 一文讀懂人工智能CLDNN網絡結構
一文讀懂人工智能CLDNN網絡結構
作者:侯藝馨
前言
總結目前語音識別的發展現狀,dnn、rnn/lstm和cnn算是語音識別中幾個比較主流的方向。2012年,微軟鄧力和俞棟老師將前饋神經網絡FFDNN(Feed Forward Deep Neural Network)引入到聲學模型建模中,將FFDNN的輸出層概率用于替換之前GMM-HMM中使用GMM計算的輸出概率,引領了DNN-HMM混合系統的風潮。長短時記憶網絡(LSTM,LongShort Term Memory)可以說是目前語音識別應用最廣泛的一種結構,這種網絡能夠對語音的長時相關性進行建模,從而提高識別正確率。雙向LSTM網絡可以獲得更好的性能,但同時也存在訓練復雜度高、解碼時延高的問題,尤其在工業界的實時識別系統中很難應用。
回顧近一年語音識別的發展,deep cnn絕對稱得上是比較火的關鍵詞,很多公司都在這方面投入了大量研究。其實 CNN 被用在語音識別中由來已久,在 12、13 年的時候 Ossama Abdel-Hamid 就將 CNN 引入了語音識別中。那時候的卷積層和 pooling 層是交替出現的,并且卷積核的規模是比較大的,CNN 的層數也并不多, 主要是用來對特征進行加工和處理,使其能更好的被用于 DNN 的分類。隨著CNN在圖像領域的發光發熱,VGGNet,GoogleNet和ResNet的應用,為CNN在語音識別提供了更多思路,比如多層卷積之后再接 pooling 層,減小卷積核的尺寸可以使得我們能夠訓練更深的、效果更好的 CNN 模型。
1、語音識別為什么要用CNN
通常情況下,語音識別都是基于時頻分析后的語音譜完成的,而其中語音時頻譜是具有結構特點的。要想提高語音識別率,就是需要克服語音信號所面臨各種各樣的多樣性,包括說話人的多樣性(說話人自身、以及說話人間),環境的多樣性等。一個卷積神經網絡提供在時間和空間上的平移不變性卷積,將卷積神經網絡的思想應用到語音識別的聲學建模中,則可以利用卷積的不變性來克服語音信號本身的多樣性。從這個角度來看,則可以認為是將整個語音信號分析得到的時頻譜當作一張圖像一樣來處理,采用圖像中廣泛應用的深層卷積網絡對其進行識別。
從實用性上考慮,CNN也比較容易實現大規模并行化運算。雖然在CNN卷積運算中涉及到很多小矩陣操作,運算很慢。不過對CNN的加速運算相對比較成熟,如Chellapilla等人提出一種技術可以把所有這些小矩陣轉換成一個大矩陣的乘積。一些通用框架如Tensorflow,caffe等也提供CNN的并行化加速,為CNN在語音識別中的嘗試提供了可能。
下面將由“淺”入“深”的介紹一下cnn在語音識別中的應用。
2、CLDNN
提到CNN在語音識別中的應用,就不得不提CLDNN(CONVOLUTIONAL, LONG SHORT-TERM MEMORY,FULLY CONNECTED DEEP NEURAL NETWORKS)[1],在CLDNN中有兩層CNN的應用,算是淺層CNN應用的代表。CNN 和 LSTM 在語音識別任務中可以獲得比DNN更好的性能提升,對建模能力來說,CNN擅長減小頻域變化,LSTM可以提供長時記憶,所以在時域上有著廣泛應用,而DNN適合將特征映射到獨立空間。而在CLDNN中,作者將CNN,LSTM和DNN串起來融合到一個網絡中,獲得比單獨網絡更好的性能。
CLDNN網絡的通用結構是輸入層是時域相關的特征,連接幾層CNN來減小頻域變化,CNN的輸出灌入幾層LSTM來減小時域變化,LSTM最后一層的輸出輸入到全連接DNN層,目的是將特征空間映射到更容易分類的輸出層。之前也有將CNN LSTM和DNN融合在一起的嘗試,不過一般是三個網絡分別訓練,最后再通過融合層融合在一起,而CLDNN是將三個網絡同時訓練。實驗證明,如果LSTM輸入更好的特征其性能將得到提高,受到啟發,作者用CNN來減小頻域上的變化使LSTM輸入自適應性更強的特征,加入DNN增加隱層和輸出層之間的深度獲得更強的預測能力。
2.1 CLDNN網絡結構
Fig 1. CLDNN Architecture網絡結構圖如圖1,假設中心幀為,考慮到內容相關性,向左擴展L幀,向右擴展R幀,則輸入特征序列為[, . . . ,],特征向量使用的是40維的log梅爾特征。
CNN部分為兩層CNN,每層256個feature maps,第一層采用9x9 時域-頻域濾波器,第二層為4x3的濾波器。池化層采用max-pooling策略,第一層pooling size是3,第二層CNN不接池化層。
