") FPGA高速接口PCIe詳解
FPGA高速接口PCIe詳解
在高速互連領域中,使用高速差分總線替代并行總線是大勢所趨。與單端并行信號(PCI總線)相比,高速差分信號(PCIe總線)可以使用更高的時鐘頻率,從而使用更少的信號線,完成之前需要許多單端并行數(shù)據(jù)信號才能達到的總線帶寬。
PCIe協(xié)議基礎知識
PCI總線使用并行總線結(jié)構(gòu),在同一條總線上的所有外部設備共享總線帶寬,而PCIe總線使用了高速差分總線,并采用端到端的連接方式,因此在每一條PCIe鏈路中只能連接兩個設備。這使得PCIe與PCI總線采用的拓撲結(jié)構(gòu)有所不同。PCIe總線除了在連接方式上與PCI總線不同之外,還使用了一些在網(wǎng)絡通信中使用的技術,如支持多種數(shù)據(jù)路由方式,基于多通路的數(shù)據(jù)傳遞方式,和基于報文的數(shù)據(jù)傳送方式,并充分考慮了在數(shù)據(jù)傳送中出現(xiàn)服務質(zhì)量QoS (Quality of Service)問題。
與PCI總線不同,PCIe總線使用端到端的連接方式,在一條PCIe鏈路的兩端只能各連接一個設備,這兩個設備互為是數(shù)據(jù)發(fā)送端和數(shù)據(jù)接收端。PCIe鏈路可以由多條Lane組成,目前PCIe鏈路×1、×2、×4、×8、×16和×32寬度的PCIe鏈路,還有幾乎不使用的×12鏈路。
在PCIe總線中,使用GT(Gigatransfer)計算PCIe鏈路的峰值帶寬。GT是在PCIe鏈路上傳遞的峰值帶寬,其計算公式為 總線頻率×數(shù)據(jù)位寬×2。
按照常理新一代的帶寬要比上一代翻倍,PCIe3.0的原始數(shù)據(jù)傳輸帶寬應該是10GT/s才對而實際卻只有8.0GT/s。我們知道,在1.0,2.0標準中,采用的是8b/10b的編碼方式,也就是說,每傳輸8比特有效數(shù)據(jù),要附帶兩比特的校驗位,實際要傳輸10比特數(shù)據(jù)。因此,有效帶寬=原始數(shù)據(jù)傳輸帶寬*80%。而3.0標準中,使用了更為有效的128b/130b編碼方案從而避免20%帶寬損失,3.0的浪費帶寬僅為1.538%,基本可以忽略不計,因此8GT/s的信號不再僅僅是一個理論數(shù)值,它將是一個實在的傳輸值。
PCIe總線采用了串行連接方式,并使用數(shù)據(jù)包(Packet)進行數(shù)據(jù)傳輸,采用這種結(jié)構(gòu)有效去除了在PCI總線中存在的一些邊帶信號,如INTx和PME#等信號。在PCIe總線中,數(shù)據(jù)報文在接收和發(fā)送過程中,需要通過多個層次,包括事務層、數(shù)據(jù)鏈路層和物理層。PCIe總線的層次結(jié)構(gòu)如下。
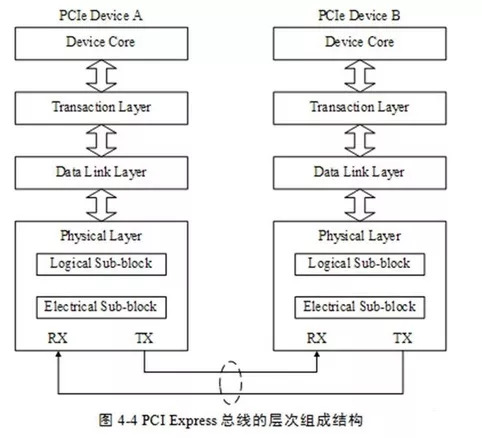
