 采用FPGA來實現系統定制流量管理
采用FPGA來實現系統定制流量管理
目前硬件高速轉發技術的趨勢是將整個轉發分成兩個部分:PE(Protocol Engine,協議引擎)和TM(Traffic Management,流量管理)。其中PE完成協議處理,TM負責完成隊列調度、緩存管理、流量整形、QOS等功能,TM與轉發協議無關。
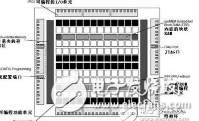
隨著通信協議的發展及多樣化,協議處理部分PE在硬件轉發實現方面,普遍采用現有的商用芯片NP(Network Processor,網絡處理器)來完成,流量管理部分需要根據系統的需要進行定制或采用商用芯片來完成。在很多情況下NP芯片、TM芯片、交換網芯片無法選用同一家廠商的芯片,這時定制TM成為了成本最低、系統最優化的方案,一般采用FPGA來實現,TM的常規結構如圖1所示。
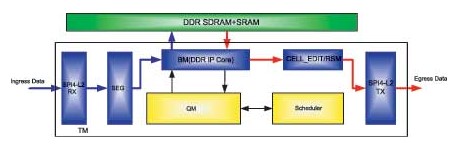
圖1 TM的常規結構圖
目前主流的TM接口均為SPI4-P2接口形式,SPI4-P2接口信號速率高,TCCS(Chan nel-to-channel skew,數據通道的抖動,包含時鐘的抖動)難以控制,在常規情況下很難做到很高的速率。SPI4-P2接口為達到高速率同時避免TCCS問題在很多情況下都對接收端提出了DPA(動態相位調整)的要求。對于SPI4-P2接口形式可直接采用Altera公司的IP Core實現。Altera的主流FPGA均實現了硬件DPA功能,以Stratix II器件為例,在使能DPA的情況下使用SPI4-P2 IP Core可實現16Gb/s的接口數據速率。
SEG模塊為數據切分塊,根據交換網的數據結構要求,在上交換網的方向上負責把IP包或數據包切分為固定大小的數據塊,方便后期的存儲調度以及交換網的操作處理,SEG模塊可配合使用SPI4-P2 IP Core來實現。與SEG模塊對應的是RSM模塊,RSM模塊將從交換網下來的數據塊重新組合成完整的IP包或數據包。
BM(Buffer Management)模塊為緩沖管理模塊,管理TM的緩沖單元,完成DRAM的存取操作。外部DRAM的控制部分可使用使用DDR SDRAM IP Core實現。
QM模塊為隊列管理模塊,負責完成端口的數據隊列管理功能,接收BM模塊讀寫DRAM時的數據入隊、出隊請求,TM所能支持的數據流的數目、業務類型數目、端口的數目等性能指標在QM模塊處體現出來。
Scheduler模塊為調度模塊,根據數據包類型及優先級和端口分配的帶寬進行調度,TM流量整形、QOS等功能通過調度模塊實現。
CELL_EDIT模塊完成輸出數據的封裝,把由DRAM中讀出的數據封裝后發送出去。
在TM中需要基于數據服務策略對于不同服務等級的數據包進行不同的管理策略,同時要保證流媒體的數據包不能亂序,數據包有大有小,經過SEG模塊所分割成的數據塊的數目也有多有少,這樣就必須有一套行之有效的數據結構基于鏈表的方法管理這些數據。QM模塊基于業務、數據流的方式管理隊列,包的管理便由BM模塊完成。
BM模塊中基于包的數據結構方面由兩部分構成:BRAM和PRAM。BRAM為數據緩沖區,對應片外的DRAM。BRAM負責存儲數據單元,相對于SEG模塊切分的數據單元,BRAM內有相應大小的存儲單元BCELL與之對應,BCELL在BRAM內以地址空間劃分,每個BCELL相同大小,BCELL為BRAM的最小存取單元。在實際系統中基于SEG模塊切分的數據單元大小,BCELL一般為64~512B。
