") 一個(gè)DCN模型從嵌入和堆積層開始
一個(gè)DCN模型從嵌入和堆積層開始
1、原理
Deep&Cross Network模型我們下面將簡(jiǎn)稱DCN模型:
一個(gè)DCN模型從嵌入和堆積層開始,接著是一個(gè)交叉網(wǎng)絡(luò)和一個(gè)與之平行的深度網(wǎng)絡(luò),之后是最后的組合層,它結(jié)合了兩個(gè)網(wǎng)絡(luò)的輸出。完整的網(wǎng)絡(luò)模型如圖:
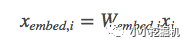
嵌入和堆疊層
我們考慮具有離散和連續(xù)特征的輸入數(shù)據(jù)。在網(wǎng)絡(luò)規(guī)模推薦系統(tǒng)中,如CTR預(yù)測(cè),輸入主要是分類特征,如“country=usa”。這些特征通常是編碼為獨(dú)熱向量如“[ 0,1,0 ]”;然而,這往往導(dǎo)致過度的高維特征空間大的詞匯。
為了減少維數(shù),我們采用嵌入過程將這些離散特征轉(zhuǎn)換成實(shí)數(shù)值的稠密向量(通常稱為嵌入向量):
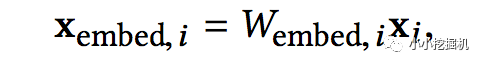
然后,我們將嵌入向量與連續(xù)特征向量疊加起來形成一個(gè)向量:
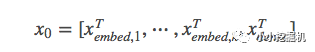
拼接起來的向量X0將作為我們Cross Network和Deep Network的輸入
Cross Network
交叉網(wǎng)絡(luò)的核心思想是以有效的方式應(yīng)用顯式特征交叉。交叉網(wǎng)絡(luò)由交叉層組成,每個(gè)層具有以下公式:
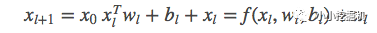
一個(gè)交叉層的可視化如圖所示:
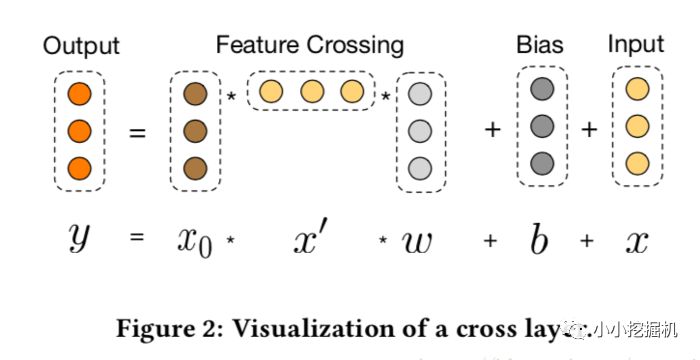
可以看到,交叉網(wǎng)絡(luò)的特殊結(jié)構(gòu)使交叉特征的程度隨著層深度的增加而增大。多項(xiàng)式的最高程度(就輸入X0而言)為L(zhǎng)層交叉網(wǎng)絡(luò)L + 1。如果用Lc表示交叉層數(shù),d表示輸入維度。然后,參數(shù)的數(shù)量參與跨網(wǎng)絡(luò)參數(shù)為:d * Lc * 2 (w和b)
交叉網(wǎng)絡(luò)的少數(shù)參數(shù)限制了模型容量。為了捕捉高度非線性的相互作用,模型并行地引入了一個(gè)深度網(wǎng)絡(luò)。
Deep Network
深度網(wǎng)絡(luò)就是一個(gè)全連接的前饋神經(jīng)網(wǎng)絡(luò),每個(gè)深度層具有如下公式:
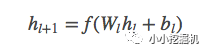
Combination Layer
鏈接層將兩個(gè)并行網(wǎng)絡(luò)的輸出連接起來,經(jīng)過一層全鏈接層得到輸出:
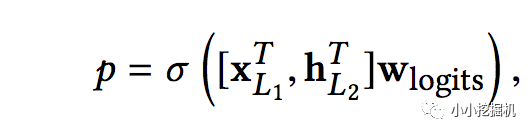
如果采用的是對(duì)數(shù)損失函數(shù),那么損失函數(shù)形式如下:
總結(jié)
DCN能夠有效地捕獲有限度的有效特征的相互作用,學(xué)會(huì)高度非線性的相互作用,不需要人工特征工程或遍歷搜索,并具有較低的計(jì)算成本。論文的主要貢獻(xiàn)包括:
1)提出了一種新的交叉網(wǎng)絡(luò),在每個(gè)層上明確地應(yīng)用特征交叉,有效地學(xué)習(xí)有界度的預(yù)測(cè)交叉特征,并且不需要手工特征工程或窮舉搜索。2)跨網(wǎng)絡(luò)簡(jiǎn)單而有效。通過設(shè)計(jì),各層的多項(xiàng)式級(jí)數(shù)最高,并由層深度決定。網(wǎng)絡(luò)由所有的交叉項(xiàng)組成,它們的系數(shù)各不相同。3)跨網(wǎng)絡(luò)內(nèi)存高效,易于實(shí)現(xiàn)。4)實(shí)驗(yàn)結(jié)果表明,交叉網(wǎng)絡(luò)(DCN)在LogLoss上與DNN相比少了近一個(gè)量級(jí)的參數(shù)量。
這個(gè)是從論文中翻譯過來的,哈哈。
2、實(shí)現(xiàn)解析
本文的代碼根據(jù)之前DeepFM的代碼進(jìn)行改進(jìn),我們只介紹模型的實(shí)現(xiàn)部分,其他數(shù)據(jù)處理的細(xì)節(jié)大家可以參考我的github上的代碼:
https://github.com/princewen/tensorflow_practice/tree/master/Basic-DCN-Demo
數(shù)據(jù)下載地址:
https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
不去下載也沒關(guān)系,我在github上保留了幾千行的數(shù)據(jù)用作模型測(cè)試。
模型輸入
模型的輸入主要有下面幾個(gè)部分:
self.feat_index = tf.placeholder(tf.int32, shape=[None,None], name='feat_index') self.feat_value = tf.placeholder(tf.float32, shape=[None,None], name='feat_value') self.numeric_value = tf.placeholder(tf.float32,[None,None],name='num_value') self.label = tf.placeholder(tf.float32,shape=[None,1],name='label') self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
