 首款自動化深度學習模型壓縮框架——PocketFlow
首款自動化深度學習模型壓縮框架——PocketFlow
【導語】騰訊 AI Lab 機器學習中心今日宣布成功研發出世界上首款自動化深度學習模型壓縮框架——PocketFlow,并即將在今年10-11月發布開源代碼。這是一款面向移動端 AI 開發者的自動模型壓縮框架,與其他現有的模型壓縮框架相比,PocketFlow 優勢在于通過集成多種深度學習模型壓縮算法,并引入超參數優化組件,提升了模型壓縮技術的自動化程度。開發者無需了解具體算法細節,即可快速地將AI技術部署到移動端產品上,實現用戶數據的本地高效處理。接下來 AI科技大本營就為大家解讀一下其背后的理論與技術。
PocketFlow 算法概述
在模型壓縮算法方面,團隊提出了一種基于判別力最大化準則的通道剪枝算法,在性能基本無損的前提下可以大幅度降低CNN網絡模型的計算復雜度,相關論文發表于 NIPS 2018。該算法在訓練過程中引入多個額外的損失項,以提升CNN網絡中各層的判別力,然后逐層地基于分類誤差與重構誤差最小化的優化目標進行通道剪枝,去除判別力相對較小的冗余通道,從而實現模型的無損壓縮。
在超參數優化算法方面,團隊研發了 AutoML 自動超參數優化框架,集成了包括高斯過程(Gaussian Processes, GP)和樹形結構 Parzen 估計器(Tree-structured Parzen Estimator, TPE)等在內的多種超參數優化算法,通過全程自動化托管解決了人工調參耗時耗力的問題,大幅度提升了算法人員的開發效率。
另一方面,考慮到深度學習模型的訓練周期普遍較長,團隊對基于 TensorFlow 的多機多卡訓練過程進行優化,降低分布式優化過程中的梯度通信耗時,研發了名為 TF-Plus 的分布式優化框架,僅需十幾行的代碼修改即可將針對單個GPU的訓練代碼擴展為多機多卡版本,并取得接近線性的加速比。此外,團隊還提出了一種誤差補償的量化隨機梯度下降算法,通過引入量化誤差的補償機制加快模型訓練的收斂速度,能夠在沒有性能損失的前提下實現一到兩個數量級的梯度壓縮,降低分布式優化中的梯度通信量,從而加快訓練速度,相關論文發表于 ICML 2018 。
PocketFlow 框架介紹
PocketFlow 框架主要由兩部分組件構成,分別是模型壓縮/加速算法組件和超參數優化組件,具體結構如下圖所示。
開發者將未壓縮的原始模型作為 PocketFlow 框架的輸入,同時指定期望的性能指標,例如模型的壓縮和/或加速倍數;在每一輪迭代過程中,超參數優化組件選取一組超參數取值組合,之后模型壓縮/加速算法組件基于該超參數取值組合,對原始模型進行壓縮,得到一個壓縮后的候選模型;基于對候選模型進行性能評估的結果,超參數優化組件調整自身的模型參數,并選取一組新的超參數取值組合,以開始下一輪迭代過程;當迭代終止時,PocketFlow 選取最優的超參數取值組合以及對應的候選模型,作為最終輸出,返回給開發者用作移動端的模型部署。
