 如何完成從Pandas到Scikit-Learn這一令人興奮的工作流
如何完成從Pandas到Scikit-Learn這一令人興奮的工作流
近日,Scikit-Learn 發布了 0.20 版本,這是近年來最大的一次更新。對許多數據科學家來說,一個典型的工作流會在使用 Scikit-Learn 進行機器學習之前,先通過 Pandas 對數據進行分析,而新的版本就將這一過程進行了簡化,并且功能更加多樣、穩定與標準。
今天,我們將通過 Ted Petrou 的一篇技術文章,為大家介紹如何完成從 Pandas 到 Scikit-Learn 這一令人興奮的工作流,并且作者基于 Kaggle 上入門級機器學習競賽之一:Housing Prices: Advanced Regression Techniques 作為案例實踐分析,讓大家可以更好地理解與使用這一工具。
全文概括及目標
通過本文,那些將 Scikit-Learn 作為機器學習庫,但依賴 Pandas 進行數據探索和準備工作的用戶一定可以收益良多。(假設你對 Scikit-Learn 和 Pandas 都有所了解)
我們會探索新的估計器ColumnTransformer,它使得我們可以對數據的不同子集單獨且并行地進行轉換,然后再把結果串接在一起。
用列中的字符串數據來創建供 pandas 使用的數據框,這一過程應該更加標準化。
估計器OneHotEncoder在對列的字符串數據編碼方面有所提升。
為了便于獨熱編碼 (one-hot encoding),我們使用新的估計器SimpleImputer來用常數填充缺失值。
我們會自定義一個估計器,該估計器將取代 Scikit-Learn 的內置工具,來執行對數據框的全部基本轉換操作。
最后,我們會基于新的估計器KBinsDiscretizer對數值進行二進制轉換 。
注:作者是在0.20 版本還沒有正式發布前完成的這個教程,以后這個教程很可能會在某些方面內容有所更新。
前言
Scikit-Learn 的機器學習模型要求輸入必須是二維的數值數據結構。字符串數據是不被接受的。但始終沒有提供一個處理字符串列的標準方法,而字符串數據在數據科學中是一種極為普遍的存在。這也致使相關教程都在探索用不同的方法來處理字符串數據列。
有些解決方案傾向于用 Pandas 的get_dummies函數;一些使用 Scikit-Learn 的獨熱編碼方法LabelBinarizer,但此方法是為類別數據(目標變量)設計的,而非面向輸入數據;還有一些方案則創建了自定義的估計器;甚至還有整個的工具包,如 sklearn-pandas 就是為了解決這個問題創造出來的。對那些想要基于字符串列來建機器學習模型的人來說,標準化方面的欠缺給他們帶來了糟糕的體驗;在轉換特定列而非整個數據集上的技術支持也比較薄弱。例如,將連續特征進行標準化處理十分普遍,而對類別特征來說卻很少見。如今這方面會變得容易得多。
sklearn-pandas:
https://github.com/scikit-learn-contrib/sklearn-pandas
▌升級至 0.20 版
幾天前,0.20 版的第一個候選版本發布了。你可以用 conda 安裝它:

或者 pip 安裝:

▌ColumnTransformer & OneHotEncoder(升級版)簡介
隨著版本更新至 0.20,從 Pandas 到 Scikit-Learn 的工作流應該越來越相似了。估計器 ColumnTransformer 會對 Pandas 數據框(或數組)中列的特定子集執行轉換操作。
OneHotEncoder 并不是一個新的估計器,但它已更新至可以編碼字符串數據列。此前,它只能對包含數值形式的類別數據進行編碼。
接下來讓我們看看,這些新特性將如何處理 Pandas 數據框中的字符串數據列。
初體驗
通過 Kaggle 房屋數據集小試牛刀
Housing Prices: Advanced Regression Techniques 是 Kaggle 的入門級機器學習競賽之一。該競賽目標是基于給定的80個特征,來預測房屋價格。特征列是由連續特征和類別特征混雜成的。你可以從網站直接下載數據或使用他們的命令行工具。
參考鏈接:
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
https://github.com/Kaggle/kaggle-api
▌觀察數據
首先我們來看看數據框,并輸出頭幾行數據。



