 高速率低延時Viterbi譯碼器的設計與實現
高速率低延時Viterbi譯碼器的設計與實現
摘要:
在Vitebi譯碼器的實現中,由于路徑存儲方式的不同分為回溯和寄存器交換模式,效果是延時與資源消耗一般只能二取其一,互為矛盾。采取3~6長度的RE-寄存器交換,混合回溯模式,極大地減少了回溯時間,并減少了路徑存儲空間需求,付出的代價是每ACS增加2~5 LUT;再結合其他Viterbi譯碼器優化算法,如分支度量一次計算,每ACS查找——即4選1等措施,實現了高吞吐量(340 Mb/s)、低延時、低資源消耗的全并行Viterbi譯碼器。
0 引言
Viterbi譯碼是1967年由VITERBI A J提出的一種概率譯碼算法,且是最大似然譯碼法。后來發現,這種算法可用于多種數字估值問題,如碼間干擾下的判決、連續相位FSK信號的最佳接收、語詞識別、序列跟蹤和源編碼等。Viterbi算法的這些應用都可以歸結為時間離散、狀態有限的馬氏過程的最佳估值問題,因而它不僅是卷積碼的一種重要譯碼算法,而且在理論上也有較大意義。
由于卷積碼優良的糾錯性能和Viterbi硬件譯碼器簡單(容易實現高速譯碼),被廣泛應用于深空通信、衛星通信、IEEE 802.11、超寬帶(UWB)系統、DAB、DVB、2G、3G、LTE、Wimax以及電力線通信中。
自1986年以來,國際上發表了很多關于Viterbi譯碼器設計的文章,如文獻[1]~[6]。為追求譯碼速度,大多采用全并行結構,吞吐量可高達1.74 Gb/s[3]、2.8 Gb/s[4],同時目前各大FPGA廠商都已經提供了很多的IP核[7]。
由于內部互連機制不同,基于FPGA的譯碼器與結構化ASIC以及定制ASIC的工作速度不可同日而語,在FPGA上實現的譯碼器工作頻率一般在140~510 MHz[6,7]之間,同樣的設計結構若采取定制ASIC實現,應能達到與文獻[3-4]相近的工作頻率(800 MHz~1.4 GHz)。
從工程應用角度看,對Viterbi 譯碼器的性能評價指標主要有譯碼速度、處理時延和資源占用等。傳統的Viterbi譯碼器結構難以兼具資源消耗少和時延小的優點。而在高速通信系統中,很多時候對譯碼時延要求很高。本文提出了一種采用部分寄存器交換的辦法可兼顧譯碼延時和消耗邏輯資源的性能。測試結果表明,采用這種部分寄存器交換的回溯方式存儲幸存路徑,具有寄存器交換時延小的優點,而所需邏輯資源與普通回溯法相當,所需存儲單元大大小于普通回溯法。
1 部分寄存器交換方式的路徑存儲
1.1 傳統的路徑存儲
幸存路徑存儲器的結構主要有兩種:一種是寄存器交換結構(RE),另一種是回溯結構(TB)[1-2]。
前者采用專用寄存器作為存儲主體,存儲的是路徑上的輸入信號信息,利用數據在寄存器陣列中的不斷交換來實現譯碼。這種方法雖然具有存儲單元少、譯碼延時短的優點,但由于其內連關系過于復雜, 功耗大(每個新判決比特輸入時寄存器都要翻轉),不適合大狀態Viterbi譯碼器的FPGA實現。
