 基于隱馬爾可夫模型( HMM )開發了一個駕駛行為預測模型
基于隱馬爾可夫模型( HMM )開發了一個駕駛行為預測模型
摘要-先進的駕駛員輔助系統( ADAS )的開發在預測駕駛行為的研究中起著重要作用。我們開發了一種基于隱馬爾可夫模型( HMM )的預測人類駕駛行為的方法。包括左/右車道變換和車道保持在內的三種不同的駕駛動作被建模為HMM的隱藏狀態。基于觀察(訓練),HMM方法能夠使用觀察到的序列來計算最可能的駕駛行為。此外,在建模過程中,觀察到的序列也用于HMM的訓練。為了提高模型的預測性能,我們提出了一種預濾波器將采集的信號量化為具有特定特征的觀測序列。
在本論文中,將討論并最終優化合適預過濾器的定義。這里最優性被定義為將車輛環境映射到量化狀態的預濾波器的最優段。結合基于HMM的精度、檢測和虛警率方面的相關結果,可以確定預濾波器的最佳參數集。利用真實人類駕駛行為的實驗數據(取自駕駛模擬器),可以得出結論,預過濾器的最佳定義可以提高檢測率和準確性,同時降低誤報率。駕駛行為預測的有效性已經通過與其他方法的比較得到了成功的證明
I介紹
駕駛員輔助系統是為了幫助人類駕駛員更好、更安全駕駛而開發的系統。典型的輔助駕駛系統側重于探測危險場景并發出警告從而避免交通事故。這類輔助系統的預測是基于諸如距離和車速等物理變量來計算的。這些物理變量描述了車輛狀態和行駛環境。雖然車輛狀態和駕駛環境與當前的駕駛安全評估相關,但最常見的事故原因與人類行為有關。因此,輔助駕駛系統應該幫助駕駛員檢測可能的不當行為。然而,遵循一般駕駛規則,司機通常會根據自己的駕駛經驗和習慣選擇最合適的操作。司機的駕駛行為被認為是個人的。因此,駕駛輔助系統應該基于對個體駕駛行為的分析進行調整,以提高交通安全并實現智能駕駛。個人駕駛行為受許多因素影響,包括當前環境條件、個人駕駛特征等。因此,駕駛員的意圖和下一次駕駛動作不能通過物理變量來簡單而直接地測量。
為了建立駕駛行為模型,一些方法已經被提出。例如,神經網絡( NN )模型已經被用于預測[ 1 ]高速公路上車輛跟馳的加速度分布。在[ 2 ]動態貝葉斯網絡( DBN )被用于估計和預測四向交叉路口的車輛跟蹤和變道的加速度以及轉彎率。在[ 3 ]中,通過使用特征函數來評估情境情境,預測交通參與者的下一個狀態,提出了一個完全概率模型。《[ 4 ]》的作者使用了一個模糊邏輯( FL )模型,該模型是由駕駛員根據經驗觀察到的高速信號交叉口的行為建立的。
在我們的研究中,使用了隱馬爾科夫模型( HMM )方法預測駕駛行為,該方法用于估計不可觀察狀態,不可觀測狀態可以通過基于期望最大化( EM )和最大似然估計( MLE )的觀測狀態來推斷,這是分別估計HMM參數和最可能隱藏狀態的標準方法[ 5 ] [ 6 ]。為了改進性能建模,必須定義觀察狀態的適當部分。實驗結果顯示,使用那些合適的觀察段范圍,可以提高駕駛行為預測模型的質量。
Ⅱ基于隱馬爾可夫模型的駕駛行為預測
隱馬爾可夫模型(HMM)已經被成功應用于語音識別和合成[7]、生物學中的DNA輪廓識別[8]以及視頻[9]中的人類行為識別等領域。如今,HMM的應用已經擴展到越來越多的研究領域,例如駕駛行為識別和預測。在[10]中,作者提出使用HMM來確定各種車輛操縱的駕駛員意圖。此外,HMM通常與其他算法一起使用。在[11]中,作者提出了一種混合狀態系統(HSS)-HMM框架,用于估計交叉口的駕駛員行為。駕駛員行為和車輛動力學被建模為HSS, HSS提供系統架構,HMM定義系統組件之間的關系,HMM和相關基本算法的詳細定義在[5]中描述。
