 最先進的NLP模型很脆弱!最先進的NLP模型是虛假的!
最先進的NLP模型很脆弱!最先進的NLP模型是虛假的!
在自然語言處理領域,泛化(Generalization)一直是研究人員激烈討論和競相研究的課題。
近期,不少機構媒體發布報道稱,機器在閱讀理解任務上,在確定某個語句是否在語義上需要另一個給定的陳述的任務上,以及在翻譯任務上的表現都優于人類。由此他們給出的結論是,如果機器可以完成所有這些任務,那么它們就具備真正的語言理解和推理能力。
但是,這根本就是假的。最近的許多研究表明,即便是最先進的NLP模型,它的背后依然充滿脆弱和虛假。
最先進的NLP模型很脆弱
如果我們在不改變原意的基礎上對原文做一些修改,模型可能會出現錯誤:
斯坦福大學的Jia和Liang,發現BiDAF模型在閱讀理解任務上存在巨大問題

只是在末尾加了一句不改變句意的話(紅字),模型的回答就從布拉格變成了芝加哥
MIT的Belinkov和華盛頓大學的Bisk,發現神經機器翻譯模型并不需要基于角色

只是微調了角色名稱,模型的BLEU分數就暴跌了
Iyyer等人,發現情緒分類模型不一定需要樹形結構的雙向LSTM

只是改變了語序,模型預測就從“積極”變成了“消極”
最先進的NLP模型是虛假的
模型只會記住人為設定的規則和偏見,但這并不是真正的學習:
Gururangan等人,發現我們只需查看假設而不觀察前提,就能利用標簽對超過50%的NLP數據集樣本進行正確分類
Moosavi和Strube,發現共指消解模型deep-coref如果主要依賴于詞法特征,比如在帶國家/地區名稱的樣本上訓練,那么它在不帶國家的文本上的表現往往會很差。同時,Levy等人研究了用于識別兩個詞之間的詞匯推理關系模型,發現這些模型學習的不是單詞之間關系特征,而是其中某一個詞的獨立屬性:這個單詞是否是一個“原型上位詞”,如動物。