PCIe總線的層次組成結(jié)構(gòu)與網(wǎng)絡中的層次結(jié)構(gòu)有類似之處,但是PCIe總線的各個層次都是使用硬件邏輯實現(xiàn)的。在PCIe體系結(jié)構(gòu)中,數(shù)據(jù)報文首先在設備的核心層(Device Core)中產(chǎn)生,然后再經(jīng)過該設備的事務層(TransactionLayer)、數(shù)據(jù)鏈路層(Data Link Layer)和物理層(Physical Layer),最終發(fā)送出去。而接收端的數(shù)據(jù)也需要通過物理層、數(shù)據(jù)鏈路和事務層,并最終到達Device Core。
事務層(Transaction Layer)
在PCIe總線層次結(jié)構(gòu)中,事務層最易理解,同時也與系統(tǒng)軟件直接相關。
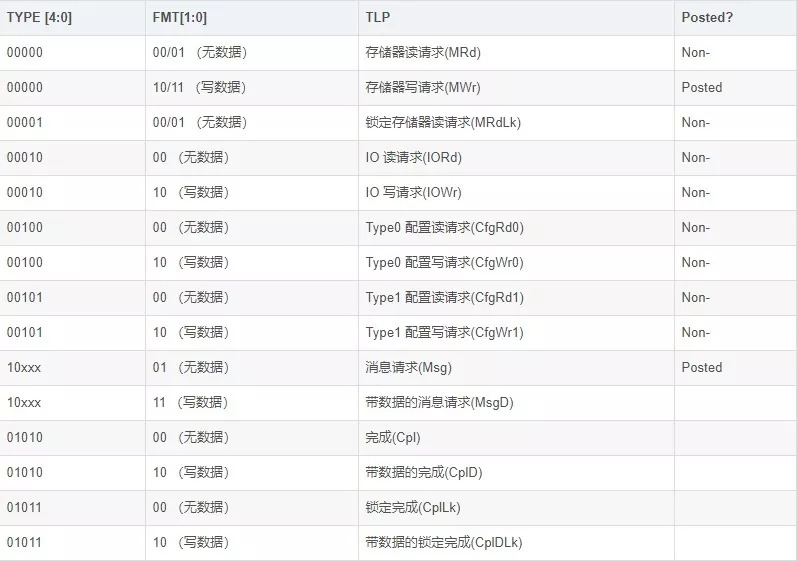
TLP由幀頭、數(shù)據(jù)、摘要組成,7系列FPGA 開始,使用標準的 AXI4 總線協(xié)議進行通信,因此 PCIe的TLP采用AXI4-S接口協(xié)議進行傳輸,數(shù)據(jù)的傳輸以大端方式對齊(高位放在低地址)。
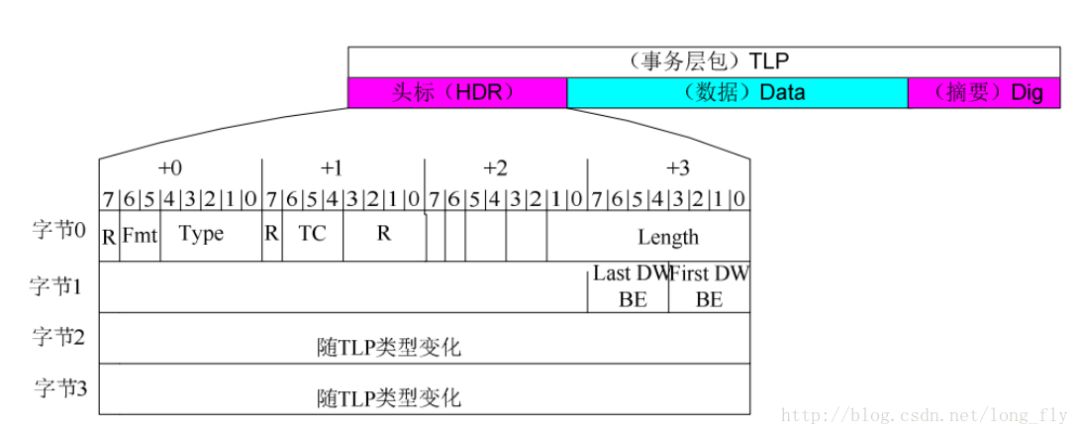
頭標:長度為3或4個DW(double word),格 式和內(nèi)容隨事務類型變化數(shù)據(jù): 若該 TLP 不攜帶數(shù)據(jù),那該段為空摘要:是基于頭標、數(shù)據(jù)而計算出來的CRC, 稱為 ECRC,一般該段由 IP核填充,所 以用戶只需處理TLP中頭標和數(shù)據(jù)段
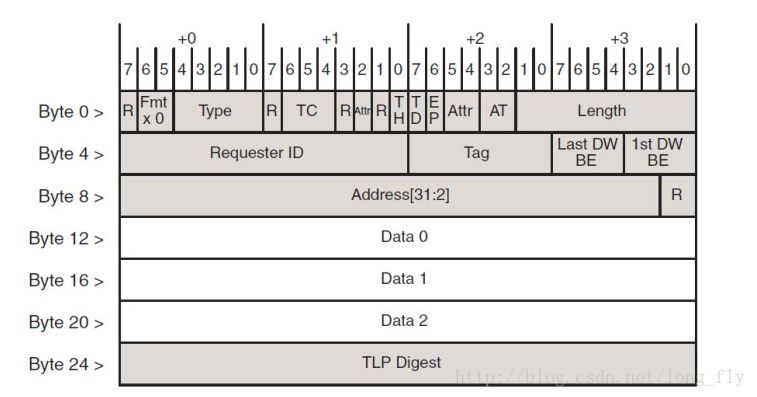

Fmt[1:0]段是關于頭標長度和該 TLP 是否有數(shù)據(jù)在的信息:
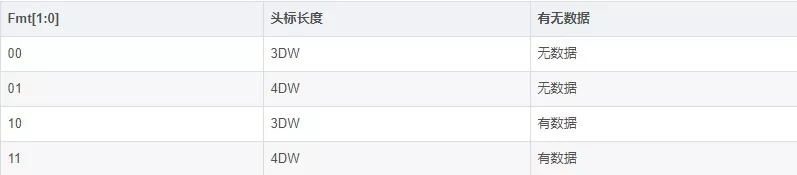
Type與 Fmt字段:一起用于規(guī)定事務類型、頭標長度和是否有數(shù)據(jù)載荷
Non-Posted命令:若設備發(fā)出一個Non-Posted請求,一段時間后,接收端需回復一個完成包,若不回復則可能遇到異常
Posted命令:不需要回復完成包給發(fā)送端
例如:發(fā)送的數(shù)據(jù)為0x4a00_0001_01a0_0004,0x01a0_0a10_0403_0201則:Fmt是2’b10,Type 是5’b01010,判斷為 3DW 帶數(shù)據(jù)的完成包,0x4a00_0001_01a0_0004_01a0_0a10是頭標,0x0403_0201是所帶的數(shù)據(jù)。
Length字段:在讀存儲器請求報文中,表示需要從目標設備數(shù)據(jù)區(qū)域讀取的數(shù)據(jù)長度;在寫存儲器請求報文中,表示當前報文的DataPayload長度,長度單位為DW。