PRAM為指針緩沖區,PRAM對應片外的SSRAM。PRAM內部同樣以地址空間分為PCELL,PCELL與BCELL一一對應,每一個PCELL對應于一個BCELL,對應的PCELL與BCELL地址相同。
PCELL的地址對應的代表相應單元的BCELL的地址,PCELL中的基本信息是下一跳指針。PRAM與BRAM關系如圖2所示。
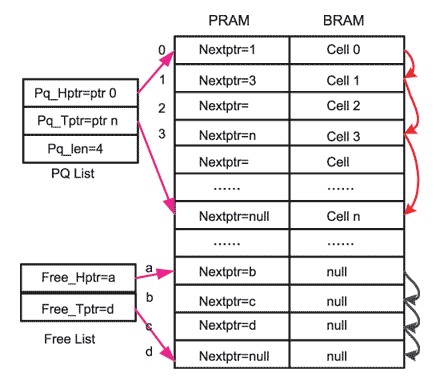
圖2 PRAM與BRAM關系圖
在PRAM中存在兩種鏈表形式,PQ List代表已經存儲的數據包鏈表。為方便數據讀出,PQ List需要記錄數據包的第一個數據塊地址,即首指針Pq_Hptr,為方便新的數據寫入,PQ List需要記錄數據包的最后一個數據塊地址,即尾指針Pq_Tptr。PQ List同時需要記錄該鏈表的長度作為調度模塊進行調度的權值計算使用。
Free List代表空閑的地址隊列。為方便地辨識、管理空閑的地址,避免地址沖突,在BM中將所有空閑的地址使用一個鏈表進行管理。這個鏈表就是空閑地址隊列。空閑地址隊列依據系統需求的不同有著不同的形式,一般空閑地址隊列的構成和PQ List相似,由空閑地址首指針Free_Hptr和空閑地址尾指針Free_Tptr構成。BM模塊的所有操作都圍繞著空閑的地址隊列Free List進行。
基于BM模塊的數據流結構,BM模塊一般分為Write Control模塊、Free List control模塊、Read Control模塊、PRAM Control模塊、BRAM Control模塊。BM的結構如圖3所示。
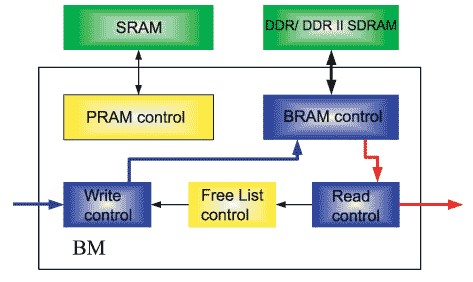
圖3 BM結構圖
Write Control模塊從Free List模塊處得到空閑地址,向BRAM Control模塊提出寫請求,同時更新PRAM中的內容。Free List control模塊負責管理空閑地址列表,提供Write Control模塊的寫BRAM地址及PRAM地址,回收經Read Control模塊讀出數據塊后釋放的地址。Read Control模塊根據調度器的調度結果,通過BRAM Control模塊讀出需要發送的數據單元,同時將釋放的緩沖單元地址寫入空閑地址列表。PRAM Control模塊為外部SSRAM的控制模塊,可直接使用參考設計完成。BRAM Control模塊為外部DRAM控制模塊,一般分為Datapath與Controler兩個子模塊。Datapath模塊專門負責數據接口部分,完成DRAM接口的DQ、DQS處理以及相應的延時調整,Controler模塊負責完成DRAM的控制需求。
在BM模塊中,BRAM的帶寬與PRAM的帶寬一般為TM的瓶頸。PRAM的帶寬主要受限于訪問的次數,而BRAM的帶寬受限于接口帶寬。例如對于一個10G的TM,BRAM的有效帶寬必須保證20G,以接口利用率最差只能達到65%計算(考慮SEG模塊切分信元出現的N+1問題),需要保證接口帶寬達到30G。使用64位的DRAM接口,接口速率不能低于500MB/s,這樣對Datapath模塊的設計提出了更高的要求。在實際系統中,BRAM主要使用DDR SDRAM、DDR II SDRAM。
當使用Stratix II FPGA,BRAM使用DDR II SDRAM時,測試表明DDR II SDRAM接口速率可達到800MB/s。在常規使用的情況下,DDR II SDRAM接口速率可保證達到667MB/s。對于一個64位的DRAM接口,接口速率可達到42.7GB/s,完全可以滿足一個10G的TM系統。
