 關于GN-GloVe的詞嵌入技術詳解
關于GN-GloVe的詞嵌入技術詳解
詞嵌入技術已經成為眾多自然語言處理(NLP)應用的基礎部分,然而,在現有語料上訓練的詞嵌入,常常受到社會偏見的影響,比如性別刻板印象。比如,“programmer”(程序員)是一個性別中立詞(gender-neutral words),但在新聞語料庫上訓練的嵌入模型看來,“programmer”和“male”(男性)一詞的聯系比“female”(女性)更緊密。
帶有這樣的偏見的詞嵌入模型,會給下游的NLP應用帶來嚴重問題。例如,基于詞嵌入技術的簡歷自動篩選系統或工作自動推薦系統,會歧視某種性別的候選人(候選人的姓名反映了性別)。除了造成這種明顯的歧視現象,有偏見的嵌入還可能暗中影響我們日常使用的NLP應用。比如,在搜索引擎中輸入“computer scientist”(計算機科學家),由于在嵌入空間中,“computer scientist”和男性姓名更接近,和女性姓名更疏遠,基于嵌入技術的搜索算法傾向于將男性科學家排在女性科學家之前,阻礙人們認識女性科學家,進一步加劇計算機科學領域的性別不平衡性。
圖片來源:Tolga Bolukbasi等
Bolukbasi等提出,通過后處理,可以緩解詞嵌入的性別刻板印象(arXiv:1607.06520)。具體方法是將性別中立詞投影到一個正交于性別維度的子空間,該性別維度由性別定義詞(gender-definition words)定義。所謂性別定義詞,是指定義中天然聯系性別的詞匯,例如“mother”(母親)、“waitress”(女侍者)。
然而,這一做法有兩個局限:
在投影性別中立詞之前,需要首先通過分類器識別出性別中立詞。如果分類器犯錯,那么錯誤會傳播到整個模型中,影響最終表現。
完全移除了性別信息,但是在某些領域(比如醫學、社會科學),性別信息是不可或缺的。
而UCLA的Jieyu Zhao、Yichao Zhou、Zeyu Li、Wei Wang、Kai-Wei Chang在即將召開的EMNLP 2018上發表的論文Learning Gender-Neutral Word Embeddings(學習性別中立詞嵌入),基于保護屬性(protected attributes)隔離性別信息,克服了上述兩個局限。
方法
這篇論文改造了GloVe模型,在其基礎之上增加了性別保護屬性。雖然論文選擇GloVe作為基礎嵌入模型,但論文提出的方法是通用的,可以應用于其他嵌入模型和屬性。
GloVe
首先簡單溫習下GloVe。
GloVe的主要直覺是,相比單詞同時出現的概率,單詞同時出現的概率的比率能夠更好地區分單詞。比如,假設我們要表示“冰”和“蒸汽”這兩個單詞。對于和“冰”相關,和“蒸汽”無關的單詞,比如“固體”,我們可以期望P冰-固體/P蒸汽-固體較大。類似地,對于和“冰”無關,和“蒸汽”相關的單詞,比如“氣體”,我們可以期望P冰-氣體/P蒸汽-氣體較小。相反,對于像“水”之類同時和“冰”、“蒸汽”相關的單詞,以及“時尚”之類同時和“冰”、“蒸汽”無關的單詞,我們可以期望P冰-水/P蒸汽-水、P冰-時尚/P蒸汽-時尚應當接近于1。
具體而言,GloVe基于加權最小二乘回歸模型,輸入為單詞-上下文同時出現頻次矩陣:
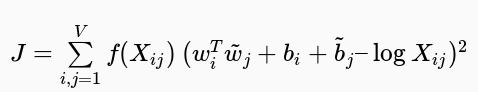
其中,f為加權函數,降低過大的同時出現頻次的影響。
GN-GloVe
這篇論文提出了一個GloVe的性別中立變體,稱為GN-Glove. GN-Glove將詞向量w分成兩部分w = [w(a); w(g)],其中w(a)∈ ?d-k表示中立成分,而w(g)∈ ?k則表示性別成分,k是為性別信息保留的維數(論文中將k設為1,即為性別信息保留一個維度)。
GN-GloVe訓練的目標是將性別特征作為保護屬性隔離在w(g)中,使w(a)中的信息不受性別影響。相應地,目標函數包括三部分:

其中,λd和λe為超參數,調節目標函數不同部分的影響力。
JG是我們之前給出的GloVe的目標函數,JD和JE迫使性別信息限于w(g)之中,使w(a)保持性別中立。
現在我們來考慮下,如何定義JD,可以讓性別信息盡量隔離在w(g)中,也就是讓w(g)表示更多的性別信息?