由于CNN最后一層輸出維度很大,大小為feature-mapstimefrequency,所以在CNN后LSTM之前接一個線性層來降維,而實驗也證明降維減少參數并不會對準確率有太大影響,線性層輸出為256維。
CNN后接2層LSTM,每個LSTM層采用832個cells,512維映射層來降維。輸出狀態標簽延遲5幀,此時DNN輸出信息可以更好的預測當前幀。由于CNN的輸入特征向左擴展了l幀向右擴展了r幀,為了確保LSTM不會看到未來多于5幀的內容,作者將r設為0。最后,在頻域和時域建模之后,將LSTM的輸出連接幾層全連接DNN層。
借鑒了圖像領域CNN的應用,作者也嘗試了長短時特征,將CNN的輸入特征作為短時特征直接輸入給LSTM作為部分輸入,CNN的輸出特征直接作為DNN的部分輸入特征。
2.2 實驗結果
針對CLDNN結構,我們用自己的中文數據做了一系列實驗。實驗數據為300h的中文有噪聲語音,所有模型輸入特征都為40維fbank特征,幀率10ms。模型訓練采用交叉熵CE準則,網絡輸出為2w多個state。由于CNN的輸入需要設置l和r兩個參數,r設為0,l經過實驗10為最優解,后面的實驗結果中默認l=10,r=0。
其中LSTM為3層1024個cells,project為512 ,CNN+LSTM和CNN+LSTM+DNN具體的網絡參數略有調整,具體如下圖,另外還增加一組實驗,兩層CNN和三層LSTM組合,實驗驗證增加一層LSTM對結果有提高,但繼續增加LSTM的層數對結果沒有幫助。
Fig 2. CLDNN實驗結構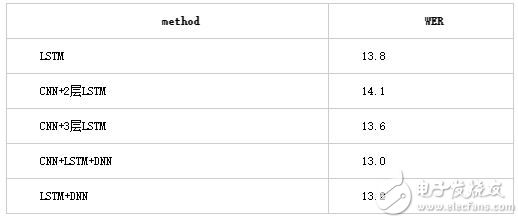 Table 1 測試集1結果
Table 1 測試集1結果
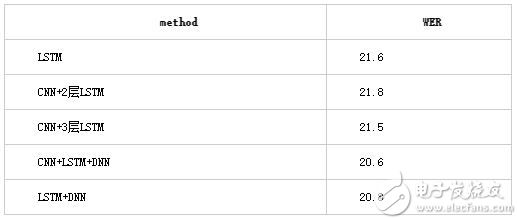 Table 2 測試集2結果
Table 2 測試集2結果
3、deep CNN
在過去的一年中,語音識別取得了很大的突破。IBM、微軟、百度等多家機構相繼推出了自己的Deep CNN模型,提升了語音識別的準確率。Residual/Highway網絡的提出使我們可以把神經網絡訓練的更深。嘗試Deep CNN的過程中,大致也分為兩種策略:一種是HMM 框架中基于 Deep CNN結構的聲學模型,CNN可以是VGG、Residual 連接的 CNN 網絡結構、或是CLDNN結構。另一種是近兩年非常火的端到端結構,比如在 CTC 框架中使用CNN或CLDNN實現端對端建模,或是最近提出的Low Frame Rate、Chain 模型等粗粒度建模單元技術。
對于輸入端,大體也分為兩種:輸入傳統信號處理過的特征,采用不同的濾波器處理,然后進行左右或跳幀擴展。
Fig 3.Multi-scale input feature. Stack 31140第二種是直接輸入原始頻譜,將頻譜圖當做圖像處理。
Fig 4. Frequency bands input
3.1 百度deep speech
百度將 Deep CNN 應用于語音識別研究,使用了 VGGNet ,以及包含Residual 連接的深層 CNN等結構,并將 LSTM 和 CTC 的端對端語音識別技術相結合,使得識別錯誤率相對下降了 10% (原錯誤率的90%)以上。
此前,百度語音每年的模型算法都在不斷更新,從 DNN ,到區分度模型,到 CTC 模型,再到如今的 Deep CNN 。基于 LSTM-CTC的聲學模型也于 2015 年底已經在所有語音相關產品中得到了上線。比較重點的進展如下:1)2013 年,基于美爾子帶的 CNN 模型 2)2014年,Sequence Discriminative Training(區分度模型) 3)2015 年初,基于 LSTM-HMM的語音識別 4)2015 年底,基于 LSTM-CTC的端對端語音識別 5)2016 年,Deep CNN 模型,目前百度正在基于Deep CNN 開發deep speech3,據說訓練采用大數據,調參時有上萬小時,做產品時甚至有 10 萬小時。
