 Python 3入門基礎知識
Python 3入門基礎知識
簡介
Python 是一種高層次的結合了解釋性、編譯性、互動性和面向對象的腳本語言。
Python 由 Guido van Rossum 于 1989 年底在荷蘭國家數學和計算機科學研究所發明,第一個公開發行版發行于 1991 年。
特點
易于學習:Python 有相對較少的關鍵字,結構簡單,和一個明確定義的語法,學習起來更加簡單。
易于閱讀:Python 代碼定義的更清晰。
易于維護:Python 的成功在于它的源代碼是相當容易維護的。
一個廣泛的標準庫:Python 的最大的優勢之一是豐富的庫,跨平臺的,在 UNIX,Windows 和 macOS 兼容很好。
互動模式:互動模式的支持,您可以從終端輸入執行代碼并獲得結果的語言,互動的測試和調試代碼片斷。
可移植:基于其開放源代碼的特性,Python 已經被移植(也就是使其工作)到許多平臺。
可擴展:如果你需要一段運行很快的關鍵代碼,或者是想要編寫一些不愿開放的算法,你可以使用 C 或 C++ 完成那部分程序,然后從你的 Python 程序中調用。
數據庫:Python 提供所有主要的商業數據庫的接口。
GUI 編程:Python 支持 GUI 可以創建和移植到許多系統調用。
可嵌入:你可以將 Python 嵌入到 C/C++ 程序,讓你的程序的用戶獲得”腳本化”的能力。
面向對象:Python 是強面向對象的語言,程序中任何內容統稱為對象,包括數字、字符串、函數等。
基礎語法
運行 Python
交互式解釋器
在命令行窗口執行python后,進入 Python 的交互式解釋器。
exit()或Ctrl + D組合鍵退出交互式解釋器。
命令行腳本
在命令行窗口執行python script-file.py,以執行 Python 腳本文件。
指定解釋器
如果在 Python 腳本文件首行輸入#!/usr/bin/env python,那么可以在命令行窗口中執行/path/to/script-file.py以執行該腳本文件。
注:該方法不支持 Windows 環境。
編碼
默認情況下,3.x 源碼文件都是 UTF-8 編碼,字符串都是 Unicode 字符。
也可以手動指定文件編碼:
# -*- coding: utf-8 -*-
或者
# encoding: utf-8
注意: 該行標注必須位于文件第一行。
標識符
第一個字符必須是英文字母或下劃線_。
標識符的其他的部分由字母、數字和下劃線組成。
標識符對大小寫敏感。
注:從 3.x 開始,非 ASCII 標識符也是允許的,但不建議。
保留字
保留字即關鍵字,我們不能把它們用作任何標識符名稱。
Python 的標準庫提供了一個 keyword 模塊,可以輸出當前版本的所有關鍵字:
>>> import keyword>>> keyword.kwlist['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注釋
單行注釋采用#,多行注釋采用'''或"""。
# 這是單行注釋'''這是多行注釋這是多行注釋'''"""這也是多行注釋這也是多行注釋"""
行與縮進
Python 最具特色的就是使用縮進來表示代碼塊,不需要使用大括號{}。
縮進的空格數是可變的,但是同一個代碼塊的語句必須包含相同的縮進空格數,縮進不一致,會導致運行錯誤。
多行語句
Python 通常是一行寫完一條語句。
但如果語句很長,我們可以使用反斜杠來實現多行語句。
total = item_one + item_two + item_three
在[],{}, 或()中的多行語句,不需要使用反斜杠。
空行
函數之間或類的方法之間用空行分隔,表示一段新的代碼的開始。
類和函數入口之間也用一行空行分隔,以突出函數入口的開始。
空行與代碼縮進不同,空行并不是 Python 語法的一部分。
書寫時不插入空行,Python 解釋器運行也不會出錯。
但是空行的作用在于分隔兩段不同功能或含義的代碼,便于日后代碼的維護或重構。
記住:空行也是程序代碼的一部分。
等待用戶輸入
input函數可以實現等待并接收命令行中的用戶輸入。
content = input(" 請輸入點東西并按 Enter 鍵 ")print(content)
同一行寫多條語句
Python 可以在同一行中使用多條語句,語句之間使用分號;分割。
import sys; x = 'hello world'; sys.stdout.write(x + ' ')
多個語句構成代碼組
縮進相同的一組語句構成一個代碼塊,我們稱之代碼組。
像if、while、def和class這樣的復合語句,首行以關鍵字開始,以冒號:結束,該行之后的一行或多行代碼構成代碼組。
我們將首行及后面的代碼組稱為一個子句(clause)。
print 輸出
print 默認輸出是換行的,如果要實現不換行需要在變量末尾加上end=""或別的非換行符字符串:
print('123') # 默認換行print('123', end = "") # 不換行
import 與 from…import
在 Python 用import或者from...import來導入相應的模塊。
將整個模塊導入,格式為:import module_name
從某個模塊中導入某個函數,格式為:from module_name import func1
從某個模塊中導入多個函數,格式為:from module_name import func1, func2, func3
將某個模塊中的全部函數導入,格式為:from module_name import *
運算符
算術運算符
| 運算符 | 描述 |
|---|---|
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
| % | 取模 |
| ** | 冪 |
| // | 取整除 |
比較運算符
| 運算符 | 描述 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
賦值運算符
| 運算符 | 描述 |
|---|---|
| = | 簡單的賦值運算符 |
| += | 加法賦值運算符 |
| -= | 減法賦值運算符 |
| *= | 乘法賦值運算符 |
| /= | 除法賦值運算符 |
| %= | 取模賦值運算符 |
| **= | 冪賦值運算符 |
| //= | 取整除賦值運算符 |
位運算符
邏輯運算符
成員運算符
身份運算符
運算符優先級
具有相同優先級的運算符將從左至右的方式依次進行,用小括號()可以改變運算順序。
變量
變量在使用前必須先”定義”(即賦予變量一個值),否則會報錯:
>>> nameTraceback (most recent call last): File "
數據類型
布爾(bool)
只有True和False兩個值,表示真或假。
數字(number)
整型(int)
整數值,可正數亦可復數,無小數。
3.x 整型是沒有限制大小的,可以當作 Long 類型使用,所以 3.x 沒有 2.x 的 Long 類型。
浮點型(float)
浮點型由整數部分與小數部分組成。
浮點型也可以使用科學計數法表示(2.5e2 = 2.5 x 10^2 = 250)
復數(complex)
復數由實數部分和虛數部分構成,可以用a + bj,或者complex(a,b)表示。
復數的實部 a 和虛部 b 都是浮點型。
數字運算
不同類型的數字混合運算時會將整數轉換為浮點數
在不同的機器上浮點運算的結果可能會不一樣
在整數除法中,除法/總是返回一個浮點數。
如果只想得到整數的結果,丟棄可能的分數部分,可以使用運算符//。
//得到的并不一定是整數類型的數,它與分母分子的數據類型有關系。
在交互模式中,最后被輸出的表達式結果被賦值給變量_,_是個只讀變量
數學函數
注:以下函數的使用,需先導入 math 包。
隨機數函數
注:以下函數的使用,需先導入 random 包。
三角函數
注:以下函數的使用,需先導入 math包。
數學常量
字符串(string)
單引號和雙引號使用完全相同。
使用三引號('''或""")可以指定一個多行字符串。
轉義符(反斜杠)可以用來轉義,使用r可以讓反斜杠不發生轉義。
如r"this is a line with ",則 會顯示,并不是換行。
按字面意義級聯字符串。
如"this " "is " "string"會被自動轉換為this is string。
字符串可以用+運算符連接在一起,用*運算符重復。
字符串有兩種索引方式,從左往右以 0 開始,從右往左以 -1 開始。
字符串不能改變。
沒有單獨的字符類型,一個字符就是長度為 1 的字符串。
字符串的截取的語法格式如下:變量[頭下標:尾下標]。
轉義字符
字符串運算符
字符串格式化
在 Python 中,字符串格式化不是 sprintf 函數,而是用%符號。
例如:
print("我叫%s, 今年 %d 歲!" % ('小明', 10))// 輸出:我叫小明, 今年 10 歲!