我們可以在監督學習的背景下考慮這個問題。假設我們有一些(人工標注的)性別定義詞,那么,如果w(g)能夠很好地表示這些性別定義詞的信息,那么表示男性的性別定義詞和表示女性的性別定義詞的差距會很大,從而充分體現性別差異。比方說,“父”的w(g)是2.0,“母”的w(g)是-2.0,相比“父”的w(g)是0.02,“母”的w(g)是0.03,一般來說,前者要更好。由此,我們給出如下的JD定義:
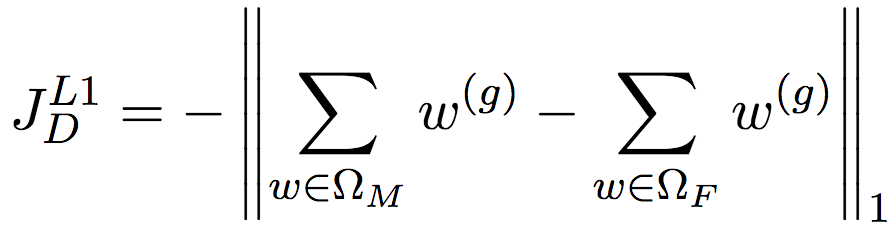
簡單說明一下上面的公式,ΩM和ΩF分別是男性定義詞(male-definition word)和女性定義詞(female-definition word)的集合,論文基于WordNet的定義劃分這兩個集合。考慮的是總體的情況,所以進行了累加。因為論文為性別信息保留了一個維度,所以上面舉例的時候直接使用了實數表示w(g),但實際上性別信息可以占用不止一個維度,因此JD的定義使用了矩陣運算。最后,我們需要最大化男性定義詞和女性定義詞之前的差距,但最終我們需要最小化目標函數值,所以最后進行了取反操作。
當然,JD的定義不止這一種。我們還可以將w(g)的取值限制在一定范圍內,比如[-1, 1],然后盡可能將w(g)往兩端推:(1-w父(g))2+(-1-w母)2. 比如,假設“父”向量的w(g)是1,而“母”向量的w(g)是-1,代入上式,結果為0.
由此我們可以得到JD的第二種定義。當然,同樣,w(g)實際上是向量,所以我們引入一個向量e ∈ ?k,該向量的所有分量為1. 然后我們考慮的也是ΩM和ΩF上的整體情況,所以累加一下。最后,[-1, 1]是一個比較合適的取值范圍,但我們完全可以選擇其他取值范圍。所以我們再引入兩個系數,將取值范圍設定為[β2, β1]. 最終的JD定義為:
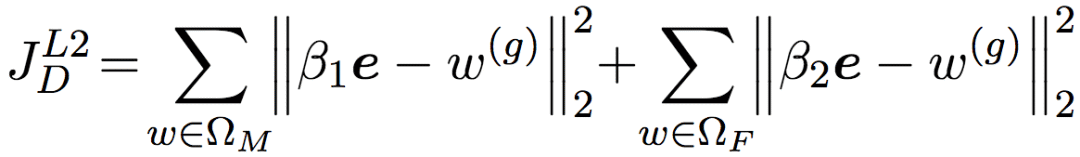
好了,接下來我們討論JE,也就是處理w(a)的部分。
這里,我們引入了vg∈ ?d-k,嵌入空間的性別方向。性別方向的概念很簡單。假設我們有很多對性別詞,比如“father”(父)和“mother”(母)、“man”(男人)和“woman”(女人)、“國王”(king)和“queen”(王后),將這些成對的性別詞向量相減,比如“父 - 母”、“男人 - 女人”、“國王 - 王后”,然后取平均,就得到了性別方向。具體來說,可以使用以下公式表示:
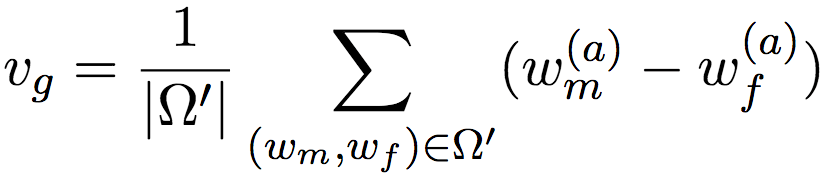
上式中,Ω'是預定義的成對性別詞向量集合。這里我們沒有直接將詞向量w相減,而是將w(a)相減。這是因為,通常情況下,用于保留性別向量的維度很少(論文只使用了一個維度),而一般來說詞向量至少有好幾百維度。而且,在訓練開始階段,w(a)中同樣包含很多性別信息(否則就不需要訓練了)。
然后,類似ΩM和ΩF,我們可以基于WordNet劃分性別中立詞集合ΩN。由于是性別中立詞,所以我們期望它們在性別方向上的投影接近零。這和Bolukbasi等將性別中立詞投影到一個正交于性別維度的子空間的做法類似。
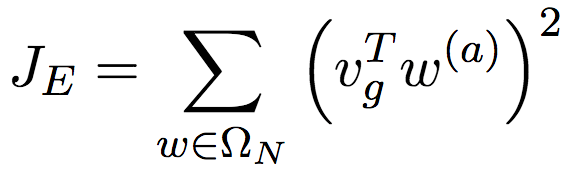
總之,我們用標記過的性別定義詞來優化wg,用標記過的性別中立詞來優化wa,再加上GloVe原本的優化目標,就得到了GN-GloVe的優化目標。
而且,整個目標函數J是可微的,所以論文在訓練時能夠采用隨機梯度下降進行優化。為了簡化訓練詞嵌入的計算復雜度,論文假定性別方向vg是一個固定向量(也就是說,在更新w(a)的時候,不計算在vg上的梯度),只在每個epoch開始的時候更新下vg.
