 探索A/B測試的貝葉斯方法背后的理論
探索A/B測試的貝葉斯方法背后的理論
編者按:和Google產品分析Zlatan Kremonic一起探索A/B測試的貝葉斯方法背后的理論。
本文將探索A/B測試的貝葉斯方法背后的理論。這一方法最近得到了廣泛認同,并在一些情形下取代了流行的頻率方法。在講述理論之后,我們將查看一個實例。
頻率統計
頻率統計以收集數據、測試假設這一傳統方法為中心。頻率統計分為以下步驟:
形式化假設。
收集數據。
計算基本的測試統計,包括p值和置信區間。
決定是否駁回零假設(null hypothesis)。
頻率統計的重要假定是參數是確定的,不過我們并不知曉。我們接下來收集的數據是那些參數及其分布的一個函數。用數學可以表達為:
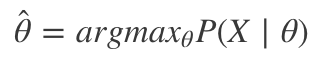
其中X是數據樣本,θ是零假設下的數據分布,戴帽θ是觀測到的參數。
總結科研報告的數據時,這一方法非常有用。置信區間的應用為我們提供了非常直觀地理解觀測到的參數的方式。不過,這一頻率方法有一些缺陷:
當我們發現p值明顯增加時,較早停止測試會增加得到假陽性結果的幾率。
我們無法測量研究結論為真的概率。
p值容易被誤解。
試驗必須全部事先指定,這可能導致看起來自相矛盾的結果。
多臂老虎機問題
在我們跳到貝葉斯推理之前,先在一個有用(且經典)的場景下考察我們的問題,這很重要。在多臂老虎機問題中,我們在一家賭場玩老虎機。給定不是所有的老虎機返水率相同這一條件,如果我們同時玩兩臺老虎機,我們將開始發現兩臺老虎機的結果不同。這導致了“探索v.s.利用困境”,迫使我們決定到底是利用高返水的機器,還是探索(隨機)選項以收集更多數據。不管我們選擇利用的程度如何,我們都在讓我們的行為適應觀測數據,這正是強化學習的一般假定之一。我們的目標是通過提高我們正做出正確決策的確定性,最大化返水,最小化損失。
處理多臂老虎機問題有很多策略,包括Epsilon-Greedy算法和UCB1算法,不過,也該讓貝葉斯推理出場了。
貝葉斯統計
貝葉斯統計以貝葉斯定理為中心:
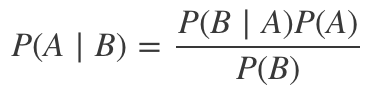
在我們試圖得出關于給定數據集的參數的結論的科研問題中,我們可以將參數視作隨機變量(有自己的分布):
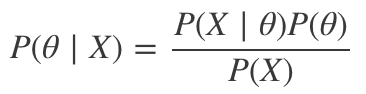
這里,
P(θ|X)稱為后驗,意為給定數據X,關于參數θ的新信念。
P(X|θ)稱為似然,回答給定當前參數θ有多大可能觀測到我們的數據。
P(θ)是先驗,意為我們關于θ的舊信念。
P(X)是P(X|θ)P(θ)dθ的積分,但因為它并不包含θ,可以直接忽略這一點,將它作為一個歸一化常量。
現在我們看到了貝葉斯范式轉變。和頻率方法不同,這里我們收集數據的前后都考慮到了參數的分布。知曉參數的分布讓我們可以給參數估計分配給定的置信度。
但我們如何知曉后驗分布呢?答案在“共軛先驗”這一概念之中:如果先驗概率分布和后驗概率分布同屬一個家族,那么它們稱為共軛分布,且先驗稱為似然函數的共軛先驗。簡單來說,如果我們知道似然函數的分布,我們就可以確定后驗和先驗的分布。
讓我們來看一個例子,假設我們正測量點擊率(某人是否點擊一則廣告)。因為我們測量的是二值輸出(點擊、沒點擊),所以我們處理的是伯努利分布,這意味著似然為:
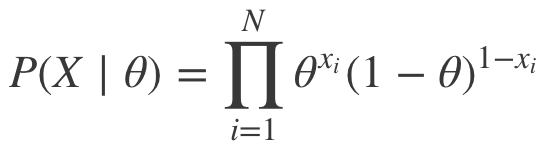
伯努利分布的共軛先驗是貝塔分布:
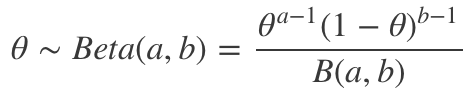
其中B(a, b)為貝塔函數。
我們需要求解后驗,首先結合似然和后驗:
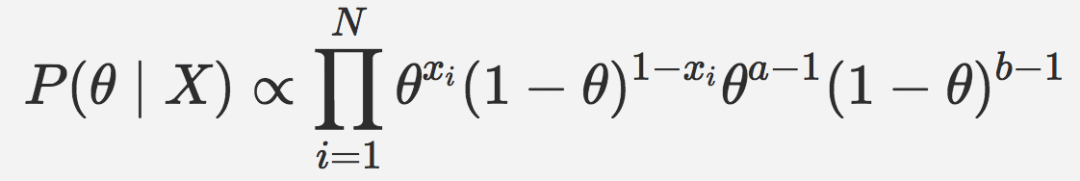
上式可以簡化為:
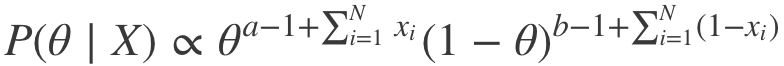
因此,我們可以看到,事實上P(θ|X)確實屬于貝塔分布,只不過超參數略有變動。由此我們得到:
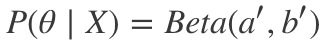
其中,
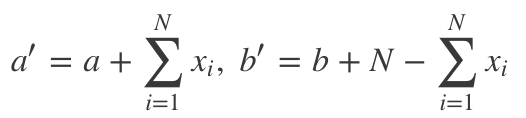
在我們的點擊率問題中,a' = a + 點擊數,b' = b + 未點擊數。
直覺上,這很合理。因為它告訴我們,后驗分布是收集數據的函數,且后驗分布可以用作更多樣本的先驗,其中的超參數直接加上新得到的額外信息。
進一步查看下貝塔分布,我們注意到這一分布的均值為:
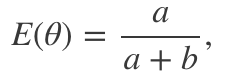
這和最大化似然時得到的值相同。最后,當a和b增加時,貝塔分布的方差遞減,可類比頻率方法中置信區間的表現:
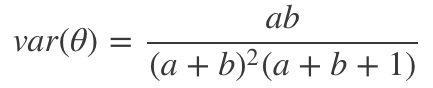
例子:湯普森采樣
在這個例子中,我們將演示如何使用湯普森采樣基于貝葉斯推理解決多臂老虎機問題。我們將使用2000次測試,而三臂的返水率為0.2、0.5、0.75. 首先,我們定義具有給定概率的Bandit(老虎機)類。該類提供一個pull(拉)方法,基于其概率返回獎勵或損失(1或0)。我們也能更新a、b,并使用這些值從所得貝塔分布中取樣。
importmatplotlib.pyplotasplt
importnumpyasnp
fromscipy.statsimportbeta
NUM_TRIALS =2000
BANDIT_PROBABILITIES = [0.2,0.5,0.75]
classBandit(object):
def__init__(self, p):
self.p = p
self.a =1
self.b =1
defpull(self):
return1ifnp.random.random() < self.pelse0
defsample(self):
returnnp.random.beta(self.a, self.b)
defupdate(self, x):
self.a += x
self.b +=1- x
下面,我們將定義一個函數繪制老虎機的貝塔分布:
defplot(bandits, trial):
x = np.linspace(0,1,200)
forbinbandits:
y = beta.pdf(x, b.a, b.b)
plt.plot(x, y, label="real p: %.4f"% b.p)
plt.title("Bandit distributions after %s trials"% trial)
plt.legend()
plt.show()
