 總覽人工智能技術圖譜,計算機視覺VS機器視覺
總覽人工智能技術圖譜,計算機視覺VS機器視覺
人工智能的發展離不開基礎支持層和技術層,基礎支持層包括大數據、計算力和算法;技術層包括計算機視覺、語音識別和自然語言處理。人工智能的技術本質是什么,本文會詳細分析。
總覽人工智能技術圖譜
基礎支撐層的算法創新發生在20世紀80年代末,是大數據和計算力將人工智能推到鎂光燈之下,而建立在這之上的基礎技術便是計算機視覺、語音識別和自然語言理解,機器試圖看懂、聽懂人類的世界、用人類的語言和人類交流,研究人類智能活動的規律。
1.計算機視覺技術(Computer Vision)
1)·什么是計算機視覺
“人的大腦皮層的活動, 大約70%是在處理視覺相關信息。視覺就相當于人腦的大門,其它如聽覺、觸覺、味覺那都是帶寬較窄的通道。視覺相當于八車道的高速, 其它感覺是兩旁的人行道。如果不能處理視覺信息的話,整個人工智能系統是個空架子,只能做符號推理,比如下棋、定理證明, 沒法進入現實世界。計算機視覺之于人工智能,它相當于說芝麻開門。大門就在這里面,這個門打不開, 就沒法研究真實世界的人工智能。”——朱松純,加州大學洛杉磯分校UCLA統計學和計算機科學教授根據科普中國撰寫的對計算機視覺的定義,這是一門研究如何讓機器“看”的科學,更進一步的說,是指用計算機代替人眼對目標進行識別、跟蹤和測量的機器視覺,并進一步做圖形處理,使計算機處理成為更適合人眼觀察或傳送給儀器檢測的圖像。
2)·計算機視覺 VS 機器視覺
計算機視覺更關注圖像信號本身以及圖像相關交叉領域(地圖、醫療影像)的研究;機器視覺則偏重計算機視覺技術工程化,更關注廣義上的圖像信號(激光和攝像頭)和自動化控制(生產線)方面的應用。
3)計算機視覺識別技術的分類
物體識別分為“1 VS N”對不同物體進行歸類,以及“1 VS 1”對同類型的物體進行區分和鑒別;物體屬性識別,結合地圖模型讓物體在視覺的三維空間里得到記憶的重建,進而進行場景的分析和判斷;物體行為識別分為3個進階的步驟,移動識別判斷物體是否做了位移,動作識別判斷物體做的是什么動作,行為識別是結合視覺主體和場景的交互做出行為的分析和判斷。
4)·計算機視覺的識別流程
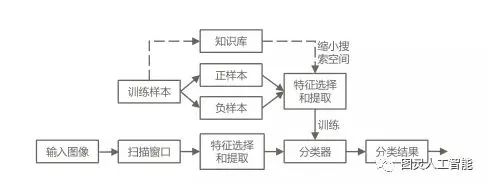
計算機視覺識別流程分為兩條路線:訓練模型和識別圖像。
訓練模型:樣本數據包括正樣本(包含待檢目標的樣本)和負樣本(不包含目標的樣本),視覺系統利用算法對原始樣本進行特征的選擇和提取訓練出分類器(模型);此外因為樣本數據成千上萬、提取出來的特征更是翻番,所以一般為了縮短訓練的過程,會人為加入知識庫(提前告訴計算機一些規則),或者引入限制條件來縮小搜索空間。
識別圖像:會先對圖像進行信號變換、降噪等預處理,再來利用分類器對輸入圖像進行目標檢測。一般檢測過程為用一個掃描子窗口在待檢測的圖像中不斷的移位滑動,子窗口每到一個位置就會計算出該區域的特征,然后用訓練好的分類器對該特征進行篩選,判斷該區域是否為目標。
5 )計算機視覺技術模式圖和對應企業圖
目前世界上圖像識別最大的數據庫,是斯坦福大學人工智能實驗室提供的ImageNet,針對諸如醫療等細分領域也需要收集相應的訓練數據;Google、Microsoft此類科技巨頭會面向市場提供開源算法框架,為初創視覺識別公司提供初級算法。