試驗
論文做了全面的試驗,驗證隔離性別信息至特定維度的想法的有效性:
可視化了嵌入空間,表明GN-GloVe分隔開了保護屬性和其他潛屬性。
在新的標注數據集上測量了GN-GloVe區分性別定義詞(gender-definition words)和性別刻板詞(gender-stereotype words)的能力。
評估了GN-GloVe在標準詞嵌入基準數據集上的表現,表明隔離性別信息沒有影響詞嵌入的功能。
演示了GN-GloVe在一個下游應用中降低性別偏差的效果。
設定
對比的基線為原生GloVe和Hard-Glove(即之前提到的Bolukbasi等提出的方法)。
所有嵌入基于2017年的英文維基百科(2017 English Wikipedia dump),GloVe的超參數使用默認值。
訓練GN-GloVe時,論文將每個維度的取值范圍限定于[-1, 1],以避免數值問題。λd和λe均設為0.8. 根據論文作者的初步研究,模型對這些超參數不敏感。另外,除非特別注明,JD使用第一種定義(L1)。
可視化嵌入空間
論文可視化了詞向量的性別分量wg在嵌入空間中的分布(為了便于查看,將橫軸拉伸至[-2, 2])。
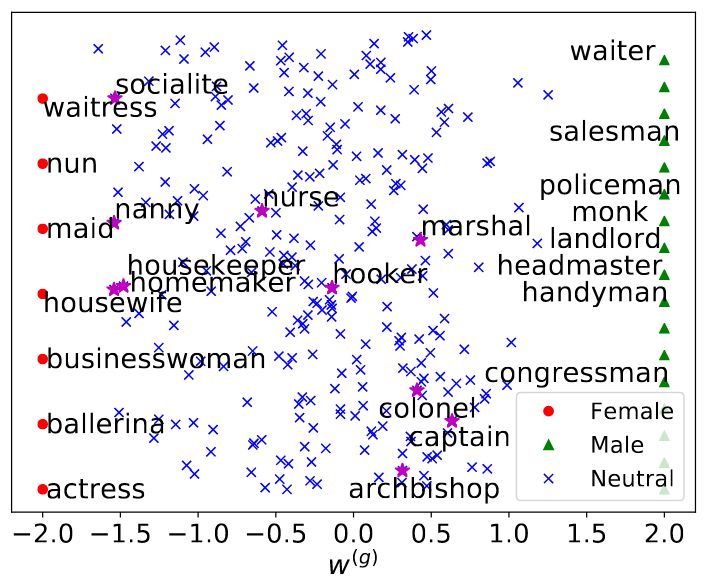
上圖中,紅點為女性定義詞(例如waitress女侍者、nun尼姑、maid女仆、housewife家庭主婦、businesswoman女商人、ballerina芭蕾舞女演員、actress女演員),綠三角為男性定義詞(例如waiter男侍者、salesman男售貨員、policeman男警察、monk和尚、landlord男地主、headmaster男校長、handyman男雜務工、congressman男議員)。圖中的性別定義詞位于橫軸的兩端,這并不出乎我們的意料,畢竟目標函數中w(g)部分的優化正是基于性別定義詞的集合ΩM和ΩF。
藍叉表示性別中立詞。從上圖可以看到,雖然確實存在越靠近0,性別中立詞的性別分量分布就越密集的趨勢,但總體上來說性別中立詞的性別分量分布得比較分散,這說明基于維基百科訓練的性別中立詞仍然包含性別信息。其中,紫五星是一些性別中立的表示職業的詞匯。這些詞匯的可視化表明GN-GloVe能夠恰當地保留性別中立詞中的性別信息。例如,圖中的“nurse”(護士)的性別分量更接近女性,而“captain”(船長)的性別分量更接近男性,和日常的刻板印象一致。
為了驗證GN-GloVe很好地隔離了性別信息,論文可視化了上面這些表示職業的詞匯的中立成分w(a)在性別方向vg上的投影(即w(a)和vg的余弦相似度)。
