 FM和深度網絡DNN的結合成為了CTR預估問題中主流的方法
FM和深度網絡DNN的結合成為了CTR預估問題中主流的方法
1、引言
在CTR預估中,為了解決稀疏特征的問題,學者們提出了FM模型來建模特征之間的交互關系。但是FM模型只能表達特征之間兩兩組合之間的關系,無法建模兩個特征之間深層次的關系或者說多個特征之間的交互關系,因此學者們通過Deep Network來建模更高階的特征之間的關系。
因此 FM和深度網絡DNN的結合也就成為了CTR預估問題中主流的方法。有關FM和DNN的結合有兩種主流的方法,并行結構和串行結構。兩種結構的理解以及實現如下表所示:

今天介紹的NFM模型(Neural Factorization Machine),便是串行結構中一種較為簡單的網絡模型。
2、NFM模型介紹
我們首先來回顧一下FM模型,FM模型用n個隱變量來刻畫特征之間的交互關系。這里要強調的一點是,n是特征的總數,是one-hot展開之后的,比如有三組特征,兩個連續特征,一個離散特征有5個取值,那么n=7而不是n=3.
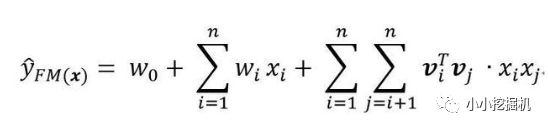
順便回顧一下化簡過程:
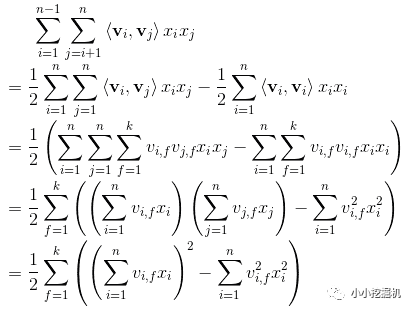
可以看到,不考慮最外層的求和,我們可以得到一個K維的向量。
對于NFM模型,目標值的預測公式變為:
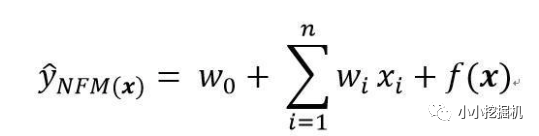
其中,f(x)是用來建模特征之間交互關系的多層前饋神經網絡模塊,架構圖如下所示:
Embedding Layer和我們之間幾個網絡是一樣的,embedding 得到的vector其實就是我們在FM中要學習的隱變量v。
Bi-Interaction Layer名字挺高大上的,其實它就是計算FM中的二次項的過程,因此得到的向量維度就是我們的Embedding的維度。最終的結果是:
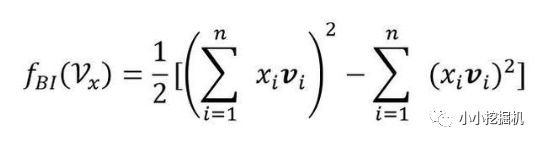
Hidden Layers就是我們的DNN部分,將Bi-Interaction Layer得到的結果接入多層的神經網絡進行訓練,從而捕捉到特征之間復雜的非線性關系。
在進行多層訓練之后,將最后一層的輸出求和同時加上一次項和偏置項,就得到了我們的預測輸出:
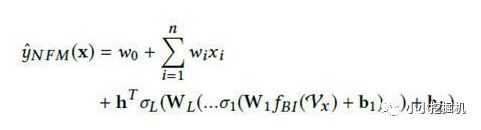
是不是很簡單呢,哈哈。
3、代碼實戰
終于到了激動人心的代碼實戰環節了,本文的代碼有不對的的地方或者改進之處還望大家多多指正。
本文的github地址為:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-NFM-Demo
本文的代碼根據之前DeepFM的代碼進行改進,我們只介紹模型的實現部分,其他數據處理的細節大家可以參考我的github上的代碼.
模型輸入
模型的輸入主要有下面幾個部分:
self.feat_index = tf.placeholder(tf.int32, shape=[None,None], name='feat_index') self.feat_value = tf.placeholder(tf.float32, shape=[None,None], name='feat_value') self.label = tf.placeholder(tf.float32,shape=[None,1],name='label') self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一個序號,主要用于通過embedding_lookup選擇我們的embedding。feat_value是對應的特征值,如果是離散特征的話,就是1,如果不是離散特征的話,就保留原來的特征值。label是實際值。還定義了dropout來防止過擬合。
權重構建
權重主要分以下幾部分,偏置項,一次項權重,embeddings,以及DNN的權重
def _initialize_weights(self): weights = dict() #embeddings weights['feature_embeddings'] = tf.Variable( tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01), name='feature_embeddings') weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias') weights['bias'] = tf.Variable(tf.constant(0.1),name='bias') #deep layers num_layer = len(self.deep_layers) input_size = self.embedding_size glorot = np.sqrt(2.0/(input_size + self.deep_layers[0])) weights['layer_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(input_size,self.deep_layers[0])),dtype=np.float32 ) weights['bias_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32 ) for i in range(1,num_layer): glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i])) weights["layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])), dtype=np.float32) # layers[i-1] * layers[i] weights["bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])), dtype=np.float32) # 1 * layer[i] return weights
