(jiǎng)賞塑形(Reward Shaping)。獎(jiǎng)賞即反饋,其對(duì) RL 算法性能的影響是巨大的。Alexirpan 的博文中已經(jīng)展示了沒有精心設(shè)計(jì)的反饋信號(hào)會(huì)讓 RL 算法產(chǎn)生多么差的結(jié)果。設(shè)計(jì)好的反饋信號(hào)一直是 RL 領(lǐng)域的研究熱點(diǎn)。近年來涌現(xiàn)出很多基于“好奇心”的 RL 算法和層級(jí) RL 算法,這兩類算法的思路都是在模型訓(xùn)練的過程中插入反饋信號(hào),從而部分地克服了反饋過于稀疏的問題。另一種思路是學(xué)習(xí)反饋函數(shù),這是逆強(qiáng)化學(xué)習(xí)(Inverse RL, IRL)的主要方式之一。近些年大火的 GAN 也是基于這個(gè)思路來解決生成建模問題, GAN 的提出者 Ian Goodfellow 也認(rèn)為 GAN 就是 RL 的一種方式 [36]。而將 GAN 于傳統(tǒng) IRL 結(jié)合的 GAIL[37] 已經(jīng)吸引了很多學(xué)者的注意。
RL 中的遷移學(xué)習(xí)與多任務(wù)學(xué)習(xí)。當(dāng)前 RL 的采樣效率極低,而且學(xué)到的知識(shí)不通用。遷移學(xué)習(xí)與多任務(wù)學(xué)習(xí)可以有效解決這些問題。通過將從原任務(wù)中學(xué)習(xí)的策略遷移至新任務(wù)中,避免了針對(duì)新任務(wù)從頭開始學(xué)習(xí),這樣可以大大降低數(shù)據(jù)需求,同時(shí)也提升了算法的自適應(yīng)能力。在真實(shí)環(huán)境中使用 RL 的一大困難在于 RL 的不穩(wěn)定性,一個(gè)自然的思路是通過遷移學(xué)習(xí)將在模擬器中訓(xùn)練好的穩(wěn)定策略遷移到真實(shí)環(huán)境中,策略在新環(huán)境中僅通過少量探索即可滿足要求。然而,這一研究領(lǐng)域面臨的一大問題就是現(xiàn)實(shí)鴻溝(Reality Gap),即模擬器的仿真環(huán)境與真實(shí)環(huán)境差異過大。好的模擬器不僅可以有效填補(bǔ)現(xiàn)實(shí)鴻溝,還同時(shí)滿足 RL 算法大量采樣的需求,因此可以極大促進(jìn) RL 的研究與開發(fā),如上文提到的 Sim-to-Real[71]。同時(shí),這也是 RL 與 VR 技術(shù)的一個(gè)結(jié)合點(diǎn)。近期學(xué)術(shù)界和工業(yè)界紛紛在這一領(lǐng)域發(fā)力。在自動(dòng)駕駛領(lǐng)域,Gazebo、EuroTruck Simulator、TORCS、Unity、Apollo、Prescan、Panosim 和 Carsim 等模擬器各具特色,而英特爾研究院開發(fā)的 CARLA 模擬器 [38] 逐漸成為業(yè)界研究的標(biāo)準(zhǔn)。其他領(lǐng)域的模擬器開發(fā)也呈現(xiàn)百花齊放之勢:在家庭環(huán)境模擬領(lǐng)域, MIT 和多倫多大學(xué)合力開發(fā)了功能豐富的 VirturalHome 模擬器;在無人機(jī)模擬訓(xùn)練領(lǐng)域,MIT 也開發(fā)了 Flight Goggles 模擬器。
