") 你知道XGBoost背后的數(shù)學原理是什么嗎?
你知道XGBoost背后的數(shù)學原理是什么嗎?
編者按:說到Kaggle神器,不少人會想到XGBoost。一周前,我們曾在“從Kaggle歷史數(shù)據(jù)看機器學習競賽趨勢”介紹過它的“霸主地位”:自提出后,這種算法在機器學習競賽中被迅速普及,并被多數(shù)奪冠模型視為訓練速度、最終性能提升的利器。那么,你知道XGBoost背后的數(shù)學原理是什么嗎?
好奇的李雷和韓梅梅
李雷和韓梅梅是形影不離的好朋友,一天,他們一起去山里摘蘋果。按照計劃,他們打算去摘山谷底部的那棵大蘋果樹。雖然韓梅梅聰明而富有冒險精神,而李雷有些謹慎和遲鈍,但他們中會爬樹的只有李雷。那么他們的路徑是什么呢?
如上圖所示,李雷和韓梅梅所在的位置是a點,他們的目標蘋果樹位于g點。山里環(huán)境復雜,要怎么做才能確定自己到了山谷底部呢?他們有兩種方法。
1.由韓梅梅計算“a”點的斜率,如果斜率為正,則繼續(xù)朝這個方向前進;如果為負,朝反方向前進。
斜率給出了前進的方向,但沒有說明他們需要朝這個方向移動多少。為此,韓梅梅決定走幾步臺階,算一下斜率,確保自己不會到達錯誤位置,最終錯過大蘋果樹。但是這種方法有風險,控制臺階多少的是學習率,這是個需要人為把控的值:如果學習率過大,李雷和韓梅梅很可能會在g點兩側(cè)來回奔走;如果學習率過小,可能天黑了他們都未必摘得到蘋果。
聽到可能會走錯路,李雷不樂意了,他不想繞遠路,也不愿意錯過回家吃飯的時間。看到好友這么為難,韓梅梅提出了第二種方法。
2.在第一種方法的基礎(chǔ)上,每走過特定數(shù)量的臺階,都由韓梅梅去計算每一個臺階的損失函數(shù)值,并從中找出局部最小值,以免錯過全局最小值。每次韓梅梅找到局部最小值,她就發(fā)個信號,這樣李雷就永遠不會走錯路了。但這種方法對女孩子不公平,可憐的韓梅梅需要探索她附近的所有點并計算所有這些點的函數(shù)值。
XGBoost的優(yōu)點在于它能同時解決以上兩種方案的缺陷。
梯度提升(Gradient Boosting)
很多梯度提升實現(xiàn)都會采用方法1來計算目標函數(shù)的最小值。在每次迭代中,我們利用損失函數(shù)的梯度訓練基學習器,然后用預測結(jié)果乘上一個常數(shù),將其與前一次迭代的值相加,更新模型。

它背后的思路就是在損失函數(shù)上執(zhí)行梯度下降,然后用基學習器對其進行擬合。當梯度為負時,我們稱它為偽殘差,因為它們依然能間接幫助我們最小化目標函數(shù)。
XGBoost
XGBoost是陳天奇在華盛頓大學求學期間提出的成果。它是一個整體加法模型,由幾個基學習器共同構(gòu)成。
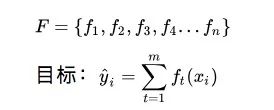
那么,我們該如何在每次迭代中選擇一個函數(shù)?這里可以用一種最小化整體損失的方法。

在上述梯度提升算法中,我們通過將基學習器擬合到相對于先前迭代值的損失函數(shù)的負梯度,在每次迭代時獲得ft(xi)。而在XGBoost中,我們只探索幾個基學習器或函數(shù),選擇其中一個計算最小值,也就是韓梅梅的方法2。
如前所述,這種方法有兩個問題:
探索不同的基學習器;
計算所有基學習器的損失函數(shù)值。
XGBoost在計算基學習器ft(xi)最小值的,使用的方法是泰勒級數(shù)逼近。比起計算精確值,計算近似值可以大大減輕韓梅梅的工作量。

雖然上面只展開到二階導數(shù),但這種近似程度就足夠了。對于任意ft(xi),第一項C都是常數(shù)。gi是前一次迭代中損失的一階導數(shù),hi是其二階導數(shù)。韓梅梅可以在探索其他基學習器前直接計算gi和hi,這就成了一個簡單的乘法問題,計算負擔大大減輕了,不是嗎?