Embedding Layer這個部分很簡單啦,是根據feat_index選擇對應的weights['feature_embeddings']中的embedding值,然后再與對應的feat_value相乘就可以了:
# Embeddings self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1]) self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
Bi-Interaction Layer我們直接根據化簡后的結果進行計算,得到一個K維的向量:
# sum-square-part self.summed_features_emb = tf.reduce_sum(self.embeddings, 1) # None * k self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K # squre-sum-part self.squared_features_emb = tf.square(self.embeddings) self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K # second order self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square, self.squared_sum_features_emb)
Deep Part將Bi-Interaction Layer層得到的結果經過一個多層的神經網絡,得到交互項的輸出:
self.y_deep = self.y_second_order for i in range(0, len(self.deep_layers)): self.y_deep = tf.add(tf.matmul(self.y_deep, self.weights["layer_%d" % i]), self.weights["bias_%d" % i]) self.y_deep = self.deep_layers_activation(self.y_deep) self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[i + 1])
得到預測輸出為了得到預測輸出,我們還需要兩部分,分別是偏置項和一次項:
# first order term self.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'], self.feat_index) self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2) # bias self.y_bias = self.weights['bias'] * tf.ones_like(self.label)
而我們的最終輸出如下:
# out self.out = tf.add_n([tf.reduce_sum(self.y_first_order,axis=1,keep_dims=True), tf.reduce_sum(self.y_deep,axis=1,keep_dims=True), self.y_bias])
剩下的代碼就不介紹啦!好啦,本文只是提供一個引子,有關NFM的知識大家可以更多的進行學習呦。
4、小結
NFM模型將FM與神經網絡結合以提升FM捕捉特征間多階交互信息的能力。根據論文中實驗結果,NFM的預測準確度相較FM有明顯提升,并且與現有的并行神經網絡模型相比,復雜度更低。
NFM本質上還是基于FM,FM會讓一個特征固定一個特定的向量,當這個特征與其他特征做交叉時,都是用同樣的向量去做計算。這個是很不合理的,因為不同的特征之間的交叉,重要程度是不一樣的。因此,學者們提出了AFM模型(Attentional factorization machines),將attention機制加入到我們的模型中,關于AFM的知識,我們下一篇來一探究竟。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
dnn
+關注
關注
0文章
59瀏覽量
9041
原文標題:推薦系統遇上深度學習(七)--NFM模型理論和實踐
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【我是電子發燒友】如何加速DNN運算?
什么是深度學習?使用FPGA進行深度學習的好處?
什么是DNN_如何使用硬件加速DNN運算
FM和FFM原理的探索和應用的經驗
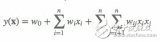
詳解DNN訓練中出現的問題與解決方法方法

用于理解深度神經網絡的CLass增強型注意響應(CLEAR)方法
回顧3年來的所有主流深度學習CTR模型
使用神經網絡實現語音驅動發音器官運動合成方法詳細資料說明
基于注意力機制的深度興趣網絡點擊率模型

綜述深度神經網絡的解釋方法及發展趨勢

淺析深度神經網絡(DNN)反向傳播算法(BP)
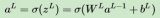





 工商網監
工商網監
評論