提升 RL 的的泛化能力。機(jī)器學(xué)習(xí)最重要的目標(biāo)就是泛化能力, 而現(xiàn)有的 RL 方法大多在這一指標(biāo)上表現(xiàn)糟糕 [8],無怪乎 Jacob Andreas 會(huì)批評(píng) RL 的成功是來自“train on the test set”。這一問題已經(jīng)引起了學(xué)界的廣泛重視,研究者們?cè)噲D通過學(xué)習(xí)環(huán)境的動(dòng)力學(xué)模型 [80]、降低模型復(fù)雜度 [29] 或模型無關(guān)學(xué)習(xí) [81] 來提升泛化能力,這也促進(jìn)了基于模型的方法與元學(xué)習(xí)(Meta-Learning)方法的發(fā)展。BAIR 提出的著名的 Dex-Net 項(xiàng)目主要目標(biāo)就是構(gòu)建具有良好魯棒性、泛化能力的機(jī)器人抓取模型 [82],而 OpenAI 也于 2018 年 4 月組織了 OpenAI Retro Contest ,鼓勵(lì)參與者開發(fā)具有良好泛化能力的 RL 算法 [83]。
層級(jí) RL(Hierarchical RL, HRL)。周志華教授總結(jié) DL 成功的三個(gè)條件為:有逐層處理、有特征的內(nèi)部變化和有足夠的模型復(fù)雜度 [39]。而 HRL 不僅滿足這三個(gè)條件,而且具備更強(qiáng)的推理能力,是一個(gè)非常潛力的研究領(lǐng)域。目前 HRL 已經(jīng)在一些需要復(fù)雜推理的任務(wù)(如 Atari 平臺(tái)上的《Montezuma's Revenge》游戲)中展示了強(qiáng)大的學(xué)習(xí)能力 [40]。
與序列預(yù)測(Sequence Prediction)結(jié)合。Sequence Prediction 與 RL、IL 解決的問題相似又不相同。三者間有很多思想可以互相借鑒。當(dāng)前已有一些基于 RL 和 IL 的方法在 Sequence Prediction 任務(wù)上取得了很好的結(jié)果 [41,42,43]。這一方向的突破對(duì) Video Prediction 和 NLP 中的很多任務(wù)都會(huì)產(chǎn)生廣泛影響。
(免模型)方法探索行為的安全性(Safe RL)。相比于基于模型的方法,免模型方法缺乏預(yù)測能力,這使得其探索行為帶有更多不穩(wěn)定性。一種研究思路是結(jié)合貝葉斯方法為 RL 代理行為的不確定性建模,從而避免過于危險(xiǎn)的探索行為。此外,為了安全地將 RL 應(yīng)用于現(xiàn)實(shí)環(huán)境中,可以在模擬器中借助混合現(xiàn)實(shí)技術(shù)劃定危險(xiǎn)區(qū)域,通過限制代理的活動(dòng)空間約束代理的行為。
關(guān)系 RL。近期學(xué)習(xí)客體間關(guān)系從而進(jìn)行推理與預(yù)測的“關(guān)系學(xué)習(xí)”受到了學(xué)界的廣泛關(guān)注。關(guān)系學(xué)習(xí)往往在訓(xùn)練中構(gòu)建的狀態(tài)鏈,而中間狀態(tài)與最終的反饋是脫節(jié)的。RL 可以將最終的反饋回傳給中間狀態(tài),實(shí)現(xiàn)有效學(xué)習(xí),因而成為實(shí)現(xiàn)關(guān)系學(xué)習(xí)的最佳方式。2017 年 DeepMind 提出的 VIN[44] 和 Pridictron[23] 均是這方面的代表作。2018 年 6 月,DeepMind 又接連發(fā)表了多篇關(guān)系學(xué)習(xí)方向的工作如關(guān)系歸納偏置 [45]、關(guān)系 RL[46]、關(guān)系 RNN[47]、圖網(wǎng)絡(luò) [48] 和已經(jīng)在《科學(xué)》雜志發(fā)表的生成查詢網(wǎng)絡(luò)(Generative Query Network,GQN)[49]。這一系列引人注目的工作將引領(lǐng)關(guān)系 RL 的熱潮。