格式化符號:
輔助指令:
Python 2.6 開始,新增了一種格式化字符串的函數str.format(),它增強了字符串格式化的功能。
多行字符串
用三引號('''或""")包裹字符串內容
多行字符串內容支持轉義符,用法與單雙引號一樣
三引號包裹的內容,有變量接收或操作即字符串,否則就是多行注釋
實例:
string = '''print( math.fabs(-10))print( random.choice(li))'''print(string)
輸出:
print( math.fabs(-10))print(random.choice(li))
Unicode
在 2.x 中,普通字符串是以 8 位 ASCII 碼進行存儲的。
而 Unicode 字符串則存儲為 16 位 Unicode 字符串,這樣能夠表示更多的字符集。
使用的語法是在字符串前面加上前綴u。
在 3.x 中,所有的字符串都是 Unicode 字符串。
字符串函數
字節(bytes)
在 3.x 中,字符串和二進制數據完全區分開。
文本總是 Unicode,由 str 類型表示,二進制數據則由 bytes 類型表示。
Python 3 不會以任意隱式的方式混用 str 和 bytes,你不能拼接字符串和字節流,也無法在字節流里搜索字符串(反之亦然),也不能將字符串傳入參數為字節流的函數(反之亦然)。
bytes 類型與 str 類型,二者的方法僅有 encode() 和 decode() 不同。
bytes 類型數據需在常規的 str 類型前加個b以示區分,例如b'abc'。
只有在需要將 str 編碼(encode)成 bytes 的時候。
比如:通過網絡傳輸數據;或者需要將 bytes 解碼(decode)成 str 的時候, 我們才會關注 str 和 bytes 的區別。
bytes 轉 str:
b'abc'.decode()str(b'abc')str(b'abc', encoding='utf-8')
str 轉 bytes:
'中國'.encode()bytes('中國', encoding='utf-8')
列表(list)
列表是一種無序的、可重復的數據序列,可以隨時添加、刪除其中的元素。
列表頁的每個元素都分配一個數字索引,從 0 開始。
列表使用方括號創建,使用逗號分隔元素。
列表元素值可以是任意類型,包括變量。
使用方括號對列表進行元素訪問、切片、修改、刪除等操作,開閉合區間為[)形式。
列表的元素訪問可以嵌套。
方括號內可以是任意表達式。
創建列表
hello = (1, 2, 3)li = [1, "2", [3, 'a'], (1, 3), hello]
訪問元素
li = [1, "2", [3, 'a'], (1, 3)]print(li[3]) # (1, 3)print(li[-2]) # [3, 'a']
切片訪問
格式:list_name[begin:end:step]begin 表示起始位置(默認為0),end 表示結束位置(默認為最后一個元素),step 表示步長(默認為1)。
hello = (1, 2, 3)li = [1, "2", [3, 'a'], (1, 3), hello]print(li) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]print(li[1:2]) # ['2']print(li[:2]) # [1, '2']print(li[:]) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]print(li[2:]) # [[3, 'a'], (1, 3), (1, 2, 3)]print(li[1:-1:2]) # ['2', (1, 3)]
訪問內嵌 list 的元素:
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ['a', 'b', 'c']]print(li[1:-1:2][1:3]) # (3, 5)print(li[-1][1:3]) # ['b', 'c']print(li[-1][1]) # b
修改列表
通過使用方括號,可以非常靈活的對列表的元素進行修改、替換、刪除等操作。
li = [0, 1, 2, 3, 4, 5]li[len(li) - 2] = 22 # 修改 [0, 1, 2, 22, 4, 5]li[3] = 33 # 修改 [0, 1, 2, 33, 4, 5]li[1:-1] = [9, 9] # 替換 [0, 9, 9, 5]li[1:-1] = [] # 刪除 [0, 5]
刪除元素
可以用 del 語句來刪除列表的指定范圍的元素。
li = [0, 1, 2, 3, 4, 5]del li[3] # [0, 1, 2, 4, 5]del li[2:-1] # [0, 1, 5]
列表操作符
+用于合并列表。
*用于重復列表元素。
in用于判斷元素是否存在于列表中。
for ... in ...用于遍歷列表元素。
[1, 2, 3] + [3, 4, 5] # [1, 2, 3, 3, 4, 5][1, 2, 3] * 2 # [1, 2, 3, 1, 2, 3]3 in [1, 2, 3] # Truefor x in [1, 2, 3]: print(x) # 1 2 3
列表函數
len(list)列表元素個數
max(list)列表元素中的最大值
min(list)列表元素中的最小值
list(seq)將元組轉換為列表
li = [0, 1, 5]max(li) # 5len(li) # 3
注:對列表使用 max/min 函數,2.x 中對元素值類型無要求,3.x 則要求元素值類型必須一致。
列表方法
list.append(obj)
在列表末尾添加新的對象
list.count(obj)
返回元素在列表中出現的次數
list.extend(seq)
在列表末尾一次性追加另一個序列中的多個值
list.index(obj)
返回查找對象的索引位置,如果沒有找到對象則拋出異常
list.insert(index, obj)
將指定對象插入列表的指定位置
list.pop([index=-1]])
移除列表中的一個元素(默認最后一個元素),并且返回該元素的值
list.remove(obj)
移除列表中某個值的第一個匹配項
list.reverse()
反向排序列表的元素
list.sort(cmp=None, key=None, reverse=False)
對原列表進行排序,如果指定參數,則使用比較函數指定的比較函數
list.clear()
清空列表 還可以使用del list[:]、li = []等方式實現
list.copy()
復制列表 默認使用等號賦值給另一個變量,實際上是引用列表變量。如果要實現
列表推導式
列表推導式提供了從序列創建列表的簡單途徑。
通常應用程序將一些操作應用于某個序列的每個元素,用其獲得的結果作為生成新列表的元素,或者根據確定的判定條件創建子序列。
每個列表推導式都在 for 之后跟一個表達式,然后有零到多個 for 或 if 子句。
返回結果是一個根據表達從其后的 for 和 if 上下文環境中生成出來的列表。
如果希望表達式推導出一個元組,就必須使用括號。
將列表中每個數值乘三,獲得一個新的列表:
vec = [2, 4, 6][(x, x**2) for x in vec]# [(2, 4), (4, 16), (6, 36)]
對序列里每一個元素逐個調用某方法:
