 騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow
騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow
AI科技評論按:騰訊 AI Lab 機器學習中心今日宣布成功研發出世界上首款自動化深度學習模型壓縮框架—— PocketFlow,并即將在近期發布開源代碼。根據雷鋒網AI科技評論了解,這是一款面向移動端AI開發者的自動模型壓縮框架,集成了當前主流的模型壓縮與訓練算法,結合自研超參數優化組件實現了全程自動化托管式的模型壓縮與加速。開發者無需了解具體算法細節,即可快速地將AI技術部署到移動端產品上,實現用戶數據的本地高效處理。
隨著AI技術的飛速發展,越來越多的公司希望在自己的移動端產品中注入AI能力,但是主流的深度學習模型往往對計算資源要求較高,難以直接部署到消費級移動設備中。在這種情況下,眾多模型壓縮與加速算法應運而生,能夠在較小的精度損失(甚至無損)下,有效提升 CNN 和 RNN 等網絡結構的計算效率,從而使得深度學習模型在移動端的部署成為可能。但是,如何根據實際應用場景,選擇合適的模型壓縮與加速算法以及相應的超參數取值,往往需要較多的專業知識和實踐經驗,這無疑提高了這項技術對于一般開發者的使用門檻。
在此背景下,騰訊AI Lab機器學習中心研發了 PocketFlow 開源框架,以實現自動化的深度學習模型壓縮與加速,助力AI技術在更多移動端產品中的廣泛應用。通過集成多種深度學習模型壓縮算法,并創新性地引入超參數優化組件,極大地提升了模型壓縮技術的自動化程度。開發者無需介入具體的模型壓縮算法及其超參數取值的選取,僅需指定設定期望的性能指標,即可通過 PocketFlow 得到符合需求的壓縮模型,并快速部署到移動端應用中。
框架介紹
PocketFlow 框架主要由兩部分組件構成,分別是模型壓縮/加速算法組件和超參數優化組件,具體結構如下圖所示。
開發者將未壓縮的原始模型作為 PocketFlow 框架的輸入,同時指定期望的性能指標,例如模型的壓縮和/或加速倍數;在每一輪迭代過程中,超參數優化組件選取一組超參數取值組合,之后模型壓縮/加速算法組件基于該超參數取值組合,對原始模型進行壓縮,得到一個壓縮后的候選模型;基于對候選模型進行性能評估的結果,超參數優化組件調整自身的模型參數,并選取一組新的超參數取值組合,以開始下一輪迭代過程;當迭代終止時,PocketFlow 選取最優的超參數取值組合以及對應的候選模型,作為最終輸出,返回給開發者用作移動端的模型部署。
具體地,PocketFlow 通過下列各個算法組件的有效結合,實現了精度損失更小、自動化程度更高的深度學習模型的壓縮與加速:
a) 通道剪枝(channel pruning)組件:在CNN網絡中,通過對特征圖中的通道維度進行剪枝,可以同時降低模型大小和計算復雜度,并且壓縮后的模型可以直接基于現有的深度學習框架進行部署。在CIFAR-10圖像分類任務中,通過對 ResNet-56 模型進行通道剪枝,可以實現2.5倍加速下分類精度損失0.4%,3.3倍加速下精度損失0.7%。