對(duì)抗樣本 RL。RL 被廣泛應(yīng)用于機(jī)械控制等領(lǐng)域,這些領(lǐng)域相比于圖像識(shí)別語音識(shí)別等等,對(duì)魯棒性和安全性的要求更高。因此針對(duì) RL 的對(duì)抗攻擊是一個(gè)非常重要的問題。近期有研究表明,會(huì)被對(duì)抗樣本操控,很多經(jīng)典模型如 DQN 等算法都經(jīng)不住對(duì)抗攻擊的擾動(dòng) [50,51]。
處理其他模態(tài)的輸入。在 NLP 領(lǐng)域,學(xué)界已經(jīng)將 RL 應(yīng)用于處理很多模態(tài)的數(shù)據(jù)上,如句子、篇章、知識(shí)庫等等。但是在計(jì)算機(jī)視覺領(lǐng)域,RL 算法主要還是通過神經(jīng)網(wǎng)絡(luò)提取圖像和視頻的特征,對(duì)其他模態(tài)的數(shù)據(jù)很少涉及。我們可以探索將 RL 應(yīng)用于其他模態(tài)的數(shù)據(jù)的方法,比如處理 RGB-D 數(shù)據(jù)和激光雷達(dá)數(shù)據(jù)等。一旦某一種數(shù)據(jù)的特征提取難度大大降低,將其與 RL 有機(jī)結(jié)合后都可能取得 AlphaGo 級(jí)別的突破。英特爾研究院已經(jīng)基于 CARLA 模擬器在這方面開展了一系列的工作。
4.3 重新審視 RL 的應(yīng)用
當(dāng)前的一種觀點(diǎn)是“RL 只能打游戲、下棋,其他的都做了”。而筆者認(rèn)為,我們不應(yīng)對(duì) RL 過于悲觀。其實(shí)能在視頻游戲與棋類游戲中超越人類,已經(jīng)證明了 RL 推理能力的強(qiáng)大。通過合理改進(jìn)后,有希望得到廣泛應(yīng)用。往往,從研究到應(yīng)用的轉(zhuǎn)化并不直觀。比如,IBM Watson? 系統(tǒng)以其對(duì)自然語言的理解能力和應(yīng)答能力聞名世界,曾在 2011 年擊敗人類選手獲得 Jeopardy! 冠軍。而其背后的支撐技術(shù)之一竟然是當(dāng)年 Gerald Tesauro 開發(fā) TD-Gammon 程序 [52] 時(shí)使用的 RL 技術(shù) [53]。當(dāng)年那個(gè)“只能用于”下棋的技術(shù),已經(jīng)在最好的問答系統(tǒng)中發(fā)揮不可或缺的作用了。今天的 RL 發(fā)展水平遠(yuǎn)高于當(dāng)年,我們?cè)趺茨軟]有信心呢?
強(qiáng)大的 IBM Watson?背后也有 RL 發(fā)揮核心作用
通過調(diào)查,我們可以發(fā)現(xiàn) RL 算法已經(jīng)在各個(gè)領(lǐng)域被廣泛使用:
控制領(lǐng)域。這是 RL 思想的發(fā)源地之一,也是 RL 技術(shù)應(yīng)用最成熟的領(lǐng)域。控制領(lǐng)域和機(jī)器學(xué)習(xí)領(lǐng)域各自發(fā)展了相似的思想、概念與技術(shù),可以互相借鑒。比如當(dāng)前被廣泛應(yīng)用的 MPC 算法就是一種特殊的 RL。在機(jī)器人領(lǐng)域,相比于 DL 只能用于感知,RL 相比傳統(tǒng)的法有自己的優(yōu)勢:傳統(tǒng)方法如 LQR 等一般基于圖搜索或概率搜索學(xué)習(xí)到一個(gè)軌跡層次的策略,復(fù)雜度較高,不適合用于做重規(guī)劃;而 RL 方法學(xué)習(xí)到的則是狀態(tài) - 動(dòng)作空間中的策略,具有更好的適應(yīng)性。