▌將目標變量從訓練集中移除
我們要移除的目標變量是 SalePrice,然后將其以數組的形式賦值給它本身。我們之后做機器學習時會用到它。

▌單個字符串列的編碼
首先,我們對一個單獨的字符串列HouseStyle進行編碼,該列含有關于房屋外部情況的數據。讓我們輸出一下每個不同字符串的個數。

可見在這一列中,我們有8個不同的值。
▌Scikit-Learn 必須基于 2D 數據
大多數 Scikit-Learn 估計器都要求數據為嚴格的二維形式。如果我們選擇上面提到的所有列作為train['HouseStyle'],技術上來講,一維數據形式的 Pandas Series 就隨之產生了。我們可以通過將列表傳入空白數據框,來強制 Pandas 創建一個單列數據框:

▌轉換器三部曲 —— 導入、實例化、調試
Scikit-Learn 的 API 對于所有估計器都是一致的,即通過固定三個步驟的過程來訓練數據。
根據不同的模塊,引入我們需要的估計器;
對估計器進行實例化,改變其默認配置;
基于數據對估計器進行調試。如果需要,將數據轉換到新的地方。
下面我們引入OneHotEncoder,并將其實例化,確保我們得到的返回數組中不存在缺失值,然后用fit_transform方法對我們的單列數據編碼。

和我們預期的一樣,它把所有不同的值都編碼成為了二進制的列。

▌有了 NumPy 數組,列名是什么呢?
值得注意的一點是,我們輸出的是 NunPy 數組而非 Pandas 數據框。起初 Scikit-Learn 并不是與 Pandas 可以直接整合的。所有的 Pandas 對象都被轉化成了 NumPy 數組,NumPy 數組都是由轉換操作生成的。
通過get_feature_names方法,我們仍可以從OneHotEncoder對象中獲得列名。

▌驗證第一行數據
驗證估計器的運行是否正常是很有必要的。讓我們看一下編碼后的數據的第一行:

這里將數組中的第6個值編碼成了1。我們用布爾值作為索引調出特征名字。

現在,我們來驗證初始數據框的列中第一個值是與之相同的。

▌利用 inverse_transform 自動化該過程
就像大多數轉換器對象一樣,方法inverse_transform方法可以幫你獲取原始數據。這里我們把row0放進列表中,使其變成二維數組。

我們可以通過將整個數組進行反轉,來驗證所有的值。

▌將轉換器作用于測試集
無論我們對測試集使用什么轉換器,我們必須對測試集也使用。讓我們來看看測試集,并獲取同樣的列,對其使用我們的轉換器。

我們又獲得了8個列。

這個例子證明了我們的觀點,但還有幾個我們可能遇到的問題,現在讓我們一一來看都有哪些。
難點
▌1. 測試集中不存在的類別
如果我們現有一座房屋,其特征是測試集中不存在的,這種情況怎么辦呢?比如現有一個特征3Story。現在我們改變房屋特征的第一個值,然后看看會產生什么結果。

根據默認設置,我們的編碼器會生成一個錯誤。這是我們所期待的,因為我們要知曉是否有測試集中不存在的字符串。如果你也存在這個問題,那么你的探索可能需要更加深入了。現在我們通過將參數 handle_unknown 設置為 'ignore' 來忽略這一未知元素,并將這一行都編碼為0。

我們來驗證一下第一行均為0.

▌2 . 測試集中的缺失值
如果你的測試集中存在缺失值(NaN 或 None),只要將 handle_unknown 設置為 'ignore',缺失值就可以被忽略。現在我們為測試集的前兩個元素加入缺失值。

▌3.訓練集中的缺失值
訓練集中存在缺失值是更為嚴重的問題。到目前為止,估計器OneHotEncoder還無法很好地解決缺失值問題。

如果像測試集一樣,也有一個方法可以忽略訓練集中的缺失值就好了。目前這種方法并不存在,我們只能對缺失值進行填充。
現在,我們必須對這些缺失值加以填充。預處理模塊中老的Imputer已經被棄用了。在同樣的位置創建了一個新模塊impute,配合新的估計器SimpleImputer和新方案“常數”。若采用默認設置,這一方案會用字符串 'missing_value' 來填充缺失值。我們可以通過參數 fill_value 來設置這個值。