freshfruit = [' banana', ' loganberry ', 'passion fruit '][weapon.strip() for weapon in freshfruit]# ['banana', 'loganberry', 'passion fruit']
用 if 子句作為過濾器:
vec = [2, 4, 6][3*x for x in vec if x > 3]# [12, 18]vec1 = [2, 4, 6]vec2 = [4, 3, -9][x*y for x in vec1 for y in vec2]# [8, 6, -18, 16, 12, -36, 24, 18, -54][vec1[i]*vec2[i] for i in range(len(vec1))]# [8, 12, -54]
列表嵌套解析:
matrix = [[1, 2, 3],[4, 5, 6],[7, 8, 9],]new_matrix = [[row[i] for row in matrix] for i in range(len(matrix[0]))]print(new_matrix)# [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
元組(tuple)
元組與列表類似,不同之處在于元組的元素不能修改
元組使用小括號,列表使用方括號
元組創建很簡單,只需要在括號中添加元素,并使用逗號隔開即可
沒有 append(),insert() 這樣進行修改的方法,其他方法都與列表一樣
字典中的鍵必須是唯一的同時不可變的,值則沒有限制
元組中只包含一個元素時,需要在元素后面添加逗號,否則括號會被當作運算符使用
訪問元組
訪問元組的方式與列表是一致的。
元組的元素可以直接賦值給多個變量,但變量數必須與元素數量一致。
a, b, c = (1, 2, 3)print(a, b, c)
組合元組
元組中的元素值是不允許修改的,但我們可以對元組進行連接組合。
tup1 = (12, 34.56);tup2 = ('abc', 'xyz')tup3 = tup1 + tup2;print (tup3)# (12, 34.56, 'abc', 'xyz')
刪除元組
元組中的元素值是不允許刪除的,但我們可以使用 del 語句來刪除整個元組
元組函數
len(tuple)元組元素個數
max(tuple)元組元素中的最大值
min(tuple)元組元素中的最小值
tuple(tuple)將列表轉換為元組
元組推導式
t = 1, 2, 3print(t)# (1, 2, 3)u = t, (3, 4, 5)print(u)# ((1, 2, 3), (3, 4, 5))
字典(dict)
字典是另一種可變容器模型,可存儲任意類型對象
字典的每個鍵值(key=>value)對用冒號(:)分割,每個對之間用逗號(,)分割,整個字典包括在花括號({})中
鍵必須是唯一的,但值則不必
值可以是任意數據類型
鍵必須是不可變的,例如:數字、字符串、元組可以,但列表就不行
如果用字典里沒有的鍵訪問數據,會報錯
字典的元素沒有順序,不能通過下標引用元素,通過鍵來引用
字典內部存放的順序和 key 放入的順序是沒有關系的
格式如下:
d = {key1 : value1, key2 : value2 }
訪問字典
dis = {'a': 1, 'b': [1, 2, 3]}print(dis['b'][2])
修改字典
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}dis[9]['name'] = 999print(dis)# {'a': 1, 9: {'name': 999}, 'b': [1, 2, 3]}
刪除字典
用 del 語句刪除字典或字典的元素。
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}del dis[9]['name']print(dis)del dis # 刪除字典# {'a': 1, 9: {}, 'b': [1, 2, 3]}
字典函數
len(dict)計算字典元素個數,即鍵的總數
str(dict)輸出字典,以可打印的字符串表示
type(variable)返回輸入的變量類型,如果變量是字典就返回字典類型
key in dict判斷鍵是否存在于字典中
字典方法
dict.clear()
刪除字典內所有元素
dict.copy()
返回一個字典的淺復制
dict.fromkeys(seq[, value])
創建一個新字典,以序列 seq 中元素做字典的鍵,value 為字典所有鍵對應的初始值
dict.get(key, default=None)
返回指定鍵的值,如果值不在字典中返回默認值
dict.items()
以列表形式返回可遍歷的(鍵, 值)元組數組
dict.keys()
以列表返回一個字典所有的鍵
dict.values()
以列表返回字典中的所有值
dict.setdefault(key, default=None)
如果 key 在字典中,返回對應的值。
如果不在字典中,則插入 key 及設置的默認值 default,并返回 default ,default 默認值為 None。
dict.update(dict2)
把字典參數 dict2 的鍵/值對更新到字典 dict 里
dic1 = {'a': 'a'}dic2 = {9: 9, 'a': 'b'}dic1.update(dic2)print(dic1)# {'a': 'b', 9: 9}
dict.pop(key[,default])
刪除字典給定鍵 key 所對應的值,返回值為被刪除的值。key 值必須給出,否則返回 default 值。
dict.popitem()
隨機返回并刪除字典中的一對鍵和值(一般刪除末尾對)
字典推導式
構造函數 dict() 直接從鍵值對元組列表中構建字典。如果有固定的模式,列表推導式指定特定的鍵值對:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)]){'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,字典推導可以用來創建任意鍵和值的表達式詞典:
>>> {x: x**2 for x in (2, 4, 6)}{2: 4, 4: 16, 6: 36}
如果關鍵字只是簡單的字符串,使用關鍵字參數指定鍵值對有時候更方便:
>>> dict(sape=4139, guido=4127, jack=4098){'sape': 4139, 'jack': 4098, 'guido': 4127}
集合(set)
集合是一個無序不重復元素的序列
創建集合
可以使用大括號{}或者set()函數創建集合
創建一個空集合必須用set()而不是{},因為{}是用來創建一個空字典
set(value)方式創建集合,value 可以是字符串、列表、元組、字典等序列類型
創建、添加、修改等操作,集合會自動去重
{1, 2, 1, 3} # {} {1, 2, 3}set('12345') # 字符串 {'3', '5', '4', '2', '1'}set([1, 'a', 23.4]) # 列表 {1, 'a', 23.4}set((1, 'a', 23.4)) # 元組 {1, 'a', 23.4}set({1:1, 'b': 9}) # 字典 {1, 'b'}
添加元素
將元素 val 添加到集合 set 中,如果元素已存在,則不進行任何操作:
set.add(val)
也可以用 update 方法批量添加元素,參數可以是列表,元組,字典等:
set.update(list1, list2,...)