自動(dòng)駕駛領(lǐng)域。駕駛就是一個(gè)序列決策過程,因此天然適合用 RL 來處理。從 80 年代的 ALVINN、TORCS 到如今的 CARLA,業(yè)界一直在嘗試用 RL 解決單車輛的自動(dòng)駕駛問題以及多車輛的交通調(diào)度問題。類似的思想也廣泛地應(yīng)用在各種飛行器、水下無人機(jī)領(lǐng)域。
NLP 領(lǐng)域。相比于計(jì)算機(jī)視覺領(lǐng)域的任務(wù),NLP 領(lǐng)域的很多任務(wù)是多輪的,即需通過多次迭代交互來尋求最優(yōu)解(如對(duì)話系統(tǒng));而且任務(wù)的反饋信號(hào)往往需要在一系列決策后才能獲得(如機(jī)器寫作)。這樣的問題的特性自然適合用 RL 來解決,因而近年來 RL 被應(yīng)用于 NLP 領(lǐng)域中的諸多任務(wù)中,如文本生成、文本摘要、序列標(biāo)注、對(duì)話機(jī)器人(文字 / 語音)、機(jī)器翻譯、關(guān)系抽取和知識(shí)圖譜推理等等。成功的應(yīng)用案例也有很多,如對(duì)話機(jī)器人領(lǐng)域中 Yoshua Bengio 研究組開發(fā)的 MILABOT 的模型 [54]、Facebook 聊天機(jī)器人 [55] 等;機(jī)器翻譯領(lǐng)域 Microsoft Translator [56] 等。此外,在一系列跨越 NLP 與計(jì)算機(jī)視覺兩種模態(tài)的任務(wù)如 VQA、Image/Video Caption、Image Grounding、Video Summarization 等中,RL 技術(shù)也都大顯身手。
推薦系統(tǒng)與檢索系統(tǒng)領(lǐng)域。RL 中的 Bandits 系列算法早已被廣泛應(yīng)用于商品推薦、新聞推薦和在線廣告等領(lǐng)域。近年也有一系列的工作將 RL 應(yīng)用于信息檢索、排序的任務(wù)中 [57]。
金融領(lǐng)域。RL 強(qiáng)大的序列決策能力已經(jīng)被金融系統(tǒng)所關(guān)注。無論是華爾街巨頭摩根大通還是創(chuàng)業(yè)公司如 Kensho,都在其交易系統(tǒng)中引入了 RL 技術(shù)。
對(duì)數(shù)據(jù)的選擇。在數(shù)據(jù)足夠多的情況下,如何選擇數(shù)據(jù)來實(shí)現(xiàn)“快、好、省”地學(xué)習(xí),具有非常大的應(yīng)用價(jià)值。近期在這方面也涌現(xiàn)出一系列的工作,如 UCSB 的 Jiawei Wu 提出的 Reinforced Co-Training [58] 等。
通訊、生產(chǎn)調(diào)度、規(guī)劃和資源訪問控制等運(yùn)籌領(lǐng)域。這些領(lǐng)域的任務(wù)往往涉及“選擇”動(dòng)作的過程,而且?guī)?a target="_blank">標(biāo)簽數(shù)據(jù)難以取得,因此廣泛使用 RL 進(jìn)行求解。
關(guān)于 RL 的更全面的應(yīng)用綜述請(qǐng)參見文獻(xiàn) [59,60]。
