 上海交大提出切片循環神經網絡,其速度是標準RNN的136倍
上海交大提出切片循環神經網絡,其速度是標準RNN的136倍
上海交通大學最新提出切片循環神經網絡(SRNN),其速度是標準RNN的136倍,并且還能更快!對六個大型情緒分析數據集的實驗表明,SRNN的性能均優于標準RNN。
在許多NLP任務中,循環神經網絡(RNN)取得了巨大的成功。但是,這種循環的結構使它們難以并行化,因此,訓練RNN需要大量的時間。
上海交通大學的Zeping Yu和Gongshen Liu,在論文“Sliced Recurrent Neural Networks”中,提出了全新架構“切片循環神經網絡”(SRNN)。SRNN可以通過將序列分割成多個子序列來實現并行化。SRNN能通過多個層獲得高級信息,而不需要額外的參數。
研究人員證明了當使用線性激活函數時,標準RNN是SRNN的一個特例。在不改變循環單元的情況下,SRNN的速度是標準RNN的136倍,并且當訓練更長的序列時可能會更快。對六個大型情緒分析數據集的實驗表明,SRNN的性能優于標準RNN。
提高RNN訓練速度的多種方法
循環神經網絡(RNN)已經被廣泛用于許多NLP任務,包括機器翻譯、問題回答、圖像說明和文本分類。RNN能夠獲得輸入序列的順序信息。最受歡迎的兩個循環單元是長短期記憶(LSTM)和門控循環單元(GRU),兩者都可以將先前的記憶存儲在隱藏狀態,并使用門控機制來確定應該在何種程度將先前的記憶應與當前的輸入結合。但是,由于其循環的結構,RNN不能并行計算。因此,訓練RNN需要花費大量時間,這限制了學術研究和工業應用。
為了解決這個問題,一些學者嘗試在NLP領域使用卷積神經網絡(CNN)來代替RNN。但是,CNN無法獲得序列的順序信息,而順序信息在NLP任務中非常重要。
一些學者試圖通過改進循環單元來提高RNN的速度,并取得了良好的效果。通過將CNN與RNN相結合,準循環神經網絡(QRNN)的速度提高了16倍。2017年Tao Lei等人提出了簡單循環單元SRU(simple recurrent unit),比LSTM快5-10倍。類似地, strongly-typed循環神經網絡(T-RNN)和最小門控單元(MGU)也是可以改進循環單元的方法。
雖然RNN在這些研究中實現了更快的速度,并且循環單元得到了改善,但整個序列中的循環結構是保持不變的。我們仍然需要等待上一步的輸出,因此RNN的瓶頸仍然存在。在本文中,我們提出切片循環神經網絡(SRNN),它在不改變循環單元的情況下,能夠比標準RNN快得多。我們證明了當使用線性激活函數時,標準RNN是SRNN的一個特例,SRNN能夠獲得序列的高級信息。
為了將我們的模型與標準RNN進行比較,我們選擇GRU作為循環單元。其他的循環單元也可以用于我們的結構,因為我們改進了整個序列中的整體RNN結構,而不僅僅是改變循環單元。我們在6個大型數據集上完成了實驗,證明SRNN在所有數據集上的性能優于標準RNN。
我們開源了實現代碼:
https://github.com/zepingyu0512/srnn
切片循環神經網絡SRNN的結構
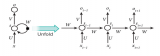