到了這里,我就可以像之前那樣進行編碼了。

要注意的一點是,現在我們有額外的一個列和特證名。

技能升級
實踐整個轉換工作
▌對測試集執行兩次轉換
我們可以手動依次執行上述兩個步驟,如下:

▌Pipeline 的使用
Scikit-Learn 提供了 Pipeline 估計器,它包括一系列轉換操作,可以將它們一一執行。你可以把機器學習模型作為最終的估計器來運行。現在我們對缺失值進行簡單的填充并編碼。

每個步驟都是一個二元組,包括一個代表該步驟的字符串和實例化的估計器。上個步驟的輸出是下個步驟的輸入。

只要將測試集傳入 transform 方法,它就可以基于 pipeline 的每一個步驟進行轉換。

▌多字符串列的轉換
對含有多個字符串的列進行轉換并不是難題。選中你要處理的列,然后基于同一個 pipeline 再傳入新的數據框。

▌獲取 pipeline 的片段
我們可以通過從屬性字典獲取名字,來獲取 pipeline 內每個單獨的轉換器。在這個例子中,我們獲取了一個獨熱編碼器,然后輸出特征名字。

▌使用新的 ColumnTransformer 選擇列
全新的ColumnTransformer允許我們為不同的列選擇不同的轉換器。類別數據列比連續數據列往往更需要進行單獨轉換。
ColumnTransformer目前還處于試驗階段,也就說未來可能有所變化。
ColumnTransformer包括一個三元組列表。元組的第一個值是特征名,第二個是實例化的估計器,第三個是一系列你想要執行轉換操作的列。該元組的形式如下:

此處的 columns 不一定非要是列名,你也可以用列的整數索引值來代替,或者一個布爾數組,甚至可以用一個函數(該函數要將整個數據框作為參數,并返回所選的列)。
你也可以選擇 NumPy 數組與ColumnTransformer配合使用,但本教程著重于和 Pandas 的整合,所以我們仍采用數據框進行討論。
▌將 Pipeline 傳入 ColumnTransformer
我們甚至可以將一個含有多個轉換器的 pipeline 傳入列的轉換器,下面我們就要這么做,因為我們的字符串列需要多個轉換器。
接下來,我們重復上面的缺失值填充步驟,并用ColumnTransformer進行編碼。要注意的是 pipeline 和上面是相同的,只是每個變量名后加了個cat。在下個部分中,我們會為數值列添加一個不同的 pipeline。

▌將整個數據框傳入 ColumnTransformer
ColumnTransformer實例選擇了我們要使用的列,所以我們將整個數據框傳入fit_transform方法。

現在我們可以通過同樣的方式將測試集進行轉換。

▌獲取特征名
我們必須花時間要做的一個事情就是去獲取特征的名字。所有轉換器都存儲在屬性字典 named_transformers_ 中。接下來,我們可以通過名字以及三元組的第一個元素來選取特定的轉換器。下面就是我們選擇轉換器的過程(此處只有一個轉換器,即一個名為 'cat' 的 pipeline)。

接下來,我們從 pipeline 選取獨熱編碼器對象,并獲得特征名。

▌數值列的轉換
數值列需要一組不同的轉換器。數值列中的缺失值通常由中位值或平均值來填充,而非一個常數。而且我們常通過減去每列平均值或除以標準差的方式對其進行標準化,而不是對它們的值直接編碼。這種方法有助于許多模型得到更好的效果,如嶺回歸模型。
▌調用所有數值列
我們可以選擇所有的數值列,而非像上面那樣手動選擇一兩個字符串列。我們通過根據dtypes屬性直接搜尋每一列的數據類型來實現這一目的,然后檢查每個dtype的kind(類型)是否為 'O'。dtypes屬性會返回一系列 Numpydtype對象。其中每一個都包含kind屬性,這些屬性都由一個字符表示。我們可以基于此去搜尋數值或字符串列。Pandas 將所有的字符串列作為object(對象)進行儲存,等同于 'O' 的類型。關于kind這個屬性的更多介紹可以參考 NumPy 文檔。
NumPy 文檔:
https://docs.scipy.org/doc/numpy/reference/generated/numpy.dtype.kind.html