雖然有上文列舉的諸多成功應(yīng)用,但我們依舊要認(rèn)識(shí)到,當(dāng)前 RL 的發(fā)展還處于初級(jí)階段,不能包打天下。目前還沒有一個(gè)通用的 RL 解決方案像 DL 一樣成熟到成為一種即插即用的算法。不同 RL 算法在各自領(lǐng)域各領(lǐng)風(fēng)騷。在找到一個(gè)普適的方法之前,我們更應(yīng)該針對(duì)特定問題設(shè)計(jì)專門的算法,比如在機(jī)器人領(lǐng)域,基于貝葉斯 RL 和演化算法的方法(如 CMAES[61])比 DRL 更合適。當(dāng)然,不同的領(lǐng)域間應(yīng)當(dāng)互相借鑒與促進(jìn)。RL 算法的輸出存在隨機(jī)性,這是其“探索”哲學(xué)帶來的本質(zhì)問題,因此我們不能盲目 All in RL, 也不應(yīng)該 RL in All, 而是要找準(zhǔn) RL 適合解決的問題。
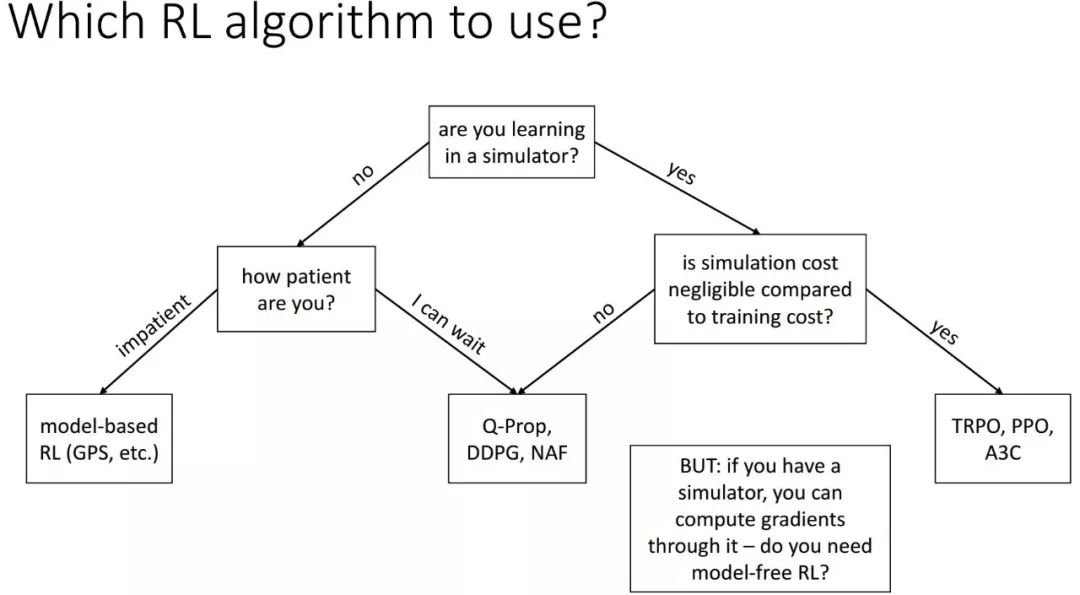
針對(duì)不同問題應(yīng)該使用的不同 RL 方法 [22]
4.4 重新審視 RL 的價(jià)值
在 NIPS 2016 上,Yan LeCun 認(rèn)為最有價(jià)值的問題是“Predictive Learning”問題,這其實(shí)類似于非監(jiān)督學(xué)習(xí)問題。他的發(fā)言代表了學(xué)界近來的主流看法。而 Ben Recht 則認(rèn)為,RL 比監(jiān)督學(xué)習(xí)(Supervised Learning, SL)和非監(jiān)督學(xué)習(xí)(Unsupervised Learning, UL)更有價(jià)值。他把這三類學(xué)習(xí)方式分別與商業(yè)分析中的描述分析(UL)、預(yù)測分析(SL)和指導(dǎo)分析(RL)相對(duì)應(yīng) [18]。
描述分析是對(duì)已有的數(shù)據(jù)進(jìn)行總結(jié),從而獲得更魯棒和清晰的表示,這個(gè)問題最容易,但價(jià)值也最低。因?yàn)槊枋龇治龅膬r(jià)值更多地在于美學(xué)方面而非實(shí)際方面。比如,“用 GAN 將一個(gè)房間的圖片渲染成何種風(fēng)格”遠(yuǎn)沒有“依據(jù)房間的圖片預(yù)測該房間的價(jià)格”更重要。而后者則是預(yù)測分析問題——基于歷史數(shù)據(jù)對(duì)當(dāng)前數(shù)據(jù)進(jìn)行預(yù)測。但是在描述分析和預(yù)測分析中,系統(tǒng)都是不受算法影響的,而指導(dǎo)分析則更進(jìn)一步地對(duì)算法與系統(tǒng)間的交互進(jìn)行建模,通過主動(dòng)影響系統(tǒng),最大化價(jià)值收益。
類比以上兩個(gè)例子,指導(dǎo)分析則是解決“如何通過對(duì)房間進(jìn)行一系列改造來最大化提升房間價(jià)格”之類的問題。這種問題最難,因?yàn)樯婕暗搅怂惴ㄅc系統(tǒng)的復(fù)雜交互,但也最有價(jià)值,因?yàn)橹笇?dǎo)性分析(RL)的天然目標(biāo)就是價(jià)值最大化,也是人類解決問題的方式。并且,無論是描述分析還是預(yù)測分析,所處理的問題的環(huán)境都是靜態(tài)的、不變的,這個(gè)假設(shè)對(duì)大多數(shù)實(shí)際的問題都不成立。而指導(dǎo)分析則被用來處理環(huán)境動(dòng)態(tài)變化的問題,甚至還要考慮到與其他對(duì)手的合作或競爭,與人類面臨的大多數(shù)實(shí)際問題更相似。
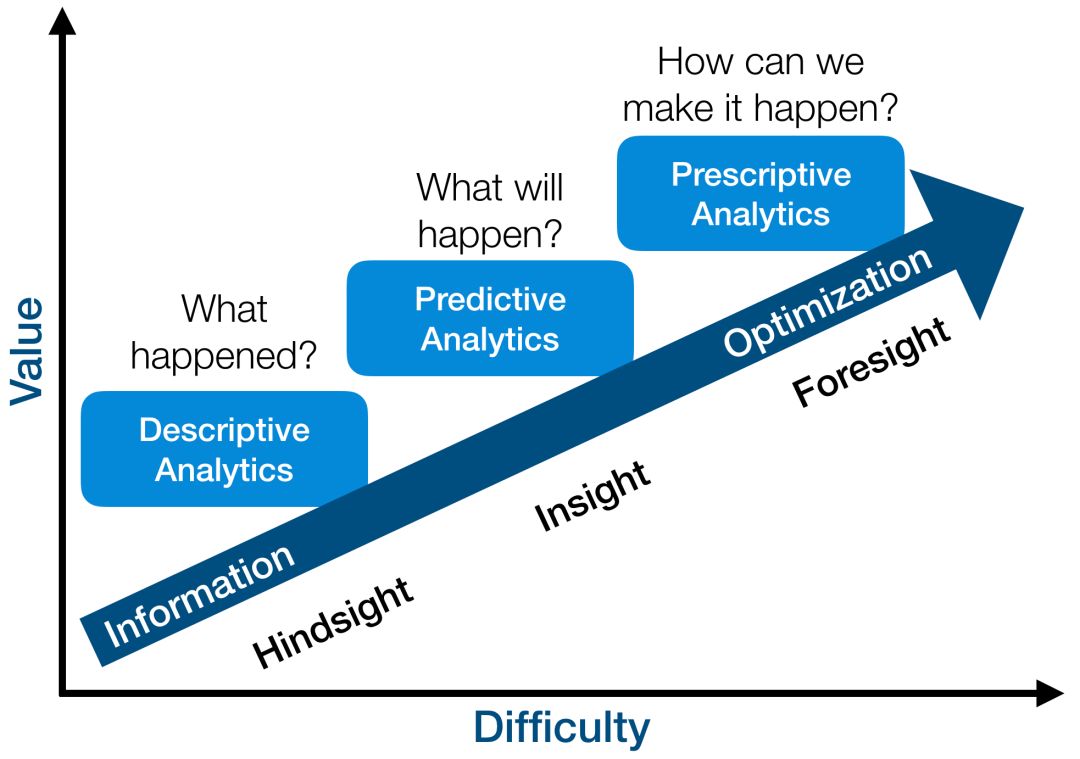
指導(dǎo)分析問題最難,也最有價(jià)值 [18]
在最后一節(jié),筆者將試圖在更廣的范圍內(nèi)討論類似于 RL 的從反饋中學(xué)習(xí)的方法,從而試圖給讀者介紹一種看待 RL 的新視角。
五、廣義的 RL——從反饋學(xué)習(xí)
