 采用CSA與4-2壓縮器改進Wallace樹型乘法器的設計
采用CSA與4-2壓縮器改進Wallace樹型乘法器的設計
引言
在微處理器芯片中,乘法器是進行數字信號處理的核心,同時也是微處理器中進行數據處理的關鍵部件。乘法器完成一次操作的周期基本上決定了微處理器的主頻。乘法器的速度和面積優化對于整個CPU的性能來說是非常重要的。為了加快乘法器的執行速度,減少乘法器的面積,有必要對乘法器的算法、結構及電路的具體實現做深入的研究。
乘法器工作的基本原理是首先生成部分積,再將這些部分積相加得到乘積。在目前的乘法器設計中,基4Booth算法是部分積生成過程中普遍采用的算法。對于N位有符號數乘法A×B來說,常規的乘法運算會產生N個部分積。如果對乘數B進行基4Booth編碼,每次需考慮3位:相鄰高位、本位和相鄰低位,編碼后產生部分積的個數可以減少到[(N+1)/2]?? ([X]取值為不大于X的整數),確定運算量0、±1A、±2A。對于2A的實現,只需要將A左移一位。因此,對于符號數乘法而言,基4 Booth算法既方便又快捷。而對于無符號數來說,只需對其高位作0擴展,而其他處理方法相同。雖然擴展后可能導致部分積的個數比有符號數乘法多1,但是這種算法很好地保證了硬件上的一致性,有利于實現。對于32位乘法來說,結合指令集的設計,通常情況下需要相加的部分積不超過18個。
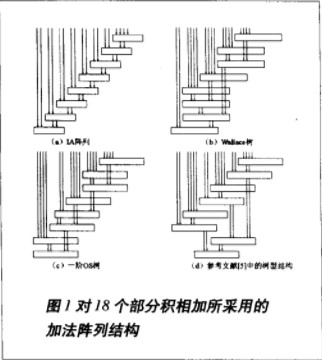
對部分積相加,可以采用不同的加法器陣列結構。而不同的陣列結構將直接影響完成一次乘法所需要的時間,因此,加法器陣列結構是決定乘法器性能的重要因素。重復陣列(Iterative Array,簡稱IA)和Wallace樹型結構是最為典型的兩種加法器陣列結構。IA結構規整,易于版圖實現,但速度最慢且面積大;理論上,Wallace樹型結構是進行乘法操作最快的加法器陣列結構,但傳統的Wallace樹型結構電路互連復雜,版圖實現困難。為了解決這個問題,人們推出了一些連接關系較為簡單的樹型結構,例如ZM樹和OS樹。它們都是將IA樹分為幾段,每段稱之為子樹,子樹內部連接采用IA結構,而子樹間采用樹型連接,以此來降低連接復雜度,但是這種方法降低了部分積相加的速度。
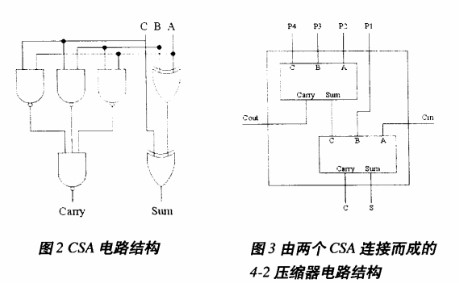
在對樹型結構進行改進的同時,設計者們也嘗試了對加法陣列中基本加法單元的改進。Wallace最早提出的方案中,是以CSA(進位保留加法器)作為基本單元構建加法陣列的。其基本方法是:通過CSA部件,以3∶2的壓縮比對部分積進行逐級壓縮,直到最后只產生兩個輸出為止,再通過進位傳遞加法器對產生的這兩個偽和與局部進位相加得出真正的結果。此后,Dadda提出了一種新的加法單元,稱為“(j,k)計數器”,它有j個輸入和k個輸出,其中j≦2k。經過研究和實踐,人們發現4-2壓縮器(實際上是5-3計數器)具有較好的平衡性和對稱性,用其作為基本加法單元構成的乘法器在總體性能上具有一定的優勢,因此4-2壓縮器也就成為了目前乘法器中較多采用的加法單元。
如前所述,(a)中的IA陣列,結構最為規整,但很明顯,其延時級數大大多于其他結構。(b)是Wallace樹結構,由于采用4-2壓縮器作為唯一的加法單元,而18不能被4整除,因此在對18個部分積的求和過程中,必然要對其中的兩個部分積做額外處理。Wallace樹采取的方法是:先將16個部分積通過三級4-2壓縮器后產生兩個結果,然后與剩下的兩個部分積一起再進行一級4-2壓縮。(c)中的一階OS樹結構也采用了類似的方法,只是在處理的先后順序上有所改變。這兩種結構,都破壞了樹的對稱性,造成路徑的不等長,因此浪費了硬件資源,且增加了布局布線的復雜度。(d)中提出的一種經過改進的樹型結構,其求和過程是:將18個部分積分為3組,先對每組中的6個部分積求和,各產生兩個中間結果,再把這6個中間結果相加。由于對每組中的6個部分積求和,可以采用相同結構的兩組4-2壓縮器,這樣就很好地降低了布局布線的復雜度。其缺點在于:用4-2壓縮器對6個中間結果進行相加的過程中,仍不能避免路徑不平衡的問題,因此,還是使關鍵路徑的延時有不必要的增加。
CSA和4-2壓縮器的電路結構和時延分析
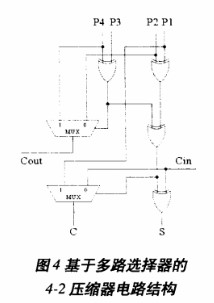
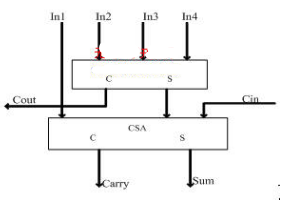
既然CSA和4-2壓縮器是加法陣列中主要采用的基本單元,那么,就有必要對CSA和4-2壓縮器在電路特性方面做一下分析比較。CSA的電路邏輯實際上就是一位全加器,其關鍵路徑上需要經過兩級異或門邏輯的延時。對于4-2壓縮器,可以把它看作是兩個CSA按照圖3形式相連而構成。
但這種未經過優化的電路結構很可能造成關鍵路徑不必要的延長。上文已提到,4-2壓縮器實際上是由5個權1的輸入,產生2個權2的輸出(Cout,C)和1個權1的輸出(S)。而本文之所以稱其為4-2壓縮器而非5-3計數器,是基于這樣一個事實:將此單元作橫向排列后,加數數目可以實現的壓縮比為4:2。
此外,通過平衡路徑,該結構使橫向進位鏈不對關鍵路徑的延遲造成影響,也就是說產生C和S信號所需的時間不決定于Cin信號,電路關鍵路徑為3個異或門的延遲。在90nm工藝條件下,采用Mentor公司的eldoD仿真工具得到的實際電路延遲仿真數據如表1所示。由此可見,一級4-2壓縮器的最大延時約為一級CSA最大延遲的1.5倍,但完成了兩級CSA所做的相加工作。
改進的Wallace樹型乘法器結構及性能比較
對于32位乘法來說,符號數相乘時,基4 Booth編碼形成16個編碼項,并由此產生16個部分積;無符號數相乘時,編碼項與部分積各多出一個。此外,在目前CPU指令集的設計中,乘加/減(C±A×B)指令已被廣泛采用。所以,在一次乘法運算中,加法陣列中需要相加的部分積最多達到18個。而部分積個數對陣列結構的設計有著重大的影響,進而也就影響了布局布線的復雜度以及陣列的延遲級數。這一點在上文對圖1中各個陣列結構的分析中,可以得到很好的證明。