解決了損失函數(shù)值的問題,我們還要探索不同的基學習器。
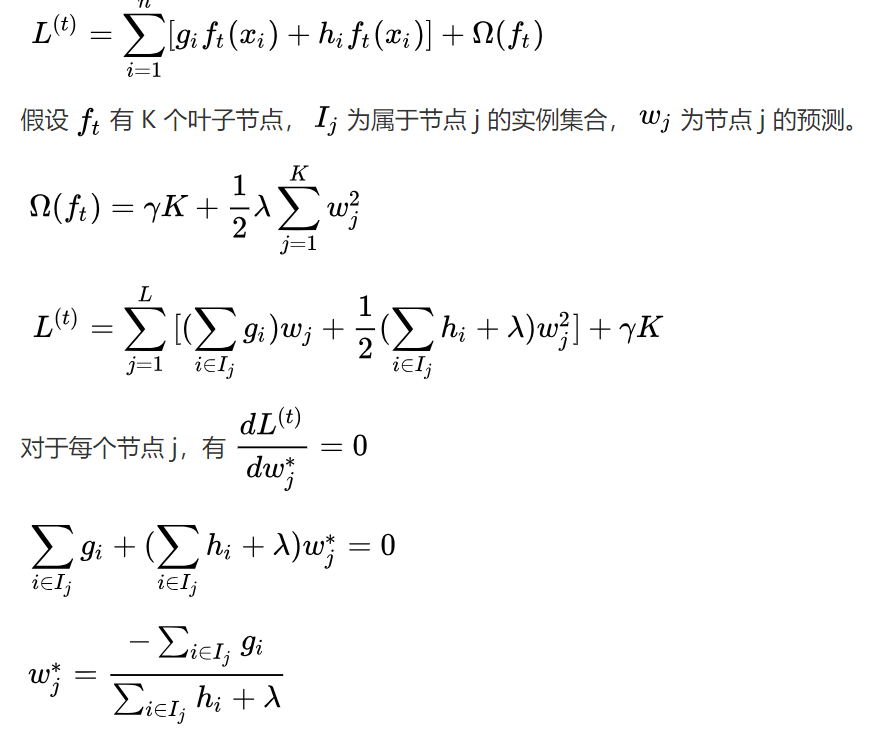
假設(shè)韓梅梅更新了一個具有K個葉子節(jié)點的基學習器ft。設(shè)Ij是屬于節(jié)點j的實例集合,wj是該節(jié)點的預測。因此,對于Ij中的實例i,我們有ft(xi)=wj。所以我們在上式中用代入法更新了L(t)的表達式。更新后,我們就能針對每個葉子節(jié)點的權(quán)重采用損失函數(shù)的導數(shù),以獲得最優(yōu)權(quán)重。
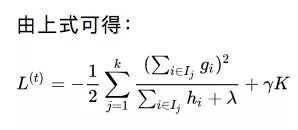
以上就是對于具有K個葉子節(jié)點的基學習器的最佳損失。考慮到這樣的節(jié)點會有上百個,一個個探索它們是不現(xiàn)實的。
所以讓我們來看韓梅梅的情況。她現(xiàn)在已經(jīng)知道如何使用泰勒展開來降低損失計算量,也知道了什么是葉子節(jié)點中的最佳權(quán)重。唯一值得關(guān)注的是如何探索所有不同的樹結(jié)構(gòu)。
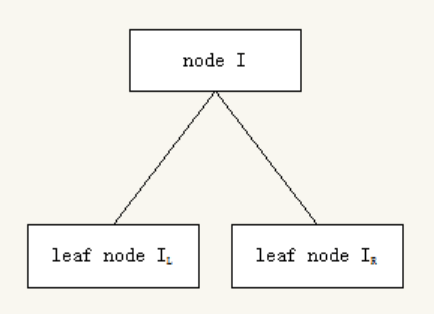
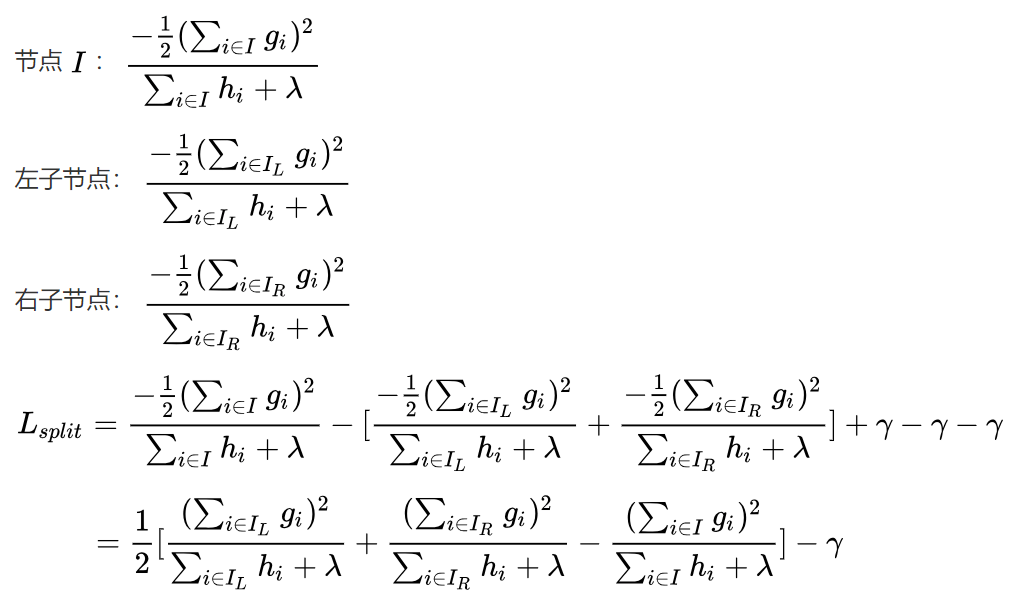
XGBoost不會探索所有可能的樹結(jié)構(gòu),它只是貪婪地構(gòu)建一棵樹,選擇導致最大損失的方法,減少分叉。在上圖中,樹從節(jié)點I開始,根據(jù)標準,節(jié)點分為左右分叉。所以我們的實例一部分被放進了左側(cè)的葉子節(jié)點,剩下的則去了右側(cè)的葉子節(jié)點。現(xiàn)在,我們就可以計算損失值并選擇導致?lián)p失減少最大的分叉。
解決了上述問題后,現(xiàn)在韓梅梅就只剩下一個問題:如何選擇分叉標準?XGBoost使用不同的技巧來提出不同的分割點,比如直方圖。對于這部分,建議去看論文,本文不再作解釋。
XGBoost要點
雖然梯度提升遵循負梯度來優(yōu)化損失函數(shù),但XGBoost計算每個基學習器損失函數(shù)值用的是泰勒展開。
XGBoost不會探索所有可能的樹結(jié)構(gòu),而是貪婪地構(gòu)建一棵樹。
XGBoost的正則項會懲罰具有多個葉子節(jié)點的樹結(jié)構(gòu)。
關(guān)于選擇分叉標準,強烈建議閱讀論文:arxiv.org/pdf/1603.02754.pdf
-
梯度
+關(guān)注
關(guān)注
0文章
30瀏覽量
10309 -
機器學習
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132406
原文標題:計算:XGBoost背后的數(shù)學之美
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
傅里葉變換的數(shù)學原理


你知道寬帶背后的技術(shù)原理嗎?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論