b) 權重稀疏化(weight sparsification)組件:通過對網絡權重引入稀疏性約束,可以大幅度降低網絡權重中的非零元素個數;壓縮后模型的網絡權重可以以稀疏矩陣的形式進行存儲和傳輸,從而實現模型壓縮。對于 MobileNet 圖像分類模型,在刪去50%網絡權重后,在 ImageNet 數據集上的 Top-1 分類精度損失僅為0.6%。
c) 權重量化(weight quantization)組件:通過對網絡權重引入量化約束,可以降低用于表示每個網絡權重所需的比特數;團隊同時提供了對于均勻和非均勻兩大類量化算法的支持,可以充分利用 ARM 和 FPGA 等設備的硬件優化,以提升移動端的計算效率,并為未來的神經網絡芯片設計提供軟件支持。以用于 ImageNet 圖像分類任務的 ResNet-18 模型為例,在8比特定點量化下可以實現精度無損的4倍壓縮。
d) 網絡蒸餾(network distillation)組件:對于上述各種模型壓縮組件,通過將未壓縮的原始模型的輸出作為額外的監督信息,指導壓縮后模型的訓練,在壓縮/加速倍數不變的前提下均可以獲得0.5%-2.0%不等的精度提升。
e) 多GPU訓練(multi-GPU training)組件:深度學習模型訓練過程對計算資源要求較高,單個GPU難以在短時間內完成模型訓練,因此團隊提供了對于多機多卡分布式訓練的全面支持,以加快使用者的開發流程。無論是基于 ImageNet 數據的Resnet-50圖像分類模型還是基于 WMT14 數據的 Transformer 機器翻譯模型,均可以在一個小時內訓練完畢。[1]
f) 超參數優化(hyper-parameter optimization)組件:多數開發者對模型壓縮算法往往不甚了解,但超參數取值對最終結果往往有著巨大的影響,因此團隊引入了超參數優化組件,采用了包括強化學習等算法以及 AI Lab 自研的 AutoML 自動超參數優化框架來根據具體性能需求,確定最優超參數取值組合。例如,對于通道剪枝算法,超參數優化組件可以自動地根據原始模型中各層的冗余程度,對各層采用不同的剪枝比例,在保證滿足模型整體壓縮倍數的前提下,實現壓縮后模型識別精度的最大化。
性能展示
通過引入超參數優化組件,不僅避免了高門檻、繁瑣的人工調參工作,同時也使得 PocketFlow 在各個壓縮算法上全面超過了人工調參的效果。以圖像分類任務為例,在 CIFAR-10 和 ImageNet 等數據集上, PocketFlow 對 ResNet 和 MobileNet 等多種 CNN 網絡結構進行有效的模型壓縮與加速。[1]
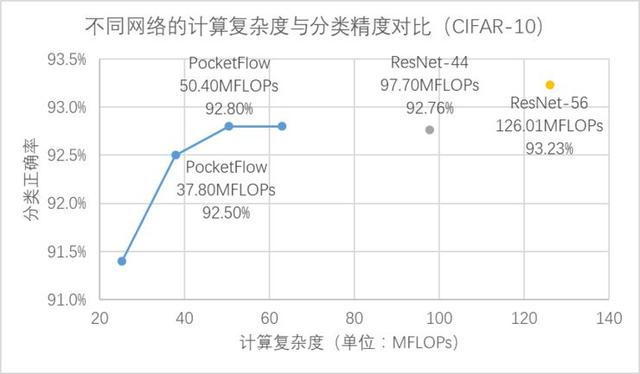
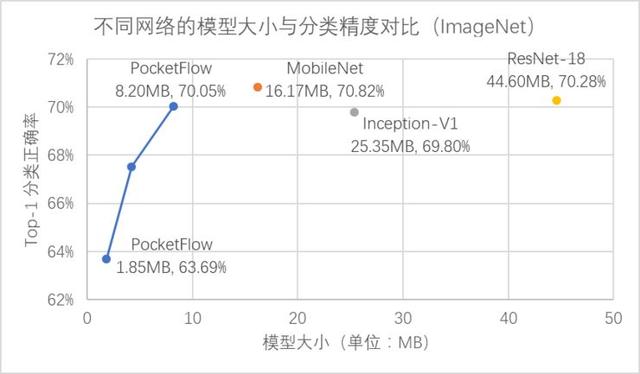
在 CIFAR-10 數據集上,PocketFlow 以 ResNet-56 作為基準模型進行通道剪枝,并加入了超參數優化和網絡蒸餾等訓練策略,實現了2.5倍加速下分類精度損失0.4%,3.3倍加速下精度損失0.7%,且顯著優于未壓縮的ResNet-44模型; [2] 在 ImageNet 數據集上,PocketFlow 可以對原本已經十分精簡的 MobileNet 模型繼續進行權重稀疏化,以更小的模型尺寸取得相似的分類精度;與 Inception-V1 、ResNet-18 等模型相比,模型大小僅為后者的約20~40%,但分類精度基本一致(甚至更高)。
