 采用FPGA器件與流水線技術實現浮點乘法器設計
采用FPGA器件與流水線技術實現浮點乘法器設計
1 引言
在數字化飛速發展的今天,人們對微處理器的性能要求也越來越高。作為衡量微處理器 性能的主要標準,主頻和乘法器運行一次乘法的周期息息相關。因此,為了進一步提高微處理器性能,開發高速高精度的乘法器勢在必行。同時由于基于IEEE754 標準的浮點運算具 有動態范圍大,可實現高精度,運算規律較定點運算更為簡捷等特點,浮點運算單元的設計 研究已獲得廣泛的重視。 本文介紹了 32 位浮點乘法器的設計,采用了基4 布思算法,改進的4:2 壓縮器及布思 編碼算法,并結合FPGA 自身特點,使用流水線設計技術,在實現高速浮點乘法的同時,也 使是系統具有了高穩定性、規則的結構、易于FPGA 實現及ASIC 的HardCopy 等特點。
2 運算規則及系統結構
2.1 浮點數的表示規則
本設計采用單精度IEEE754 格式【2】。設參與運算的兩個數A、B 均為單精度浮點數, 即:
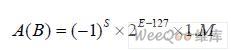
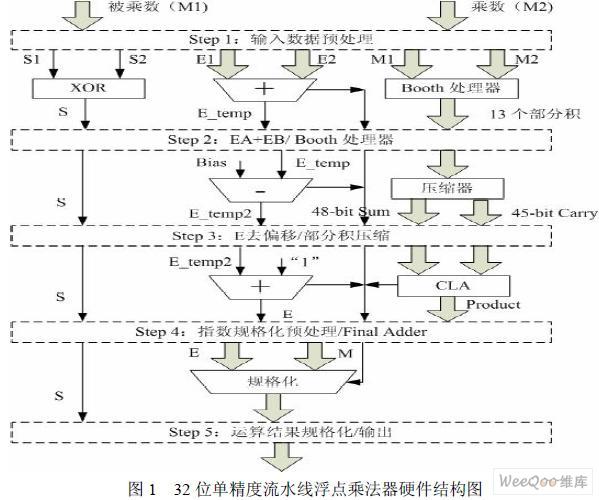
2.2 浮點乘法器的硬件系統結構
本設計用于專用浮點FFT 處理器,因此對運算速度有較高要求。為了保證浮點乘法器 可以穩定運行在80M 以下,本設計采用了流水線技術。流水線技術可提高同步電路的運行 速度,加大數據吞吐量。而FPGA 的內部結構特點很適合在其中采用流水線設計,并且只需 要極少或者根本不需要額外的成本。綜上所述,根據系統分割,本設計將采用5 級流水處理, 圖1 為浮點乘法器的硬件結構圖。
3 主要模塊設計與仿真
3.1 指數處理模塊(E_Adder)設計
32位浮點數格式如文獻【2】中定義。由前述可知,浮點乘法的主要過程是兩個尾數相 乘,同時并行處理指數相加及溢出檢測。對于32位的浮點乘法器而言,其指數為8位,因而 本設計采用帶進位輸出的8位超前進位加法器完成指數相加、去偏移等操作,具體過程如下。
E_Adder 模塊負責完成浮點乘法器運算中指數域的求和運算,如下式所示:
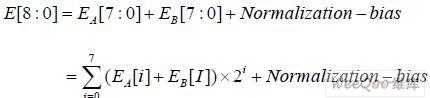
其中,E[8]為MSB 位產生的進位。Bias=127 是IEEE754 標準中定義的指數偏移值。 Normalization 完成規格化操作,因為指數求和結果與尾數相乘結果有關。在本次設計中,通 過選擇的方法,幾乎可以在Normalization 標志產生后立刻獲得積的指數部分,使E_Adder 不處于關鍵路徑。
本設計收集三級進位信號,配合尾數相乘單元的 Normalization 信號,對計算結果進行 規格化處理,并決定是否輸出無窮大、無窮小或正常值。
根據 E_Adder 的時序仿真視圖,可看出設計完全符合應用需求。
3.2 改進的Booth 編碼器設計
由于整個乘法器的延遲主要決定于相加的部分積個數,因此必須減少部分積的數目才能 進而縮短整個乘法器的運算延遲。本設計采用基4 布思編碼器,使得部分積減少到13 個, 并對傳統的編碼方案進行改進。編碼算法如表1 所示。
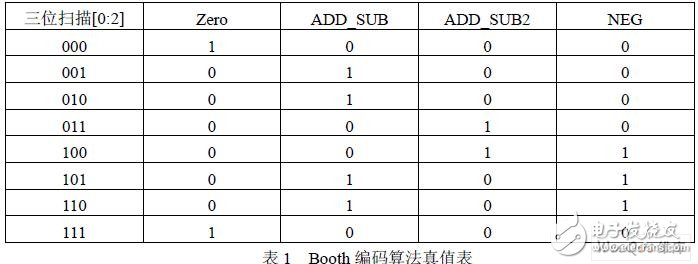
由于 FPGA 具有豐富的與、或門資源,使得該方法在保證速度和準確性的前提下,充分 利用了FPGA 內部資源,節省了面積,同時符合低功耗的要求。
3.3 部分積產生與壓縮結構設計
3.3.1 部分積產生結構
根據布思編碼器輸出結果,部分積產生遵循以下公式【4】:
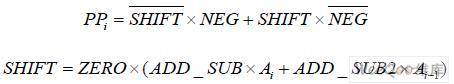
其中,PPi 為部分積;Ai 為被乘數。經過隱藏位和符號位的擴展后,26 位的被乘數尾數將產 生13 個部分積。在浮點乘法器中,尾數運算采用的是二進制補碼運算。因此,當NEG=1 時要在部分積的最低位加1,因為PPi 只完成了取反操作。而為了加強設計的并行性,部分 積最低位加1 操作在部分積壓縮結構中實現。另外,為了完成有符號數相加,需對部分積的 符號位進行擴展,其結果如圖4 所示。13 個部分積中,除第一個部分積是29 位以外,其余 部分積擴展為32 位。其中,第一個部分積包括3 位符號擴展位“SSS”,第2 至13 個部分 積的符號擴展位為“SS”,加一操作位為“NN”,遵循如下公式:
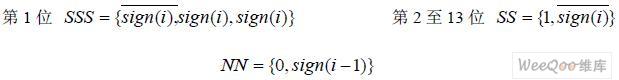
其中,i 為部分積的行數,sign(i)為第i 行部分積的符號。
3.3.2 部分積壓縮結構
本設計混合使用 4:2 壓縮器、3:2 壓縮器、全加器和半加器,實現了13 個部分積的 快速壓縮,并保證了精度。本文部分積壓縮結構的劃分如圖2 所示。