Fig5. 百度語音識別發展百度發現,深層 CNN 結構,不僅能夠顯著提升 HMM 語音識別系統的性能,也能提升 CTC 語音識別系統的性能。僅用深層 CNN 實現端對端建模,其性能相對較差,因此將如 LSTM 或 GRU的 循環隱層與 CNN結合是一個相對較好的選擇。可以通過采用 VGG 結構中的 3*3 這種小 kernel ,也可以采用 Residual 連接等方式來提升其性能,而卷積神經網絡的層數、濾波 個數等都會顯著影響整個模型的建模能力,在不同規模的語音訓練數據庫上,百度需要采用不同規模的 DeepCNN 模型配置才能使得最終達到最優的性能。
因此,百度認為:1)在模型結構中,DeepCNN 幫助模型具有很好的在時頻域上的平移不變性,從而使得模型更加魯棒(抗噪性) 2)在此基礎上,DeepLSTM 則與 CTC 一起專注于序列的分類,通過 LSTM 的循環連接結構來整合長時的信息。3)在 DeepCNN 研究中,其卷積結構的時間軸上的感受野,以及濾波 的個數,針對不同規模的數據庫訓練的語音識別模型的性能起到了非常重要的作用。4)為了在數萬小時的語音數據庫上訓練一個最優的模型,則需要大量的模型超參的調優工作,依托多機多 GPU 的高性能計算平臺,才得以完成工作。5)基于 DeepCNN 的端對端語音識別引擎,也在一定程度上增加了模型的計算復雜度,通過百度自研的硬件,也使得這樣的模型能夠為廣大語音識別用戶服務。
3.2 IBM
2015 年,IBM Watson 公布了英語會話語音識別領域的一個重大里程 :系統在非常流行的評測基準 Switchboard 數據庫中取得了 8% 的詞錯率(WER)。到了2016年 5 月份,IBM Watson 團隊再次宣布在同樣的任務中他們的系統創造了6.9% 的詞錯率新紀錄,其解碼部分采用的是HMM,語言模型采用的是啟發性的神經網絡語言模型。聲學模型主要包含三個不同的模型,分別是帶有maxout激活的循環神經網絡、3*3卷積核的深度卷積神經網絡、雙向長短期記憶網絡,下面我們來具體看看它們的內部結構。
Fig 6. IBM Deep CNN 框架非常深的卷積神經網絡的靈感來自2014ImageNet參賽的VGG網絡,中心思想是使用較小的3*3卷積核來取代較大的卷積核,通過在池化層之前疊加多層卷積網絡,采取ReLU激活函數,可以獲得相同的感知區域,同時具備參數數目較少和更多非線性的優點。
如上圖所示,左1為最經典的卷積神經網絡,只使用了兩個卷積層,并且之間包含一個池化層,卷積層的卷積核也較大,99和43,而卷積的特征面也較多,512張卷積特征面。
左2、左3、左4均為深度卷積神經網絡的結構,可以注意到與經典的卷積神經網絡所不同的是,卷積的特征面由64個增加到128個再增加到256個,而且池化層是放在卷積的特征面數增加之前的;卷積核均使用的是較小的33卷積核,池化層的池化大小由21增加到2*2。
最右邊10-conv的參數數目與最左邊的經典卷積神經網絡參數數目相同,但是收斂速度卻足足快了5倍,盡管計算復雜度提高了一些。
3.3 微軟
2016年9月在產業標準 Switchboard 語音識別任務上,微軟研究者取得了產業中最低的 6.3% 的詞錯率(WER)。基于神經網絡的聲學和語言模型的發展,數個聲學模型的結合,把 ResNet 用到語音識別。
而在2016年的10月,微軟人工智能與研究部門的團隊報告出他們的語音識別系統實現了和專業速錄員相當甚至更低的詞錯率(WER),達到了5.9%。5.9% 的詞錯率已經等同于人速記同樣一段對話的水平,而且這是目前行Switchboard 語音識別任務中的最低記錄。這個里程意味著,一臺計算機在識別對話中的詞上第一次能和人類做得一樣好。系統性地使用了卷積和 LSTM 神經網絡,并結合了一個全新的空間平滑方法(spatial smoothing method)和 lattice-free MMI 聲學訓練。
雖然在準確率的突破上都給出了數字基準,微軟的研究更加學術,是在標準數據庫——口語數據庫 switchboard 上面完成的,這個數據庫只有 2000 小時。
3.4 Google
根據 Mary Meeker 年度互聯網報告,Google以機器學習為背景的語音識別系統,2017年3月已經獲得英文領域95%的字準確率,此結果逼近人類語音識別的準確率。如果定量的分析的話,從2013年開始,Google系統已經提升了20%的性能。
Fig 7. Google 語音識別性能發展從近幾年google在各類會議上的文章可以看出,google嘗試deep CNN的路徑主要采用多種方法和模型融合,如Network-in-Network (NiN),Batch Normalization (BN),Convolutional LSTM (ConvLSTM)方法的融合。比如2017 icassp會議中google所展示的結構