具體地,PocketFlow 通過下列各個算法組件的有效結合,實現了精度損失更小、自動化程度更高的深度學習模型的壓縮與加速:
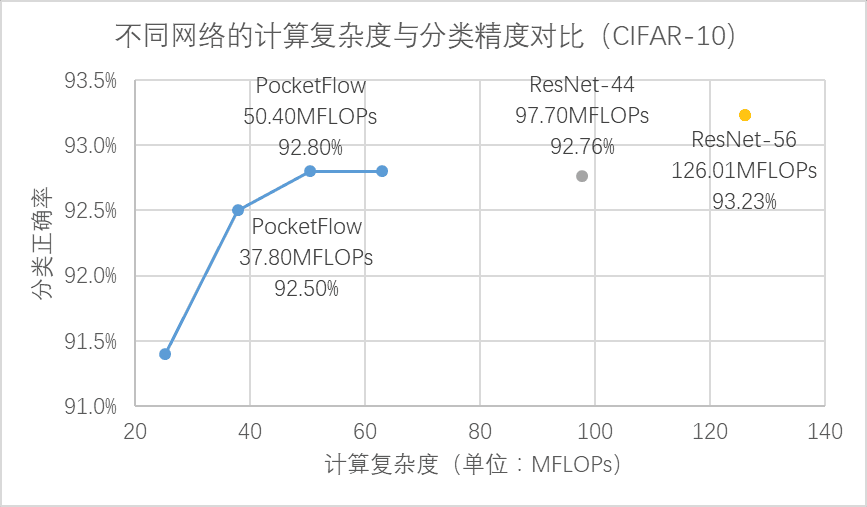
▌通道剪枝(channel pruning)組件:在 CNN 網絡中,通過對特征圖中的通道維度進行剪枝,可以同時降低模型大小和計算復雜度,并且壓縮后的模型可以直接基于現有的深度學習框架進行部署。在 CIFAR-10 圖像分類任務中,通過對 ResNet-56 模型進行通道剪枝,可以實現 2.5 倍加速下分類精度損失 0.4%,3.3 倍加速下精度損失 0.7%。
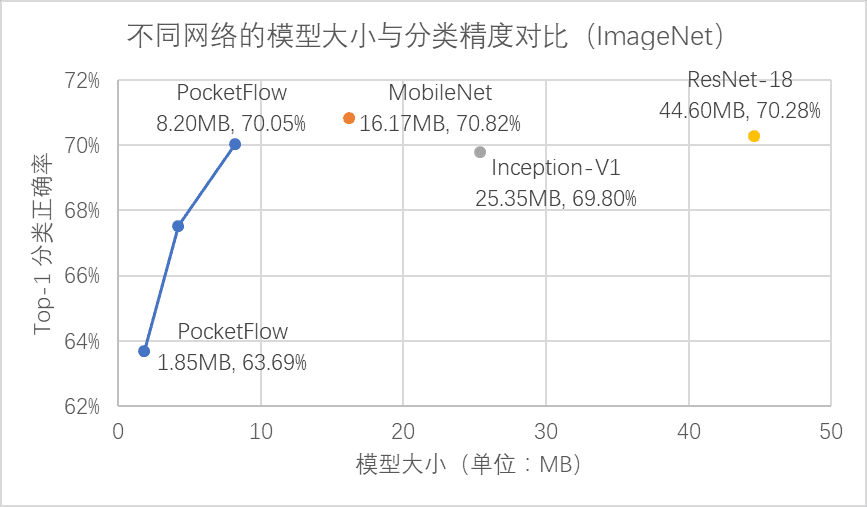
▌權重稀疏化(weight sparsification)組件:通過對網絡權重引入稀疏性約束,可以大幅度降低網絡權重中的非零元素個數;壓縮后模型的網絡權重可以以稀疏矩陣的形式進行存儲和傳輸,從而實現模型壓縮。對于 MobileNet 圖像分類模型,在刪去 50% 網絡權重后,在ImageNet 數據集上的 Top-1 分類精度損失僅為 0.6%。
▌權重量化(weight quantization)組件:通過對網絡權重引入量化約束,可以降低用于表示每個網絡權重所需的比特數;團隊同時提供了對于均勻和非均勻兩大類量化算法的支持,可以充分利用 ARM 和 FPGA 等設備的硬件優化,以提升移動端的計算效率,并為未來的神經網絡芯片設計提供軟件支持。以用于 ImageNet 圖像分類任務的 ResNet-18 模型為例,在 8 比特定點量化下可以實現精度無損的 4 倍壓縮。
▌網絡蒸餾(network distillation)組件:對于上述各種模型壓縮組件,通過將未壓縮的原始模型的輸出作為額外的監督信息,指導壓縮后模型的訓練,在壓縮/加速倍數不變的前提下均可以獲得 0.5%-2.0% 不等的精度提升。
▌多GPU訓練(multi-GPU training)組件:深度學習模型訓練過程對計算資源要求較高,單個GPU難以在短時間內完成模型訓練,因此團隊提供了對于多機多卡分布式訓練的全面支持,以加快使用者的開發流程。無論是基于 ImageNet 數據的 Resnet-50 圖像分類模型還是基于WMT14數據的 Transformer 機器翻譯模型,均可以在一個小時內訓練完畢。
▌超參數優化(hyper-parameter optimization)組件:多數開發者對模型壓縮算法往往不甚了解,但超參數取值對最終結果往往有著巨大的影響,因此團隊引入了超參數優化組件,采用了包括強化學習等算法以及 AI Lab 自研的 AutoML 自動超參數優化框架來根據具體性能需求,確定最優超參數取值組合。例如,對于通道剪枝算法,超參數優化組件可以自動地根據原始模型中各層的冗余程度,對各層采用不同的剪枝比例,在保證滿足模型整體壓縮倍數的前提下,實現壓縮后模型識別精度的最大化。
