 半監督學習算法的現實性評價
半監督學習算法的現實性評價
編者按:半監督學習是近年來非常熱門的一個研究領域,畢竟機器學習模型的本質是個“吃”數據的“怪獸”,雖然現實世界擁有海量數據,但針對某個問題的標記數據卻仍極度稀缺。為了用更少的標記數據完成更多現實任務,研究人員想出了這種從無標記數據中提取數據結構的巧妙做法。那么它能被用于現實任務嗎?今天論智帶來的是NIPS 2018收錄的一篇Google Brain論文:Realistic Evaluation of Semi-Supervised Learning Algorithms。
摘要
當遇到標簽有限或沒有足夠經費請人標記數據等問題時,半監督學習(SSL)提供了一個強大的框架。近年來,基于深層神經網絡的SSL算法在標準基準測試任務中被證明是有用的。但是,我們認為這些基準測試并不能解決在應用于實際任務時,這些算法將面臨的各種問題。
我們為一些廣泛使用的SSL算法重新創建了統一實現,并在一系列任務中對它們進行了測試。實驗發現:那些不使用未標記數據的簡單基線的性能通常被低估了;對于不同數量的標記數據和未標記數據,SSL算法的敏感程度也不同;并且當未標記數據集中包含不屬于該類的數據時,網絡性能會大幅降低。
為了幫助指導SSL研究真正能適應現實世界,我們公開了論文的統一重新實現和評估平臺。
簡介
無數實驗已經證實,如果我們對大量數據進行標記,那么深層神經網絡就能在某些監督學習任務上實現和人類相仿,甚至超人的表現。然而,這種成功是需要代價的。也就是說,為了創建大型數據集,我們往往要耗費大量的人力、財力和風險在數據標記上。因此對于許多現實問題,它們沒有足夠的資源來構建足夠大的數據集,這就限制了深度學習的廣泛應用。
解決這一問題的一種可行方法是使用半監督學習框架。和需要標記數據的監督學習算法相比,SSL算法能從未標記數據中提取數據結構,進而提高網絡性能,這降低了操作門檻。而最近的一些研究結果也表明,在某些情況下,即便給定數據集中的大部分數據都遺失了標簽,SSL算法也能接近純監督學習的表現。
面對這些成功,一個自然而然的問題就是:SSL算法能否被用于現實世界的任務?在本文中,我們認為答案是否定的。具體而言,當我們選擇一個大型數據集,然后去除其中的大量標簽對比SSL算法和純監督學習算法時,我們其實忽略了算法本身的各種常見特征。
下面是我們的一些發現:
如果兩個神經網絡在調參上花費相同資源,那么用SSL和只用標記數據帶來的性能差異會小于以往論文的實驗結論。
不使用未標記數據的、高度正則化的大型分類器往往具有強大性能,這證明了在同一底層模型上評估不同SSL算法的重要性。
如果先在不同的標記數據集上預訓練模型,之后再在指定數據集上訓練模型,它的最終性能會比用SSL算法高不少。
如果未標記數據中包含與標記數據不同的類分布,使用SSL算法的神經網絡的性能會急劇下降。
事實上,小的驗證集會妨礙不同方法、模型和超參數設置之間的可靠比較。
評估方法改進
科研人員評估SSL算法一般遵循以下流程:首先,選擇一個用于監督學習的通用數據集,刪去其中大多數數據的標簽;其次,把保留標簽的數據制作成小型數據集D,把未標記數據整理成數據集DUL;最后,用半監督學習訓練一些模型,在未經修改的測試集上檢驗它們的性能。
但下面是現有方法的缺陷及其改進:
P.1 一個共享的實現
現有SSL算法比較沒有考慮底層模型的一致性,這是不科學的。在某些情況下,同樣是簡單的13層CNN,不同實現會導致一些細節,比如參數初始化、數據預處理、數據增強、正則化等,發生改變。不同模型的訓練過程(優化、幾個epoch、學習率)也是不一樣的。因此,如果不用同一個底層實現,算法對比不夠嚴謹。
P.2 高質量監督學習基線
SSL的目標是基于標記數據集D和未標記數據集DUL,使模型的性能比單獨用D訓練出來的完全相同的基礎模型更好。雖然道理很簡單,但不同論文對于這個基線的介紹卻存在出入,比如去年Laine&Aila和Tarvainen&Valpola在論文中用了一樣的基線,雖然模型是一樣的,但它們的準確率差竟然高達15%。
為了避免這種情況,我們參考為SSL調參,重新調整了基線模型,確保它的高質量。
P.3 和遷移學習的對比
在實踐中,如果數據量有限,通常我們會用遷移學習,把在相似大型數據集上訓練好的模型拿過來,再根據手頭的小數據集進行“微調”。雖然這種做法的前提是存在那么一個相似的、夠大的數據集,但如果能實現,遷移學習確實能提供性能強大的、通用性好的基線,而且這類基線很少有論文提及。
P.4 考慮類分布不匹配
需要注意的是,當我們選擇數據集并刪去其中大多數數據的標簽時,這些數據默認DUL的類分布和D的完全一致。但這不合理,想象一下,假設我們要訓練一個能區分十張人臉的分類器,但每個人的圖像樣本非常少,這時,你可能會選擇使用一個包含隨機人臉圖像的大型未標記數據集來進行填充,那么這個DUL中的圖像就并不完全是這十個人的。
