 自然語言處理研究的基本問題及發展趨勢
自然語言處理研究的基本問題及發展趨勢
自然語言處理(NLP)是計算機科學領域與人工智能領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。隨著深度學習在圖像識別、語音識別領域的大放異彩,人們對深度學習在NLP的價值也寄予厚望。自然語言處理作為人工智能領域的認知智能,成為目前大家關注的焦點。
基本概念
自然語言處理既是一門技術也是一門學科。
自然語言指人類使用的語言,如漢語、英語等
語言是思維的載體,是人類交流的工具
語言的兩種屬性:文字和聲音
人類歷史上以文字形式記載和流傳的知識占80%以上。
自然語言處理的定義:
"自然語言處理又稱為自然語言理解,就是利用計算機為工具對人類特有的書面形式和又頭形式的自然語言的信息進行各種類型處理和加工的技術。” —— 馮志偉《自然語言的計算機處理》
研究的基本問題
1. 語音學
語音學(Phonetics)問題:研究詞及其語音的關聯
2. 形態學
形態學(Morphology)問題:研究詞是如何由有意義的基本單位-詞素(Morphemes)構詞的。
詞素是從詞或者詞干的直接成分的角度來確定的音義結合體。字和詞素不是一一對應的:
有的漢字實際上代表不同的詞素。如“副”這個字代表多種詞素:“第二的、次級的”、“相配、相稱”、某種計量單位。
同一詞素可以由不同的漢字來表示。如:“來吧”中的“吧”可以由“罷”代替。
有些漢字在某些場合屬于詞素,某些場合不是。如:“沙”在“泥沙”里面是詞素,在“沙發”里面不代表意義。詞素與詞的關系是“詞素的功能是構詞詞”。
詞素構詞有兩種情況:
一個詞素單獨構詞一個詞。如:人、魚、書、蜈蚣等。
兩個或兩個以上的詞素構詞一個詞。如:人+民,機+器等。
3. 語法學
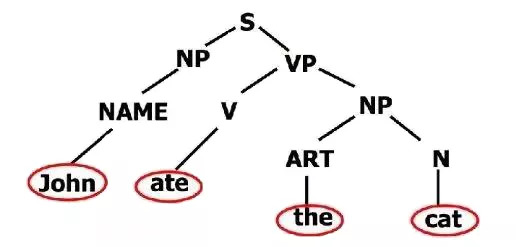
語法學(Syntax)問題:研究句子結構成分之間的相互關系和組成句子的序列。
為什么一句話可以這么說也可以那么說?
4. 語義學
語義學(Sementics)問題:研究如何從一個語句中詞的意義,以及這些詞在該語句中句法結構中的作用來推導出該語句的意義。
下面的話說了什么?
蘋果不吃了
這個人真牛
火燒圓明園/火燒驢肉
5. 語用學
語用學(Pragmatics)問題:研究在不同上下文中的語句的應用,以及上下文對語句理解所產生的影響。從狹義的語言學觀點看,語用學處理的是語言結構中有形式體現的那些語境。相反,語用學最寬泛的定義是研究語義學未能涵蓋的那些意義。
在語用學中最基本的一個概念是語境,它是專門研究語言的理解和使用的學問,它研究在特定場景中的特定話語,研究如何通明朝這個朝代更過語境來理解和使用。
下面話為什么這樣說?
火,火!
A:看看魚怎么樣了?B:我剛才翻了一下。
研究的主要內容
1. 機器翻譯
基于規則的機器翻譯方法認為翻譯的過程是需要對源語言的分析和源語言意義的表示,然后再生成等價的標語言的過程。根據翻譯過程的不同,規則方法可分為兩種主要方法:基于轉換的方法的翻譯過程包括三個階段:分析得到一種源語言的抽象表示;把源語言的抽象表示轉換為目標語言的抽象表示 ;由目標語言的抽象表示生成目標語言。基于中間語言的方法在對源語言分析后產生的是中間語言,而目標語言的生成是直接由這種中間語言開始的。
基于實例的機器翻譯本質是“以翻譯實例為基礎,基于相似原理的機器翻譯”,其利用的主要知識源是預處理過的雙語語料和翻譯詞典。基于實例的翻譯過程通常包括三步: 在翻譯實例庫中搜索匹配片段;確定相應的譯文片段;重新組合譯文片段以得到最終翻譯。
統計機器翻譯也是基于雙語語料庫的,但與基于實例的方法在翻譯過程中直接使用翻譯 實例不同,統計方法通過事先的訓練過程將雙語語料庫中隱含的翻譯知識抽象成統計模型, 而翻譯過程通常就是基于這些統計模型的解碼過程。
神經機器翻譯神經機器翻譯與傳統的統計機器翻譯不同,神經機器翻譯的目的是建立一個單一的神經網絡,可以聯合調整,以最大限度地提高翻譯性能。最近提出的用于神經機器翻譯的模型通常屬于編碼器-解碼器族,且將源語句編碼成固定長度向量,解碼器從該向量生成翻譯。
2. 信息檢索
信息檢索(Information retrieval):信息檢索也稱為情報檢索,就是利用計算機從大量文檔中找到符合用戶需要的相關信息。
面向多語言的信息檢索稱為跨語言的信息檢索,如google,baidu等。
早期的信息檢索系統采用“布爾查詢”的方法來進行全文檢索。這種方法無疑將構造一個合適的查詢的責任推到用戶身上。用戶必須詳細的規劃自己的查詢,其復雜程度不亞于編程語言。這種檢索方式并不提供任何的文檔相關性測度,對于文檔與查詢的評價就只有“匹配“、“不匹配”兩種而已。這兩點問題決定了布爾查詢不能被廣泛應用。但是,由于布爾檢索能夠給用戶提供更多的可控制性,今天我們仍然可以在搜索引擎的“高級搜索”中找到布爾查詢的身影。
對于大規模的語料庫,任何檢索都可能返回數量眾多的結果,因此對檢索結果進行排序是必須的。因此,一個好的信息檢索模型必須提供文檔相關性測度。一個好的測度應該使與用戶查詢需求最相關的那些結果,排在最前面,同時允許盡可能多的,與用戶查詢有一定關系的結果被包括進來。目前,最為常用的信息檢索模型有三種:-向量空間模型 (Vector Space Model, VSM)-概率模型 (Probabilistic Model) -推理網絡模型 (Inference Network Model)