圖 2 中,虛線給出了傳統部分積的壓縮劃分,而實線描述的是本文采用的部分積壓縮結 構劃分,這樣的劃分有利于簡化第二級的壓縮結構,從而在保證速度的基礎上,節省FPGA 內部資源。從圖2 中可看出,有些位不必計算,因為這些位是由Booth 編碼時引入的乘數尾 數的符號位產生的,48 位足以表達運算結果。
3.3.3 改進的4:2 壓縮器
本設計采用廣泛使用的 4:2 壓縮器,并針對FPGA 內部資源特點,對其進行了改進。 如圖3 所示。 傳統的 4:2 壓縮器即兩個全加器級聯,共需要四個異或門和8 個與非門。而改進的4: 2 壓縮器需要四個異或門和兩個選擇器(MUX)。8 個與非門需要36 個晶體管,而兩個MUX 需要20 個晶體管。同時,FPGA 內部集成了大量的異或門和選擇器資源,這種設計方法也是對FPGA 的一個充分利用。
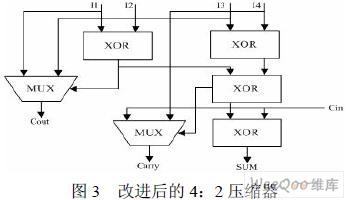
由于壓縮部分積需要大量的4:2 壓縮器,所以改進的電路能 在一定程度上減小版圖的面積,也為該乘法器的ASIC 后端設計帶來了優勢。另外,改進的 壓縮器的4 個輸入到輸出S 的延時相同,都是3 級XOR 門延時。
4 32 位浮點乘法器的實現與仿真
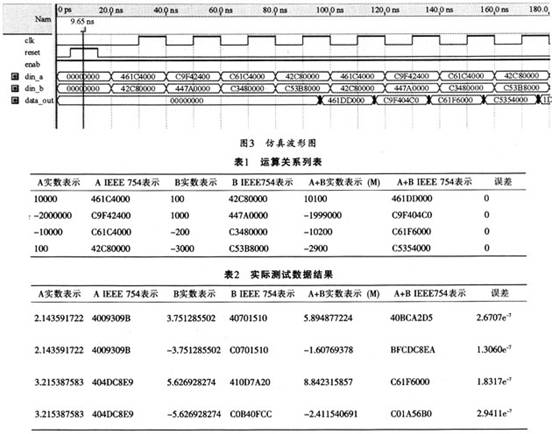
圖 4 顯示了本設計的FPGA 時序仿真結果,時序仿真環境為Quartus II 7.0,目標芯片為 Cyclone 系列的EP1C6Q240C8,功能仿真環境為Modelsim 6.0b。整個設計采用VHDL 語言進行結構描述,綜合策略為面積優先。由仿真視圖可看出,該浮點乘法器可穩定運行在80M 及以下頻率,在延時5 個周期后,以后每一個周期可穩定輸出一級乘法運算結果,實現了高 吞吐量。如果采用全定制進行后端版圖布局布線,乘法器的性能將更加優越。

5 結語
針對FPGA 器件內部資源特性,獨創地提出了一種適合FPGA 實現 的5 級流水高速浮點乘法器。該乘法器支持IEEE754 標準32 位單精度浮點數,采用了基4 布思算法、改進的布思編碼器、部份積壓縮結構等組件,從而在保證高速的前提下,縮小了 硬件規模,使得該乘法器的設計適合工程應用及科學計算,并易于ASIC 的后端版圖實現。 該設計已使用在筆者設計的浮點FFT 處理器中,取得了良好效果。
-
FPGA
+關注
關注
1626文章
21665瀏覽量
601814 -
編碼器
+關注
關注
45文章
3594瀏覽量
134147 -
微處理器
+關注
關注
11文章
2247瀏覽量
82311
發布評論請先 登錄
相關推薦
怎么設計基于FPGA的WALLACETREE乘法器?
基于FPGA的高速流水線浮點乘法器該怎么設計?
【夢翼師兄今日分享】 流水線設計講解
怎么實現32位浮點陣列乘法器的設計?
基于Pezaris 算法的流水線陣列乘法器設計
基于FPGA 的單精度浮點數乘法器設計

一種高速流水線乘法器結構
使用verilogHDL實現乘法器
乘法器原理_乘法器的作用

采用Gillbert單元如何實現CMOS模擬乘法器的應用設計





 工商網監
工商網監
評論