 一種從視頻中學習技能的框架(skills from videos,SFV)
一種從視頻中學習技能的框架(skills from videos,SFV)
無論是日常簡單的動作還是令人驚嘆的雜技,人類可以通過觀察別人的動作學會一系列驚人的技能。今天如果你想要學習新的技能,像YouTube一樣的視頻網站上擁有豐富的資源供你學習。
但遺憾的是,對于機器來說通過大量的視覺數據來進行技能學習依然面臨著很大的挑戰。目前絕大多數的模仿學習需要精確的動作記錄,例如精密的動作捕捉系統。但獲取動作捕捉數據很多時候十分復雜,極大的依賴于設備,將環境局限于于室內無遮擋的場景,這限制了可以被記錄的技能類型。那么如果存在一個智能體可以從視頻中學習技能就好了!
在這一工作中,伯克利BAIR的研究人員提出了一種從視頻中學習技能的框架(skills from videos,SFV),結合了前沿的計算機視覺和強化學習技術構建的系統可以從視頻中學習種類繁多的技能,包括后空翻和很滾翻等高難度動作。同時智能體還學會了在仿真物理環境中復現這些技能的策略,而無需任何的手工位姿標記。
SFV問題在計算機圖形學領域一直受到廣泛關注,先前的技術主要依靠手工的控制結構來限制可以產生的行為,這使得主體可以學習到的技能非常有限,同時表現出來的動作也很不自然。近年來,深度學習技術在視覺模仿鄰域取得了很大的進展,包括Atari游戲和簡單的機器人任務都取得的不錯的成績,但這些任務在所描述的與主體運行的環境只有些許的不同,并且所得到的結果也只是相對簡單的動力學過程。
基于深度學習視覺模仿的Atrai和簡單的機器人任務
框 架
研究人員提出的系統由三個部分構成:位姿估計、運動重建和運動模仿。
-首先利用輸入的視頻實現位姿估計,從每一幀中預測出主角的位姿;
-隨后在運動重建階段,將上一階段預測的位姿進行銜接得到參考的運動過程,并修正一些在位姿估計階段的缺陷;
-最終將參考運動過程傳輸給模仿階段,模擬的主體將會利用強化學習來訓練模仿這些動作。
這一框架主要包括位姿估計、運動重建和運動模仿三個過程
位姿估計
研究人員利用基于視覺的運動估計器來預測給定視頻中主角的在每一幀的運動。位姿估計器利用人體網格恢復中的方法來構建,利用了弱監督對抗的方法訓練從單目圖像中預測出位姿。
從視頻中恢復人體位姿
雖然在訓練位姿估計器的時候需要進行位姿標記,但在訓練完成后它就可以用于新的圖像而無需額外的標記。
基于視覺的位姿估計器從每一幀中預測出主角的動作
運動重建
由于基于單幀圖像預測的位姿是不連續的,在上圖中可以看到明顯不連貫的動作。同時由于估計器某些錯誤估計的存在會產生一系列奇異結果造成估計的位姿出現跳變。這會造成智能體在物理上無法模仿。所以運動重建的目的就在于減輕上述原因帶來的影響,得到更為符合物理實際的參考運動,以便于智能體模擬。所以研究人員提出了下面的目標函數來優化新的參考運動:
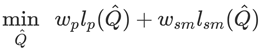
其中保證了參考運動與原始運動接近,而則保證了相鄰幀之間運動相近以便得到更加平滑的運動結果,這兩個損失對應了不同的權重w。
經過優化后的參考運動結果如下,可以看到明顯地改善了位姿之間的連續性,讓生成的運動估計更為平滑。
運動模仿
在獲取了參考運動序列后,就可以訓練智能體來模擬這些技能了。研究人員使用了強化學習來訓練智能體學習這些技能,其中獎勵函數也十分簡單,主要用于鼓勵智能體采取不斷減小t時刻與每一幀參考運動位姿之間差距的策略。
雖然簡單,但得到了很好的結果。智能體學會了一系列高難度動作,從不同的技能視頻片段中學會了不同的技能。
來一個側手翻
再來一個前空翻
鯉魚打挺也不賴
嘿!看我的回旋踢!
結果
在訓練完成后,這一智能體可以學會從youtube中收集的20中不同的技能。
能唱能跳、能翻滾跳躍、武術也不在話下。
甚至對于與視頻中主角人類在形態上很不相似的Atlas機器,這一策略依然十分有效。
研究人員同時還發現,模擬智能體學習到的行為具有很強的泛化性。在新的環境中依舊可以學習如何適應崎嶇的地面。
運動平滑而又穩定
這一研究取得良好效果的關鍵在于,將SFV這一復雜問題分解成多個可控的部分,并選取合適的方法來解決這些問題,并將他們有機高效的結合起來。然而這一領域依舊面臨著很大挑戰,下面就是一個學習失敗的例子:
但這一工作依舊表明,充分合理地利用已有的技術我們可以在充滿挑戰的問題中得到不錯的結果。希望這一研究可以啟發小伙伴們對于相關領域的研究。
-
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
智能體
+關注
關注
1文章
135瀏覽量
10570 -
Youtube
+關注
關注
0文章
143瀏覽量
15519
原文標題:看看Youtube就能學會雜技,伯克利新算法讓智能體學會高難度動作
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從入門到精通,你不可錯過的CCES進階十大培訓視頻
一種基于圖像平移的目標檢測框架
一種基于Deep U-Net的多任務學習框架
一種基于USB2.0的視頻圖像處理芯片設計
一種用深度學習框架對普通視頻進行流暢穩定的慢動作回放的技術

實現機器學習的一種重要框架是深度學習
最新機器學習開源項目Top10
一種基于框架特征的共指消解方法

一種用于交通流預測的深度學習框架

一個通用的時空預測學習框架






 工商網監
工商網監
評論