得到了類別,然后用一個字符來表示這些數據類型。

現假設所有數值列都不是對象。我們也可以通過這種方式來獲取特征列。

一旦我們獲得了數值列的名字,我們就可以再次使用ColumnTransformer了。

▌將特征列和數值列的轉換器相結合
基于ColumnTransformer,我們可以分別對數據框的每個部分進行單獨轉換。在這個例子中我們會使用每個單獨列。
接下來我們為特征列和數值列共同創建一個單獨的 pipeline,然后用ColumnTransformer來對它們進行單獨轉換。這兩個轉換器是并行工作的,然后再把兩個結果整合在一起。
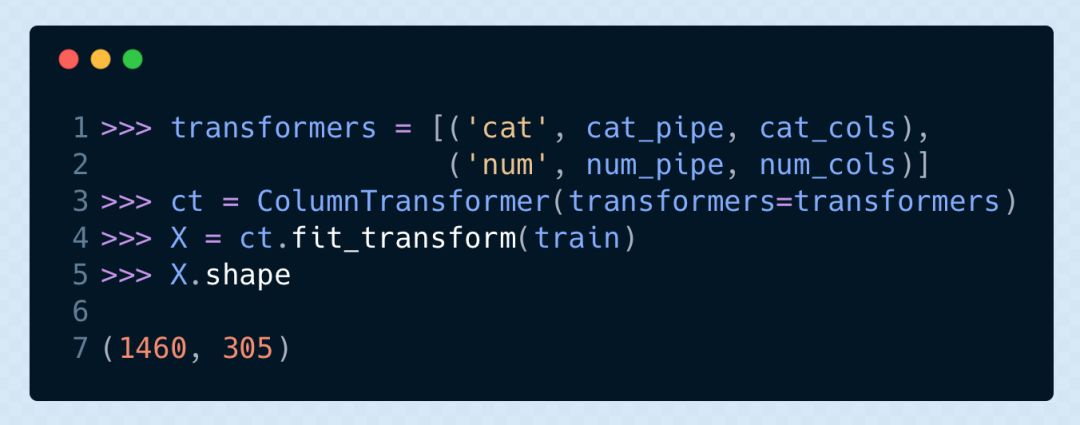
進行機器學習
這些工作的全部意義在于布置我們的數據,以便于我們接下來的機器學習環節。我們可以創建最終版 pipeline,并添加一個機器學習模型作為最后的估計器。pipeline 的第一步是我們上面提到的整個轉換環節。我們將房屋的出售價格SalePrice設為y。這里我們用fit方法來代替 fit_transform,因為最后一個環節是機器學習模型,不需要轉換操作。

我們可以用 score 方法來評估模型,返回的值為 R-square(確定系數):

