 PageRank算法所建立的模型
PageRank算法所建立的模型
引言
PageRank是Sergey Brin與Larry Page于1998年在WWW7會議上提出來的,用來解決鏈接分析中網頁排名的問題。在衡量一個網頁的排名,直覺告訴我們:
當一個網頁被更多網頁所鏈接時,其排名會越靠前;
排名高的網頁應具有更大的表決權,即當一個網頁被排名高的網頁所鏈接時,其重要性也應對應提高。
對于這兩個直覺,PageRank算法所建立的模型非常簡單:一個網頁的排名等于所有鏈接到該網頁的網頁的加權排名之和:

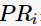 表示i個網頁的PageRank值,用以衡量每一個網頁的排名;若排名越高,則其PageRank值越大。網頁之間的鏈接關系可以表示成一個有向圖
表示i個網頁的PageRank值,用以衡量每一個網頁的排名;若排名越高,則其PageRank值越大。網頁之間的鏈接關系可以表示成一個有向圖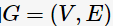 ,邊
,邊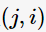 代表了網頁j鏈接到了網頁i;
代表了網頁j鏈接到了網頁i;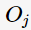 為網頁j的出度,也可看作網頁j的外鏈數( the number of out-links)。
為網頁j的出度,也可看作網頁j的外鏈數( the number of out-links)。
假定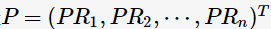 為n維PageRank值向量,A為有向圖G所對應的轉移矩陣,
為n維PageRank值向量,A為有向圖G所對應的轉移矩陣,
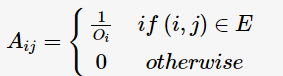
n個等式(1)改寫為矩陣相乘:

但是,為了獲得某個網頁的排名,而需要知道其他網頁的排名,這不就等同于“是先有雞還是先有蛋”的問題了么?幸運的是,PageRank采用power iteration方法破解了這個問題怪圈。欲知詳情,請看下節分解。
求解
為了對上述及以下求解過程有個直觀的了解,我們先來看一個例子,網頁鏈接關系圖如下圖所示:
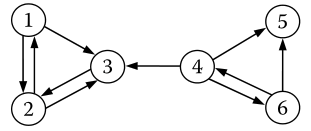
那么,矩陣A即為

所謂power iteration,是指先給定一個P的初始值,然后通過多輪迭代求解:
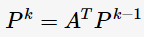
最后收斂于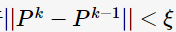 ,即差別小于某個閾值。我們發現式子(2)為一個特征方程(characteristic equation),并且解P是當特征值(eigenvalue)為1時的特征向量(eigenvector)。為了滿足(2)是有解的,則矩陣AA應滿足如下三個性質:
,即差別小于某個閾值。我們發現式子(2)為一個特征方程(characteristic equation),并且解P是當特征值(eigenvalue)為1時的特征向量(eigenvector)。為了滿足(2)是有解的,則矩陣AA應滿足如下三個性質:
stochastic matrix,則行至少存在一個非零值,即必須存在一個外鏈接(沒有外鏈接的網頁被稱為dangling pages);
不可約(irreducible),即矩陣A所對應的有向圖G必須是強連通的,對于任意兩個節點u,v∈V,存在一個從u到v的路徑;
非周期性(aperiodic),即每個節點存在自回路。
顯然,一般情況下矩陣A這三個性質均不滿足。為了滿足性質stochastic matrix,可以把全為0的行替換為e/ne/n,其中e為單位向量;同時為了滿足性質不可約、非周期,需要做平滑處理:
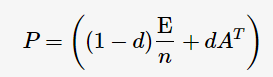
其中,d為 damping factor,常置為0與1之間的一個常數;E為單位陣。那么,式子(1)被改寫為
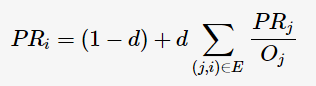
-
算法
+關注
關注
23文章
4599瀏覽量
92645 -
PageRank
+關注
關注
0文章
5瀏覽量
6651
原文標題:【十大經典數據挖掘算法】PageRank
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺技術的AI算法模型
AI算法/模型/框架/模型庫的含義、區別與聯系
ai大模型和算法有什么區別
AI大模型與小模型的優缺點
如何使用PyTorch建立網絡模型
基于神經網絡算法的模型構建方法
建立神經網絡模型的三個步驟
深度學習模型訓練過程詳解
拆解大語言模型RLHF中的PPO算法






 工商網監
工商網監
評論