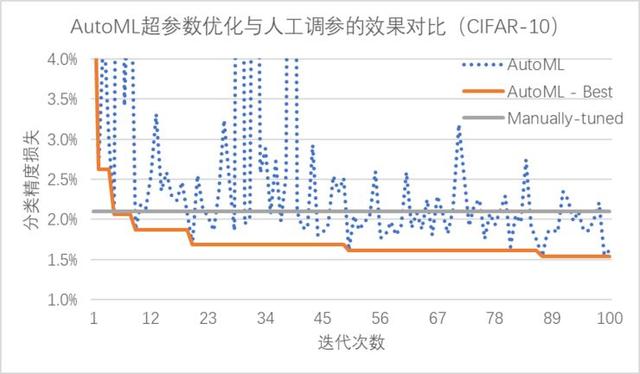
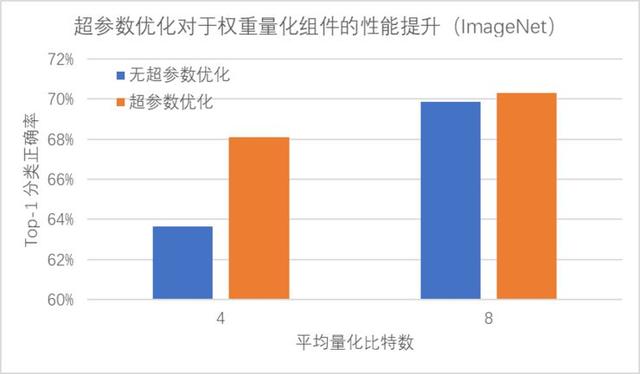
相比于費時費力的人工調參,PocketFlow 框架中的 AutoML 自動超參數優化組件僅需10余次迭代就能達到與人工調參類似的性能,在經過100次迭代后搜索得到的超參數組合可以降低約0.6%的精度損失;通過使用超參數優化組件自動地確定網絡中各層權重的量化比特數,PocketFlow 在對用于 ImageNet 圖像分類任務的ResNet-18模型進行壓縮時,取得了一致性的性能提升;當平均量化比特數為4比特時,超參數優化組件的引入可以將分類精度從63.6%提升至68.1%(原始模型的分類精度為70.3%)。
深度學習模型的壓縮與加速是當前學術界的研究熱點之一,同時在工業界中也有著廣泛的應用前景。隨著PocketFlow的推出,開發者無需了解模型壓縮算法的具體細節,也不用關心各個超參數的選擇與調優,即可基于這套自動化框架,快速得到可用于移動端部署的精簡模型,從而為AI能力在更多移動端產品中的應用鋪平了道路。
參考文獻
[1] Zhuangwei Zhuang, Mingkui Tan, Bohan Zhuang, Jing Liu, Jiezhang Cao, Qingyao Wu, Junzhou Huang, Jinhui Zhu, “Discrimination-aware Channel Pruning for Deep Neural Networks", In Proc. of the 32nd Annual Conference on Neural Information Processing Systems, NIPS '18, Montreal, Canada, December 2018.
[2] Jiaxiang Wu, Weidong Huang, Junzhou Huang, Tong Zhang, “Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization”, In Proc. of the 35th International Conference on Machine Learning, ICML ’18, Stockholm, Sweden, July 2018.
本文來源:AI科技評論
-
AI
+關注
關注
87文章
28875瀏覽量
266191 -
騰訊
+關注
關注
7文章
1633瀏覽量
49289
發布評論請先 登錄
相關推薦
機械自動化和電氣自動化區別是什么
機械自動化是自動化的一種嗎
產線自動化改造,智能化空調壓縮機中的工業RFID技術應用
工業自動化和自動化區別是什么
IBM開源AI模型,推動AI企業化應用
Yellow.ai業界首創生成式AI代理模型
紅帽發布RHEL AI開發者預覽版,集成IBM Granite模型,簡化AI開發流程
鴻蒙OS開發實戰:【自動化測試框架】使用指南
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
HamronyOS自動化測試框架使用指南
明治傳感亮相世界頂級自動化大展







 工商網監
工商網監
評論