回溯法利用通用的RAM作為存儲主體,存儲的是幸存路徑的格狀連接關系,通過讀寫RAM來完成數據的寫入和回溯輸出。其優點是內連關系簡單、規則;缺點一是譯碼延時大——一般并行譯碼時回溯法的延時是寄存器交換法的4倍,缺點二是存儲單元要求多。具體性能區別分析如下。
設卷積碼編碼約束長度為L,譯碼深度V=6×L;對碼率R=1/2的譯碼器而言,每系統時鐘輸入2 bit編碼傳輸信息,輸出1 bit譯碼后信息。
對于基2加比選的全并行RE方式:路徑存儲部分需鎖存交換2L-1個狀態的長V路徑信息,即需V×2L-1個邏輯單元和寄存器,譯碼時延為V個系統時鐘。
對于全并行的傳統TB方式,因每譯出1 bit,至少回溯V bit,為實現連續譯碼,一次回溯應譯出多個比特,設為x。則從譯碼輸入到準備回溯需等待V+x個系統時鐘,若每系統時鐘只回溯y=1 bit,則一次譯碼輸出需回溯V+x個系統時鐘。采取多片輪讀(一片寫,2至多片讀)的模式,在回溯期間又寫入V+x個符號的路徑信息。
流水線方式操作時,在(n+1)x系統時鐘內至少完成n次回溯譯碼x bit。2片讀時,2x時鐘內需完成(V+x)符號的回溯,因而一般取x=V。
這樣,2x時鐘內讀的2片RAM深度分別為2V,寬度2L-1個狀態的1 bit路徑信息,共計4V深度(按之前4V系統時鐘內寫入順序標記為1a、1b,之后啟動寫2a、2b的深度為2V的2片RAM),寫入2V深度之后啟動回溯讀出1b、1a;V深度后另一片讀出2a、1b,這樣回溯出1a、1b處的傳輸信息,同時寫入2b、1a路徑。
在這段時間內又寫入2V深度的路徑信息(1a,1b),與2片讀的RAM中的前一片2V深度RAM讀出信息(1b,1a)交叉。當路徑存儲RAM采用一讀一寫的雙端口RAM實現時,2片RAM即可實現1片寫,2片讀的寫入及回溯功能。
所以,總存儲單元應為深度為4V個符號的寬度2L-1個狀態路徑信息,即4V×2L-1bit存儲單元,實際深度取滿足(M=2N>4V)的最小正整數N對應的M。
譯碼延時:從譯碼器開始接收到準備回溯需2V個時鐘,回溯(V+x)即2V深度需2V個系統時鐘,共計4V個系統時鐘。
1.2 改進的部分寄存器交換回溯方式
從上述傳統TB方式可以看出,為減小譯碼延時和存儲單元,可采取一次并行讀出多比特符號的路徑信息。本文提出采用部分寄存器交換方法,累積多符號(2~6)的路徑信息后,一次存儲寫入一個地址的存儲單元,從而加快之后的讀過程。
設部分RE的長度為y。采取1片存儲單元1讀1寫方式,每次回溯譯出x比特,則回溯延時為t=(V+x)/y;在此回溯期間又寫入t比特路徑信息,為保證路徑信息存儲單元不發生有用信息覆蓋,要求t≤x,即x≥(V+x)/y,也即x≥V/(y-1)。一般x取滿足條件的最小整數值。
譯碼延時為等待時間加回溯時間。對每段譯碼信息而言從開始接收到回溯前的等待時間為:V+x比特的譯碼信息接收時間V+x個系統時鐘。譯碼延時共計V+x+t≈V+2x。
路徑信息存儲單元為(V+2x)/y深(實際深度取滿足M=2N>(V+2x)/y的最小正整數N對應的M),y×2L-1寬,總比特數為(V+2x)×2L-1。
另外,回溯時要多消耗y個2L-1選一的邏輯資源,即y×2L-1的組合LUT;由于采用部分寄存器交換,需要2L-1個長為y的寄存器鎖存當前路徑信息。