PocketFlow 性能
通過引入超參數優化組件,不僅避免了高門檻、繁瑣的人工調參工作,同時也使得 PocketFlow在各個壓縮算法上全面超過了人工調參的效果。以圖像分類任務為例,在 CIFAR-10 和ImageNet等 數據集上,PocketFlow 對 ResNet 和M obileNet 等多種 CNN網絡結構進行有效的模型壓縮與加速。
在 CIFAR-10 數據集上,PocketFlow 以 ResNet-56 作為基準模型進行通道剪枝,并加入了超參數優化和網絡蒸餾等訓練策略,實現了 2.5 倍加速下分類精度損失 0.4%,3.3 倍加速下精度損失 0.7%,且顯著優于未壓縮的 ResNet-44 模型; 在 ImageNet 數據集上,PocketFlow 可以對原本已經十分精簡的 MobileNet 模型繼續進行權重稀疏化,以更小的模型尺寸取得相似的分類精度;與 Inception-V1、ResNet-18 等模型相比,模型大小僅為后者的約 20~40%,但分類精度基本一致(甚至更高)。
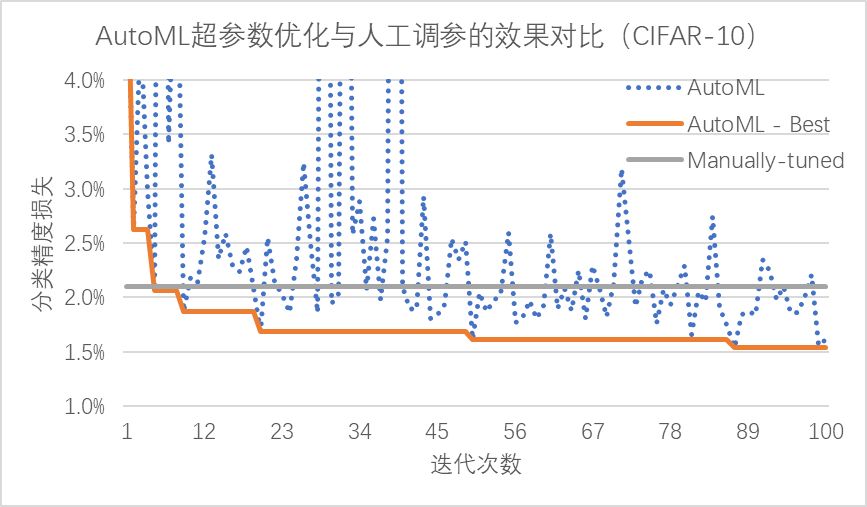
相比于費時費力的人工調參,PocketFlow 框架中的 AutoML 自動超參數優化組件僅需 10 余次迭代就能達到與人工調參類似的性能,在經過 100 次迭代后搜索得到的超參數組合可以降低約0.6% 的精度損失;通過使用超參數優化組件自動地確定網絡中各層權重的量化比特數,PocketFlow 在對用于 ImageNet 圖像分類任務的 ResNet-18 模型進行壓縮時,取得了一致性的性能提升;當平均量化比特數為4 比特時,超參數優化組件的引入可以將分類精度從 63.6%提升至 68.1%(原始模型的分類精度為 70.3%)。
部署與應用
PocketFlow 助力移動端業務落地。在騰訊公司內部,PocketFlow 框架正在為多項移動端實際業務提供了模型壓縮與加速的技術支持。例如,在手機拍照 APP 中,人臉關鍵點定位模型是一個常用的預處理模塊,通過對臉部的百余個特征點(如眼角、鼻尖等)進行識別與定位,可以為后續的人臉識別、智能美顏等多個應用提供必要的特征數據。團隊基于 PocketFlow 框架,對人臉關鍵點定位模型進行壓縮,在保持定位精度不變的同時,大幅度地降低了計算開銷,在不同的移動處理器上取得了 25%-50% 不等的加速效果,壓縮后的模型已經在實際產品中得到部署。
對話騰訊 AI Lab
在發布的首日,我們和騰訊 AI Lab 就 PocketFlow 相關問題進行了更深入的交流。以下內容為采訪實錄。
▌目前有哪些主流的模型壓縮算法?你們采用的基于判別力最大化準則的通道剪枝算法的原理是什么?有哪些優勢?