HMM描述了兩個隨機過程之間的關系:一個由一組未觀察到的(隱藏的)狀態S = {S1,S2,...SN},其中N為無法直接測量的隱藏狀態的數量。另一個隨機過程由一組M個可觀察符號V ={V1,V2,...VM}。隱藏狀態和觀察符號位于,時間t分別被定義為Qt和Ot。因此,隱藏狀態序列是Q= {Q1,Q2,...QT},觀察序列是O = {O1,O2,...OT},其中T是序列的長度。使用HMM參數的序列可以通過分析觀察序列來確定未觀察到的狀態。
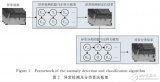
在我們的研究中,駕駛行為主要考慮車道變換。執行的駕駛操縱是隱藏狀態。它們包括左/右車道變換和正常車道保持,因此N = 3.駕駛行為預測模型可視為標準HMM,如圖1所示
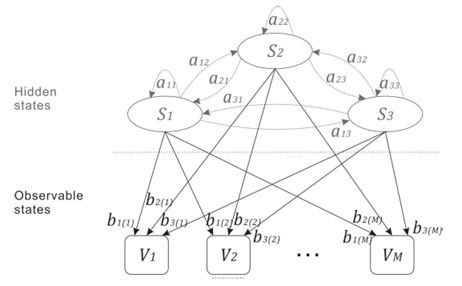
圖1.具有3種狀態的HMM模型
驅動行為表示為Si,觀察值Vk表示為下標k。該模型可以定義為一種系統,其中駕駛行為以狀態轉移概率ai j= P(Qt= Sj| Qt-1= Si),i,j [1,N]切換到另一個,這意味著從狀態Si移動到狀態Sj的概率。所有轉移概率ai j可以構成狀態轉移概率矩陣
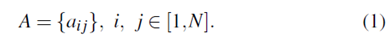
觀察概率bj ( k )定義了在時間t從狀態S j產生觀察Vk的概率,這意味著bj ( k )= P ( Ot= Vk| Qt= Sj)。相應的觀測概率分布矩陣表示為
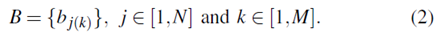
為了描述HMM,有必要使用初始概率分布,其指示在狀態Si中開始的概率,其中
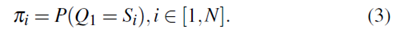
使用以上定義,完整的HMM可以定義為λ= ( A,B,π)。
為了實現基于HMM的駕駛行為預測,該過程必須分為兩部分:第一部分是模型的訓練,第二部分是估計最可能的隱藏狀態序列。為了訓練HMM,Baum - Welch算法(也稱為期望最大化)將被用來估計最大似然模型參數λ= ( A,B,π)。在給定的觀察序列O及其對應的隱藏狀態序列Q中,HMM λ的參數被計算和調整以最佳地擬合這兩個序列。基于保存的HMM λ,使用Viterbi算法計算具有最高概率的駕駛行為的最可能序列。
如前所述,隱藏狀態序列將由觀察序列確定。因此,選擇描述組成觀察狀態的當前狀況的參數是非常重要的。這些參數必須考慮到數據收集的可行性,并具備達到模型識別目的的能力。當司機在高速公路上行駛時,ego車輛和其他周圍車輛之間的關系是影響司機決策的主要因素。在我們的研究者中,與前方車輛的相對速度、ego車輛和周圍車輛之間的距離被選擇作為觀察變量,即時間t的觀察向量被定義為
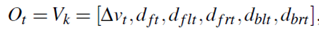
其中k∈[ 1,M ],M是觀察選擇的數量。表I給出了參數的細節。在我們的研究中,駕駛模擬器用于收集每個參數的數據。在現實世界中,這些參數將取自不同的傳感器,如照相機、雷達、激光雷達和超聲波。[12]
在駕駛過程中,所有觀察參數都被認為是可測量的。信號是動態的,隨時間變化。每個參數的改變將導致觀察向量的改變。這里假設通過預濾波實現的量化信號,這在汽車領域中是典型的,使用精度有限的相關電子設備。在預濾波器的輸出端,導出了以特征向量為特征的量化信號。通過使用特征向量,應該區分不同的駕駛情況。基于預濾波器,每個觀測參數的信號數據將被分成多個段。每個片段代表一個相應的觀察結果。因此,線段的范圍很重要,將被定義來描述觀察結果。使用這些分段范圍,可以處理和組合信號以形成HMM預測過程的特征。為了簡化建模過程,在這個貢獻中定義了一個預濾波器,它只使用兩個不同的范圍值,并將每個觀測參數分成三個部分。表I中顯示了每個觀測參數的左閾值和右閾值(即兩個范圍值)。顯然,觀測段范圍的值非常重要,因為它們隱含地定義了HMM訓練的觀測序列,并最終影響了精度。