last/1st DW BE字段:PCIe總線以字節(jié)為基本單位進行數(shù)據(jù)傳遞,但是Length字段以DW為最小單位,該字段用于規(guī)定第一個和最后一個的有效字節(jié)的位置。
Requester ID:該TLP包的產(chǎn)生設備,的總線號(Bus Number)、設備號(Device Number)、功能號(Function Number)等
Tag:Requester ID、Tag合起來組成Transaction ID,在同一時間段內(nèi),PCIe設備發(fā)出的每一個Non-Posted數(shù)據(jù)請求TLP,其Transaction ID必須唯一,即Tag必須唯一
讀寫TLP包的格式:
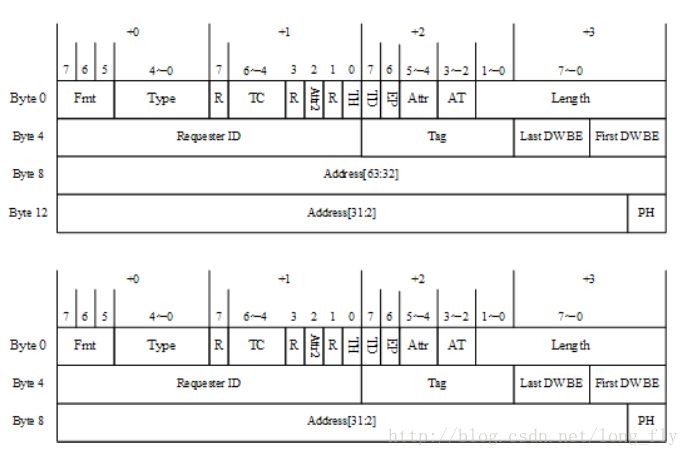
上圖中的兩個格式,前者是針對64位地址的讀寫包,后者則是針對32位地址的讀寫包
完成包的格式:
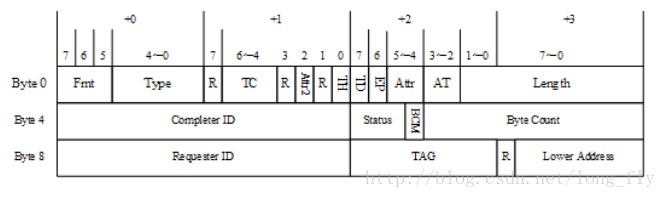
Completer ID:該完成包的產(chǎn)生設備的ID號Byte Count:記錄源設備還需要從目標設備中獲得多少字節(jié)的數(shù)據(jù)才能完成全部數(shù)據(jù)傳遞Lower Address:接收端必須使用存儲器讀寫完成TLP的Low Address 字段,識別該TLP中包含有效數(shù)據(jù)的起始地址
事務層空間
PCI配置空間:主要用于向系統(tǒng)提供設備自身的基本信息,并接受系統(tǒng)對設備全局狀態(tài)的控制和查詢(設備只有在系統(tǒng)軟件初始化配置空間之后,才能夠被其他主設備訪問,當配置空間被初值化后,該設備在當前的PCI總線樹上將擁有一個獨立的BAR空間)
I/O空間:主要包括設備的控制狀態(tài)寄存器,一般用于控制查詢設備的工作狀態(tài)及少量數(shù)據(jù)交換存儲器空間:一般用于大量數(shù)據(jù)的交換(內(nèi)存、顯存、擴展ROM、設備緩沖區(qū)等)
消息空間: 傳遞消息的空間
PCIe通訊是靠發(fā)送TLP包,讀寫包里都會有地址信息,若FPGA向PC發(fā)送TLP 包,例如 MWr 包,那么地址信息就是PC的物理地址;若發(fā)送的是 MRd 包,那PC收到后會回復一個完成包,F(xiàn)PGA從完成包提取出數(shù)據(jù)即可
PC 如何讀寫板卡的數(shù)據(jù):
PC啟動時,BIOS探測PCIe設備有多少個BAR空間,每個空間有多大,然后對應為這些空間分配地址
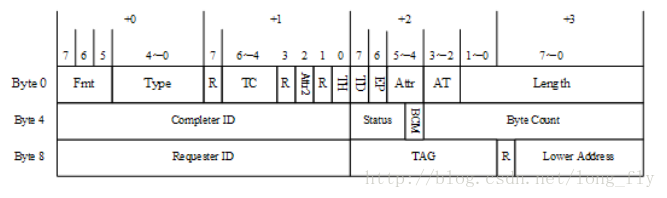
以上圖為例,BAR2的空間大小為0x1000,PC上的起始地址為0xFDEFF000,若想通過PC訪問BAR2的0x40地址,則在PC上直接訪問0xFDEFF040即可,起始地址在不同的PC上是不一樣的(但是偏移地址是相同的),在 FPGA 中,BAR 空間的設置,是根據(jù)用戶需求在IP核里定義大小的