現在,開始我們的試驗。首先,我們初始化三臺老虎機。我們將根據預先確定的sample_points繪制它們的分布。每次測試時,我們從每臺老虎機的分布中取樣,并選擇返水率最高的老虎機。被選中的老虎機將有機會拉動它的拉桿,進而更新其a、b值。
defexperiment():
bandits = [Bandit(p)forpinBANDIT_PROBABILITIES]
sample_points = [5,50,100,500,1999]
foriinxrange(NUM_TRIALS):
# 從每個老虎機取樣
bestb =None
maxsample = -1
allsamples = []# 收集這些數據以便調試時打印
forbinbandits:
sample = b.sample()
allsamples.append("%.4f"% sample)
ifsample > maxsample:
maxsample = sample
bestb = b
ifiinsample_points:
print"current samples: %s"% allsamples
plot(bandits, i)
# 拉動樣本最大的老虎機的拉桿
x = bestb.pull()
# 更新剛剛拉動拉桿的老虎機的分布
bestb.update(x)
調用experiment()函數可以進行測試。
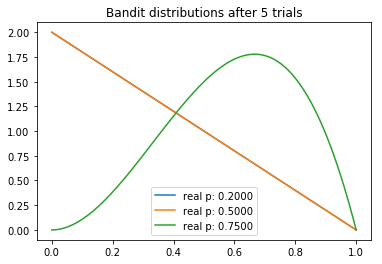
測試5次后
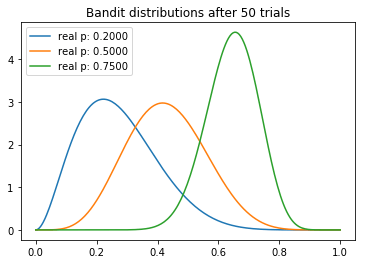
測試50次后
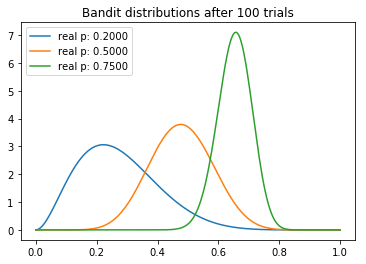
測試100次后
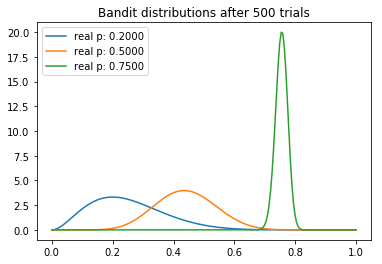
測試500次后
測試1999次后
從試驗中,我們可以觀察到一些有趣的東西。我們注意到每個分布的均值逐漸向真值收斂。不過我們看到,高返水的老虎機的方差最低,這反映了它具有最高的N。然而,這未必是一個問題,因為最后返水最高的分布和其他兩個較低的分布幾乎沒有重疊的部分,這意味著從較差的老虎機取樣將產生較高返水的概率是最小的。
結果概率
基于湯普森采樣的貝葉斯推斷的另一優勢是我們可以計算給定結果優于替代選擇的概率。例如,如果我們正測量兩個競爭頁面的點擊率,期望回報將是后驗分布的均值。那么,給定均值高于另一均值的概率,可以通過計算兩者的聯合概率分布函數之下的面積得到。假設均值二高于均值一,則:
結論
就A/B測試問題而言,貝葉斯推理和頻率方法之間沒有明顯的贏家,在選擇一種方法之前最好首先評估場景。參考鏈接部分的最后一個鏈接提供了關于何處適用老虎機測試(包括湯普森采樣)的一些要領。
-
貝葉斯
+關注
關注
0文章
77瀏覽量
12554 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:基于湯普森采樣的貝葉斯A/B測試
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于概率的常見的分類方法--樸素貝葉斯

貝葉斯統計的一個實踐案例讓你更快的對貝葉斯算法有更多的了解
一文秒懂貝葉斯優化/Bayesian Optimization






 工商網監
工商網監
評論