Agrawal等人,發現用CNN+LSTM解決QA問題時,模型會“聽”到一半就收斂到預測答案。也就是說,該模型很大程度上受訓練數據中的表面相關性影響,缺乏對概念組合問題的理解。
是搶答,還是瞎蒙?
關于改善NLP模型的研討會
綜上所述,因此,盡管在基準數據集上表現良好,但在理解新的、從未見過的自然語言文本時,現代NLP技術在語言理解和推理方面還遠不及人類。這也一直是機器學習的核心挑戰。在之前舉辦的NAACL研討會上,與會專家圍繞這個核心討論了兩方面內容:
我們該如何充分衡量系統在新的、從未見過的輸入上的表現?或者換句話說,我們該如何充分衡量系統的概括性?
我們該如何修改模型,以便它擁有更好的泛化能力?
這兩個問題都很棘手,顯然,為期一天的研討會肯定討論不出什么結果。但是在會議現場,一些有遠見卓識的NLP研究人員還是探討了不少方法和想法,其中有一些尤其值得關注。在下文中,我們會介紹它們中的三個主題:巧妙地使用更多歸納偏置;努力構建有“常識”的NLP模型;使用沒見過的分布和沒見過的任務。
主題1:巧妙使用更多歸納偏置
當學習器遇到從未見過的任務時,它會作出假設,而歸納偏置就是用于學習輸入到輸出映射函數的一組假設。
去年,Yann LeCun和Christopher Manning曾有過一場辯論,他們討論的主題是我們是否應該在深度學習系統的架構中建立先驗。Manning是將更多語言結構納入深度學習系統的主要倡導者,而Yann LeCun則認為簡單的神經網絡已經能夠處理復雜任務,他把先驗稱為“必要之惡”,指出某些假設會限制系統發展。
站在Yann LeCun的立場上看,他有一個令人信服的論點,即如果在現代模型中加入面向語言的偏置,這些模型在基準任務上的性能往往不怎么好。但是,目前NLP領域還是廣泛支持Manning的說法,ACL 2017上一個值得注意的趨勢就是在神經結構中引入語言結構。
然而,學界對這種觀點的支持似乎沒有達到預期效果,這不是說大家錯了,而是如果想讓模型性能提高,現有偏置必須被整合歸納成全新的形式,按Manning的話來講,就是:
我們應該收集更多的歸納偏置。正是因為對如何添加歸納偏置一無所知,我們才要做數據增強、創建偽訓練數據編碼這些偏置。盡管這似乎是一種奇怪的做事方式。
這也是Yejin Choi在自然語言生成(NLG)任務上遇到的問題。她在會議上展示了由常規語言模型——一個帶集束搜索解碼器的門控RNN生成的評論樣本。
自然語言輸入:
All in all, I would highly recommend this hotel to anyone who wants to be in the heart of the action.
不自然的輸出,重復、矛盾、平淡:
All in all, I would highly recommend this hotel to anyone who wants to be in the heart of the action, and want to be in the heart of the action. If you want to be in the heart of the action, this is not the place for you. However, if you want to be in the middle of the action, this is the place to be.
在她看來,當前的語言模型正在生成不自然的語言,因為它們是:
被動學習者。雖然同樣是閱讀文本并生成輸出,人類學習者可以把適當的語言標準(如相關性、風格、重復和蘊涵)反映到生成的內容中,但模型不能。換句話說,它們不“練習”寫作。
表面學習者。它們不會捕捉事實、實體、事件和活動之間的高階關系,這對人類來說可能是語言理解的關鍵線索。換句話說,它們不了解我們的世界。
如果我們鼓勵模型用特定的損失函數以數據驅動的方式學習語言特征,那么它確實正在“練習”寫作。相比自然語言理解(NLU),這種方法更好,因為NLU一般只處理自然語言,它并不能理解機器語言,比如上述輸出這類重復、矛盾、平淡的表達。用無法理解機器語言的先驗教模型生成自然語言是沒有意義的。
總之,我們應該改進的是這些偏置的數據驅動方法,而不是開發引入結構偏置的新型神經架構。
事實上,自然語言生成(NLG)并不是需要優化學習器的唯一NLP任務。在機器翻譯中,目前涉及優化的一個嚴重問題在于模型訓練,在訓練過程中我們要用到交叉熵之類的損失函數,但這些函數已經被證明存在偏差, 而且和人類判斷不充分相關。只要我們使用這種簡單的度量標準訓練我們的模型,模型的預測就一定會和人類判斷存在不匹配。
因此,考慮到任務目標過于復雜,強化學習似乎成了NLP的一個完美選擇,因為它允許模型通過反復試驗在模擬環境中學習類似人類的監督信號(“獎勵”)。
主題2:常識性知識
雖然“常識”在人類眼里很常見,但我們很難把它教給機器,比如為什么要進行對話?為什么要回復電子郵件?為什么要總結文檔?
這些任務的輸入和輸出之間缺乏一對一的映射,如果要解決它們,機器首先要建立起關于人類世界的整體認知,無論是知識、總結還是推理。換句話說,只要模式匹配(現代NLP)沒有掌握人類“常識”的概念,它們就不可能解決這些問題。
Choi用一個簡單但有效的新聞標題“Cheeseburger stabbing”來說明這一點。