移除元素
如果存在元素 val 則移除,不存在就報錯:
set.remove(val)
如果存在元素 val 則移除,不存在也不會報錯:
set.discard(val)
隨機移除一個元素:
set.pop()
元素個數
與其他序列一樣,可以用len(set)獲取集合的元素個數。
清空集合
set.clear()set = set()
判斷元素是否存在
val in set
其他方法
set.copy()
復制集合
set.difference(set2)
求差集,在 set 中卻不在 set2 中
set.intersection(set2)
求交集,同時存在于 set 和 set2 中
set.union(set2)
求并集,所有 set 和 set2 的元素
set.symmetric_difference(set2)
求對稱差集,不同時出現在兩個集合中的元素
set.isdisjoint(set2)
如果兩個集合沒有相同的元素,返回 True
set.issubset(set2)
如果 set 是 set2 的一個子集,返回 True
set.issuperset(set2)
如果 set 是 set2 的一個超集,返回 True
集合計算
a = set('abracadabra')b = set('alacazam')print(a) # a 中唯一的字母# {'a', 'r', 'b', 'c', 'd'}print(a - b) # 在 a 中的字母,但不在 b 中# {'r', 'd', 'b'}print(a | b) # 在 a 或 b 中的字母# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}print(a & b) # 在 a 和 b 中都有的字母# {'a', 'c'}print(a ^ b) # 在 a 或 b 中的字母,但不同時在 a 和 b 中# {'r', 'd', 'b', 'm', 'z', 'l'}
集合推導式
a = {x for x in 'abracadabra' if x not in 'abc'}print(a)# {'d', 'r'}
流程控制
if 控制
if 表達式1: 語句 if 表達式2: 語句 elif 表達式3: 語句 else: 語句elif 表達式4: 語句else: 語句
1、每個條件后面要使用冒號:,表示接下來是滿足條件后要執行的語句塊。
2、使用縮進來劃分語句塊,相同縮進數的語句在一起組成一個語句塊。
3、在 Python 中沒有 switch - case 語句。
三元運算符:
<表達式1> if <條件> else <表達式2>
編寫條件語句時,應該盡量避免使用嵌套語句。
嵌套語句不便于閱讀,而且可能會忽略一些可能性。
for 遍歷
for <循環變量> in <循環對象>: <語句1>else: <語句2>
else 語句中的語句2只有循環正常退出(遍歷完所有遍歷對象中的值)時執行。
在字典中遍歷時,關鍵字和對應的值可以使用items()方法同時解讀出來:
knights = {'gallahad': 'the pure', 'robin': 'the brave'}for k, v in knights.items(): print(k, v)
在序列中遍歷時,索引位置和對應值可以使用enumerate()函數同時得到:
for i, v in enumerate(['tic', 'tac', 'toe']): print(i, v)
同時遍歷兩個或更多的序列,可以使用zip()組合:
questions = ['name', 'quest', 'favorite color']answers = ['lancelot', 'the holy grail', 'blue']for q, a in zip(questions, answers): print('What is your {0}? It is {1}.'.format(q, a))
要反向遍歷一個序列,首先指定這個序列,然后調用reversed()函數:
for i in reversed(range(1, 10, 2)): print(i)
要按順序遍歷一個序列,使用sorted()函數返回一個已排序的序列,并不修改原值:
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']for f in sorted(set(basket)): print(f)
while 循環
while<條件>: <語句1>else: <語句2>
break、continue、pass
break 語句用在 while 和 for 循環中,break 語句用來終止循環語句。
即循環條件沒有 False 條件或者序列還沒被完全遞歸完,也會停止執行循環語句。
continue 語句用在 while 和 for 循環中,continue 語句用來告訴 Python 跳過當前循環的剩余語句,然后繼續進行下一輪循環。
continue 語句跳出本次循環,而 break 跳出整個循環。
pass 是空語句,是為了保持程序結構的完整性。
pass 不做任何事情,一般用做占位語句。
迭代器
迭代器是一個可以記住遍歷的位置的對象。
迭代器對象從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。
迭代器只能往前不會后退。
迭代器有兩個基本的方法:iter()和next()。
字符串,列表或元組對象都可用于創建迭代器。
迭代器可以被 for 循環進行遍歷:
li = [1, 2, 3]it = iter(li)for val in it: print(val)
迭代器也可以用 next() 函數訪問下一個元素值:
import sysli = [1,2,3,4]it = iter(li)while True: try: print (next(it)) except StopIteration: sys.exit()
生成器
在 Python 中,使用了 yield 的函數被稱為生成器(generator)。
跟普通函數不同的是,生成器是一個返回迭代器的函數,只能用于迭代操作。
更簡單點理解生成器就是一個迭代器。
在調用生成器運行的過程中,每次遇到 yield 時函數會暫停并保存當前所有的運行信息,返回 yield 的值,并在下一次執行 next() 方法時從當前位置繼續運行。
調用一個生成器函數,返回的是一個迭代器對象。
import sysdef fibonacci(n): # 生成器函數 - 斐波那契 a, b, counter = 0, 1, 0 while True: if (counter > n): return yield a a, b = b, a + b counter += 1f = fibonacci(10) # f 是一個迭代器,由生成器返回生成while True: try: print(next(f)) except StopIteration: sys.exit()
函數
自定義函數
函數(Functions)是指可重復使用的程序片段。
它們允許你為某個代碼塊賦予名字,允許你通過這一特殊的名字在你的程序任何地方來運行代碼塊,并可重復任何次數。
這就是所謂的調用(Calling)函數。
函數代碼塊以def關鍵詞開頭,后接函數標識符名稱和圓括號()。
任何傳入參數和自變量必須放在圓括號中間,圓括號之間可以用于定義參數。
函數的第一行語句可以選擇性地使用文檔字符串—用于存放函數說明。
函數內容以冒號起始,并且縮進。
return [表達式]結束函數,選擇性地返回一個值給調用方。
不帶表達式的 return 相當于返回 None。
return可以返回多個值,此時返回的數據未元組類型。
定義參數時,帶默認值的參數必須在無默認值參數的后面。
def 函數名(參數列表): 函數體
參數傳遞
在 Python 中,類型屬于對象,變量是沒有類型的:
a = [1,2,3]a = "Runoob"
以上代碼中,[1,2,3] 是 List 類型,”Runoob” 是 String 類型。
而變量 a 是沒有類型,她僅僅是一個對象的引用(一個指針),可以是指向 List 類型對象,也可以是指向 String 類型對象。
可更改與不可更改對象
在 Python 中,字符串,數字和元組是不可更改的對象。
而列表、字典等則是可以修改的對象。
不可變類型:變量賦值 a=5 后再賦值 a=10,這里實際是新生成一個 int 值對象 10,再讓 a 指向它,而 5 被丟棄,不是改變a的值,相當于新生成了a。
可變類型:變量賦值 la=[1,2,3,4] 后再賦值 la[2]=5 ,則是將 list la 的第三個元素值更改,本身la沒有動,只是其內部的一部分值被修改了。