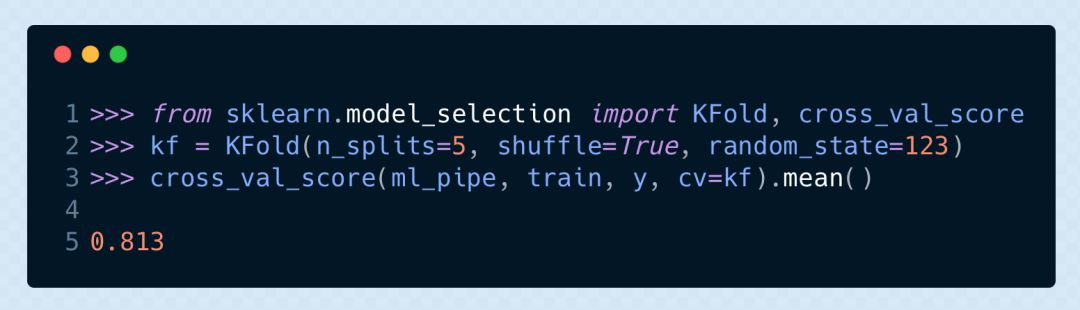
模型的表現:交叉驗證
當然了,用訓練集本身來驗證模型是毫無意義的。讓我們做一下 K 折交叉驗證,來看看模型對于未見過的數據有什么表現。我們設置一個隨機數,以確保在整個過程中都能按固定的隨機序列對原數據進行劃分。
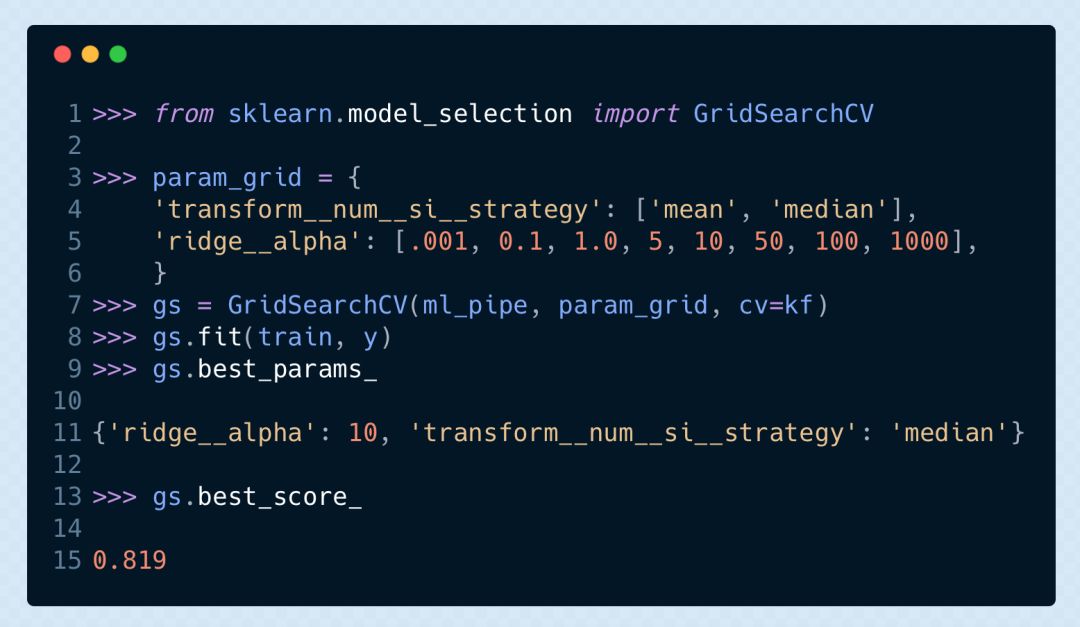
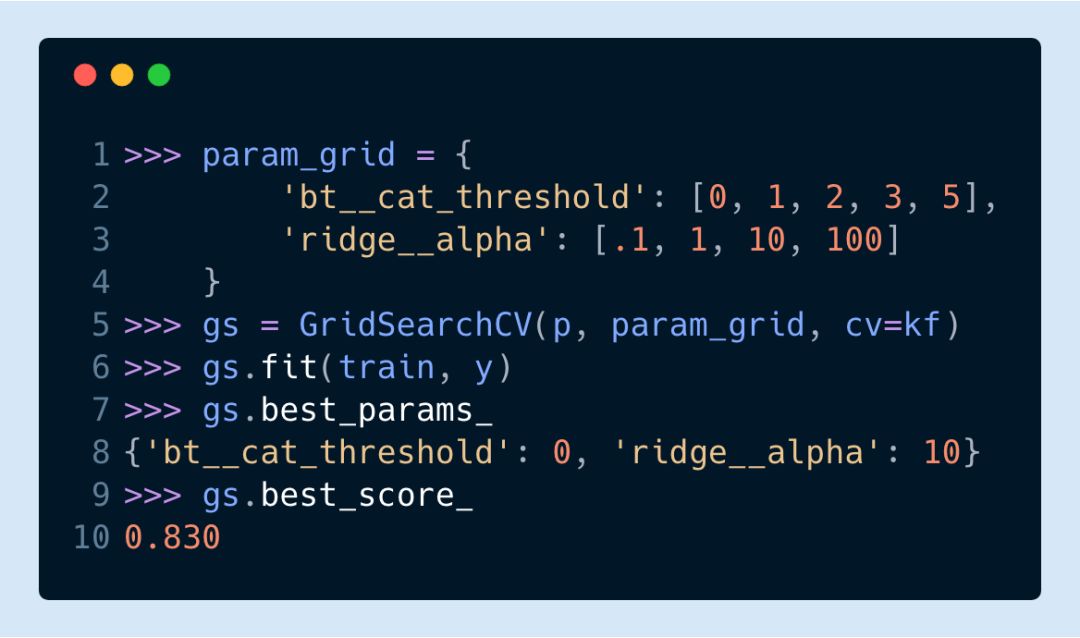
網格搜索的參數選擇