在這里,只知道“stabbing”和名詞“Cheeseburger”之間的依賴關系是不足以理解其中的真正含義的。把這個標題輸入模型后,機器可能會據此提出幾個合理的問題:
有人因為芝士漢堡上刺傷了其他人? 有人刺傷了一個芝士漢堡? 一個芝士漢堡刺傷了某人? 這個芝士漢堡刺傷了另一個芝士漢堡?
這實際上是一篇男子因為漢堡發生爭執而刺傷母親的報道。如果機器有社會、生理常識,它們就不會問出荒謬的問題。因為社會常識會告訴它,第一個選項是合理的,因為刺傷某人影響惡劣,有新聞價值,而刺傷漢堡沒有人會關心。而“生理常識”會告訴它,漢堡是不能被作為兇器刺傷別人的。
除了整合常識性知識,Choi還建議把“通過標簽理解”改成“通過模擬理解”,因為前者只關注“說了什么”,后者模擬了文本隱含的因果效應,不僅包含“說了什么”,也包含“沒有說出口但表達了什么”。下面是一個說明隱含因果效應對預測很重要的示例:
根據食譜上“將藍莓添加到松餅混合物中,然后烘烤半小時”的說法,智能體必須能預測這樣一些必要的事實,例如藍莓現在正在烤箱中;混合物的溫度會上升。
此外,在完型填空式的閱讀理解任務中,目前模型推斷答案所需的大部分信息都來自給定的故事,但如果有額外的常識性知識,效果會更好。
需要常識的完型填空式閱讀理解
很可惜,我們必須承認,現代NLP技術的工作方式就像“沒有大腦的嘴”。為了改變這一點,我們必須為他們提供常識,并教導他們推理未說但隱含的內容。
RNN是“沒有大腦的嘴”嗎?
主題3:評估未知的分布和未知的任務
用監督學習解決問題的標準方法包括以下步驟:
決定如何標記數據;
手動標記數據;
將標記的數據分成訓練集、測試集和驗證集,保證它們的數據分布盡量一致;
覺得如何表示輸入;
學習從輸入到輸出的映射函數;
根據失當度量,用測試集檢驗模型學習效果。
按照這種方法,如果我們要解決下圖這個問題,我們需要標記數據,訓練識別目標的模型,考慮多種表征和解釋(圖片、文本、分布、拼寫、語音),并將它們放在一起。直到模型最終確定一個“最佳”全局解,并讓人類對這個解感到滿意。
一個很難標記的輸入樣本
Dan Roth認為:
現有標準方法不可擴展。我們永遠不會有足夠的標記數據來訓練針對所有任務的所有模型。為了解決上圖中的難題,一種方法是訓練5個不同的組件然后合并,另一種方法是需要大量數據來訓練端到端模型。盡管可以使用諸如ImageNet之類的可用資源來解決圖像識別,但這個預測結果并不能反映在這個語境下,單詞“world”比單詞“globe”更好。即便我們有大量注釋人員每天不停工作,他們的速度也趕不上流行文化數據更新的速度。
如果訓練數據和測試數據分布相似,那其實任何有足夠訓練數據的模型都能完成這個任務。但是,如果是訓練集、測試集、驗證集中從未出現過的新事物,那么為了確保模型性能,我們必須設計一個更“正確”的方案。
在訓練和測試過程中推斷相同的任務被稱為domain adaptation,這是近幾年很多人關注的一個點。
一些人開始嘗試在訓練和測試過程中推斷不同任務。比如李等人訓練了一個只用給定句子的屬性標簽就能完成文本屬性轉變的模型,不需要在語料庫中對具有不同屬性和相同內容的句子配對。換句話說,他們訓練了一個模型,它先作為分類器預測句子數據,之后再進行文本屬性轉變。同樣的,Selsam等人訓練了一個學習解決SAT問題的模型,也是先分類,再具體解決。
值得注意的是,兩種模型都大量使用了歸納偏置,前者使用的假設是屬性通常表現在局部判別性短語中;后者則捕獲了調查傳播的歸納偏差。
此外,研討會還討論了要不要構建“壓力測試數據集”。它不同于基準測試,檢驗的是模型的超水平發揮,以便觀察它的泛化性能。
模型只有在解決了更容易的案例之后才有機會解決更難的問題,所以根據難度對樣本進行分類是合理的。但是,考慮到現在我們還不清楚哪些問題是模型確實難以解決的,如果一開始就把“更難”的問題定義為模型無法解決的問題,那這種方法就有潛在危險。
小結
綜合全文,我們可以對這屆NAACL研討會做出一下總結:
我們應該使用更多的歸納偏置,但是我們必須找出將它們集成到神經架構中的最合適的方法,這樣它們才能真正實現預期的改進。
我們必須通過一些類似人類的常識概念來增強最先進的NLP模型,使它們能夠捕捉事實、實體、事件或活動之間的高階關系。但是挖掘常識是具有挑戰性的,因此我們需要新的、創造性的方法。
最后,我們應該處理未知的分布和未知的任務,否則只要數據夠,無論什么模型都能解決問題。顯然,訓練這樣的模型更難,結果也不會立竿見影。所以作為研究人員,我們必須大膽地開發這樣的模型,作為審稿人,我們不應該懲罰那些試圖這樣做的工作。
-
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
nlp
+關注
關注
1文章
487瀏覽量
22012
原文標題:NAACL研討會深思:NLP泛化模型背后的虛假和脆弱
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
圖解2018年領先的兩大NLP模型:BERT和ELMo
最先進的數字CMOS圖像傳感器MIS1011(兼容AR0130)
谷歌AutoML系統自動開發出計算機視覺模型,遠超最先進的模型
史上最強通用NLP模型誕生
金融市場中的NLP 情感分析
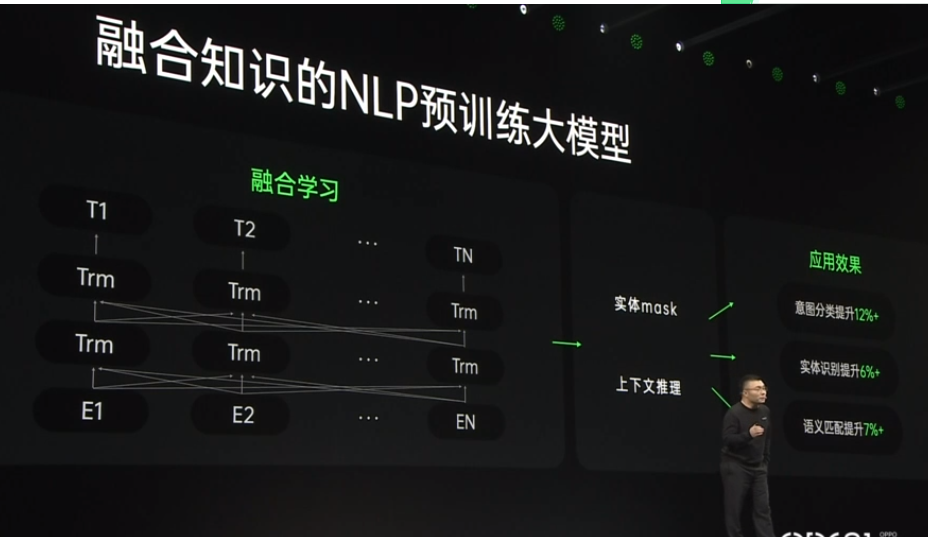
2021 OPPO開發者大會:NLP預訓練大模型






 工商網監
工商網監
評論