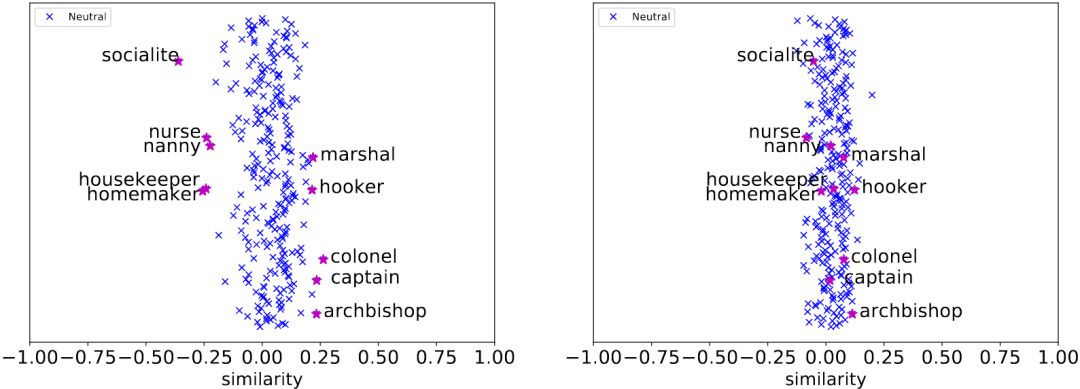
左:GloVe;右:GN-GloVe
可以看到,相比性別刻板印象嚴重的GloVe,GN-GloVe的中立分量在性別方向上的投影接近零,這說明GN-GloVe很好地隔離了性別信息。
論文統計了表示職業的詞匯在性別子空間上的投影平均長度。GloVe是0.080,GN-Glove是0.052. 也就是說,相比GloVe,GN-Glove降低了35%的性別偏差。當然,完全去除性別信息的Hard-GloVe能取得更好的結果,0.019,然而,這也意味著Hard-GloVe損失了性別信息,并且區分性別刻板詞和性別定義詞的能力較差。
SemBias
為了研究模型表示的性別信息的質量,論文按照SemEval 2012 Task2的方式,創建了一個SemBias數據集。這個數據集中的每個樣本包含4對單詞,即一對性別定義詞(例如,waiter - waitress,男侍者 - 女侍者),一對性別刻板詞(例如,doctor - nurse,醫生 - 護士),兩對與性別無關的意思相近的詞(例如,dog - cat,狗 - 貓,cup - lid,杯 - 蓋)。模型需要比較這四對詞中,哪一對和“he - she”(他 - 她)更接近。理想情形下,模型應當選中性別定義詞對。
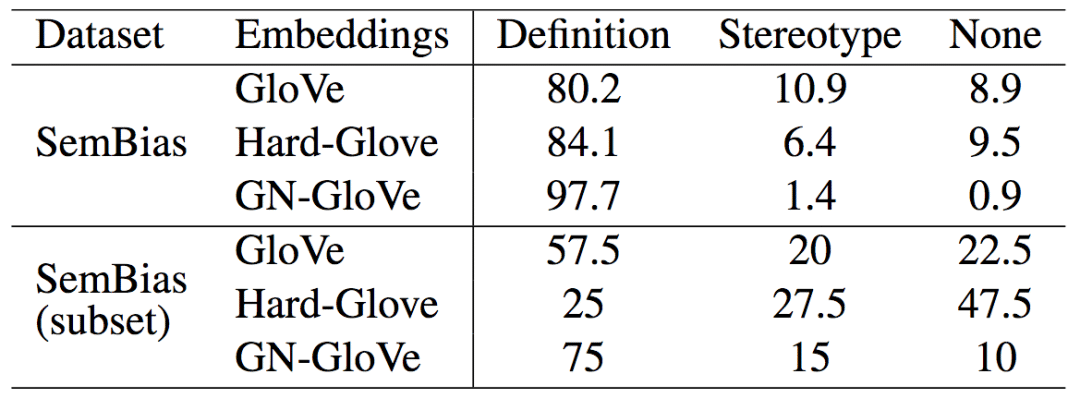
從上表我們看到,GN-Glove在SemBias上達到了97.7%的精確度,顯著高于GloVe和Hard-GloVe的表現。SemBias(subset)是包含未在訓練中作為種子詞匯使用的單詞對的數據子集。在這一子集上,GN-GloVe的表現就更突出了,這表明GN-GloVe可以很好地將基于訓練集學習到的識別能力推廣到其他性別定義詞。相反,移除了所有性別信息的Hard-GloVe的表現就很糟糕了,幾乎是在隨機猜測了。
詞匯相似度和類比
在標準詞嵌入基準數據集上的評估表明,GN-GloVe在相似度任務上達到了更高的精確度,而在類比任務中的評分略有下降。總體而言,GN-GloVe和GloVe、Hard-GloVe表現大致相當,隔離性別信息并未影響詞嵌入的一般功能。

簡單說明一下上面的表格。類比任務回答“A對應B,就像C對應_?”這一問題,也就是在嵌入空間中找到最接近wA- wB+ wC的詞向量w. 相似度任務則評估詞嵌入模型捕捉單詞相似度的能力(對比人類標注)。
指代消解
最后,論文測試了GN-GloVe在下游應用指代消解上的表現。