Scikit-Learn 的網格搜索需要我們傳入參數名字典,與可能的數值相映射。當我們使用 pipeline 時,必須在每一步的名字后加兩個下劃線,然后再接參數名。如果你的 pipeline 有多個層,我們必須再繼續加兩個下劃線來再提升一個層,直到我們能獲取需要優化其參數的估計器。
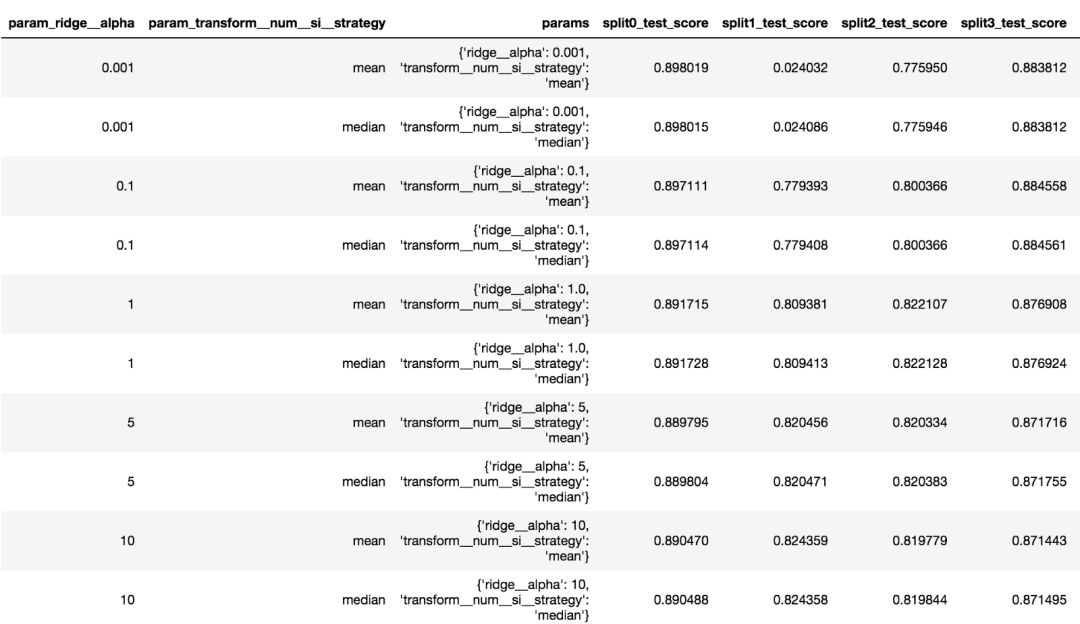
▌在 Pandas 數據框中獲得網格搜索的全部結果
網格搜索的全部結果被存儲在cv_results_中。為了便于展示,這是一個可以轉換為 Pandas 數據框的字典,而且它提供了更加便于手動掃描的結構。