發(fā)送中斷
PCIe可以發(fā)出兩種中斷:虛擬INTx信號線(PCI的信號)和MSI(消息)
虛擬INTx信號線:
發(fā)送的數(shù)據(jù)為:0x3400_0000_0100_0020, 0x0000_0000_0000_0000則:Fmt為2’b01,Type 為5’b10100,判斷為消息請求包,Message Code 為0x20(8’b0010_0000),判斷為中斷(INTx)消息
發(fā)送的數(shù)據(jù)為:0x3400_0000_0100_0024, 0x0000_0000_0000_0000時,則:Fmt 為2’b01,Type 為5’b10100,判斷為消息請求包,Message Code 為0x24(8’b0010_0100),判斷為中斷(INTx)撤銷消息
這個之后有需要的話,可以做實驗測試,現(xiàn)階段就先只找到這兩個信號線(如圖直接搜索int_(x))
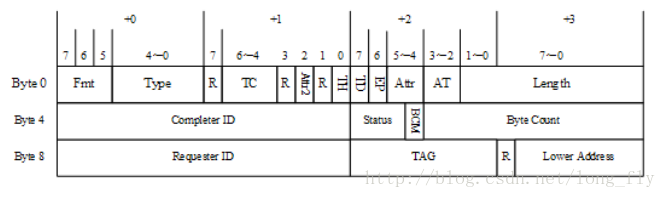
MSI中斷:
是基于消息機制的,PC啟動后會為 PCIe 板卡分配消息地址,板卡發(fā)送中斷的話,只需向?qū)牡刂钒l(fā)送消息即可(消息內(nèi)容中包含消息號,每個消息號對應在PC 端的某一地址)注:在Xilinx平臺上,中斷和其他包是分開的,中斷發(fā)送是非常簡單的,只需要簡單操作幾條信號線,PCIe 核就可以自己組織需要的中斷包向外發(fā)送
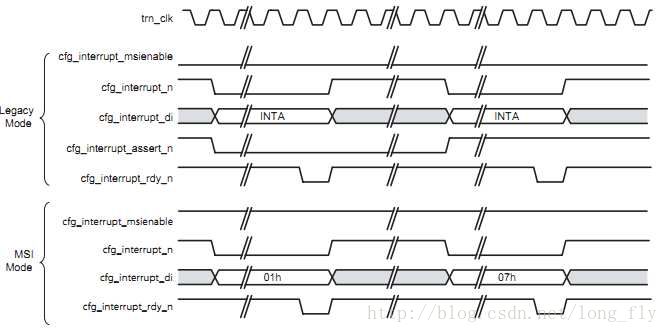
PCIe的IP核
使用環(huán)境:VIVADO 2017.4IP核版本:7 Series FPGAs Integrated Block for PCI Express v3.3官方文檔:pg054
IP核概覽圖:
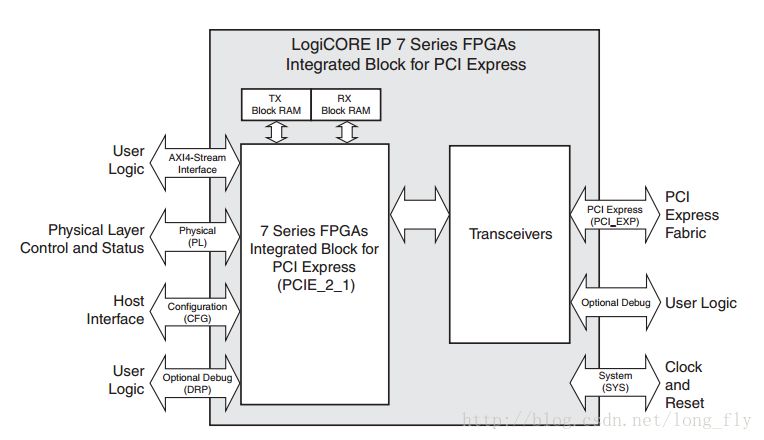
IP核接口定義:System Interface:
PCI Express Interface:
上圖為4X模式下的,外部引腳的接口,共4組,每組都有收發(fā)信號,且收發(fā)信號線均為差分線
Configuration Interface:
這類信號名稱一般以cfg_開頭,主要用于檢測PCIE終端的configuration space狀態(tài),詳情見手冊,此類信號在IP核上有很多很多,比如:
其中的中斷接口信號一般以cfg_interrupt開頭其中的異常報告信號一般以cfg_err_開頭
Physical Layer Interface:此類信號一般以pl_開頭,詳情見手冊,用于控制和檢測PCIE物理層,可以改變速度、位寬等,一般不使用
Dynamic Reconfiguration Port Interface:DRP接口,此類信號一般以pcie_drp_開頭,詳情見手冊,用于動態(tài)配置PCIE核的寄存器,用于調(diào)試