本節(jié)使用“廣義的 RL”一詞指代針對(duì)“從反饋學(xué)習(xí)”的橫跨多個(gè)學(xué)科的研究。與上文中介紹的來自機(jī)器學(xué)習(xí)、控制論、經(jīng)濟(jì)學(xué)等領(lǐng)域的 RL 不同,本節(jié)涉及的學(xué)科更寬泛,一切涉及從反饋學(xué)習(xí)的系統(tǒng),都暫且稱為廣義的 RL。
5.1 廣義的 RL,是人工智能研究的最終目標(biāo)
1950 年,圖靈在其劃時(shí)代論文 Computing Machinery and Intelligence[62] 中提出了著名的“圖靈測試”概念:如果一個(gè)人(代號(hào) C)使用測試對(duì)象皆理解的語言去詢問兩個(gè)他不能看見的對(duì)象任意一串問題。對(duì)象為:一個(gè)是正常思維的人(代號(hào) B)、一個(gè)是機(jī)器(代號(hào) A)。如果經(jīng)過若干詢問以后,C 不能得出實(shí)質(zhì)的區(qū)別來分辨 A 與 B 的不同,則此機(jī)器 A 通過圖靈測試。
請(qǐng)注意,“圖靈測試”的概念已經(jīng)蘊(yùn)含了“反饋”的概念——人類借由程序的反饋來進(jìn)行判斷,而人工智能程序則通過學(xué)習(xí)反饋來欺騙人類。同樣在這篇論文中,圖靈還說到“除了試圖直接去建立一個(gè)可以模擬成人大腦的程序之外,為什么不試圖建立一個(gè)可以模擬小孩大腦的程序呢?如果它接受適當(dāng)?shù)慕逃蜁?huì)獲得成人的大腦。”——從反饋中逐漸提升能力,這不正是 RL 的學(xué)習(xí)方式么?可以看出,人工智能的概念從被提出時(shí)其最終目標(biāo)就是構(gòu)建一個(gè)足夠好的從反饋學(xué)習(xí)的系統(tǒng)。
1959 年,人工智能先驅(qū) Arthur Samuel 正式定義了“機(jī)器學(xué)習(xí)”這概念。也正是這位 Samuel,在 50 年代開發(fā)了基于 RL 的的象棋程序,成為人工智能領(lǐng)域最早的成功案例 [63]。為何人工智能先驅(qū)們的工作往往集中在 RL 相關(guān)的任務(wù)呢?經(jīng)典巨著《人工智能:一種現(xiàn)代方法》里對(duì) RL 的評(píng)論或許可以回答這一問題:可以認(rèn)為 RL 囊括了人工智能的所有要素:一個(gè)智能體被置于一個(gè)環(huán)境中,并且必須學(xué)會(huì)在其間游刃有余(Reinforcement Learning might be considered to encompass all of AI: an agent is placed in an environment and must learn to behave successfully therein.) [64]。
不僅僅在人工智能領(lǐng)域,哲學(xué)領(lǐng)域也強(qiáng)調(diào)了行為與反饋對(duì)智能形成的意義。生成論(Enactivism)認(rèn)為行為是認(rèn)知的基礎(chǔ),行為與感知是互相促進(jìn)的,智能體通過感知獲得行為的反饋,而行為則帶給智能體對(duì)環(huán)境的真實(shí)有意義的經(jīng)驗(yàn) [65]。
行為和反饋是智能形成的基石 [65]
看來,從反饋學(xué)習(xí)確實(shí)是實(shí)現(xiàn)智能的核心要素。