我們構建了一個新的RNN結構,稱為切片循環神經網絡(SRNN),如圖2所示。在圖2中,循環單位也稱為A。
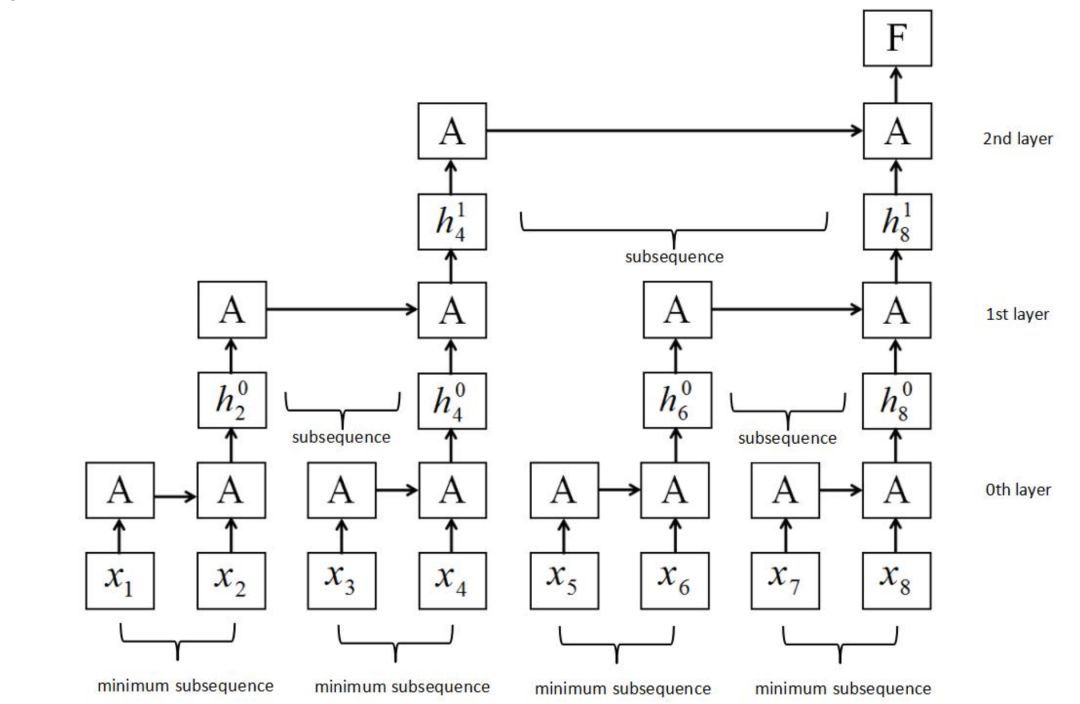
圖2:SRNN結構。它是通過將輸入序列分割成幾個長度相等的最小子序列來構造的。循環單元可以在每層子序列上同時工作,信息可以通過多層傳遞。
輸入序列X的長度為T,輸入序列為:
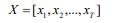
其中x是每個步驟的輸入,它可能具有多個維度,例如單詞嵌入。然后將X分割成長度相等的n個子序列,每個子序列的長度n為:
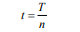
其中n為切片數,序列X可表示為:
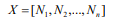
其中每個子序列是:
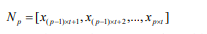
類似地,我們將每個子序列N再次切割成相等長度的n個子序列,然后重復該切片操作k次,直到我們在底層有一個適當的最小子序列長度(我們稱之為第0層,如圖2所示), 通過切片k次獲得k + 1層。 第0層的最小子序列長度為:
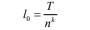
第0層的最小子序列數為:
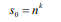
因為第p層(p> 0)上的每個父序列被切成n個部分,所以第p層上的子序列的數量是:
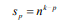
并且第p層的子序列長度為:
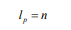
以圖2為例。 序列長度T為8,切片操作次數k為2,每個第p層的切片編號n為2。將序列切片兩次后,在第0層得到4個最小子序列,每個最小子序列的長度為 2。如果序列的長度或其子序列的長度不能除以n,我們可以利用填充法或在每一層上選擇不同的切片編號。 不同的k和n可以用于不同的任務和數據集。
SRNN和標準RNN之間的區別在于SRNN將輸入序列切分為許多最小子序列,并利用每個子序列上的循環單元。通過這種方式,子序列可以很容易地并行化。在第0層,循環單元通過連接結構對每個最小子序列起作用。 接下來,我們獲得第0層上每個最小子序列的最后隱藏狀態,這些狀態在第1層用作其父序列的輸入。 然后我們使用第(p-1)層上每個子序列的最后隱藏狀態作為其第p層上的父序列的輸入,并計算第p層上子序列的最后隱藏狀態:
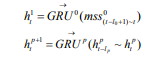
其中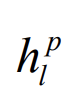 為第p層上的數l隱藏狀態,mss為第0層上的最小子序列,不同層上可以使用不同的GRU。在每層上的每個子父序列之間重復該操作,直到我們得到頂層(第k層)的最終隱藏狀態F:
為第p層上的數l隱藏狀態,mss為第0層上的最小子序列,不同層上可以使用不同的GRU。在每層上的每個子父序列之間重復該操作,直到我們得到頂層(第k層)的最終隱藏狀態F:
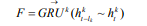
實驗:序列長度越長,SRNN處理的速度優勢就越大
數據集
我們在六個大規模情緒分析數據集上評估SRNN。表1列出了數據集的信息。我們選擇80%的數據用于訓練,10%用于驗證,10%用于測試。
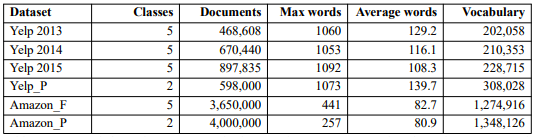
表1:數據集信息。Max words表示最大序列長度,Average words表示每個數據集中句子的平均長度。
結果和分析
每個數據集的結果如表2所示。我們選擇不同的n和k值,得到不同的SRNN。例如,SRNN(16,1)表示n = 16且k = 1,當T為512時,可以得到長度為32的最小子序列;當T為256時,可以得到長度為16的最小子序列。我們將4個SRNN與標準RNN進行了比較。每個數據集中,粗體字表示性能最高的模型和速度最快的模型。
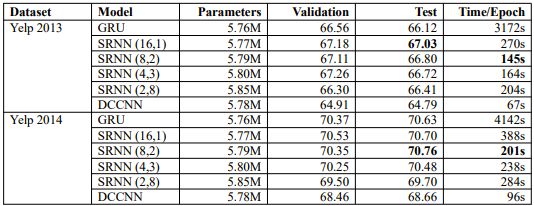
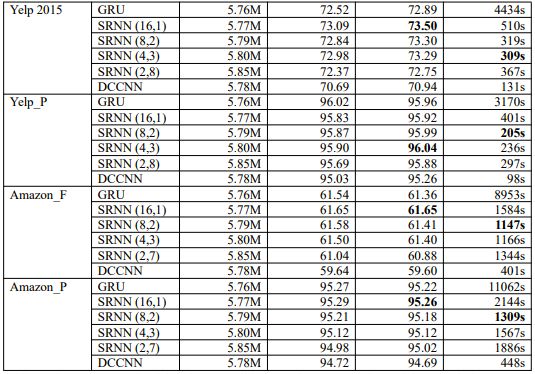
表2:每個數據集上模型驗證和測試的準確度和訓練時間。我們構建了四種不同的SRNN結構。DCCNN是dilated casual卷積神經網絡。
結果表明,在幾乎沒有額外參數的條件下,SRNN在所有數據集上的性能和速度都優于標準RNN。不同的SRNN在不同的數據集上都實現了最佳性能:
SRNN(16,1)在Yelp 2013,Yelp 2015,Amazon_F和Amazon_P上都獲得最高的準確度;
SRNN(8,2)在Yelp 2014上的性能最佳;
SRNN(4,3)在Yelp_P上表現最好。
K大于1時,SRNN在Yelp數據集上比標準RNN快了將近15倍,可見速度的優勢取決于k,n和T。
SRNN(4,3)在Yelp 2015上速度最快, 而SRNN(8,2)在其余數據集最快(DCCNN除外)。
我們注意到,Yelp數據集上的SRNN(2,8)和Amazon數據集上的SRNN(2,7)沒有達到最佳性能,但也沒有在準確性方面減弱太多。這意味著SRNN能夠通過多個層傳輸信息,因此,當我們訓練非常長的序列時,SRNN可以獲得顯著的效果。當n為2時,SRNN具有與DCCNN相同的層數,并且SRNN的精度比DCCNN高得多。因此,這表明SRNN中的循環結構優于dilated casual卷積神經網絡結構。
我們使用NVIDIA GTX 1080 GPU在5120個文檔上訓練模型,因為如果使用更多的數據,訓練標準RNN需要花費太多時間。訓練時間如表3所示。
從表3中得到驚人的結果:序列長度越長,SRNN實現的速度優勢就越大。當序列長度為32768時,SRNN僅需52s,而標準RNN需要花費近2小時。SRNN的速度是標準RNN的136倍!并且如果使用更長的序列,速度優勢可能更大。因此,SRNN可以在長序列任務上實現更快的速度,例如語音識別、字符級文本分類和語言建模。
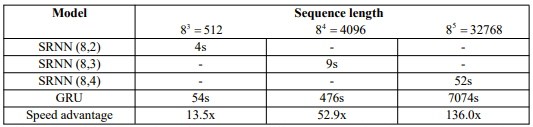
表3:不同序列長度的訓練時間和速度優勢。對于每個序列長度,我們選擇不同的SRNN結構。
SRNN的優勢和重要意義