可以看到,這里與DeepFM相比,一個(gè)明顯的變化是將離散特征和連續(xù)特征分開,連續(xù)特征不再轉(zhuǎn)換成embedding進(jìn)行輸入,所以我們的輸入共有五部分。
feat_index是離散特征的一個(gè)序號(hào),主要用于通過embedding_lookup選擇我們的embedding。feat_value是對(duì)應(yīng)離散特征的特征值。numeric_value是我們的連續(xù)特征值。label是實(shí)際值。還定義了dropout來防止過擬合。
權(quán)重構(gòu)建
權(quán)重主要包含四部分,embedding層的權(quán)重,cross network中的權(quán)重,deep network中的權(quán)重以及最后鏈接層的權(quán)重,我們使用一個(gè)字典來表示:
def _initialize_weights(self): weights = dict() #embeddings weights['feature_embeddings'] = tf.Variable( tf.random_normal([self.cate_feature_size,self.embedding_size],0.0,0.01), name='feature_embeddings') weights['feature_bias'] = tf.Variable(tf.random_normal([self.cate_feature_size,1],0.0,1.0),name='feature_bias') #deep layers num_layer = len(self.deep_layers) glorot = np.sqrt(2.0/(self.total_size + self.deep_layers[0])) weights['deep_layer_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(self.total_size,self.deep_layers[0])),dtype=np.float32 ) weights['deep_bias_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32 ) for i in range(1,num_layer): glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i])) weights["deep_layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])), dtype=np.float32) # layers[i-1] * layers[i] weights["deep_bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])), dtype=np.float32) # 1 * layer[i] for i in range(self.cross_layer_num): weights["cross_layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.total_size,1)), dtype=np.float32) weights["cross_bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.total_size,1)), dtype=np.float32) # 1 * layer[i] # final concat projection layer input_size = self.total_size + self.deep_layers[-1] glorot = np.sqrt(2.0/(input_size + 1)) weights['concat_projection'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(input_size,1)),dtype=np.float32) weights['concat_bias'] = tf.Variable(tf.constant(0.01),dtype=np.float32) return weights
計(jì)算網(wǎng)絡(luò)輸入
這一塊我們要計(jì)算兩個(gè)并行網(wǎng)絡(luò)的輸入X0,我們需要將離散特征轉(zhuǎn)換成embedding,同時(shí)拼接上連續(xù)特征:
# model self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1]) self.embeddings = tf.multiply(self.embeddings,feat_value) self.x0 = tf.concat([self.numeric_value, tf.reshape(self.embeddings,shape=[-1,self.field_size * self.embedding_size])] ,axis=1)
Cross Network