3. 自動文摘
TextRank 算法是一種用于文本的基于圖的排序算法。其基本思想來源于谷歌的 PageRank算法,通過把文本分割成若干組成單元(單詞、句子)并建立圖模型, 利用投票機制對文本中的重要成分進行排序,僅利用單篇文檔本身的信息即可實現關鍵詞提取、文摘。
傳統的摘要生成系統大部分都是抽取型的,這類方法從給定的文章中,抽取關鍵的句子或者短語, 并重新拼接成一小段摘要,而不對原本的內容做創造性的修改。深度學習是一個生成方法,它會創造性的生成摘要。最新的方法是神經注意力模型(Neural attention model)。
4. 文檔分類
文檔分類:其目的就是利用計算機系統對大量的文檔按照一定的分類標準實現自動歸類。
文檔分類的方法有基于機器學習的方法(如svm,decision tree)和基于深度學習(如cnn,rnn)的方法。
流程:樣本處理 — 特征選擇 — 分類。
應用:圖書管理、內容管理、情感分析等。
5. 問答系統
問答系統(Question answer system):通過計算機對人提出的問題的理解,利用自動推理等手段,在有關知識資源中自動求解答案并作出相應的回答。問答技術有時與語音技術、人機交互技術等相結合,構成人機對話系統。
問答系統模型通常分為基于檢索的模型和基于生成的模型。
基于檢索的模型回答是提前定義的,使用規則引擎、正則匹配或者深度學習訓練好的分類器從數據庫中挑選一個最佳的回復。
基于生成的模型多使用深度學習的方法。最流行的方法是seq2seq attention model。
6. 文字識別
文字識別(Character Recognition):通過計算機系統對印刷體或手寫體等文字進行自動識別,將其轉換為計算機可以出來的電子文本。
傳統的文字識別方法就是特征工程+分類器的方法。深度學習的方法主要有rcnn,yolo等。
流程:預處理—特征提取和降維—分類器—后處理。
7. 語音識別
語音識別(Speech Recognition):將輸入計算機的語音信號轉換成書面語表示。
應用:文字錄入、人機通訊、語音翻譯等
難點:大量存在同音詞、近音詞、集外詞、又音等等。
輸入:美中貿易摩擦升級
識別結果:美中貿易摩擦生機
早期的語音識別系統主要采用隱馬爾科夫模型來建模。
現在的語音識別系統多采用end2end的方法。
8. 語音生成
語音生成(speech generate):利用計算機將書面語轉換為語音信號。
語音生成有兩個主要目標:可理解性(intelligibility)和自然感(naturalness)。可理解性是指合成音頻的清晰度,特別是聽話人能夠在多大程度上提取出原信息。自然感則描述了無法被可理解性直接獲取的信息,比如聽的整體容易程度、全局的風格一致性、地域或語言層面的微妙差異等等。
百度的 Deep Voice、Yoshua Bengio 團隊提出的 Char2Wav以及谷歌的 Tacotron均在語音生成方面表現突出。
面臨的困難
1. 語義歧義如:他說:“她這個真有意思 (funny)”。她說:“他這個怪有意思的 (funny)”。于是他們以為他們有意思 (wish),并讓他向她意思意思 (express)。他說:“我根本沒有那個意思 (thought)”!她也說:“你們這么說是什么意思 (intention)”?事后有人說:“真有意思 (funny)”。也有人說:“真沒意思 (nonsense)”。
2. 存在未知的語言現象 ? 新的詞匯,如專業術語、外來語、人名、機構名等 ? 新的含義,如打醬油、漲姿勢、藍瘦香菇、吃棗藥丸等 ? 新的用法和語句結構。在又語和網絡語中出現的“非規范”的語句結構。如“這屆人民不行”、“扎心了老鐵”。
發展趨勢
目前,人們主要通過兩種思路來進行自然語言處理,一種是基于規則的理性主義,另外一種是基于統計的經驗主義。現實的情況是,統計學習方法越來越受到重視,自然語言處理中更多地使用機器自動學習的方法來獲取語言知識。
深度學習在自然語言處理中的應用極大的促進了行業的發展。但是,即使使用深度學習,仍然有許多問題只能達到基本的要求,如問答系統、對話系統、對話翻譯等。
結語
如今,如何有效利用海量信息已成為信息技術發展的一個關鍵性問題。自然語言處理則無可避免地成為該領域長期發展的一個新的戰略制高點。路漫漫其修遠兮,NLP作為一個高度交叉的新興學科,不論是探究語言本質還是付諸實際應用,必定還會有令人期待的驚喜和異常快速的發展。
-
機器學習
+關注
關注
66文章
8306瀏覽量
131834 -
nlp
+關注
關注
1文章
481瀏覽量
21932
原文標題:深入機器學習之自然語言處理
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
語義理解和研究資源是自然語言處理的兩大難題
【推薦體驗】騰訊云自然語言處理
什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網監
工商網監
評論