Debug Interface:user_和fc_開頭的信號,輸出系統(tǒng)工作狀態(tài),用于調(diào)試
AXI4-S Interface:以m_axis_rx_、s_axis_tx_、tx_、rx_開頭,用于傳輸數(shù)據(jù),詳情見手冊
DMA傳輸模式XAPP1052官方例程解析
xapp1052是xilinx官方給出的一個有關DMA數(shù)據(jù)傳輸?shù)臉永糜赑C端和FPGA端之間的DMA數(shù)據(jù)傳輸,雖然xapp1052并不是一個完整的DMA數(shù)據(jù)傳輸?shù)慕K端硬件設計,但是還是有很大參考價值的文件層次:
主要包括PCIe硬核和應用邏輯,硬核由軟件生成,應用邏輯主要包括發(fā)送引擎、接收引擎和存儲器訪問模塊RX_ENGINE:用于解析IP核的數(shù)據(jù)包,負責DMA讀接收數(shù)據(jù)包TX_ENGINE:負責DMA寫發(fā)送數(shù)據(jù)包和中斷控制BMD_EP_MEM_ACCESS:存儲訪問模塊,包含DMA狀態(tài)及控制寄存器用以控制DMA讀寫,這里的寄存器是以PIO的方式寫入配置,在RC中設置的TLP長度、TLP數(shù)量信息等會寫入到這些寄存器中BMD_GEN2、BMD_RD_THROTTLE、BMD_TO_CTRL、BMD_CFG_CTRL:BMD的一些相關的配置和控制信號的處理模塊axi_trn_top:負責axi協(xié)議和trn協(xié)議的相互轉(zhuǎn)換
DMA寫流程:一次DMA寫的過程是由FPGA的數(shù)據(jù)寫入RC端的存儲器中的過程,具體步驟為:0>在RC端申請一塊物理地址連續(xù)的內(nèi)存,EP端準備好寫數(shù)據(jù)后向RC端發(fā)送中斷1>在RC端分析中斷,并向BAR0空間設置本次DMA寫的TLP大小、TLP數(shù)量、寫地址等,(通過PIO的方式,將帶有上述信息的TLP包發(fā)送給EP端,寫入FPGA的DMA控制狀態(tài)寄存器中),并且啟動DMA2>根據(jù)DMA狀態(tài)控制寄存器的內(nèi)容,在收到DMA寫啟動命令后,TX引擎開始從FPGA中讀取數(shù)據(jù)并按第一步設置的DMA大小數(shù)量來組裝TLP包然后發(fā)送到PCIe核3>FPGA發(fā)送完數(shù)據(jù)后通過中斷等形式通知主機DMA完成,主機讀取 BAR0 空間狀態(tài)寄存器判斷中斷類型做出相應判斷,同時主機從內(nèi)存讀出數(shù)據(jù)
狀態(tài)機:BMD_64_TX_RST_STATE:初始的復位狀態(tài),在該狀態(tài)判斷該進入發(fā)送完成包、存儲器寫和存儲器讀的其中一個狀態(tài)