根據(jù)論文中的計(jì)算公式,一步步計(jì)算得到cross network的輸出:
# cross_part self._x0 = tf.reshape(self.x0, (-1, self.total_size, 1)) x_l = self._x0 for l in range(self.cross_layer_num): x_l = tf.tensordot(tf.matmul(self._x0, x_l, transpose_b=True), self.weights["cross_layer_%d" % l],1) + self.weights["cross_bias_%d" % l] + x_l self.cross_network_out = tf.reshape(x_l, (-1, self.total_size))
Deep Network
這一塊就是一個(gè)多層全鏈接神經(jīng)網(wǎng)絡(luò):
self.y_deep = tf.nn.dropout(self.x0,self.dropout_keep_deep[0]) for i in range(0,len(self.deep_layers)): self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["deep_layer_%d" %i]), self.weights["deep_bias_%d"%i]) self.y_deep = self.deep_layers_activation(self.y_deep) self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])
Combination Layer
最后將兩個(gè)網(wǎng)絡(luò)的輸出拼接起來,經(jīng)過一層全鏈接得到最終的輸出:
# concat_part concat_input = tf.concat([self.cross_network_out, self.y_deep], axis=1) self.out = tf.add(tf.matmul(concat_input,self.weights['concat_projection']),self.weights['concat_bias'])
定義損失
這里我們可以選擇logloss或者mse,并加上L2正則項(xiàng):
# loss if self.loss_type == "logloss": self.out = tf.nn.sigmoid(self.out) self.loss = tf.losses.log_loss(self.label, self.out) elif self.loss_type == "mse": self.loss = tf.nn.l2_loss(tf.subtract(self.label, self.out)) # l2 regularization on weights if self.l2_reg > 0: self.loss += tf.contrib.layers.l2_regularizer( self.l2_reg)(self.weights["concat_projection"]) for i in range(len(self.deep_layers)): self.loss += tf.contrib.layers.l2_regularizer( self.l2_reg)(self.weights["deep_layer_%d" % i]) for i in range(self.cross_layer_num): self.loss += tf.contrib.layers.l2_regularizer( self.l2_reg)(self.weights["cross_layer_%d" % i])
剩下的代碼就不介紹啦!
好啦,本文只是提供一個(gè)引子,有關(guān)DCN的知識(shí)大家可以更多的進(jìn)行學(xué)習(xí)呦。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100541 -
交叉網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
3瀏覽量
6037 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120979
原文標(biāo)題:推薦系統(tǒng)遇上深度學(xué)習(xí)(五)--Deep&Cross Network模型理論和實(shí)踐
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
DAQ數(shù)據(jù)采集2小時(shí)左右開始隊(duì)列堆積如何處理?
如何建立一個(gè)simulink模型
嵌入式入門學(xué)習(xí)該從哪里開始
部署基于嵌入的機(jī)器學(xué)習(xí)模型
BERT中的嵌入層組成以及實(shí)現(xiàn)方式介紹
探索一種降低ViT模型訓(xùn)練成本的方法
博世新品安保DCN會(huì)議系統(tǒng)性能分析
3D打印模型出現(xiàn)層錯(cuò)位的原因與解決方法
區(qū)塊鏈如何從協(xié)議層開始變得更有用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論