騰訊 AI Lab:目前主流的模型壓縮算法包括低秩分解(low-rank decomposition)、通道剪枝(channel pruning)、權重稀疏化(weight sparsification)、權重量化(weight quantization)、網絡結構搜索(network architecture search)等。PocketFlow 中不僅包含了 AI Lab 自研的模型壓縮算法(例如基于判別力最大化準則的通道剪枝算法),還提供了對當前主流的多種模型壓縮算法(包括通道剪枝、權重稀疏化、權重量化)的支持,并且基于自研的 AutoML 框架提供了分布式網絡結構搜索功能,功能完備且易于擴展。
我們提出基于判別力最大化準則的通道剪枝算法的一個出發點是目前的通道剪枝算法大多沒有考慮通道的判別力信息,僅考慮了重構誤差的最小化,導致高壓縮倍數下的精度損失較大。我們算法首先在訓練過程中引入了多個額外的有監督損失項,以提升CNN網絡中各層的判別力,再逐層地基于分類誤差與重構誤差最小化的優化目標進行通道剪枝,去除判別力相對較小的冗余通道,從而實現模型的無損壓縮。
▌PocketFlow框架支持通道剪枝、權重稀疏化、權重量化算法,每次模型壓縮的過程是隨機選擇一種算法嗎?這些算法各有哪些優勢?
騰訊 AI Lab:PocketFlow 會基于具體的模型壓縮需求,選擇適當的模型壓縮算法。這三類算法各有優勢:通道剪枝算法的加速性能較好,易于部署;權重稀疏化算法可以達到更高的壓縮倍數;權重量化算法的內存帶寬開銷較小,并且可以充分利用 ARM、FPGA 等設備在定點運算方面的硬件優化。舉個例子,如果用戶希望得到加速倍數較高的壓縮模型,并且直接在移動端部署,那么PocketFlow 會自動地選擇通道剪枝算法進行模型壓縮。
▌對網絡權重引入稀疏化約束會增加模型的訓練難度,降低模型的收斂性嗎?你們是如何解決的?
騰訊 AI Lab:是的,在加入權重稀疏化約束的過程中,會引入數個超參數,如果取值不當,會導致模型訓練不穩定甚至完全不收斂。PocketFlow 中超參數優化組件的引入正是為了解決這一問題(同時也適用于其他模型壓縮算法),通過自動化地搜索最優超參數取值組合,僅經過 10余 次迭代就可以達到與人工調參類似的效果,在 100 次迭代后可以使得壓縮后的模型降低約 0.6% 的精度損失。
▌在超參數優化方面,你們提出的 AutoML-自動超參數優化框架和 Google 的 AutoML 有什么異同?
騰訊 AI Lab:AutoML 自動超參數優化框架是我們 AI Lab 之前已有的一套自研工具,適用于任意模型的超參數優化任務,PocketFlow 借助于該框架實現了模型壓縮與加速場景下的超參數優化,以提高訓練流程的自動化程度,降低使用門檻。Google 的 AutoML 則更多地針對視覺領域的應用場景,實現了從網絡結構搜索到遷移學習和超參數優化的整體流程的自動化。
▌為什么 PocketFlow 可以在壓縮模型的基礎上甚至讓模型的性能提升?