發(fā)送完成包:BMD_64_TX_CPLD_QW1:發(fā)送完成包 — 返回存儲器地址和指定數(shù)據(jù)BMD_64_TX_CPLD_WIT:發(fā)送完成包 — 等待完成存儲器寫:BMD_64_TX_MWR_QW1:DMA存儲器寫請求(32bit地址),發(fā)送3DW長度的頭+1DW數(shù)據(jù)BMD_64_TX_MWR64_QW1:DMA存儲器寫請求(64bit地址),發(fā)送4DW長度的頭BMD_64_TX_MWR_QWN:發(fā)送剩余的數(shù)據(jù)到RC端存儲器讀:BMD_64_TX_MRD_QW1:DMA存儲器讀請求(然后在RX引擎接收相應數(shù)據(jù))
DMA讀流程:一次DMA讀的過程是將RC端存儲空間的數(shù)據(jù)讀入到FPGA中的過程,具體步驟為:0>在RC端申請一塊物理地址連續(xù)的內(nèi)存,并向該內(nèi)存寫入數(shù)據(jù),EP端準備好讀數(shù)據(jù)后向RC端發(fā)送中斷1>在RC端分析中斷,并向BAR0空間設置本次DMA讀的TLP大小、TLP數(shù)量、讀地址等,(通過PIO的方式,將帶有上述信息的TLP包發(fā)送給EP端,并寫入DMA控制狀態(tài)寄存器中),并啟動DMA2>根據(jù)DMA狀態(tài)與控制寄存器的內(nèi)容,在收到DMA讀啟動命令后,在TX引擎中組裝存儲器讀TLP包后,發(fā)送給PCIe核,RC端根據(jù)收到的存儲器讀包,在指定的地址讀取數(shù)據(jù)后形成帶數(shù)據(jù)的完成包(CPLD)返回給FPGA,F(xiàn)PGA在RX引擎中接收數(shù)據(jù)3>FPGA接收完數(shù)據(jù)后通過中斷形式通知主機DMA讀完成,主機讀取 BAR0 空間狀態(tài)寄存器判斷中斷類型做出相應判斷
狀態(tài)機:BMD_64_RX_RST:根據(jù)trn_rd[62:56]來判斷包的類型:32位地址讀請求
(BMD_MEM_RD32_FMT_TYPE)32位地址寫請求
(BMD_MEM_WR32_FMT_TYPE)不帶數(shù)據(jù)的完成包(BMD_CPL_FMT_TYPE)帶數(shù)據(jù)的完成包(BMD_CPLD_FMT_TYPE)
32位地址讀請求:BMD_64_RX_MEM_RD32_QW1:解析RC端的讀TLP包 — 通知TX引擎發(fā)送完成包BMD_64_RX_MEM_RD32_WT:解析RC端的讀TLP包 — 等待完成包發(fā)送完畢
32位地址寫請求BMD_64_RX_MEM_WR32_QW1:解析RC端的寫TLP包 — 寫入寄存器BMD_64_RX_MEM_WR32_WT:解析RC端的寫TLP包 — 等待寫寄存器完畢
不帶數(shù)據(jù)的完成包BMD_64_RX_CPL_QW1:解析出完成包的tag,送至MEM模塊
帶數(shù)據(jù)的完成包BMD_64_RX_CPLD_QW1:解析RC端的完成包 — 獲得數(shù)據(jù)BMD_64_RX_CPLD_QWN:解析RC端的完成包 — 直至完成
axi-trn互轉(zhuǎn):由于7系列的PCIe核的數(shù)據(jù)是通過AXI-S協(xié)議傳輸?shù)模荴APP1052中的信號的相關處理是對trn_信號進行處理,所以會有一個協(xié)議轉(zhuǎn)換的模塊
