 采用VC++和Matlab混合編程搭建基于HMM的語音識別的實驗平臺
采用VC++和Matlab混合編程搭建基于HMM的語音識別的實驗平臺
1 引言
Matlab 是一款高性能的數值計算和可視化軟件,集成數值分析、矩陣計算、信號運算、 信號處理和圖形顯示于一體,構成了一個方便的、界面友好的用戶環境。目前,基于Matlab 的語音識別開發平臺雖然在可讀性、可移植性和可擴充性上優于其它編程語言,且調試功能 強大、數據庫函數豐富,可使研究人員“站在巨人的肩上”更加直觀、方便地進行分析、計 算與設計工作,從而大大地節省了時間[1]。但考慮到其執行代碼速度低下,不能直接與硬件 底層直接接觸等缺點,因此提出了采用Matlab 和VC++混合編程來搭建語音識別實驗平臺, 并對傳統Viterbi 算法進行變形,直接使用FPGA 的加法器、比較器和邏輯操作來計算觀察 值序列,以實現一種簡單的嵌入式語音模板匹配。
2 基于HMM 的語音識別
2.1 語音識別系統
語音識別系統(Speech Recognition System,SRS)基本上是一個模式分類的任務,即通 過訓練,系統能夠把輸入的語音按一定模式進行分類[2]。實驗在Matlab 7.0 系統上建立了一 個簡單的基于隱馬爾可夫模型(Hidden Markov Model,HMM)的語音識別過程,如圖1。
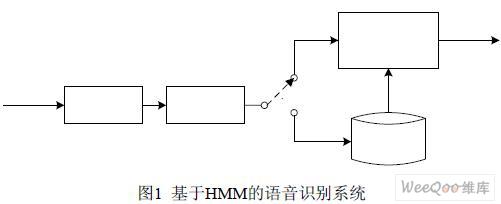
(1)語音輸入:在一般實驗室環境下進行語音信號采樣,采樣格式為PCM,采樣頻率 16 KHZ,A/D 的量化精度8 Bit。然后經過去噪、預加重、分幀、加窗等處理過程,去掉語音信號中包含的大量冗余信息,加強語音信號的高頻共振峰,便于進行頻譜分析。
(2)端點檢測:考慮到語音信號的錄制是在較為安靜的實驗室環境下進行,利用過零 率Z 來檢測清音,用短時能量E 來檢測濁音,兩者配合實現可靠的端點檢測[3]。
(3)特征提取和量化:對有效語音段進行特征提取,即提取基于Mel 刻度的倒頻譜矢 量(Mel Frequency Cepstrum Coefficients,MFCC),它是識別過程中的輸入特征值。特征值 經矢量量化Vector Quantization,VQ),輸出VQ 碼本類別號,即HMM 訓練與識別階段使 用的觀察值序列o。
(4)模型訓練與語音識別:訓練階段,系統采用一系列訓練觀察值估計HMM 參數,

2.2 Viterbi 算法
由于計算復雜度的限制,對于基于HMM 的實時語音識別來說,需要設計一個高效的硬 件結構來執行Viterbi 譯碼過程,以加速HMM 的識別過程。考慮了FPGA 的特點,分別采 用對數概率和狀態概率的最小路徑對傳統的Viterbi 算法進行變形,其計算P( o |λ ) v 的過程 如下[5]:

通過上面的變形,不僅可以使傳統 Viterbi 算法中的乘法轉成加法,降低時間消化,有 效地避免數據下溢的問題。而且隨著Viterbi 計算過程的進行,已計算的狀態概率值隨之增 加,改原來找結束概率的最大值為最小值[6]。因此,只需要計算T 時刻的概率T δ( i) ,它是 大于前參考單詞模型的最小值Pv 的。
實驗將直接使用 FPGA 的加法器、比較器和邏輯操作來實現上述公式(2)和公式(3), 可以顯著提高系統效率,系統結構如下圖2。
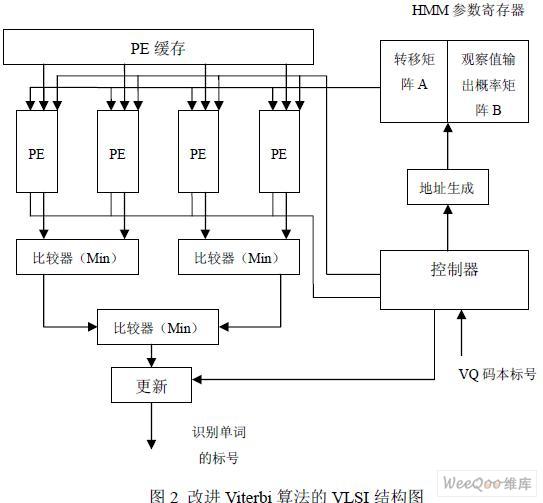
在這一方案中,識別過程直接由 FPGA 芯片內的邏輯塊從觀察序列中計算概率得分, 其中,觀察值序列通過VQ 得出。系統包括了兩個用來存儲轉移矩陣A 和輸出概率矩陣B 的存儲器,一個處理單元(Processing Element,PE)陣列,控制器,地址生成和附加比較 邏輯。PE 包括有Viterbi 算法的核心模塊加-比-選單元(Add-Compare-Select Unit,ACSU), 狀態累加器,和用來比較( i ) T δ 和極值Pv的附加比較器。PE 從HMM 參數寄存器中取出參 考模型,沿最小路徑計算其概率,然后與極值Pv 進行比較。當(i) T δ 大于Pv 時,控制器在 下一狀態時使PE 操作無效;同時,控制器控制存儲器緩沖操作,并生成整個計算過程中的 控制信號。
3 VC++和Matlab 混合編程
對于在 FPGA 上實現語音識別的核心模塊——Viterbi 算法時,有許多工作需要在實驗 前完成,如定制硬件源代碼、轉換浮點數據為定點數據和電路仿真等。為減少這部分工作, 采用軟硬件協同設計的思想,由軟件來執行HMM 模型訓練和其它識別過程(如MFCC、 VQ 等)。在實驗時,用軟件來執行HMM 模型訓練和語音單詞識別。然后,把實驗數據(語 音數據和HMM 模型參數)轉換成定點數據格式,由PCI 設備驅動程序將實驗數據、源代 碼等下載到硬件,用于FPGA 驗證平臺。
根據上述思想,采用Matlab 和VC + +混合編制PCI 設備驅動程序,利用Matlab 系統提 供的外部程序調用接口MEX 文件來實現其于VC++的混合編程。MEX 文件是一種約定格式 編寫的文件,使用C 語言或FOTRAN 語言編寫,是由Matlab 解釋器自動調用并執行的動態 鏈接函數(Dynamic Link Library Function),它在Mac 下以.mex 為后綴名,在Windows 下 即.dll 文件。基于C 語言的MEX 文件主要由兩部分組成,第一部分稱為入口子程序,其作 用是在Matlab 系統與被調用的外部子程序間建立通信聯系。第二部分稱為計算功能子程序,它包含所有實際需要完成的功能的源代碼,由入口子程序調用[7]。
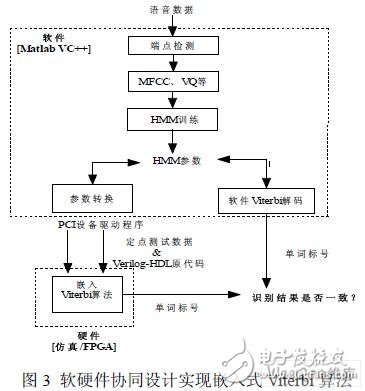
該方法可以在軟硬件之間達到一致的識別結果,其方案描述如圖3 所示。實驗中,計算 由FPGA 硬件完成,該子程序的主要負責FPGA 與PCI 的數據傳遞,即PCI 設備驅動。通 過MEX 文件,不僅可在Matlab 系統中像調用內建函數一樣調用存在的算法,使資源得到 充分利用,避免重復程序設計。同時,還可以對硬件直接進行編程,彌補Matlab 的不足。
4 實驗
該語音識別實驗采用的硬件平臺是包括有Altera Cyclone 系列EP1C12 的FPGA 和 PCI9054 芯片的PCI 開發板。EP1C 的FPGA 負責硬件Viterbi 計算,PCI9054 在驅動程序的 幫助下負責PC 和FPGA 間實驗數據和結果的傳輸。
由于 FPGA 的空間限制,實驗選擇了4 狀態的HMM 模型和容量64 的VQ 碼本,占用 FPGA 的LE(邏輯單元)1,125 個,存儲單元占用約132K 位。然后將.sof 目標文件下載到 PCI 卡上的FPGA 芯片中運行,在Matlab 中調用VC++編寫的PCI 設備驅動程序,將VQ 后 的語音數據和HMM 模型參數傳送給FPGA 內的Viterbi 譯碼電路,實驗中,通過驅動程序 輸出模板標號與實際語音的標號及仿真實驗導出的標號一致。
在 P4 3.0GHz 的PC 機和200MHz FPGA 驗證平臺上,對于約100 幀的單個語音文件識 別而言,軟/硬件Viterbi 算法的耗時如下表1 所示。

由上述實驗結果證明了該Viterbi 算法的VLSI 結構能夠準確且快速地實現語音識別的解 碼過程,滿足嵌入式計算精度要求,表明該實現方案是切實可行的。
5 結束語
采用 Matlab、VC + +和FPGA 搭建了一個軟硬件協同的語音識別實驗 研究平臺,以VC++來彌補Matlab 不能與硬件底層進行直接接觸的不足。并在傳統Viterbi 算法基礎上,對其采取一定變形,直接使用FPGA 的加法器、比較器和邏輯操作建立Viterbi 算法的VLSI 結構,來計算觀察值序列,以實現一種簡單的基于HMM 語音識別的模板匹配。 采用這種軟硬件協同的實驗研究平臺,可在利用前面Matlab 的實驗成果基礎上,逐步實現 語音識別各功能模塊的嵌入式設計,減少工作量,并易于調試。
-
FPGA
+關注
關注
1626文章
21669瀏覽量
601866 -
matlab
+關注
關注
182文章
2963瀏覽量
230170 -
語音識別
+關注
關注
38文章
1724瀏覽量
112547
發布評論請先 登錄
相關推薦
MATLAB 與VC混合編程問題,MATCOM
Matlab與C/C++ 混合編程技術總結的太棒了
Matlab和VC混合編程的DSP數據采集系統
基于MATCOM的MATLAB與VC混合編程技術研究
Matlab和VC++混合編程實現障礙檢測系統






 工商網監
工商網監
評論