一個完整 WorkFlow 還需要解決的問題
▌創建含有全部基礎操作的自定義轉換器
上述討論的工作流還存在一些限制。例如,在我們使用fit方法時,若OneHotEncoder可以提供忽略缺失值的選項就好了。比如,它可以將缺失值編碼為一行0。現在它強制我們用字符串來填充缺失值,并將這些字符串編碼成一個單獨的列。
▌自定義估計器類
Scikit_Learn 的文檔提供了許多關于如何寫估計器類方面的指導。base 模塊中的BaseEstimator類為我們提供了get_params和set_params方法。做網格搜索時,set_params方法是必需的。你可以自己寫,或從 BaseEstimator 直接繼承。
Scikit_Learn 文檔:
http://scikit-learn.org/stable/developers/contributing.html#rolling-your-own-estimator
BasicTransformer 類可以執行下面一系列操作:
用平均值或中位值對數值列的缺失值進行填充
將全部數值列做標準化處理
對字符串列采取獨熱編碼
不對特征列的缺失值加以填充,而是將它們編碼為0
忽略測試集字符串列中不存在的值
允許我們為字符串列中一個值必須出現的次數設置閾值。該閾值以下的字符串都被編碼為0
大多數操作都是基本的轉換,對許多數據集來說是必須執行的。
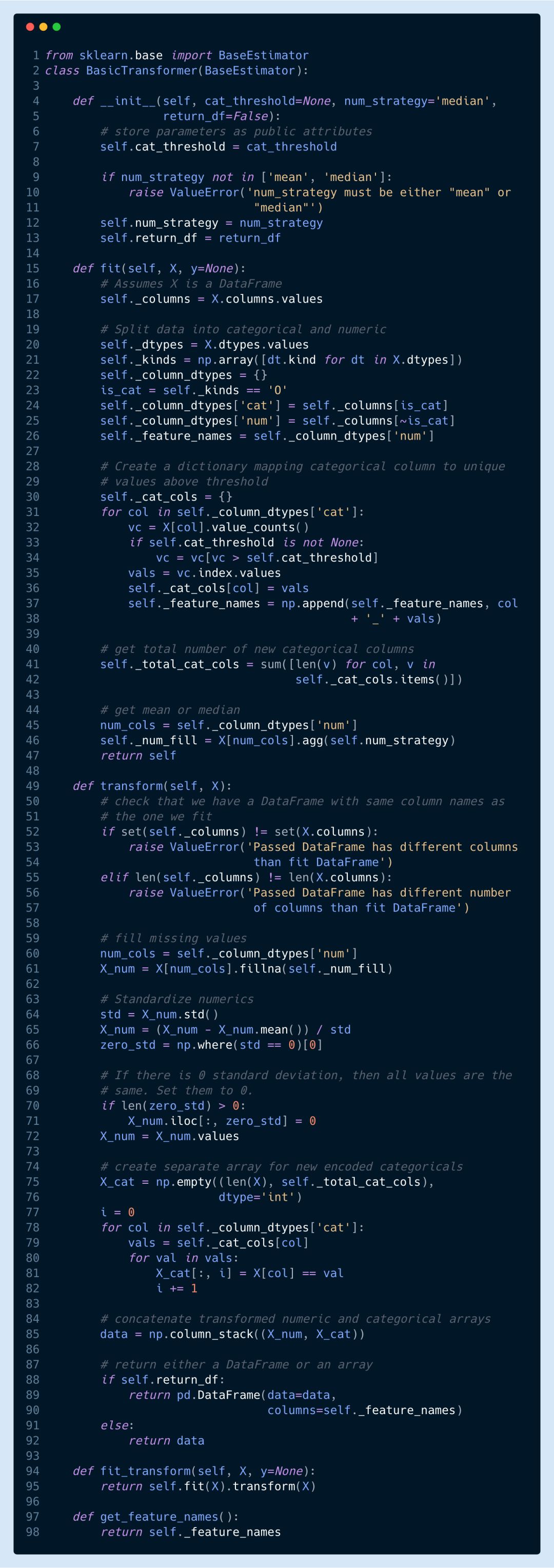
▌BasicTransformer 的使用
BasicTransformer估計器的使用和其它的 scikit-learn 估計器一樣。我們可以將其實例化,然后轉換數據。