2 其他優化措施
采用了文獻[5]中提到的分支度量線性變換3 bit量化解調信號時,分支度量仍為3 bit的非負數,簡化了之后的路徑度量溢出處理。
分支度量一次計算多次查找——對于(2,1,n)碼即4選一。
簡單的累積路徑度量溢出,對于(2,1,7)3 bit量化卷積碼,路徑度量的最大最小范圍在3+log27位內。因所有路徑度量及分支度量都是非負數,這樣再補充一位最高位溢出位,確定了存儲路徑度量的寄存器位寬為3+log27+17。
由于采用全并行結構,一個時鐘內必須完成一次ACS(Add-Compare-Select,加比選),因而ACS部分未采用文獻[7]中流水線結構,ACS是制約全并行結構Viterbi譯碼器最高工作頻率的因素之一。但采取了緩解分支度量選擇的時延,兩級計算鎖存的分支度量算法,較一級分支度量鎖存提高了約10 MHz的最高工作頻率。
3 譯碼器設計
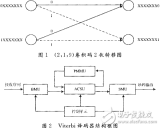
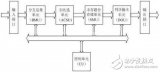
譯碼器的結構框圖如圖1所示。
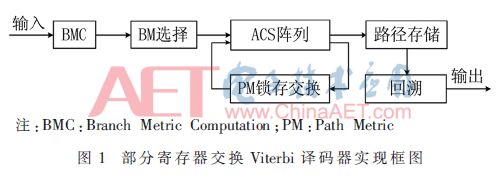
4 資源占用實驗性能
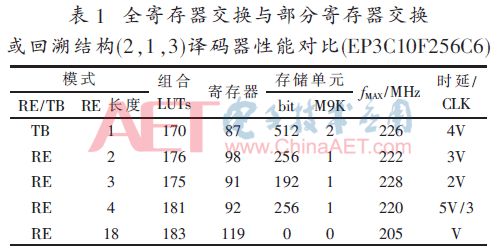
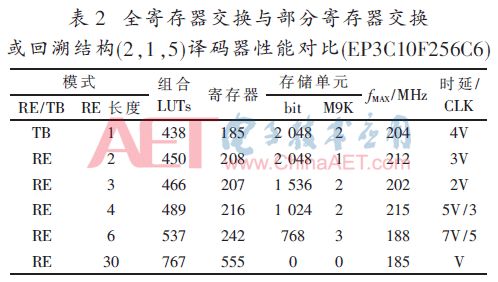
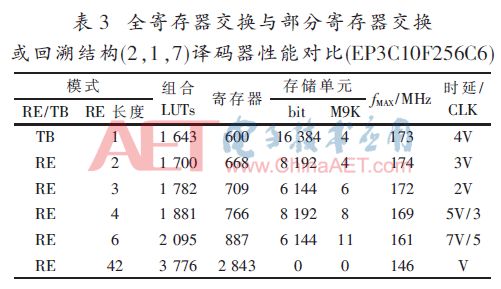
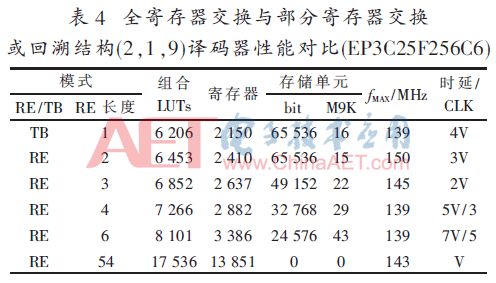
按照圖1設計的基2全并行譯碼器在Quartus9.1下時序仿真正確后,綜合適配結果如表1~表4所述,其中:V=6×L,量化比特數為3。
5 譯碼器其他性能
5.1 譯碼器譯碼性能
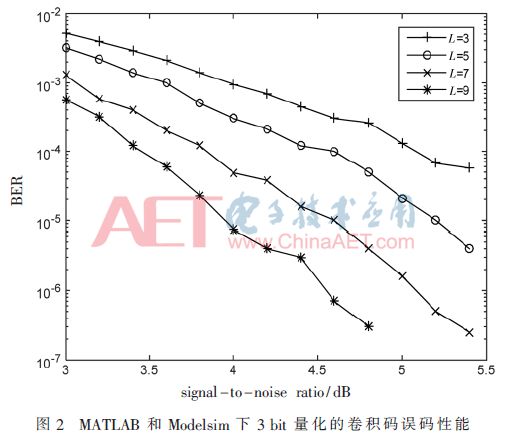
在MATLAB下3 bit量化定點仿真和Modelsim下3 bit量化前仿真:分別對(2,1,3)、(2,1,5)、(2,1,7)、(2,1,9)的50段(信噪比小于等于4.4 dB時)或100段(信噪比大于4.4 dB時)長度為40 000的已編碼序列經信噪比(SNR=Eb/no)為3~5.4 dB(僅在MATLAB下,而在Modelsim下每種卷積碼僅選擇譯碼BER=10-3及10-4兩種情況)的AGWN BPSK信道傳輸的接收信號進行模擬,誤碼性能如圖2所示。后仿真[2,7]時對(2,1,3)、(2,1,5)、(2,1,7)、(2,1,9)4種卷積碼分別選取了5.2 dB、4.8 dB、4.0 dB、3.4 dB下長度為40 000的有噪已編碼接收序列進行誤碼性能測試,與圖2完全一致。
5.2 吞吐量
當吞吐量定義為譯碼器輸出信息速率時(而文獻[5]中吞吐量定義為譯碼器輸入速率,與量化比特無關),對于本文中的基2全并行碼率R=1/2的Viterbi譯碼器,吞吐量為2fmax。即在CycloneIII上實現的(2,1,7)全并行譯碼器吞吐量在290~350 Mb/s之間。
