") 人臉識別究竟如何工作?亞馬遜、谷歌、IBM、微軟現(xiàn)在在用什么?
人臉識別究竟如何工作?亞馬遜、谷歌、IBM、微軟現(xiàn)在在用什么?
有關(guān)人臉識別的項(xiàng)目我們已經(jīng)介紹了很多了,那么哪種人臉識別的API最好?本文將對比四種API,分別是亞馬遜Rekognition、谷歌Cloud Vision API、IBM Watson Visual Recognition以及微軟的Face API,從成功率、價(jià)格和速度三方面分析上述四種軟件服務(wù)商的產(chǎn)品。
人臉識別究竟如何工作?
深入分析之前,首先讓我們探究一下人臉識別的工作原理。
Viola-Jones的人臉識別
2001年,Paul Viola和Michael Jone開始了計(jì)算機(jī)視覺的革命,當(dāng)時(shí)的人臉識別技術(shù)并不成熟,識別準(zhǔn)確度較低,速度也很慢。直到提出了Viola-Jones人臉識別框架后,不僅成功率大大提高,而且還能實(shí)施進(jìn)行人臉識別。
自從上世紀(jì)90年代開展了各項(xiàng)人臉識別、目標(biāo)識別挑戰(zhàn)賽,這類技術(shù)得到了迅猛發(fā)展。
2010年,ImageNet視覺識別挑戰(zhàn)賽開始舉辦,前兩年,大部分參賽隊(duì)伍都用Fisher Vectors和支持向量機(jī)的結(jié)合。但2012年,一切都變了。
多倫多大學(xué)的團(tuán)隊(duì)(Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton)第一次在目標(biāo)物體識別任務(wù)上使用了深度卷積神經(jīng)網(wǎng)絡(luò),并拿到冠軍。他們使用的方法錯(cuò)誤率為15.4%,而第二名的錯(cuò)誤率為26.2%。到了2013年,前5名的隊(duì)伍全部都開始用深度卷積神經(jīng)網(wǎng)絡(luò)。
所以,神經(jīng)網(wǎng)絡(luò)到底怎么工作的呢?
亞馬遜、谷歌、IBM、微軟現(xiàn)在在用什么?
目前為止,各大公司仍然使用深度卷積神經(jīng)網(wǎng)絡(luò)或者結(jié)合其他深度學(xué)習(xí)技術(shù)進(jìn)行人臉識別。
亞馬遜:aws.amazon.com/cn/rekognition/faqs/
谷歌:www.youtube.com/watch?v=OcycT1Jwsns&feature=youtu.be&t=2m41s
IBM:www.ibm.com/cloud/watson-visual-recognition
微軟:docs.microsoft.com/en-us/azure/cognitive-services/face/overview
這四種工具看起來都差不多,但是結(jié)果還有些許不同。首先我們從價(jià)格看起。
價(jià)格
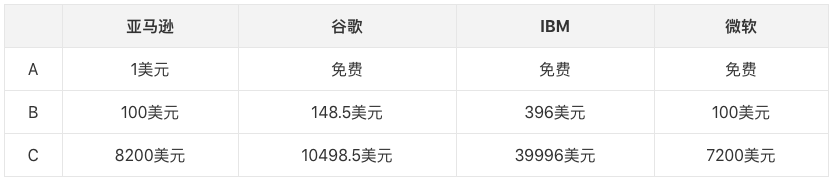
亞馬遜、谷歌和微軟三家的價(jià)格模式類似,都是用量越多收費(fèi)越少。但是IBM不同,當(dāng)你的免費(fèi)額度用完后,每個(gè)API接口的價(jià)錢都是一樣的。四種工具中,微軟的免費(fèi)額度是最高的,每月可處理30000張圖片。
價(jià)格對比
現(xiàn)有以下三種情況:
A:小型創(chuàng)業(yè)公司每月處理1000張圖片
B:數(shù)字生產(chǎn)商每月處理10萬張圖片
C:數(shù)據(jù)中心每月處理1000萬張圖片
動(dòng)手試試
本文所用代碼可在我的GitHub中找到:github.com/dpacassi/face-detection