以接收類信號為例,發(fā)送類信號類比:trn_rsrc_rdy:表示RC端(接收的源)準備就緒trn_rdst_rdy:表示EP端(接收的目的)準備就緒trn_rsrc_dsc:表示RC端(接收的源)將當前包丟掉trn_rsof:接收幀開始標志,(僅在trn_rsrc_rdy低時有效)trn_reof:接收幀結(jié)束標志,(僅在trn_rsrc_rdy低時有效)trn_rd:接收到的數(shù)據(jù),(僅在trn_rsrc_rdy低時有效)trn_rrem:接收數(shù)據(jù)余數(shù),為0表示數(shù)據(jù)在trn_rd[63:0],為1表示數(shù)據(jù)在trn_rd[63:32](僅在trn_reof、trn_rsrc_rdy、trn_rdst_rdy同時低時有效)trn_rbar_hit[6:0]:表示當前包在哪個BAR空間,低有效(僅在trn_rsof、trn_reof低時有效)trn_rbar_hit[0]——>BAR0trn_rbar_hit[1]——>BAR1trn_rbar_hit[2]——>BAR2trn_rbar_hit[3]——>BAR3trn_rbar_hit[4]——>BAR4trn_rbar_hit[5]——>BAR5trn_rbar_hit[6]——>Expansion ROM Addres
-
FPGA
+關注
關注
1620文章
21510瀏覽量
598972 -
高速接口
+關注
關注
1文章
44瀏覽量
14740 -
PCIe
+關注
關注
15文章
1165瀏覽量
81994
原文標題:FPGA高速接口之PCIe
文章出處:【微信號:gh_873435264fd4,微信公眾號:FPGA技術聯(lián)盟】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
FPGA的高速接口應用注意事項
FPGA的PCIE接口應用需要注意哪些問題
開發(fā)FPGA Kintex-7板子的PCIe與DDR模塊高速通信,應該準備些什么?
求教關于由FPGA上PCIE接口產(chǎn)生中斷的問題
有沒有Alter的FPGA開發(fā)板PCIe接口
6678 pcie和FPGA接口
采用FPGA實現(xiàn)PCIe接口設計
PCIE高速傳輸解決方案FPGA技術XILINX官方XDMA驅(qū)動
今天分享 PCIE高速接口XILINX.ISE教程
采用低成本FPGA實現(xiàn)高效的低功耗PCIe接口

基于FPGA技術的LVDS傳輸模式如何實現(xiàn)PCIE接口卡設計
【含案例源碼】IMX8基于FlexSPI、PCIe與FPGA的高速通信開發(fā)詳解!

基于FPGA的PCIE I/O控制卡通信方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論