 采用HDFS技術的云存儲的應用解決方案
采用HDFS技術的云存儲的應用解決方案
海量的高校信息資源需要整合,這是當前不爭的事實,因為高校信息資源存在著資源分布不均衡、更新維護成本高、共享程度低和安全性差等一系列問題。整合需要解決的首要問題就是信息的合理存儲,以便實現對其高效、安全的訪問。與傳統的存儲方式相比,云存儲很好地解決了這個問題。
云存儲(Cloud Storage)是在云計算(Cloud Computing)概念上延伸和發展出來的一個新的概念,它是指通過集群應用、網格技術或分布式文件系統等功能,將網絡中大量各種不同類型的存儲設備通過應用軟件集合起來協同工作,共同對外提供數據存儲和業務訪問功能的一個系統。
1 存儲方式的比較
高可靠性:云存儲實現對信息的分布式存儲,信息被切分為多個數據塊分散存儲在云中的節點中,實現了多副本備份機制,因此安全性要遠高于傳統的單一甚至帶有鏡像服務器的信息存儲方式。
訪問的高效性:云中的控制節點通過"心跳檢測"不斷地監視存儲節點的狀態,當發現存儲節點已經失效時,控制節點能夠將工作負載交給那些運行正常的存儲節點來完成。同時,由于云中的數據是分布式的存儲,能夠很好地分擔存儲和訪問的壓力,這些都使得云存儲具有很高訪問的效率。
存儲成本低:原先的信息資源的存儲一般使用專業的存儲設備,價格不菲,使得資源存儲的成本也隨之提高。而云中的存儲設備都是廉價的商業機,跟單一的大容量專業存儲設備相比較,存儲容量更大,存儲成本更低。
管理便捷:云存儲能夠在軟件層做到自動容錯而不依賴硬件本身的容錯,而且將信息資源存儲在云中,有利于對資源進行統一的管理,提高資源的使用率。
另外,云存儲還具有超強的可擴展性、不受具體地理位置所限、基于商業組件、按照使用收費(如每G收15美分)、可跨不同應用等。所有這些充分體現了云存儲這種方式的優越性。
2 基于HDFS的云存儲
2.1 HDFS的引入
目前各大公司都有自己的云存儲產品,如微軟公司的"Windows Live Sky Drive"網絡移動硬盤服務、Google公司的"Google Stora ge"的云計算存儲服務、亞馬遜的Amazon webservices等。
在眾多的云存儲產品技術中,HDFS技術可以實施運行在普通的PC集群上,有效降低存儲成本,該技術是Google文件系統(GFS)的開源實現,是分布式計算開源框架Hadoop的底層實現,Hadoop是Google集群系統的一個開源項目總稱,Google集群系統是使用低成本的成熟技術構建的一個穩定、高性能、高可用性、可擴展的系統。Hadoop平臺雖然是一項新興的技術,但它的發展非常迅速,已開始被應用在企業、高校、科研機構等各個行業。文中重點研究HDFS云存儲在高校信息整合中是如何應用的。
2.2 HDFS的理論剖析
Hadoop文件系統(Hadoop Distributed File System,HDFS)雖然和現有的文件系統有相似之處,也是可以運行在普通的硬件之上的分布式文件系統,但是HDFS具有高容錯性,可以部署在低成本的硬件之上,可以以流的方式訪問文件數據,從而高吞吐量地對應用程序進行訪問,這些還是和一般的文件系統有區別的。圖1是HDFS體系結構圖。
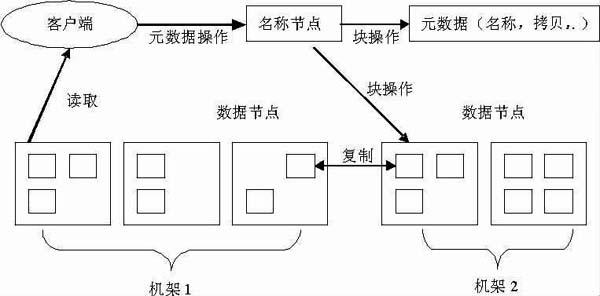
圖1 HDFS體系結構圖
研究HDFS的體系結構圖可以得知,名稱節點上保存這控制數據節點信息的元數據。客戶端可以通過名稱節點對元數據進行操作,也可以直接對數據節點進行讀寫。HDFS體系結構是個主從結構,這個主從結構常由單個的名稱節點和多個數據節點組成,名稱節點負責管理文件命名空間和客戶端訪問的主服務器,而數據節點則負責對存儲進行管理,下面來剖析一下體系結構各部分的功能。
2.2.1 名稱節點和數據節點的功能
名稱節點的功能包括4個方面:一是管理元數據和文件塊:二是管理文件系統的命名空間,包括記錄文件系統元數據被修改的情況:三是監聽客戶端和數據節點請求和處理這些請求。客戶端事件比較復雜,比如名字空間的創建與刪除,文件的創建、刪除和修改等,數據節點的事件包括文件塊信息變化、心跳響應等:四是心跳檢測。所謂心跳檢測,就是數據節點會定期將自己的負載情況通過心跳信息向名稱節點匯報。