Python 函數的參數傳遞:
不可變類型:類似 c++ 的值傳遞,如 整數、字符串、元組。如fun(a),傳遞的只是a的值,沒有影響a對象本身。
比如在 fun(a)內部修改 a 的值,只是修改另一個復制的對象,不會影響 a 本身。
可變類型:類似 c++ 的引用傳遞,如 列表,字典。
如 fun(la),則是將 la 真正的傳過去,修改后fun外部的la也會受影響
Python 中一切都是對象,嚴格意義我們不能說值傳遞還是引用傳遞,我們應該說傳不可變對象和傳可變對象。
參數
必需參數
必需參數須以正確的順序傳入函數。
調用時的數量必須和聲明時的一樣。
關鍵字參數
關鍵字參數和函數調用關系緊密,函數調用使用關鍵字參數來確定傳入的參數值。
使用關鍵字參數允許函數調用時參數的順序與聲明時不一致,因為 Python 解釋器能夠用參數名匹配參數值。
def print_info(name, age): "打印任何傳入的字符串" print("名字: ", name) print("年齡: ", age) returnprint_info(age=50, name="john")
默認參數
調用函數時,如果沒有傳遞參數,則會使用默認參數。
def print_info(name, age=35): print ("名字: ", name) print ("年齡: ", age) returnprint_info(age=50, name="john")print("------------------------")print_info(name="john")
不定長參數
加了星號*的參數會以元組的形式導入,存放所有未命名的變量參數。
如果在函數調用時沒有指定參數,它就是一個空元組。
我們也可以不向函數傳遞未命名的變量。
def print_info(arg1, *vartuple): print("輸出: ") print(arg1) for var in vartuple: print (var) returnprint_info(10)print_info(70, 60, 50)
加了兩個星號**的參數會以字典的形式導入,變量名為鍵,變量值為字典元素值。
def print_info(arg1, **vardict): print("輸出: ") print(arg1) print(vardict)print_info(1, a=2, b=3)
匿名函數
Python 使用 lambda 來創建匿名函數。
所謂匿名,意即不再使用def語句這樣標準的形式定義一個函數。
lambda 只是一個表達式,函數體比 def 簡單很多。
lambda 的主體是一個表達式,而不是一個代碼塊。
僅僅能在 lambda 表達式中封裝有限的邏輯進去。
lambda 函數擁有自己的命名空間,且不能訪問自己參數列表之外或全局命名空間里的參數。
雖然 lambda 函數看起來只能寫一行,卻不等同于 C 或 C++ 的內聯函數,后者的目的是調用小函數時不占用棧內存從而增加運行效率。
# 語法格式lambda [arg1 [,arg2,.....argn]]:expression
變量作用域
L (Local) 局部作用域
E (Enclosing) 閉包函數外的函數中
G (Global) 全局作用域
B (Built-in) 內建作用域
以 L –> E –> G –> B 的規則查找,即:在局部找不到,便會去局部外的局部找(例如閉包),再找不到就會去全局找,再者去內建中找。
Python 中只有模塊(module),類(class)以及函數(def、lambda)才會引入新的作用域,其它的代碼塊(如 if/elif/else/、try/except、for/while等)是不會引入新的作用域的。
也就是說這些語句內定義的變量,外部也可以訪問。
定義在函數內部的變量擁有一個局部作用域,定義在函數外的擁有全局作用域。
局部變量只能在其被聲明的函數內部訪問,而全局變量可以在整個程序范圍內訪問。
調用函數時,所有在函數內聲明的變量名稱都將被加入到作用域中。
當內部作用域想修改外部作用域的變量時,就要用到global和nonlocal關鍵字。
num = 1def fun1(): global num # 需要使用 global 關鍵字聲明 print(num) num = 123 print(num)fun1()
如果要修改嵌套作用域(enclosing 作用域,外層非全局作用域)中的變量則需要 nonlocal 關鍵字。
def outer(): num = 10 def inner(): nonlocal num # nonlocal關鍵字聲明 num = 100 print(num) inner() print(num)outer()
模塊
編寫模塊有很多種方法。
其中最簡單的一種便是創建一個包含函數與變量、以 .py 為后綴的文件。
另一種方法是使用撰寫 Python 解釋器本身的本地語言來編寫模塊。
舉例來說,你可以使用 C 語言來撰寫 Python 模塊,并且在編譯后,你可以通過標準 Python 解釋器在你的 Python 代碼中使用它們。
模塊是一個包含所有你定義的函數和變量的文件,其后綴名是.py。
模塊可以被別的程序引入,以使用該模塊中的函數等功能。
這也是使用 Python 標準庫的方法。
當解釋器遇到 import 語句,如果模塊在當前的搜索路徑就會被導入。
搜索路徑是一個解釋器會先進行搜索的所有目錄的列表。
如想要導入模塊,需要把命令放在腳本的頂端。
一個模塊只會被導入一次,這樣可以防止導入模塊被一遍又一遍地執行。
搜索路徑被存儲在 sys 模塊中的 path 變量。
當前目錄指的是程序啟動的目錄。
導入模塊
導入模塊:
import module1[, module2[,... moduleN]]
從模塊中導入一個指定的部分到當前命名空間中:
from modname import name1[, name2[, ... nameN]]
把一個模塊的所有內容全都導入到當前的命名空間:
from modname import *
__name__ 屬性
每個模塊都有一個__name__屬性,當其值是'__main__'時,表明該模塊自身在運行,否則是被引入。
一個模塊被另一個程序第一次引入時,其主程序將運行。
如果我們想在模塊被引入時,模塊中的某一程序塊不執行,我們可以用__name__屬性來使該程序塊僅在該模塊自身運行時執行。
if __name__ == '__main__': print('程序自身在運行')else: print('我來自另一模塊')
dir 函數
內置的函數dir()可以找到模塊內定義的所有名稱。
以一個字符串列表的形式返回。
如果沒有給定參數,那么dir()函數會羅列出當前定義的所有名稱。
在 Python 中萬物皆對象,int、str、float、list、tuple等內置數據類型其實也是類,也可以用dir(int)查看int包含的所有方法,也可以使用help(int)查看int類的幫助信息。
包
包是一種管理 Python 模塊命名空間的形式,采用”點模塊名稱”。
比如一個模塊的名稱是 A.B, 那么他表示一個包 A中的子模塊 B 。
就好像使用模塊的時候,你不用擔心不同模塊之間的全局變量相互影響一樣,采用點模塊名稱這種形式也不用擔心不同庫之間的模塊重名的情況。
在導入一個包的時候,Python 會根據 sys.path 中的目錄來尋找這個包中包含的子目錄。
目錄只有包含一個叫做__init__.py的文件才會被認作是一個包,主要是為了避免一些濫俗的名字(比如叫做 string)不小心的影響搜索路徑中的有效模塊。
最簡單的情況,放一個空的__init__.py文件就可以了。
當然這個文件中也可以包含一些初始化代碼或者為__all__變量賦值。
第三方模塊
easy_install 和 pip 都是用來下載安裝 Python 一個公共資源庫 PyPI 的相關資源包的,pip 是 easy_install 的改進版,提供更好的提示信息,刪除 package 等功能。
老版本的 python 中只有 easy_install,沒有pip。
easy_install 打包和發布 Python 包,pip 是包管理。
easy_install 的用法:
安裝一個包
easy_install 包名easy_install "包名 == 包的版本號"
升級一個包
easy_install -U "包名 >= 包的版本號"
pip 的用法:
安裝一個包
pip install 包名pip install 包名 == 包的版本號
升級一個包 (如果不提供version號,升級到最新版本)
pip install —upgrade 包名 >= 包的版本號
刪除一個包
pip uninstall 包名
已安裝包列表
pip list
面向對象