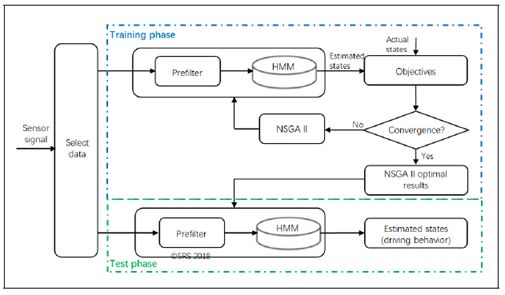
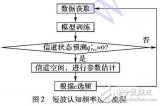
圖2.最佳預過濾器定義說明
一個簡單的方法是根據一般駕駛規則選擇一個通用預過濾器,例如在德國,50m是高速公路上兩個導向柱之間的相應距離。因此,距離的分段范圍值可以定義為50m和100 m,速度計上的間隔可以用來表示相對速度的范圍值,例如10公里/小時和20公里/小時。
預測過程的核心是通過HMM來實現的。使用給定的隱藏狀態序列及其相應的觀察序列,可以訓練HMM。因此,輸入到HMM的特征向量可以通過使用通用預濾波器來提取,這有助于確定最佳HMM并提高預測性能。出于這個原因,對于每個驅動器,可以生成具有個性化最佳預濾波器的HMM。
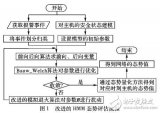
在圖2中,示出了產生最佳預過濾器的過程。為了定義最佳預過濾參數,使用非支配排序遺傳算法II ( NSGA - II )。NSGA - II源自NSGA,用于解決多目標優化問題( MOPs ) [ 16 ]。通過使用NSGA - II,使用不同的范圍值重復訓練HMM。考慮所有可能的范圍值,每個范圍從該參數的最小值變為最大值。確定每個觀測參數的最佳閾值(最佳預濾波器)以最小化目標函數。
準確度( ACC )、檢測率( DR )和虛警率( FAR )被廣泛用于評估分類器[ 13 ] [ 14 ]。
它們是基于真陽性( TP )、假陽性( FP )、真陰性( TN )以及假陰性( FN )數來計算的。為了解釋,舉例說明了一個混淆矩陣(圖3 )來描述向右改變車道的參數。真陽性( TP )表示

圖3.混淆矩陣的說明[車道改為右]
它們的計算基于真陽性(TP),誤報(FP),真陰性(TN)以及假陰性(FN)數。為了解釋,示出了混淆矩陣(圖3)作為示例來描述用于向右改變車道的參數。真陽性(TP)表示當估計的機動是正的時(向右改變車道)并且實際的也是正的事件的數量,對比度假陽性(FP)表示當估計的機動是正的時的事件的數量和實際值不相同,對于真假陰性(TN / FN)。 ACC,DR和FAR由[14]定義

如前所述,每個觀察參數(預濾波器)的左/右閾值是確定HMM訓練的觀察序列的臨界值,因此影響估計的狀態。 TP,FP,TN和FN的值將由估計的狀態定義,并最終影響ACC,DR和FAR值。在研究中,將針對前述ACC,DR和FAR參數的改進來選擇最佳預濾波器。因此,目標函數定義為
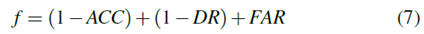
三種駕駛行為。
III.實驗結果
本節介紹了基于HMM的變道機動預測的實驗裝置和獲得的結果。使用所提出的模型,基于測量的變化和速度,預測了駕駛員的車道變換行為。為了提高預測性能,必須定義最佳預濾波器(特征參數)。
A.實驗設計
應用如圖4所示的專業駕駛模擬器SCANeRTMstudio來收集駕駛數據,該駕駛數據用于訓練和測試所提出的方法。該模擬器配備五個監視器,180度視野,基座固定駕駛員座椅,方向盤和踏板。三個后視鏡是決定改變車道所必需的,它們顯示在顯示器的相應位置上,駕駛模擬器的數據獲取頻率為20Hz。
圖4.駕駛模擬器,椅子動力學和控制,U DuE