騰訊 AI Lab:目前深度學習模型大多存在一定的冗余度,通過在一定范圍內降低模型的冗余度,往往不會對模型的擬合能力造成影響;另一方面,模型壓縮算法通過限制模型的解空間,可以起到防止模型過擬合的作用,尤其是在一些訓練數據和標注信息有限的應用場景下,反而能帶來模型的性能提升。
▌壓縮過程是在云端還是離線完成的?如何保護使用者技術隱私和數據隱私?
騰訊 AI Lab:模型壓縮的訓練過程沒有對云端服務的依賴,可以直接基于我們即將發布的開源代碼在使用者的本地環境中運行,無需擔心技術和數據的隱私性問題。
▌模型壓縮后如何部署到移動端(各種不同的移動設備)?對硬件的需求如何?
騰訊 AI Lab:基于不同模型壓縮算法訓練得到的模型的部署方式不盡相同,例如通道剪枝后的模型可以直接基于目前常見的移動端深度學習框架進行部署,權重定點量化后的模型可以基于 TensorFlow Lite進行部署。經過 PocketFlow 壓縮或者加速后,無論是模型大小還是計算量都大大精簡,因此在移動端部署模型時對硬件的需求并不高,例如我們正在為一款手機拍照 APP 提供模型壓縮支持,壓縮后的模型在華為 Mate 10 和小米 5S Plus 等設備上的運行耗時均在10ms 以內。
▌你們的實驗都是用的 CV 里ResNet 和 MobileNet 這種比較成熟的模型,以及被廣泛使用的公開數據集CIFAR-10和ImageNet,推廣到其他任意的模型上的效果是否也可以保證?泛化效果如何?
騰訊 AI Lab:我們在騰訊公司內部也支持了諸如人臉關鍵點定位和姿態估計等任務中的模型壓縮需求。以人臉關鍵點定位任務為例,我們可以在保持定位精度不變的同時,顯著降低計算開銷,根據在不同手機上的實測數據,壓縮后的模型可以取得 1.4-2.0 倍不等的加速效果。
▌PocketFlow目前有沒有對語音識別、NLP等領域的任務模型進行壓縮前后的對照試驗?效果如何?
騰訊 AI Lab:我們當前主要針對視覺領域中的模型進行壓縮,下一階段的主要研發目標之一就是為語音和 NLP 等模型提供壓縮技術支持,屆時也歡迎有相關需求的開發者和研究人員來使用并提出改進意見。
▌用戶需要設定哪些期望性能指標?是預先設定好迭代次數?迭代次數如何設定是合適的?如果一直達不到設定的指標怎么辦?
騰訊 AI Lab:用戶主要需要設置的期望性能指標是目標的模型壓縮和/或加速倍數,之后 PocketFlow 會自動搜索符合要求的模型中精度最高者作為輸出;我們會給出建議的壓縮/加速倍數的設置范圍(例如基于權重量化的壓縮倍數不能超過 32 倍),因此基本不會出現達不到性能指標的問題。迭代次數不需要用戶設置(對于進階用戶我們提供了設置迭代次數的接口),根據實驗評估結果,我們預設的迭代次數適用于多個模型壓縮算法的超參數優化任務。
▌開發者什么時候可以真正使用上?
騰訊 AI Lab:我們預計在今年10-11月完成 PocketFlow 的開源發布工作,屆時普通開發者即可開始使用,同時我們也歡迎有興趣的開發者向 PocketFlow 貢獻代碼。
-
騰訊
+關注
關注
7文章
1644瀏覽量
49400 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977
原文標題:對話騰訊AI Lab:即將開源自動化模型壓縮框架PocketFlow,加速效果可達50%
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow
自動化測試框架思想和構建
基于Web的自動化測試框架的研究
深度學習模型壓縮與加速綜述






 工商網監
工商網監
評論