BM模塊作為緩沖管理模塊,緩沖的基本單元為BCELL,基于對BCELL的管理,對于BM的操作都牽涉到空閑地址隊列的操作以及鏈表的操作。最基本的操作就是寫入操作和讀出操作。BM模塊的寫入操作由Write Control模塊發起。
對于Write Control模塊,有數據單元需要寫入,首先向Free List模塊申請空閑地址,Free List將首指針a給Write Control模塊,作為該數據塊的寫地址,同時讀出首指針a對應在PRAM中的內容,得到下一跳地址b,將下一跳地址b作為新的空閑地址首指針。
PQ List將尾指針n更新為新寫入的地址a,同時更新PRAM中n地址的內容,將a作為下一跳添入n地址。基于節省操作周期,NULL的內容保留原值,不再更新。這樣,一次BRAM的寫入操作需要一次PRAM的讀取操作及一次PRAM的寫入操作。
QM模塊接收調度模塊的出隊信息,將出隊的PQ鏈表信息傳送給BM模塊進行讀取操作。
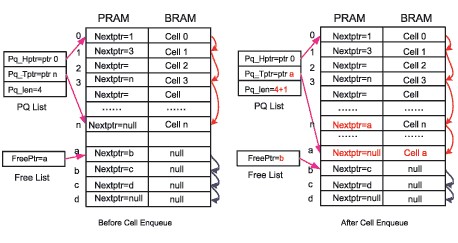
圖4 BM模塊的寫入操作
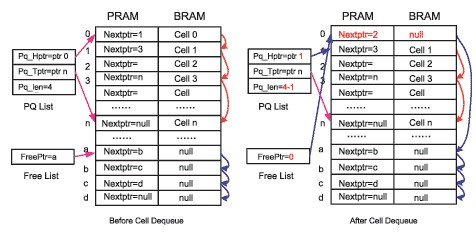
圖5 讀出操作的Free List堆棧結構
BM模塊的讀取操作由Read Control模塊發起完成,當有數據單元需要讀出,相應的數據單元地址則需要回收進入空閑地址隊列Free List。對于不同的系統需求,空閑地址隊列Free List有不同的形式。比較簡單的操作是將Free List作為堆棧形式使用。
Read Control模塊由PQ List的首地址0讀出相應的BRAM中的內容,同時讀出PRAM中對應的下一跳地址1,更新地址1為新的首地址。Free List將首指針a更新為剛釋放的地址0,同時地址0中寫入下一跳指針a。這樣一次BRAM的讀出操作需要一次PRAM的讀取操作及一次PRAM的寫入操作。
作為堆棧形式的空閑地址隊列在實際操作中會把一部分空閑地址隊列放入片內緩沖中。這樣在讀BRAM釋放地址進入空閑地址隊列時可以節省PRAM的一次寫入操作,在寫BRAM時申請空閑地址時可以節省PRAM的一拍讀取操作。PRAM堆棧結構下內置空閑地址隊列表如圖6所示。
圖6 PRAM堆棧結構下內置空閑地址隊列表
以圖5的讀出操作為例,當Read Control模塊由PQ List的首地址0讀出相應的BRAM中的內容,同時讀出PRAM中對應的下一跳地址1,更新地址1為新的首地址。這時,地址0為已經釋放的地址,按空閑隊列的操作要求,地址0需要進入空閑地址隊列中,在寫操作時再將地址0讀出提供給Write Control模塊用于寫BRAM。而基于圖6的結構,地址0在被釋放后不再進行更新PRAM中的空閑地址隊列Free List的操作,直接寫入片內緩沖中,在Write Control模塊申請地址時由片內緩沖中讀出提供給Write Control模塊 。僅在片內Free List緩沖幾乎滿時,進行PRAM中的空閑地址隊列Free List的更新操作,或在片內Free List緩沖空時進行PRAM中的空閑地址隊列Free List的讀取操作。基于圖6的結構,在一個讀寫周期內,可以節省兩次PRAM的操作,在最壞情況下也可節省一次PRAM的操作。但基于堆棧的結構,棧頂的地址被高頻率的反復的調用,棧底的地址很難被使用,DRAM的工作壽命會因此受到影響。為保證DRAM的工作壽命,在有些系統中將空閑地址隊列Free List做成鏈表形式,從而保證每個DRAM的存儲空間都能被平均的使用。讀出操作的Free Lis鏈表結構如圖7所示。