數據節點的功能包括3個方面:一是通過自身服務進程與文件系統客戶端打交道,完成數據塊的讀寫;二是周期性的向名稱節點發送信號,報告本節點的狀態;三是執行數據的流水線復制。
2.2.2 元數據和數據交互
HDFS體系結構中有三種類型的元數據保存在名稱節點的內存中,分別是:文件(包含目錄)的名字空間、文件到文件塊的映射、文件塊的位置信息。這種數據結構對于數據訪問的效率和安全性都有很大的幫助。
HDFS中數據的交互無外乎數據的讀和寫,重點設計的對象就是客戶端、名稱節點和數據節點。客戶端首先從名稱節點中讀取對應的文件塊信息,再和數據節點建立連接并獲取數據,圖2具體描述了數據讀取過程。
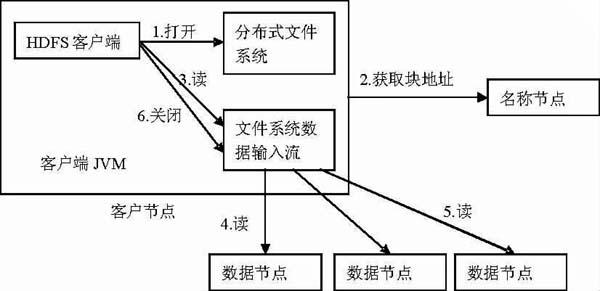
圖2HDFS 數據讀取過程
HDFS的數據寫入過程比讀取過程細節上更為復雜一些,但是模型圖非常類似。除了數據的讀寫,維護數據的可用性和一致性也是系統最基本的要求和重要的功能。一般來說,系統通過數據復制、節點故障、數據校驗、垃圾回收機制來維護數據的可用性和一致性。
3 HDFS的云存儲應用于整合高校信息資源
3.1 系統分析與設計
目前高校信息資源面臨著空前的海量數據管理難題,存儲數據的成本在不斷增加,而且信息的安全性也亟待提高。因此要借用云存儲這種新的工作模式來解決這個問題。根據高校的特殊情況,結合云存儲的優點,要設計一個成功的云存儲案例,需要考慮這么幾個方面:
1)低成本海量存儲 將數據存儲在一般的個人電腦構成的網絡中,并進行合理調配,構成一個有機海量存儲設備。
2)高效率的訪問 數據盡可能的存儲在不同的數據節點中,當客戶端對信息進行請求時,能高效的回復,并做到并發。
3)安全性高 每個文件都會有多個副本分別存儲在多個數據節點上。如果某個數據節點出現問題,不會發生文件丟失的現象。
3.2 系統功能設計
高校相對于云存儲系統是一個用戶,而高校內部有多個部門,相對于云存儲系統的用戶高校來說是一個子用戶。云存儲系統能夠創建、管理、維護高校云存儲用戶;高校云用戶能夠創建、管理、維護各部門子用戶。而子用戶才是真正的終端信息存儲用戶,他們上傳、下載、刪除數據信息。由于我們的這個系統是基于HDFS的,而一個基本的HDFS由一個NameNode和n個DataNode組成,云存儲系統是由多個地方的HDFS存儲設備通過應用軟件集合起來協同工作,完成外部訪問請求。可以將本文描述的分布式文件系統(DFS)抽象成一個三級模型,如圖3所示。
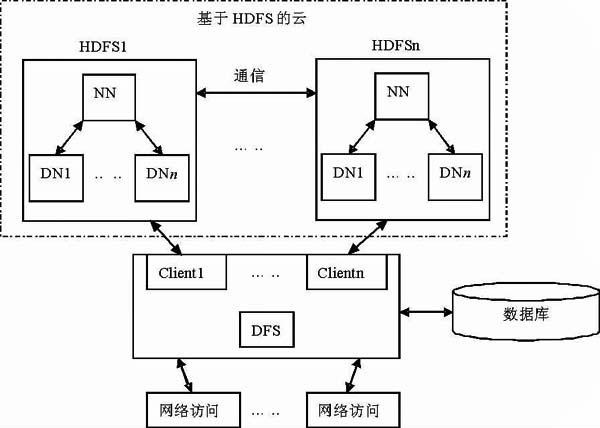
圖3 系統結構圖
根據系統結構圖可以清楚看到本文描述的分布式文件系統(DFS)的業務邏輯模型:終端網絡發出信息存取訪問請求,DFS通過封裝與HDFS通信協議的Client客戶端與基于HDFS的云存儲系統進行通信,完成對信息的訪問。HDFS存儲業務以云狀分布在網絡的各個部分,它具有容量大、性能高、可靠性好、協同優良的特點,正是這些特點,完成了高校信息資源高效訪問與存儲。
4 結論
基于HDFS的云存儲是一種動態可調整、基于互聯網的存儲解決方案,用戶可以通過通用和易用協議和應用程序接口通過網絡訪問存儲目標,這種新技術對最終用戶來說很有好處。云存儲可以讓用戶很容易增加存儲容量,而且不需要購買、安裝和管理任何存儲基礎設施,卻提供了一個完善的備份、容災數據中心。云存儲的成本和易用性優勢對高校具有很強的吸引力,發展和應用前景廣闊。
-
Google
+關注
關注
5文章
1758瀏覽量
57417 -
云計算
+關注
關注
39文章
7742瀏覽量
137208 -
云存儲
+關注
關注
7文章
732瀏覽量
45996
發布評論請先 登錄
相關推薦

采用Sun StorEdge技術創建存儲解決方案
269私有云服務器的完全解決方案
hadoop hdfs 文件優點
如何用MRAM和NVMe SSD構建未來的云存儲的解決方案
云備份解決方案的考慮要素

基于HDFS校園云存儲平臺
應對海量圖片存儲的分布式存儲解決方案





 工商網監
工商網監
評論