類與對象是面向對象編程的兩個主要方面。
一個類(Class)能夠創建一種新的類型(Type),其中對象(Object)就是類的實例(Instance)。
可以這樣來類比:你可以擁有類型int的變量,也就是說存儲整數的變量是int類的實例(對象)。
類(Class):用來描述具有相同的屬性和方法的對象的集合。
它定義了該集合中每個對象所共有的屬性和方法。對象是類的實例。
方法:類中定義的函數。
類變量:類變量在整個實例化的對象中是公用的。
類變量定義在類中且在函數體之外。類變量通常不作為實例變量使用。
數據成員:類變量或者實例變量用于處理類及其實例對象的相關的數據。
方法重寫:如果從父類繼承的方法不能滿足子類的需求,可以對其進行改寫,這個過程叫方法的覆蓋(override),也稱為方法的重寫。
實例變量:定義在方法中的變量,只作用于當前實例的類。
繼承:即一個派生類(derived class)繼承基類(base class)的字段和方法。
繼承也允許把一個派生類的對象作為一個基類對象對待。
例如,有這樣一個設計:一個Dog類型的對象派生自Animal類,這是模擬”是一個(is-a)”關系(例圖,Dog是一個Animal)。
實例化:創建一個類的實例,類的具體對象。
對象:通過類定義的數據結構實例。對象包括兩個數據成員(類變量和實例變量)和方法。
Python 中的類提供了面向對象編程的所有基本功能:類的繼承機制允許多個基類,派生類可以覆蓋基類中的任何方法,方法中可以調用基類中的同名方法。
對象可以包含任意數量和類型的數據。
self
self表示的是當前實例,代表當前對象的地址。
類由self.__class__表示。
self不是關鍵字,其他名稱也可以替代,但self是個通用的標準名稱。
類
類由class關鍵字來創建。
類實例化后,可以使用其屬性,實際上,創建一個類之后,可以通過類名訪問其屬性。
對象方法
方法由def關鍵字定義,與函數不同的是:方法必須包含參數self, 且為第一個參數,self代表的是本類的實例。
類方法
裝飾器@classmethod可以將方法標識為類方法。
類方法的第一個參數必須為cls,而不再是self。
靜態方法
裝飾器@staticmethod可以將方法標識為靜態方法。
靜態方法的第一個參數不再指定,也就不需要self或cls。
__init__ 方法
__init__方法即構造方法,會在類的對象被實例化時先運行,可以將初始化的操作放置到該方法中。
如果重寫了__init__,實例化子類就不會調用父類已經定義的__init__。
變量
類變量(Class Variable)是共享的(Shared)——它們可以被屬于該類的所有實例訪問。
該類變量只擁有一個副本,當任何一個對象對類變量作出改變時,發生的變動將在其它所有實例中都會得到體現。
對象變量(Object variable)由類的每一個獨立的對象或實例所擁有。
在這種情況下,每個對象都擁有屬于它自己的字段的副本。
也就是說,它們不會被共享,也不會以任何方式與其它不同實例中的相同名稱的字段產生關聯。
在 Python 中,變量名類似__xxx__的,也就是以雙下劃線開頭,并且以雙下劃線結尾的,是特殊變量,特殊變量是可以直接訪問的,不是 private 變量。
所以,不能用__name__、__score__這樣的變量名。
訪問控制
私有屬性
__private_attr:兩個下劃線開頭,聲明該屬性為私有,不能在類地外部被使用或直接訪問。
私有方法
__private_method:兩個下劃線開頭,聲明該方法為私有方法,只能在類的內部調用,不能在類地外部調用。
我們還認為約定,一個下劃線開頭的屬性或方法為受保護的。
比如,_protected_attr、_protected_method。
繼承
類可以繼承,并且支持繼承多個父類。
在定義類時,類名后的括號中指定要繼承的父類,多個父類之間用逗號分隔。
子類的實例可以完全訪問所繼承所有父類的非私有屬性和方法。
若是父類中有相同的方法名,而在子類使用時未指定,Python 從左至右搜索,即方法在子類中未找到時,從左到右查找父類中是否包含方法。
方法重寫
子類的方法可以重寫父類的方法。
重寫的方法參數不強制要求保持一致,不過合理的設計都應該保持一致。
super()函數可以調用父類的一個方法,以多繼承問題。
類的專有方法:
__init__: 構造函數,在生成對象時調用
__del__: 析構函數,釋放對象時使用
__repr__: 打印,轉換
__setitem__: 按照索引賦值
__getitem__: 按照索引獲取值
__len__: 獲得長度
__cmp__: 比較運算
__call__: 函數調用
__add__: 加運算
__sub__: 減運算
__mul__: 乘運算
__div__: 除運算
__mod__: 求余運算
__pow__: 乘方
類的專有方法也支持重載。
實例
class Person: """人員信息""" # 姓名(共有屬性) name = '' # 年齡(共有屬性) age = 0 def __init__(self, name='', age=0): self.name = name self.age = age # 重載專有方法: __str__ def __str__(self): return "這里重載了 __str__ 專有方法, " + str({'name': self.name, 'age': self.age}) def set_age(self, age): self.age = age class Account: """賬戶信息""" # 賬戶余額(私有屬性) __balance = 0 # 所有賬戶總額 __total_balance = 0 # 獲取賬戶余額 # self 必須是方法的第一個參數 def balance(self): return self.__balance # 增加賬戶余額 def balance_add(self, cost): # self 訪問的是本實例 self.__balance += cost # self.__class__ 可以訪問類 self.__class__.__total_balance += cost # 類方法(用 @classmethod 標識,第一個參數為 cls) @classmethod def total_balance(cls): return cls.__total_balance # 靜態方法(用 @staticmethod 標識,不需要類參數或實例參數) @staticmethod def exchange(a, b): return b, a class Teacher(Person, Account): """教師""" # 班級名稱 _class_name = '' def __init__(self, name): # 第一種重載父類__init__()構造方法 # super(子類,self).__init__(參數1,參數2,....) super(Teacher, self).__init__(name) def get_info(self): # 以字典的形式返回個人信息 return { 'name': self.name, # 此處訪問的是父類Person的屬性值 'age': self.age, 'class_name': self._class_name, 'balance': self.balance(), # 此處調用的是子類重載過的方法 } # 方法重載 def balance(self): # Account.__balance 為私有屬性,子類無法訪問,所以父類提供方法進行訪問 return Account.balance(self) * 1.1class Student(Person, Account): """學生""" _teacher_name = '' def __init__(self, name, age=18): # 第二種重載父類__init__()構造方法 # 父類名稱.__init__(self,參數1,參數2,...) Person.