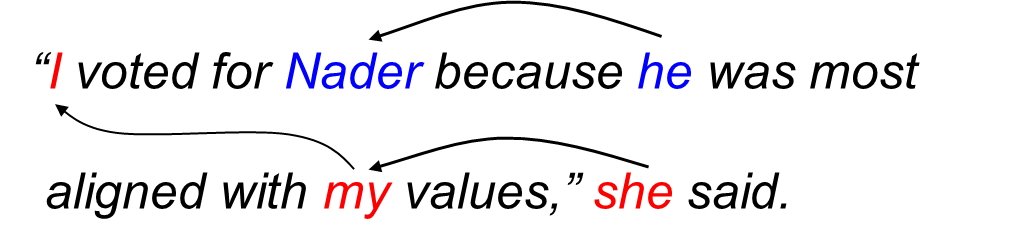
指代消解
論文使用了Ontonotes 5.0和WinoBias這兩個數據集。其中,WinoBias數據集由兩部分構成,PRO子集偏向刻板印象,ANTI子集反刻板印象。例如,PRO子數據集中有一個樣本是“The CEO raised the salary of the receptionist because he is generous.”(CEO給接待員漲了薪水,因為他很慷慨。)在這個句子中,代詞“he”(他)指代“CEO”,和社會的刻板印象一致。而ANTI子數據集包含幾乎一模一樣的樣本,只是性別人稱代詞換成相反的性別,也就是把“he”(他)改成“she”(她)。這和社會的刻板印象相悖,在當前社會,女性CEO在所有CEO中所占的比例遠低于男性。

上表中,Avg表示WinoBias數據集的平均F1值(PRO和ANTI的F1值的平均),Diff表示PRO和ANTI的F1值差異的絕對值(Diff越低,說明系統中的性別偏差越低)。總體上來說,在OntoNotes數據集上,GN-GloVe取得了和GloVe、Hard-GloVe相當的表現。而在WinoBias數據集上,相比GloVe,GN-GloVe顯著降低了性別偏差。在只使用中立成分w(a)的情況下,GN-GloVe的性別偏差水平接近完全去除性別信息的Hard-GloVe.
結語
在本文的結尾,讓我們回顧一下GN-GloVe的優勢:
通用性高,適用于任何語言(只需提供預定義的種子詞匯),可擴展至GloVe以外的嵌入模型和性別以外的保護屬性。
隔離了性別信息,既緩解了在下游應用中加劇刻板印象的問題,又可用于社會科學研究等需要性別信息的場景而無需重新訓練詞嵌入。
隔離性別信息后,改善了詞嵌入的可解釋性。
不依賴分類器區分性別中立詞,避免了分類誤差傳播問題。
-
自然語言處理
+關注
關注
1文章
614瀏覽量
13511
原文標題:GN-Glove 性別中立的詞嵌入學習
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
絕對經典教材.基于ARM嵌入式Linux系統開發技術詳解
鴻蒙構建系統——gn官方FAQ翻譯,以及gn官方文檔分享
鴻蒙構建系統——gn官方FAQ翻譯,以及gn官方文檔分享
嵌入式liunx開發技術詳解

詞對嵌入技術,可以改善現有模型在跨句推理上的表現
PyTorch教程15.5之帶全局向量的詞嵌入(GloVe)






 工商網監
工商網監
評論