Fig 8. [5] includes two convolutional layer at the bottom andfollowed by four residual block and LSTM NiN block. Each residual blockcontains one convolutional LSTM layer and one convolutional layer.3.5 科大訊飛DFCNN
2016年,在提出前饋型序列記憶網絡FSMN (Feed-forward Sequential Memory Network) 的新框架后,科大訊飛又提出了一種名為深度全序列卷積神經網絡(Deep Fully Convolutional Neural Network,DFCNN)的語音識別框架,使用大量的卷積層直接對整句語音信號進行建模,更好地表達了語音的長時相關性。
DFCNN的結構如下圖所示,它輸入的不光是頻譜信號,更進一步的直接將一句語音轉化成一張圖像作為輸入,即先對每幀語音進行傅里葉變換,再將時間和頻率作為圖像的兩個維度,然后通過非常多的卷積層和池化(pooling)層的組合,對整句語音進行建模,輸出單元直接與最終的識別結果比如音節或者漢字相對應。
Fig 9. DFCNN框架首先,從輸入端來看,傳統語音特征在傅里葉變換之后使用各種人工設計的濾波器組來提取特征,造成了頻域上的信息損失,在高頻區域的信息損失尤為明顯,而且傳統語音特征為了計算量的考慮必須采用非常大的幀移,無疑造成了時域上的信息損失,在說話人語速較快的時候表現得更為突出。因此DFCNN直接將語譜圖作為輸入,相比其他以傳統語音特征作為輸入的語音識別框架相比具有天然的優勢。其次,從模型結構來看,DFCNN與傳統語音識別中的CNN做法不同,它借鑒了圖像識別中效果最好的網絡配置,每個卷積層使用3x3的小卷積核,并在多個卷積層之后再加上池化層,這樣大大增強了CNN的表達能力,與此同時,通過累積非常多的這種卷積池化層對,DFCNN可以看到非常長的歷史和未來信息,這就保證了DFCNN可以出色地表達語音的長時相關性,相比RNN網絡結構在魯棒性上更加出色。最后,從輸出端來看,DFCNN還可以和近期很熱的CTC方案完美結合以實現整個模型的端到端訓練,且其包含的池化層等特殊結構可以使得以上端到端訓練變得更加穩定。
4、總結
由于CNN本身卷積在頻域上的平移不變性,同時VGG、殘差網絡等深度CNN網絡的提出,給CNN帶了新的新的發展,使CNN成為近兩年語音識別最火的方向之一。用法也從最初的2-3層淺層網絡發展到10層以上的深層網絡,從HMM-CNN框架到端到端CTC框架,各個公司也在deep CNN的應用上取得了令人矚目的成績。
總結一下,CNN發展的趨勢大體為:
1 更加深和復雜的網絡,CNN一般作為網絡的前幾層,可以理解為用CNN提取特征,后面接LSTM或DNN。同時結合多種機制,如attention model、ResNet 的技術等。
2 End to End的識別系統,采用端到端技術CTC , LFR 等。
3 粗粒度的建模單元,趨勢為從state到phone到character,建模單元越來越大。
但CNN也有局限性,[2,3]研究表明,卷積神經網絡在訓練集或者數據差異性較小的任務上幫助最大,對于其他大多數任務,相對詞錯誤率的下降一般只在2%到3%的范圍內。不管怎么說,CNN作為語音識別重要的分支之一,都有著極大的研究價值。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100561 -
語音識別
+關注
關注
38文章
1725瀏覽量
112562 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237662 -
科大訊飛
+關注
關注
19文章
789瀏覽量
61195
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
FPGA在人工智能中的應用有哪些?
人工智能神經元的基本結構
人工智能神經網絡系統的特點
5G智能物聯網課程之Aidlux下人工智能開發(SC171開發套件V1)
嵌入式人工智能的就業方向有哪些?
如何優化PLC的網絡結構?






 工商網監
工商網監
評論