建立圖像數(shù)據(jù)集
要做人臉識別,首先就要建立數(shù)據(jù)集。本文所用到的圖像是從pexels網(wǎng)站上下載的,你可以直接到我的GitHub中下載。
編寫基礎(chǔ)測試框架
說是“框架”,實(shí)際上我的自定義代碼只有兩種類別。然而,這兩種類別很容易地就幫我分析了原始圖像數(shù)據(jù),在不同的任務(wù)上也只需要少量代碼。
FaceDetectionClient中記錄了圖片存儲的信息、四種工具的細(xì)節(jié)以及所有處理過的圖像。
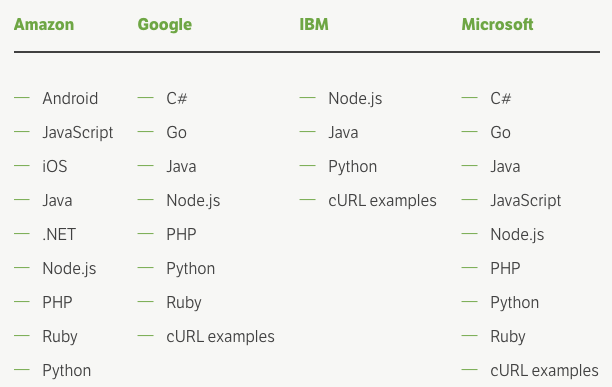
比較四種SDK
以下是四種工具支持的語言:
inter-rater 可信度
在讓計(jì)算機(jī)進(jìn)行人臉識別之前,我先記錄下了自己所觀察到的圖片中人臉數(shù)量。同時(shí),我還找了三位同時(shí)對圖片進(jìn)行識別。
什么是人臉?
我在進(jìn)行手動(dòng)標(biāo)記時(shí),只要露出四分之一臉就算一個(gè)人臉,而我的同事們有的會(huì)把不明顯的也算作人臉,或者看到眼睛、鼻子就算一張臉。所以每個(gè)人的判斷標(biāo)準(zhǔn)不同。
對這張圖,我們四人有不同的結(jié)論,分別是10張、13張、16張和16張人臉。所以我打算取平均值,14。
比較結(jié)果
圖中可以看出,微軟智能達(dá)到17.55%的人臉檢測率,為什么成功率如此低?首先,圖片數(shù)據(jù)集中的確有一些故意刁難識別器的圖像,另外要知道,機(jī)器的能力比人類還差得遠(yuǎn),想提高人臉識別的效率,還有很大的進(jìn)步空間。
雖然亞馬遜的工具能檢測出最多的人臉,但是谷歌和微軟的處理時(shí)間明顯更快。
另外,在人臉相對較小的圖片中,同樣還是亞馬遜表現(xiàn)得更好:
在這張圖片中,亞馬遜檢測出了10個(gè)人臉,而谷歌為4,IBM和微軟都是0。
不同角度和不完整人臉
看了上面的例子,可能會(huì)覺得IBM不中用。IBM的作用在普通圖片上一般般,但是在難度更大的圖片上,IBM的能力就很大了。尤其是在不常見的角度進(jìn)行人臉識別或者殘缺人臉識別。例如下面三張圖片的人臉只有IBM識別了出來:
邊界框
沒錯(cuò),各家的邊界框也有差別。亞馬遜、IBM和微軟都會(huì)返回只含有人臉的邊界框。而谷歌不光會(huì)圈起來人臉,會(huì)連帶整個(gè)頭部一起選中。
谷歌
微軟
看出差別了嗎?
誤報(bào)率
雖然我的數(shù)據(jù)集很小(只有33張照片),但是有兩張圖沒有模型識別出人臉。
亞馬遜和谷歌都只識別出了上圖中紋身中的頭像,而微軟識別失敗。只有IBM正確識別到了前面吉他手的人臉。恭喜IBM!
這張照片,谷歌在同一區(qū)域檢測出了兩張人臉。莫非看到了人眼看不到的東西?(細(xì)思極恐)
結(jié)語
雖然每種工具都有自己的有缺點(diǎn),但總的來說,亞馬遜、谷歌和IBM還不錯(cuò),微軟就很一般了,它的分?jǐn)?shù)最低。
微軟竟然沒檢測出其中的人臉
在本系列的下一篇文章中,我們會(huì)對比OpenCV以及其他開源工具,請繼續(xù)關(guān)注!
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100566 -
人臉識別
+關(guān)注
關(guān)注
76文章
4007瀏覽量
81783 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24649
原文標(biāo)題:人臉識別哪家強(qiáng)?四種API對比
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論