2.語音識別(Automatic Speech Recognition)
1)什么是語音識別
語音識別是以語音為研究對象,通過信號處理和識別技術讓機器自動識別和理解人類口述的語言后,將語音信號轉換為相應的文本或命令的一門技術。由語音識別和語音合成、自然語言理解、語義網絡等技術相結合的語音交互正在逐步成為當前多通道、多媒體智能人機交互的主要方式。
2)語音識別的流程
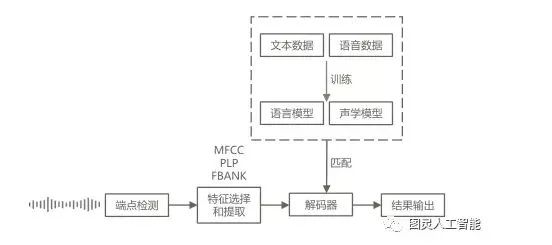
語音識別流程分為訓練和識別兩條線路。
語音信號經過前端信號處理、端點檢測等預處理后,逐幀提取語音特征,傳統的特征類型包括有MFCC、PLP、FBANK等特征,提取好的特征會送到解碼器,在訓練好的聲學模型、語言模型之下,找到最為匹配的此序列作為識別結果輸出。
3)語音識別技術模式圖和對應企業圖
基礎層:包含大數據、計算力和算法三塊,其中大數據等接入的是相應領域的第三方服務商。機器在識別人類的語音指令后接入、提供相應的服務。諸如影視、電影票、餐飲等;
技術層:以科大訊飛為首的語音技術提供商;
應用層:傳統家居環境中的電視、音箱廠商都給加上了語音識別功能,新增交互方式;還有智能車載采用語音交互讓手不離開方向盤提高安全系數;還有搜索廠商基于搜索做出來的語音助手等。
3.自然語言理解(Natural Language Understanding)
1)什么是自然語言理解
自然語言理解即文本理解,和語音圖像的模式識別技術有著本質的區別,語言作為知識的載體,承載了復雜的信息量,具有高度的抽象性,對語言的理解屬于認知層面,不能僅靠模式匹配的方式完成。
2)自然語言理解的應用:搜索引擎+機器翻譯;
自然語言理解最典型兩種應用為搜索引擎和機器翻譯。搜索引擎可以在一定程度上理解人類的自然語言,從自然語言中抽取出關鍵內容并用于檢索,最終達到搜索引擎和自然語言用戶之間的良好銜接,可以在兩者之間建立起更高效,更深層的信息傳遞。
3)自然語言理解技術在搜索引擎中的應用
4)自然語言理解技術在機器翻譯中的應用
事實上搜索引擎和機器翻譯不分家,互聯網、移動互聯網為其充實了語料庫使得其發展模態發生了質的改變。互聯網、移動互聯網除了將原先線下的信息(原有語料)進行在線化之外,還衍生出來的新型UGC模式:知識分享數據,像維基百科、百度百科等都是人為校準過的詞條,噪聲小;社交數據,像微博和微信等展現用戶的個性化、主觀化、時效性,可以用來做個性化推薦、情感傾向分析、以及熱點輿情的檢測和跟蹤等;社區、論壇數據,像果殼、知乎等為搜索引擎提供了問答知識、問答資源等數據源。另一方面,因為深度學習采用的層次結構從大規模數據中自發學習的黑盒子模式是不可解釋的,而以語言為媒介的人與人之間的溝通應該要建立在相互理解的基礎上,所以深度學習在搜索引擎和機器翻譯上的效用沒有語音圖像識別領域來得顯著。
一圖看懂新一代
人工智能知識體系大全
-
機器視覺
+關注
關注
161文章
4345瀏覽量
120108 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237546 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927
原文標題:一圖看懂新一代人工智能知識體系大全
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論