▌在 pipeline 中使用自定義轉換器
我們可以將自定義的轉換器設置為 pipeline 的一部分。

我們也可以用它做交叉驗證,所得分數與之前的分數很相近。
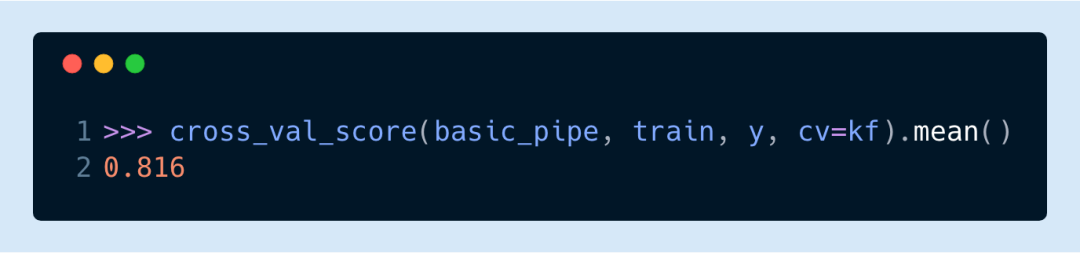
我們可以把它用作網格搜索的一部分。這證明了去掉低頻率字符串對該模型幫助不大,即使對其它模型有明顯的提升。最佳分數有所提升,可能是因為使用了不同的編碼方式。
▌基于新的 KBinsDiscretizer 對數值列作二進制轉換并編碼
存在多個列都含有關于年份的信息,所以比起把它們當作特征列,將這些列的值進行二進制轉換更為合理。Scikit-Learn 開發了新的估計器KBinsDiscretizer來執行這一操作。它不僅將這些值轉換為二進制碼,還會對其進行編碼。在此之前,你可以通過 Pandas 的cut和qcut函數手動完成這個過程。
讓我們看看它是如何工作的,以YearBuilt列為例。
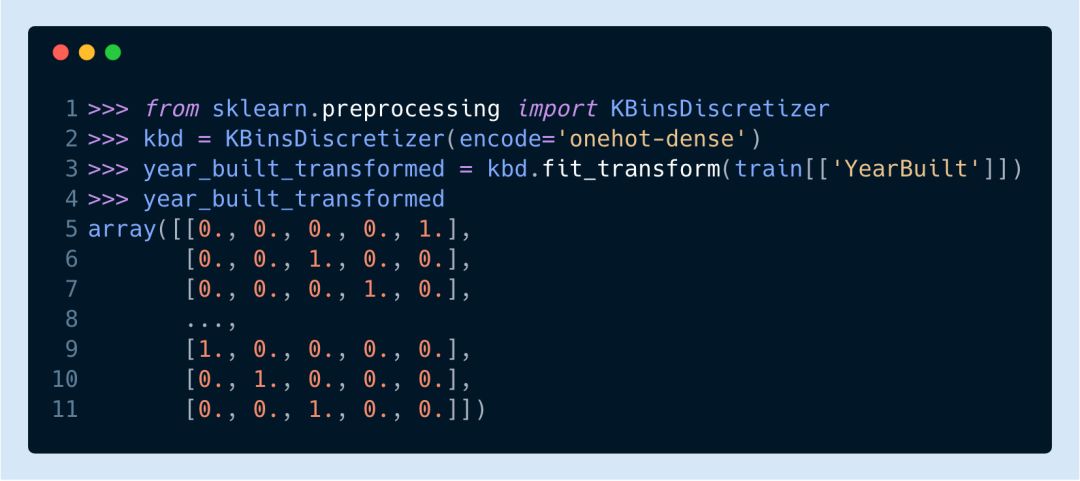
每個二進制結果包含的位數相等,我們將每一列相加來驗證這一點。

▌用 ColumnTransformer 分別處理所有年份列
我們可以采用ColumnTransformer對列的其它子集進行單獨處理。下面一段代碼是我們之前轉換操作的后續步驟。我們也可以去掉Id這一列,它的作用只是用來標記每一行。
接下來進行交叉驗證,計算得分,然后我們發現這一系列操作并沒有使結果提升。
改變每一列的二進制串數目也許會優化我們的結果。但無論如何,KBinsDiscretizer還是使二進制化數值變量這一過程變得更加容易了。
Scikit-Learn 0.20 更多的有點
關于新版本還有許多本文未提到的新特性。查看文檔中的 What’s New 部分可以得到更多信息。
What’s New:
http://scikit-learn.org/dev/whats_new.html#version-0-20-0
總結
本文介紹了一種新型工作流,它有助于那些依賴于 Pandas 做數據分析與準備工作的 Scikit-Learn 用戶。
這是一個更加流暢且多功能的過程,包括納入 Pandas 數據框,并將其進行轉換,以便于后續的機器學習,這一系列操作都由全新且優化的估計器ColumnTransformer、SimpleImpute,、OneHotEncoder和KBinsDiscretizer來完成。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132407 -
數據科學
+關注
關注
0文章
165瀏覽量
10045
原文標題:Scikit-Learn大變化:合并Pandas
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Python機器學習庫談Scikit-learn技術
在PyODPS DataFrame自定義函數中使用pandas、scipy和scikit-learn
6個令人興奮的醫療保健物聯網案例
6個令人興奮的醫療保健物聯網案例
高級駕駛輔助系統是一個令人興奮的市場空間
如何在移動和嵌入式設備上部署機器學習模型
基于Python的scikit-learn編程實例
詳細解析scikit-learn進行文本分類

用英特爾DAAL性能庫加速SCIKIT學習
高性能Python代碼工具的介紹
scikit-learn K近鄰法類庫使用的經驗總結
RAPIDS cuML中的輸入輸出可配置性






 工商網監
工商網監
評論