回到人工智能領(lǐng)域。DL 取得成功后,與 RL 結(jié)合成為 DRL。知識(shí)庫相關(guān)的研究取得成功后,RL 算法中也逐漸加入了 Memory 機(jī)制。而變分推理也已經(jīng)找到了與 RL 的結(jié)合點(diǎn)。近期學(xué)界開始了反思 DL 的熱潮,重新燃起對(duì)因果推理與符號(hào)學(xué)習(xí)的興趣,于是也出現(xiàn)了關(guān)系 RL 和符號(hào) RL[66] 相關(guān)的工作。通過回顧學(xué)術(shù)的發(fā)展,我們也可以總結(jié)出人工智能發(fā)展的一個(gè)特點(diǎn):每當(dāng)一個(gè)相關(guān)方向取得突破,總是會(huì)回歸到 RL 問題, 尋求與 RL 相結(jié)合。與其把 DRL 看作 DL 的拓展,不如看作 RL 的一次回歸。因此我們不必特別擔(dān)心 DRL 的泡沫,因?yàn)?RL 本就是人工智能的最終目標(biāo),有著旺盛的生命力,未來還會(huì)迎來一波又一波的發(fā)展。
5.2 廣義的 RL,是未來一切機(jī)器學(xué)習(xí)系統(tǒng)的形式
Recht 在他的最后一篇博文中 [67] 中強(qiáng)調(diào),只要一個(gè)機(jī)器學(xué)習(xí)系統(tǒng)會(huì)通過接收外部的反饋進(jìn)行改進(jìn),這個(gè)系統(tǒng)就不僅僅是一個(gè)機(jī)器學(xué)習(xí)系統(tǒng),而且是一個(gè) RL 系統(tǒng)。當(dāng)前在互聯(lián)網(wǎng)領(lǐng)域廣為使用的 A/B 測試就是 RL 的一種最簡單的形式。而未來的機(jī)器學(xué)習(xí)系統(tǒng),都要處理分布動(dòng)態(tài)變化的數(shù)據(jù)并從反饋中學(xué)習(xí)。因此可以說,我們即將處于一個(gè)“一切機(jī)器學(xué)習(xí)都是 RL”的時(shí)代,學(xué)界和工業(yè)界都亟需加大對(duì) RL 的研究力度。Recht 從社會(huì)與道德層面對(duì)這一問題進(jìn)行了詳細(xì)探討 [67],并將他從控制與優(yōu)化角度對(duì) RL 的一系列思考總結(jié)成一篇綜述文章供讀者思考 [69]。
5.3 廣義的 RL,是很多領(lǐng)域研究的共同目標(biāo)
4.2 節(jié)已經(jīng)提到 RL 在機(jī)器學(xué)習(xí)相關(guān)的領(lǐng)域被分別發(fā)明與研究,其實(shí)這種從反饋中學(xué)習(xí)的思想,在很多其他領(lǐng)域也被不斷地研究。僅舉幾例如下:
在心理學(xué)領(lǐng)域,經(jīng)典條件反射與操作性條件反射的對(duì)比,就如同 SL 和 RL 的對(duì)比;而著名心理學(xué)家 Albert Bandura 提出的“觀察學(xué)習(xí)”理論則與 IL 非常相似;精神分析大師 Melanie Klein 提出的“投射性認(rèn)同”其實(shí)也可以看做一個(gè) RL 的過程。在心理學(xué)諸多領(lǐng)域中,與 RL 關(guān)聯(lián)最近的則是行為主義學(xué)派(Behaviorism)。其代表人物 John Broadus Watson 將行為主義心理學(xué)應(yīng)用于廣告業(yè),極大推動(dòng)了廣告業(yè)的發(fā)展。這很難不讓人聯(lián)想到,RL 算法的一大成熟應(yīng)用就是互聯(lián)網(wǎng)廣告。而行為主義受到認(rèn)知科學(xué)影響而發(fā)展出的認(rèn)知行為療法則與 RL 中的策略遷移方法有異曲同工之妙。行為主義與 RL 的淵源頗深,甚至可以說是 RL 思想的另一個(gè)源頭。本文限于篇幅無法詳述,請(qǐng)感興趣的讀者參閱心理學(xué)方面的文獻(xiàn)如 [53]。