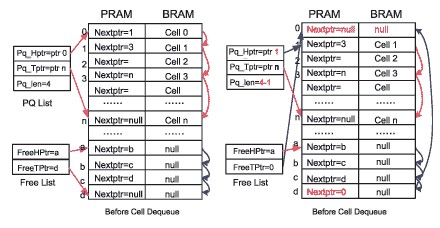
圖7 讀出操作的Free Lis鏈表結構
Read Control模塊由PQ List的首地址0讀出相應的BRAM中的內容,同時讀出PRAM中對應的下一跳地址1,更新地址1為新的首地址。
Free List相對于堆棧模式增加尾指針d。Free List在回收地址時維持首指針a不變,將尾指針d更新為剛釋放的地址0,同時地址d中寫入下一跳指針0。這樣一次BRAM的讀出操作同樣需要一次PRAM的讀取操作及一次PRAM的寫入操作。對于鏈表方式的空閑地址隊列Free List,在每個讀、寫周期必須進行兩次PRAM的寫入操作及兩次PRAM的讀取操作,PRAM的效率不高。
針對兩種空閑地址隊列的效率及對DRAM的影響,在很多系統中采用了折中的方法,即在PRAM中使用鏈表方法管理空閑地址隊列Free List,在片內采用堆棧模式另建一個空閑地址隊列Free List,在這種情況下,每個讀、寫周期需要三次PRAM的操作。
在實際系統中,BRAM的帶寬與PRAM的帶寬一般為TM的瓶頸,PRAM主要受限于訪問的次數,而BRAM受限于接口帶寬。
在10G的TM系統中,片內數據總線的位寬定為128位,系統時鐘定為150MHz,BCELL的大小定為64B。在這種情況下,讀取操作和寫入操作均為4個時鐘周期。在滿足10G系統的需求下,讀取、寫入操作周期為7個時鐘周期。在前面曾計算過,在滿足10G TM系統的情況下,BRAM采用64位 DDR II SDRAM,接口時鐘使用250MHz即可滿足數據接口的需求。PRAM采用32位ZBT SRAM ,接口時鐘使用系統時鐘,每個PCELL為64位,每個讀、寫周期需要6個時鐘周期完成。在實際系統中采用Altera FPGA,BM的設計可以滿足10G的TM線速工作的需求。
在40G核心網的TM系統中,片內數據總線的位寬為256位,系統時鐘采用250MHz(在40GE的系統中可選用200MHz)。采用DDR II SDRAM,接口時鐘使用333MHz,則192位的BRAM可以滿足40G的TM需求。此時,BCELL可為96B、192B、384B,在這里選用192B。當BCELL選用192B時,讀取操作和寫入操作同樣均為6個時鐘周期。在滿足40G系統的需求下,讀取、寫入操作周期為9個時鐘周期。PRAM采用48位QDR SRAM,接口時鐘使用150MHz,每個PCELL為96位,在每個讀、寫時鐘周期內,PRAM最多可被操作5次。在采用Altera FPGA的情況下,BRAM采用192位 DDR II SDRAM,PRAM采用48位QDR SRAM,BM的設計可以滿足40G的TM線速工作的需求。
-
處理器
+關注
關注
68文章
19161瀏覽量
229122 -
FPGA
+關注
關注
1626文章
21666瀏覽量
601836 -
芯片
+關注
關注
453文章
50402瀏覽量
421802
發布評論請先 登錄
相關推薦
遠程管理系統定制
適用于FPGA、GPU和ASIC系統的電源管理
適用于FPGA、GPU和ASIC系統的電源管理
如何實現定制緩沖管理?
怎么實現基于FPGA的具有流量控制機制的高速串行數據傳輸系統設計?
基于FPGA和IP Core的定制緩沖管理的實現

采用FPGA實現同步、幀同步系統的設計
采用FPGA與IP來實現DDR RAM控制和驗證的方法





 工商網監
工商網監
評論