__init__(self, name, age) def get_info(self): # 以字典的形式返回個人信息 return { 'name': self.name, # 此處訪問的是父類Person的屬性值 'age': self.age, 'teacher_name': self._teacher_name, 'balance': self.balance(), } # 教師 Johnjohn = Teacher('John')john.balance_add(20)john.set_age(36) # 子類的實例可以直接調用父類的方法print("John's info:", john.get_info())# 學生 Marymary = Student('Mary', 18)mary.balance_add(18)print("Mary's info:", mary.get_info())# 學生 Fakefake = Student('Fake')fake.balance_add(30)print("Fake's info", fake.get_info())# 三種不同的方式調用靜態方法print("john.exchange('a', 'b'):", john.exchange('a', 'b'))print('Teacher.exchange(1, 2)', Teacher.exchange(1, 2))print('Account.exchange(10, 20):', Account.exchange(10, 20))# 類方法、類屬性print('Account.total_balance():', Account.total_balance())print('Teacher.total_balance():', Teacher.total_balance())print('Student.total_balance():', Student.total_balance())# 重載專有方法print(fake)
輸出:
John's info: {'name': 'John', 'age': 36, 'class_name': '', 'balance': 22.0} Mary's info: {'name': 'Mary', 'age': 18, 'teacher_name': '', 'balance': 18} Fake's info {'name': 'Fake', 'age': 18, 'teacher_name': '', 'balance': 30} john.exchange('a', 'b'): ('b', 'a') Teacher.exchange(1, 2) (2, 1) Account.exchange(10, 20): (20, 10) Account.total_balance(): 0 Teacher.total_balance(): 20 Student.total_balance(): 48 這里重載了 __str__ 專有方法, {'name': 'Fake', 'age': 18}
錯誤和異常
語法錯誤
SyntaxError 類表示語法錯誤,當解釋器發現代碼無法通過語法檢查時會觸發的錯誤。
語法錯誤是無法用try...except...捕獲的。
>>> print: File "
異常
即便程序的語法是正確的,在運行它的時候,也有可能發生錯誤。
運行時發生的錯誤被稱為異常。
錯誤信息的前面部分顯示了異常發生的上下文,并以調用棧的形式顯示具體信息。
>>> 1 + '0'Traceback (most recent call last): File "
異常處理
Python 提供了try ... except ...的語法結構來捕獲和處理異常。
try 語句執行流程大致如下:
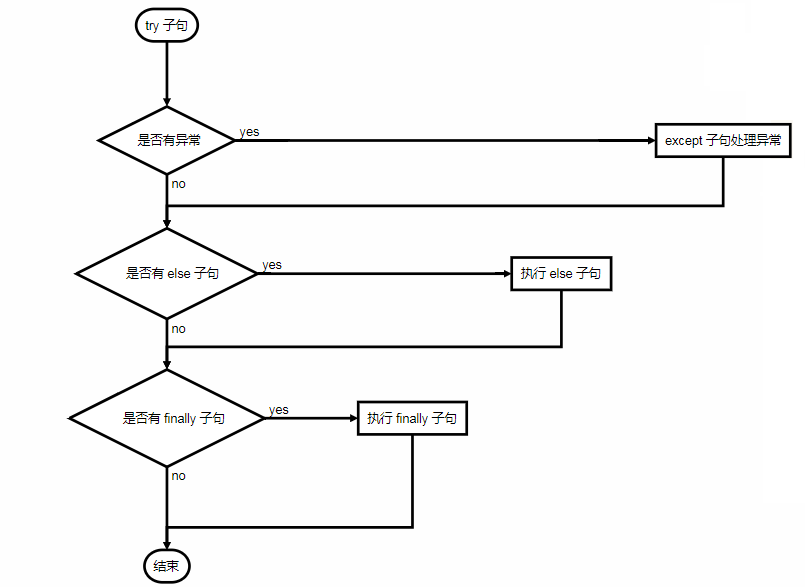
首先,執行 try 子句(在關鍵字 try 和關鍵字 except 之間的語句)。
如果沒有異常發生,忽略 except 子句,try 子句執行后結束。
如果在執行 try 子句的過程中發生了異常,那么 try 子句余下的部分將被忽略。
如果異常的類型和 except 之后的名稱相符,那么對應的 except 子句將被執行。
最后執行 try 語句之后的代碼。
如果一個異常沒有與任何的 except 匹配,那么這個異常將會傳遞給上層的 try 中。
一個 try 語句可能包含多個 except 子句,分別來處理不同的特定的異常。
最多只有一個 except 子句會被執行。
處理程序將只針對對應的 try 子句中的異常進行處理,而不是其他的 try 的處理程序中的異常。
一個 except 子句可以同時處理多個異常,這些異常將被放在一個括號里成為一個元組。
最后一個 except 子句可以忽略異常的名稱,它將被當作通配符使用。
可以使用這種方法打印一個錯誤信息,然后再次把異常拋出。
try except 語句還有一個可選的 else 子句,如果使用這個子句,那么必須放在所有的 except 子句之后,這個子句將在 try 子句沒有發生任何異常的時候執行。
異常處理并不僅僅處理那些直接發生在 try 子句中的異常,而且還能處理子句中調用的函數(甚至間接調用的函數)里拋出的異常。
不管 try 子句里面有沒有發生異常,finally 子句都會執行。
如果一個異常在 try 子句里(或者在 except 和 else 子句里)被拋出,而又沒有任何的 except 把它截住,那么這個異常會在 finally 子句執行后再次被拋出。
拋出異常
使用raise語句拋出一個指定的異常。
raise 唯一的一個參數指定了要被拋出的異常,它必須是一個異常的實例或者是異常的類(也就是 Exception 的子類)。
如果你只想知道這是否拋出了一個異常,并不想去處理它,那么一個簡單的 raise 語句就可以再次把它拋出。
自定義異常
可以通過創建一個新的異常類來擁有自己的異常。
異常類繼承自 Exception 類,可以直接繼承,或者間接繼承。
當創建一個模塊有可能拋出多種不同的異常時,一種通常的做法是為這個包建立一個基礎異常類,然后基于這個基礎類為不同的錯誤情況創建不同的子類。
大多數的異常的名字都以”Error”結尾,就跟標準的異常命名一樣。
實例
import sysclass Error(Exception): """Base class for exceptions in this module.""" pass# 自定義異常class InputError(Error): """Exception raised for errors in the input. Attributes: expression -- input expression in which the error occurred message -- explanation of the error """ def __init__(self, expression, message): self.expression = expression self.message = messagetry: print('code start running...') raise InputError('input()', 'input error') # ValueError int('a') # TypeError s = 1 + 'a' dit = {'name': 'john'} # KeyError print(dit['1'])except InputError as ex: print("InputError:", ex.message)except TypeError as ex: print('TypeError:', ex.args) passexcept (KeyError, IndexError) as ex: """支持同時處理多個異常, 用括號放到元組里""" print(sys.exc_info())except: """捕獲其他未指定的異常""" print("Unexpected error:", sys.exc_info()[0]) # raise 用于拋出異常 raise RuntimeError('RuntimeError')else: """當無任何異常時, 會執行 else 子句""" print('"else" 子句...')finally: """無論有無異常, 均會執行 finally""" print('finally, ending')
文件操作
打開文件
open()函數用于打開/創建一個文件,并返回一個 file 對象:
open(filename, mode)
filename:包含了你要訪問的文件名稱的字符串值
mode:決定了打開文件的模式:只讀,寫入,追加等
文件打開模式:
文件對象方法
fileObject.close()
close() 方法用于關閉一個已打開的文件。
關閉后的文件不能再進行讀寫操作,否則會觸發 ValueError 錯誤。
close() 方法允許調用多次。
當 file 對象,被引用到操作另外一個文件時,Python 會自動關閉之前的 file 對象。 使用 close() 方法關閉文件是一個好的習慣。
fileObject.flush()
flush() 方法是用來刷新緩沖區的,即將緩沖區中的數據立刻寫入文件,同時清空緩沖區,不需要是被動的等待輸出緩沖區寫入。