駕駛場景基于高速公路駕駛場景,具有四個車道的兩個方向和模擬的交通環境。在駕駛期間,當前車緩慢行駛時,參與者可以執行超車操縱。超車后,參與者也可以回到最初的車道。從左到右改變車道的時間點由參與者決定。遵循德國的交通規則,只允許從左車道超車。共招募了9名年齡介乎25至38歲的參與者。他們都持有有效的駕駛執照。每位參與者進行了約25分鐘的駕駛。
1)數據處理階段:為了將數據標記為隱藏狀態序列以及觀察序列,需要對信號數據進行分類和處理。此貢獻中的隱藏狀態僅考慮更改車道。在駕駛模擬中,可以通過車輛中心點的位置確定當前車道i。因此,通過在不同時間比較車道i的值,可以確定車輛的車道變換。當當前車道的值與最后時刻it-1相同時,定義車道保持。當該值增加時定義向左變換的車道,并且當減小車道時向右變換車道。在實驗中,駕駛員決定改變車道(轉向燈)的時間已經在車道變換之前的2到3秒之間,平均值為2.5秒。因此,將考慮在行動之前2.5秒發生作為駕駛行為的車道變化。然而,如果自我車輛通過駕駛與白線重疊,則可能產生一些車道變換數據,并且這些數據不反映駕駛員的真實行為。因此,有必要去除這些干擾數據以獲得準確的實驗數據。表II給出了每種隱藏狀態的符號及其具體描述。
觀察載體可以通過預濾器分類并處理成序列。如第II部分所述,將使用最大ACC,最大DR以及最小FAR確定最佳預濾波器。因此,它應該用于改善駕駛行為預測的性能。為了證明這一點,使用兩個不同的預濾器對觀察向量進行分類。一個預過濾器正在使用這些最佳段。另一種是使用一組通用分段范圍進行比較,通過比較實驗數據給出,例如平均值,最小安全距離等。
2)訓練階段:在本實驗中,每個實驗數據集分為10個子集,這10個子集中的7個被認為是訓練數據集,其他被認為是測試數據集。每個訓練數據集的位置是不同的,并且不重復,例如,第一訓練數據集從第一至第七子集中選擇,第二訓練數據集從第二至第八子集中選擇,依此類推。每個訓練和測試數據集必須包含不同的換道操作。訓練數據集可用于估計HMM參數。利用該HMM參數,可以計算隱藏狀態。在下一步驟中,將比較來自訓練數據的隱藏狀態序列和由HMM模型計算的隱藏狀態序列,以檢查對應關系并計算ACC,DR和FAR。然后,計算目標函數(7)。然后,通過關于上述目標函數的優化來定義預濾波器值。該預濾器及其相應的HMM模型將用于測試階段。
3) 測試階段:每個特定于驅動程序的測試數據集必須與在訓練階段使用的數據相關。 因此,已經在訓練階段計算了每個測試數據集的最佳預濾波器和相應的HMM模型。最可能的駕駛行為將通過使用相應的HMM來確定。通過計算和實際駕駛行為之間的比較,可以評估準確性。
B評估
為了評估所提出的方法,將通過使用相同的訓練數據集和不同的預濾波器來學習HMM。在選擇最佳預濾器之后,使用通用預濾器與最佳預濾器比較該方法。將比較計算的和實際的駕駛行為以評估相似性。數據集#5的測試階段的結果如圖5所示。這里隱藏狀態(駕駛行為)作為模擬時間的函數給出。隱藏狀態的符號如表II所示。綠色,藍色和紅色線分別表示使用一般預濾波器的原始狀態,計算的隱藏狀態,以及使用最佳預濾波器計算的隱藏狀態。結果表明,優化的基于預過濾器的HMM預測的狀態最適合原始狀態。藍線錯誤計算隱藏狀態的數量多于紅色。
圖5. HMM驗證結果[測試數據集#5]
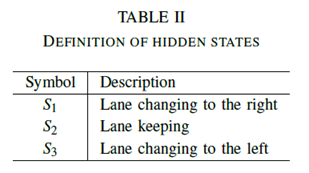
通過選擇數據集#5的一般和最佳預濾波器的ACC,DR和FAR的百分比示于表III中。從得到的結果可以清楚地看出,使用最佳預濾器,總體ACC分別從73.4%(訓練)和68.8%(測試)增加到91.9%和87.5%。類似地,使用最佳預濾器,DR高于使用通用預濾器。