在教育學(xué)領(lǐng)域,一直有關(guān)于“主動(dòng)學(xué)習(xí)”與“被動(dòng)學(xué)習(xí)”兩種方式的對(duì)比與研究,代表性研究有 Cone of Experience,其結(jié)論與機(jī)器學(xué)習(xí)領(lǐng)域關(guān)于 RL 與 SL 的對(duì)比非常相似。而教育學(xué)家杜威提倡的“探究式學(xué)習(xí)”就是指主動(dòng)探索尋求反饋的學(xué)習(xí)方法;
在組織行為學(xué)領(lǐng)域,學(xué)者們探究“主動(dòng)性人格”與“被動(dòng)性人格”的不同以及對(duì)組織的影響;
在企業(yè)管理學(xué)領(lǐng)域,企業(yè)的“探索式行為”和“利用式行為”一直是一個(gè)研究熱點(diǎn);
……
可以說,一切涉及通過選擇然后得到反饋,然后從反饋中學(xué)習(xí)的領(lǐng)域,幾乎都有 RL 的思想以各種形式存在,因此筆者稱之為廣義的 RL。這些學(xué)科為 RL 的發(fā)展提供了豐富的研究素材,積累了大量的思想與方法。同時(shí),RL 的發(fā)展不會(huì)僅僅對(duì)人工智能領(lǐng)域產(chǎn)生影響,也會(huì)推動(dòng)廣義的 RL 所包含的諸多學(xué)科共同前進(jìn)。
結(jié) 語
雖然 RL 領(lǐng)域目前還存在諸多待解決的問題,在 DRL 這一方向上也出現(xiàn)不少泡沫,但我們應(yīng)該看到 RL 領(lǐng)域本身在研究和應(yīng)用領(lǐng)域取得的長足進(jìn)步。這一領(lǐng)域值得持續(xù)投入研究,但在應(yīng)用時(shí)需保持理性。而對(duì)基于反饋的學(xué)習(xí)的研究,不僅有望實(shí)現(xiàn)人工智能的最終目標(biāo),也對(duì)機(jī)器學(xué)習(xí)領(lǐng)域和諸多其他領(lǐng)域的發(fā)展頗有意義。這確實(shí)是通向人工智能的最佳路徑。這條路上布滿荊棘,但曙光已現(xiàn)。
-
人工智能
+關(guān)注
關(guān)注
1791文章
46853瀏覽量
237550 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
266瀏覽量
11213
原文標(biāo)題:泡沫破裂之后,強(qiáng)化學(xué)習(xí)路在何方?
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
人工智能、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)存在什么區(qū)別

《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
名單公布!【書籍評(píng)測活動(dòng)NO.44】AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新
人工智能如何強(qiáng)化智能家居設(shè)備的功能
FPGA在人工智能中的應(yīng)用有哪些?
通過強(qiáng)化學(xué)習(xí)策略進(jìn)行特征選擇

5G智能物聯(lián)網(wǎng)課程之Aidlux下人工智能開發(fā)(SC171開發(fā)套件V2)
機(jī)器學(xué)習(xí)怎么進(jìn)入人工智能
5G智能物聯(lián)網(wǎng)課程之Aidlux下人工智能開發(fā)(SC171開發(fā)套件V1)
嵌入式人工智能的就業(yè)方向有哪些?
深度學(xué)習(xí)在人工智能中的 8 種常見應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論