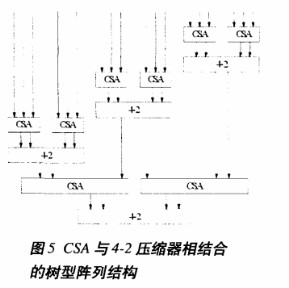
此結構中,采用CSA和4-2壓縮器共同作為基本加法單元,對18個部分積進行壓縮。其具體過程為:先采用CSA對18個部分積做第一次壓縮,產生12個中間結果,再采用4-2壓縮器進行第二次壓縮,然后再分別采用CSA和4-2壓縮器對第二次壓縮產生的6個中間結果和隨后產生的4個中間結果做壓縮,得到最終的兩個偽和,送入進位傳播加法器得到最終結果。該結構通過在第一次和第三次壓縮中采用CSA,使得最初的18個部分積和用4-2壓縮器進行第二次壓縮產生的6個中間結果能夠同時得到處理,使各條路徑在時延上達到平衡,相比于只采用4-2壓縮器作為基本加法單元的陣列,這就節省了不必要的等待時間。與此同時,用兩級CSA取代兩級4-2壓縮器,也使得關鍵路徑的延時有了明顯的縮短,對高速集成電路設計有著很高的實用價值。此外,由圖5可以看出,此結構具有較好的對稱性和規整性,宏模塊數量少,有利于布局布線。同時,對于目前指令集設計中常用的乘法指令,該結構對硬件的利用率也是相當高的。概括地說,該結構保持了傳統Wallace樹型結構求和速度快的優點,又較好地改進了原來那種由單一加法單元構成的陣列的不足。
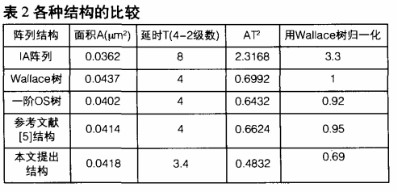
本文在90nm工藝下采用全定制設計方法,利用Cadence的版圖工具Virtuoso對各種情況進行了比較。另外,采用經過4-2壓縮器級數度量關鍵路徑的時延,不考慮互連延時,再通過AT2標準做了進一步的比較。
結語
采用CSA與4-2壓縮器相結合的電路,在對部分積的求和過程中對硬件達到了最為高效的利用。同時,這種結構既發揮了CSA版圖面積小的優點,又體現了4-2壓縮器壓縮比高、速度快的長處,因此,與其他結構相比,本文提出的改進結構在面積和速度上都達到了相對理想的效果。雖然其在布局布線上有一定的復雜度,但與傳統的Wallace樹相比,已取得了頗為可觀的改進。目前,該結構乘法器的版圖設計工作已基本完成,并被用于正在進行的64位高性能嵌入式CPU設計的項目中,預計于2007年3月進行流片。
-
芯片
+關注
關注
453文章
50397瀏覽量
421796 -
微處理器
+關注
關注
11文章
2247瀏覽量
82312 -
乘法器
+關注
關注
8文章
205瀏覽量
36975
發布評論請先 登錄
相關推薦
怎么實現32位浮點陣列乘法器的設計?
基于跳躍式Wallace樹的低功耗32位乘法器
基于FPGA 的單精度浮點數乘法器設計

基于IP核的乘法器設計
基于FPGA的WALLACE TREE乘法器設計
基于FPGA的高速流水線浮點乘法器設計與實現
乘法器原理_乘法器的作用

采用Gillbert單元如何實現CMOS模擬乘法器的應用設計





 工商網監
工商網監
評論