現有的SSL算法評估都忽略了這種情況,而我們明確研究了類分布相同/類分布不同數據之間的影響。
P.5 改變標記和未標記數據的數量
改變兩種數據的數量這種做法并不罕見,研究人員通常喜歡通關刪去不同數量的底層標記數據來改變D的大小,但到目前為止,以系統的方式改變DUL確不太常見。這可以模擬兩種現實場景:一是未標記數據集非常巨大(比如用網絡數十億未標記圖像提高模型分類性能),二是未標記數據集相對較小(比如醫學影像數據,它們的成本很高)。
P.6 切合實際的小型驗證集
人為創建的SSL數據集往往有個特征,就是驗證集會比訓練集大很多。比如SVHN的驗證集大約有7000個標記數據,許多論文在用這個數據集做研究時,往往只從原訓練集里抽取1000個標記數據,但會保留完整驗證集。這就意味著驗證集是訓練集的7倍,而在現實任務中,數據更多的集一般是會被作為訓練集的。
實驗
這個實驗的目的不是產生state-of-art的結果,而是通過建立一個通用框架,對各種模型性能進行嚴格的比較分析。此外,由于我們使用的模型架構和超參數調整方法和以前的論文很不一樣,它們也沒法和過去的工作直接比較,只能單獨列出。
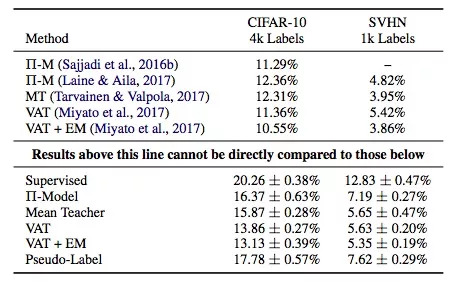
上表是實用各SSL算法的模型在驗證集上的錯誤率,它們使用了同樣的底層模型——Wide ResNet,縱坐標是監督學習和各類常用的SSL算法:Π-Model, Mean Teacher, Virtual Adversarial Training, PseudoLabeling,以及Entropy Minimization。
需要注意的是,表格上部是前人的工作,下部是本文的成果,它們不能直接對比(本文模型使用的參數是上面的一半,所以性能會差一些)。但是,透過數據我們還是可以發現:
結論1:Mean Teacher和VAT的表現總體不錯。
結論2:監督學習模型和半監督學習模型之間的性能差異并沒有其他論文中描述的那么大。
結論3:基于這個表格的數據,我們用遷移學習訓練了一個模型,發現它在CIFAR-10驗證集上的錯誤率是12%,這個結果比SSL算法更好。
上圖是各模型在CIFAR-10上的錯誤率,已知標記訓練集有6類圖像,每類圖像400個樣本。其中縱坐標是錯誤率,橫坐標是未標記數據相對標記數據的不同類分布占比,比如25%表示未標記數據集中有1/4的類是標記數據集上沒有的。陰影區是五次實驗標準差。
結論4:和不使用任何未標記數據相比,如果我們在未標記數據集中加入更多的額外類,模型的性能會降低。
結論5:SSL算法對標記數據/未標記數據的不同數據量很敏感。
上圖是各算法模型的平均驗證錯誤對比,使用的是10個大小不同的隨機采樣非重疊驗證集。實線是平均值,陰影是標準差,訓練集是包含1000個標記數據的SVHN。圖中的縱坐標是錯誤率,橫坐標是驗證集相對于訓練集的大小,比如10%表示驗證集只包含100個標記數據。
結論6:10%是個合適的比例,因此對于嚴重依賴大型驗證集做超參數調整的SSL算法,它們的實際適用性很有限,即便是交叉驗證也沒法帶來太多改善。
總結
通過上述實驗結果,我們已經證實把SSL算法用于現實實踐暫時是不恰當的,那么今后該怎么評估它們呢?下面是一些建議:
在比較不同SSL算法時,使用完全相同的底層模型。模型結構的差異,甚至是細節,都會對最終結果產生很大影響。
仔細調整基線的在使用監督學習和遷移學習時的準確率,SSL的目標應該是明顯優于完全監督學習。
呈現數據中混有其他類數據時模型的性能變化,因為這是現實場景中很常見的現象。
報告性能時,測試不同標記數據/未標記數據量下的情況。理想情況下,即便標記數據非常少,SSL算法也能從未標記數據中提取到有用信息。因此我們建議將SVHN與SVHN-Extra相結合,以測試算法在大型未標記數據中的性能。
不要在不切實際的大型驗證集上過度調參。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100545 -
算法
+關注
關注
23文章
4600瀏覽量
92649 -
SSL
+關注
關注
0文章
125瀏覽量
25721
原文標題:NIPS 2018入選論文:對深度半監督學習算法的現實評價
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于半監督學習框架的識別算法
你想要的機器學習課程筆記在這:主要討論監督學習和無監督學習
如何用Python進行無監督學習
谷歌:半監督學習其實正在悄然的進化
機器學習算法中有監督和無監督學習的區別
最基礎的半監督學習
半監督學習最基礎的3個概念
半監督學習:比監督學習做的更好
密度峰值聚類算法實現LGG的半監督學習






 工商網監
工商網監
評論