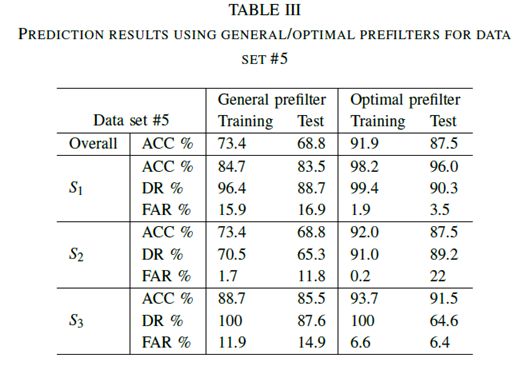
在三種不同演習的FAR中,右側車道變換的訓練和測試階段的FAR分別為15.9%和16.9%,優化后,FAR降至1.9%和3.5%。FAR的值可以由等式(6)定義。可以看出,較高的FAR值是由圖3中定義的較高的分子FP值(假陽性)產生的。對于向右變化的機動車道,FP是真實狀態時的事件數,估計的狀態是右邊的車道變換。這些結果也可以從圖5中檢測到。這里S1定義了向右的車道變換。可以觀察到,在若干情況下,估計的狀態被錯誤地計算為S1。上述描述性問題更常出現在藍線(使用一般預濾波器)而不是紅線(使用最佳預濾波器)。可以得出結論,使用合適的預濾器可以改善預測結果。即使通過,在實驗期間仍然可以找到一些例外,例如,車道保持(測試)的優化FAR值比預設值(大約高10%)更差。然而,考慮到所有情況的總體結果由于預濾器的優化而得到改善。
圖6. 9個測試數據集的平均ACC、DR和FAR由不同模型實現
為了驗證模型在駕駛行為預測方面的有效性,使用其他算法進行比較。人工神經網絡(ANN)和支持向量機(SVM)等典型算法用于建立駕駛行為模型。在[17]中,作者建立了三個模型,包括ANN,SVM,組合ANN和SVM(ANN-SVM)來估計公路車道下降時的車道變換行為。這兩種算法的優點是它們不需要數據處理。為了評估這些方法,將實際駕駛行為與所有數據集的估計駕駛行為進行比較。然后,計算每個駕駛行為的ACC,DR和FAR。每組的相應速率如圖6所示。從結果(圖6)可以說,在預濾波器的最佳選擇之后,所有ACC,DR以及(1-FAR)值都較大超過80%。盡管仍然可以找到一些例外,例如ANN-SVM(保守)的一些ACC高于最佳HMM,但是DR的值減小。為了進一步評估駕駛行為預測的性能,接收器操作特性(ROC)圖如圖7所示。從結果可以看出,使用最優HMM,DR最高,FAR最低。方法。因此,最佳HMM在所有模型中都具有最佳性能。
圖7.不同模型的ROC圖
IV.總結和結論
在該研究中,基于隱馬爾可夫模型( HMM )開發了一個駕駛行為預測模型。包括左/右車道變換和車道保持在內的三種不同的駕駛動作被建模為HMM的隱藏狀態,并使用駕駛模擬器在高速公路場景中進行模擬。基于HMM,可以通過觀察狀態推斷出不可觀察的狀態。所考慮的方法基于這樣的假設,即相關的物理變量被離散成若干段,以考慮典型的傳感器特性。通過尋找最佳預濾波器,而不是優化HMM模型,考慮并改進了HMM的預測性能。在該方法中,基于從9個不同測試驅動程序獲得的數據,驗證了該方法。每次都選擇不同位置的子集進行訓練和測試。在相同的實驗數據集上,使用觀察段范圍的一般(預先設置的)值和最終(優化的)值來比較HMM模型。
最終獲得的結果顯示HMM識別駕駛員行為的能力顯著提高。結果表明,除了分類器(這里:HMM )之外,組合的預設和適應策略對該方法的統計特性有顯著影響。使用最佳參數的HMM模型提高了檢測率和準確性,同時降低了誤報率。通過選擇最佳預過濾參數,預測性能可以得到改善,這一點已在該研究中得到成功證明。
-
濾波器
+關注
關注
158文章
7596瀏覽量
176603 -
神經網絡
+關注
關注
42文章
4717瀏覽量
100015
原文標題:基于改進的HMM方法預測駕駛員行為
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于隱馬爾可夫模型的音頻自動分類

基于隱馬爾可夫預測的功率博弈機制






 工商網監
工商網監
評論