在結構化ASIC器件如HardCopyIII上消耗邏輯資源與在CycloneIII上相當時(2,1,7)卷積碼的最高工作頻率340 Hz,吞吐量680 Mb/s。
若采用定制ASIC實現,吞吐量應可滿足引言中提到的目前各種使用Viterbi譯碼的標準(500 Mb/s)的需求。
5.3 與其他文獻的并行譯碼器性能對比
與其他文獻的(2,1,3)全并行譯碼器性能對比(EP3-C10F256C6)如表5所示。
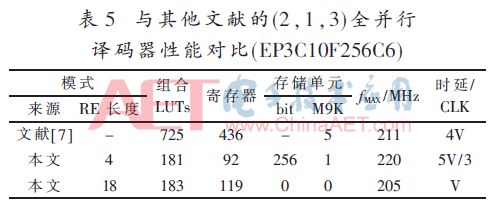
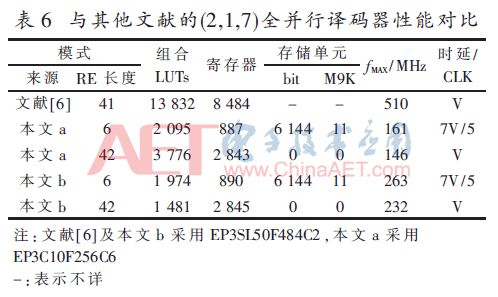
由表中數據可以看出,本文設計的(2,1,3)卷積碼全并行譯碼器明顯優于Altera公司提供的IP核,邏輯資源占用量僅其25%,譯碼時延也僅其25%。與其他文獻的(2,1,7)全并行譯碼器性能對比如表6所示。
6 結論
本文采用部分寄存器交換的譯碼器在交換長度為3時與簡單回溯模式相比消耗邏輯資源幾乎相近,存儲單元減少25%~66%的條件下實現譯碼延時減半的效果。
對于短約束長度的卷積碼,如(2,1,3)、(2,1,5)采用全寄存器交換資源消耗不會增加太多,但譯碼延時比交換長度為3時又減少50%,更具實用價值。
而對于長約束長度的卷積碼,如(2,1,7)、(2,1,9)采用全寄存器交換資源消耗增加太多,選用寄存器交換長度為4或6時較合適,此時的時延與完全寄存器交換相近,但消耗的邏輯資源與簡單回溯模式相當,存儲器單元比簡單回溯小很多(小50%或62.5%),雖然在本文中的FPGA下實現時消耗的存儲塊數更多,但那是由于CycloneIII的每塊存儲塊比較大(深度大而寬度受限),若采用最小深度為16的小存儲塊時(比如定制ASIC技術)其優勢將明顯顯現出來。
-
寄存器
+關注
關注
31文章
5317瀏覽量
120010 -
譯碼器
+關注
關注
4文章
310瀏覽量
50280 -
Viterbi
+關注
關注
0文章
13瀏覽量
9799
原文標題:【學術論文】高速率低延時Viterbi譯碼器的設計與實現
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是硬判決和軟判決Viterbi 譯碼算法 ?
應用于LTE-OFDM系統的Viterbi譯碼在FPGA中的實現
基于IP核的Viterbi譯碼器實現
基帶芯片中Viterbi譯碼器的研究與實現
從FPGA實現的角度對大約束度Viterbi譯碼器中路徑存儲
Viterbi譯碼器回溯算法實現

基于ME算法的RS譯碼器VLSI高速實現方法
基于ASIC的高速Viterbi譯碼器設計
基于FPGA的指針反饋式低功耗Viterbi譯碼器的性能分析和設計

關于基于Xilinx FPGA 的高速Viterbi回溯譯碼器的性能分析和應用介紹
通過采用FPGA器件設計一個Viterbi譯碼器
基于XC6SLX16-2CSG-324型FPGA實現Viterbi譯碼器的設計
淺談FPGA的指針反饋式低功耗Viterbi譯碼器設計






 工商網監
工商網監
評論