一般情況下,文件關閉后會自動刷新緩沖區,但有時你需要在關閉前刷它,這時就可以使用 flush() 方法。
fileObject.fileno()
fileno() 方法返回一個整型的文件描述符(file descriptor FD 整型),可用于底層操作系統的 I/O 操作。
fileObject.isatty()
isatty() 方法檢測文件是否連接到一個終端設備,如果是返回 True,否則返回 False。
next(iterator[,default])
Python 3 中的 File 對象不支持 next() 方法。
Python 3 的內置函數next()通過迭代器調用__next__()方法返回下一 項。
在循環中,next()函數會在每次循環中調用,該方法返回文件的下一行, 如果到達結尾(EOF),則觸發 StopIteration。
fileObject.read()
read() 方法用于從文件讀取指定的字節數,如果未給定或為負則讀取所有。
fileObject.readline()
readline() 方法用于從文件讀取整行,包括 “ ” 字符。
如果指定了一個非負數的參數,則返回指定大小的字節數,包括 “ ” 字符。
fileObject.readlines()
readlines() 方法用于讀取所有行(直到結束符 EOF)并返回列表,該列表可以由 Python 的for... in ...結構進行處理。
如果碰到結束符 EOF,則返回空字符串。
fileObject.seek(offset[, whence])
seek() 方法用于移動文件讀取指針到指定位置。
whence 的值, 如果是 0 表示開頭, 如果是 1 表示當前位置, 2 表示文件的結尾。
whence 值為默認為0,即文件開頭。
例如:
seek(x, 0):從起始位置即文件首行首字符開始移動 x 個字符
seek(x, 1):表示從當前位置往后移動 x 個字符
seek(-x, 2):表示從文件的結尾往前移動 x 個字符
fileObject.tell(offset[, whence])
tell() 方法返回文件的當前位置,即文件指針當前位置。
fileObject.truncate([size])
truncate() 方法用于從文件的首行首字符開始截斷,截斷文件為 size 個字符,無 size 表示從當前位置截斷;截斷之后 V 后面的所有字符被刪除,其中 Widnows 系統下的換行代表2個字符大小。
fileObject.write([str])
write() 方法用于向文件中寫入指定字符串。
在文件關閉前或緩沖區刷新前,字符串內容存儲在緩沖區中,這時你在文件中是看不到寫入的內容的。
如果文件打開模式帶 b,那寫入文件內容時,str (參數)要用 encode 方法轉為 bytes 形式,否則報錯:TypeError: a bytes-like object is required, not 'str'。
fileObject.writelines([str])
writelines() 方法用于向文件中寫入一序列的字符串。
這一序列字符串可以是由迭代對象產生的,如一個字符串列表。換行需要指定換行符 。
實例
filename = 'data.log'# 打開文件(a+ 追加讀寫模式)# 用 with 關鍵字的方式打開文件,會自動關閉文件資源with open(filename, 'w+', encoding='utf-8') as file: print('文件名稱: {}'.format(file.name)) print('文件編碼: {}'.format(file.encoding)) print('文件打開模式: {}'.format(file.mode)) print('文件是否可讀: {}'.format(file.readable())) print('文件是否可寫: {}'.format(file.writable())) print('此時文件指針位置為: {}'.format(file.tell())) # 寫入內容 num = file.write("第一行內容 ") print('寫入文件 {} 個字符'.format(num)) # 文件指針在文件尾部,故無內容 print(file.readline(), file.tell()) # 改變文件指針到文件頭部 file.seek(0) # 改變文件指針后,讀取到第一行內容 print(file.readline(), file.tell()) # 但文件指針的改變,卻不會影響到寫入的位置 file.write('第二次寫入的內容 ') # 文件指針又回到了文件尾 print(file.readline(), file.tell()) # file.read() 從當前文件指針位置讀取指定長度的字符 file.seek(0) print(file.read(9)) # 按行分割文件,返回字符串列表 file.seek(0) print(file.readlines()) # 迭代文件對象,一行一個元素 file.seek(0) for line in file: print(line, end='')# 關閉文件資源if not file.closed: file.close()
輸出:
文件名稱: data.log文件編碼: utf-8文件打開模式: w+文件是否可讀: True文件是否可寫: True此時文件指針位置為: 0寫入文件 6 個字符 16第一行內容 16 41第一行內容第二次['第一行內容 ', '第二次寫入的內容 ']第一行內容第二次寫入的內容
序列化
在 Python 中 pickle 模塊實現對數據的序列化和反序列化。pickle 支持任何數據類型,包括內置數據類型、函數、類、對象等。
方法
dump
將數據對象序列化后寫入文件
pickle.dump(obj, file, protocol=None, fix_imports=True)
必填參數 obj 表示將要封裝的對象。
必填參數 file 表示 obj 要寫入的文件對象,file 必須以二進制可寫模式打開,即wb。
可選參數 protocol 表示告知 pickle 使用的協議,支持的協議有 0,1,2,3,默認的協議是添加在 Python 3 中的協議3。
load
從文件中讀取內容并反序列化
pickle.load(file, fix_imports=True, encoding='ASCII', errors='strict')
必填參數 file 必須以二進制可讀模式打開,即rb,其他都為可選參數。
dumps
以字節對象形式返回封裝的對象,不需要寫入文件中
pickle.dumps(obj, protocol=None, fix_imports=True)
loads
從字節對象中讀取被封裝的對象,并返回。
pickle.loads(bytes_object, fix_imports=True, encoding='ASCII', errors='strict')
實例
import pickledata = [1, 2, 3]# 序列化數據并以字節對象返回dumps_obj = pickle.dumps(data)print('pickle.dumps():', dumps_obj)# 從字節對象中反序列化數據loads_data = pickle.loads(dumps_obj)print('pickle.loads():', loads_data)filename = 'data.log'# 序列化數據到文件中with open(filename, 'wb') as file: pickle.dump(data, file)# 從文件中加載并反序列化with open(filename, 'rb') as file: load_data = pickle.load(file) print('pickle.load():', load_data)
輸出:
pickle.dumps(): b'x80x03]qx00(Kx01Kx02Kx03e.'pickle.loads(): [1, 2, 3]pickle.load(): [1, 2, 3]
命名規范
Python 之父 Guido 推薦的規范
-
編碼
+關注
關注
6文章
935瀏覽量
54760 -
數據庫
+關注
關注
7文章
3763瀏覽量
64274 -
python
+關注
關注
56文章
4782瀏覽量
84449
原文標題:Python 3 入門,看這篇就夠了!
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
python基礎教程實例之python基礎入門100例程序分享

python的基礎知識培訓教程課件免費下載







 工商網監
工商網監
評論