在這一部分,我們將討論SRNN的優勢和重要意義。隨著RNN在許多NLP任務中取得成功,許多學者提出了不同的結構來提高RNN的速度。通過改善循環單元,很多研究都能加快RNN的速度。但是,RNN的傳統連接結構幾乎沒有被質疑過,而這種結構里每個步驟都與它的前一步驟相關聯。正是這種連接結構限制了RNN的速度。SRNN改進了傳統的連接方法。我們構建了一種切片結構(sliced structure)來實現RNN的并行化。在六個大規模情感分析數據集的實驗結果表明,SRNN比標準RNN具有更好的性能。原因如下:
(1)當使用標準RNN連接結構時,具門控結構的循環單元(例如GRU和LSTM)是有用的,但是當序列很長時,它們就無法存儲所有的重要信息。SRNN可以將長序列分成許多短的子序列,并用短序列來獲取重要信息。SRNN能夠通過從第0層到頂層的多層結構傳輸重要信息。
(2)SRNN能夠從序列中獲取高級信息,而不僅僅是單詞級信息。我們在512個單詞的文本中使用SRNN(8,2)時,第0層可以從單詞嵌入中獲得句子級信息,第1層可以從句子級信息中獲得段落級信息,第2層可以生成段落級信息的最終文檔級表示。而標準RNN只能獲得詞匯級信息。雖然不可能每個文檔有8個段落,每個段落有8個句子,每個句子有8個單詞,但是總體的順序信息和結構信息是統一的。以段落信息為例,人們總是在文章的開頭或結尾表達自己的觀點,并在文章中間舉例說明。與標準RNN相比,SRNN更容易在頂層獲得這些信息。
(3)在處理序列方面,SRNN類似于人腦的機制。例如,我們作為人類在得到一篇文章,并被要求回答一些問題時,我們通常不需要深入閱讀整篇文章。我們會試圖找到提及具體信息的段落,然后在段落中找到可以回答問題的句子和單詞。SRNN可以通過多個層輕松做到這一點。
除了提高準確性之外,SRNN的最大優勢是可以并行計算,實現更快的速度。我們在不同序列長度的實驗表明SRNN的運行速度比標準RNN快得多。而且,在更長的序列上,SRNN可能更快。隨著互聯網的發展,每天都有數以億計的數據產生,SRNN可以作為處理這些數據的新方法。
結論和未來工作
在這篇論文中,我們提出切片循環神經網絡(SRNN),這是RNN的整體結構改進。 SRNN可以達到比標準RNN快得多的速度,并在六個大規模情感數據集上實現更好的性能。
SRNN在文本分類方面取得了成功。在未來的工作中,我們希望將其推廣到其他NLP應用,例如問答、文本摘要和機器翻譯。在序列到序列模型中,SRNN可以用作編碼器,并且可以通過使用反向SRNN結構來改進解碼器。此外,我們希望在一些長序列任務中使用SRNN,例如語言模型、音樂生成和音頻生成。我們想探索更多SRNN的變體,例如,可以添加雙向結構和注意力機制。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100539 -
函數
+關注
關注
3文章
4306瀏覽量
62430 -
rnn
+關注
關注
0文章
88瀏覽量
6873
原文標題:比RNN快136倍!上交大提出SRNN,現在RNN也能做并行計算了
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是RNN (循環神經網絡)?





 工商網監
工商網監
評論