") 理解Batch Normalization中Batch所代表具體含義的知識基礎(chǔ)
理解Batch Normalization中Batch所代表具體含義的知識基礎(chǔ)
Batch Normalization(簡稱BN)自從提出之后,因為效果特別好,很快被作為深度學(xué)習(xí)的標(biāo)準(zhǔn)工具應(yīng)用在了各種場合。BN大法雖然好,但是也存在一些局限和問題,諸如當(dāng)BatchSize太小時效果不佳、對RNN等動態(tài)網(wǎng)絡(luò)無法有效應(yīng)用BN等。針對BN的問題,最近兩年又陸續(xù)有基于BN思想的很多改進Normalization模型被提出。BN是深度學(xué)習(xí)進展中里程碑式的工作之一,無論是希望深入了解深度學(xué)習(xí),還是在實踐中解決實際問題,BN及一系列改進Normalization工作都是繞不開的重要環(huán)節(jié)。
一. 從Mini-Batch SGD說起
我們先從Mini-Batch SGD的優(yōu)化過程講起,因為這是下一步理解Batch Normalization中Batch所代表具體含義的知識基礎(chǔ)。
我們知道,SGD是無論學(xué)術(shù)圈寫文章做實驗還是工業(yè)界調(diào)參跑模型最常用的模型優(yōu)化算法,但是有時候容易被忽略的一點是:一般提到的SGD是指的Mini-batch SGD,而非原教旨意義下的單實例SGD。
圖1. Mini-Batch SGD 訓(xùn)練過程(假設(shè)Batch Size=2)
所謂“Mini-Batch”,是指的從訓(xùn)練數(shù)據(jù)全集T中隨機選擇的一個訓(xùn)練數(shù)據(jù)子集合。假設(shè)訓(xùn)練數(shù)據(jù)集合T包含N個樣本,而每個Mini-Batch的Batch Size為b,于是整個訓(xùn)練數(shù)據(jù)可被分成N/b個Mini-Batch。在模型通過SGD進行訓(xùn)練時,一般跑完一個Mini-Batch的實例,叫做完成訓(xùn)練的一步(step),跑完N/b步則整個訓(xùn)練數(shù)據(jù)完成一輪訓(xùn)練,則稱為完成一個Epoch。完成一個Epoch訓(xùn)練過程后,對訓(xùn)練數(shù)據(jù)做隨機Shuffle打亂訓(xùn)練數(shù)據(jù)順序,重復(fù)上述步驟,然后開始下一個Epoch的訓(xùn)練,對模型完整充分的訓(xùn)練由多輪Epoch構(gòu)成(參考圖1)。
在拿到一個Mini-Batch進行參數(shù)更新時,首先根據(jù)當(dāng)前Mini-Batch內(nèi)的b個訓(xùn)練實例以及參數(shù)對應(yīng)的損失函數(shù)的偏導(dǎo)數(shù)來進行計算,以獲得參數(shù)更新的梯度方向,然后根據(jù)SGD算法進行參數(shù)更新,以此來達到本步(Step)更新模型參數(shù)并逐步尋優(yōu)的過程。
圖2. Mini-Batch SGD優(yōu)化過程
具體而言,如果我們假設(shè)機器學(xué)習(xí)任務(wù)的損失函數(shù)是平方損失函數(shù):
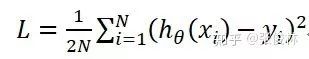
那么,由Mini-Batch內(nèi)訓(xùn)練實例可得出SGD優(yōu)化所需的梯度方向為:
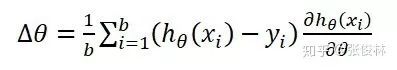

根據(jù)梯度方向即可利用標(biāo)準(zhǔn)SGD來更新模型參數(shù):
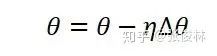
其中,η是學(xué)習(xí)率。
由上述過程(參考圖2)可以看出,對于Mini-Batch SGD訓(xùn)練方法來說,為了能夠參數(shù)更新必須得先求出梯度方向,而為了能夠求出梯度方向,需要對每個實例得出當(dāng)前參數(shù)下映射函數(shù)的預(yù)測值,這意味著如果是用神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)映射函數(shù)h_θ的話,Mini-Batch內(nèi)的每個實例需要走一遍當(dāng)前的網(wǎng)絡(luò),產(chǎn)生當(dāng)前參數(shù)下神經(jīng)網(wǎng)絡(luò)的預(yù)測值,這點請注意,這是理解后續(xù)Batch Normalization的基礎(chǔ)。
至于Batch Size的影響,目前可以實驗證實的是:batch size 設(shè)置得較小訓(xùn)練出來的模型相對大batch size訓(xùn)練出的模型泛化能力更強,在測試集上的表現(xiàn)更好,而太大的batch size往往不太Work,而且泛化能力較差。但是背后是什么原因造成的,目前還未有定論,持不同看法者各持己見。因為這不是文本的重點,所以先略過不表。
二.Normalization到底是在做什么?
Normalization的中文翻譯一般叫做“規(guī)范化”,是一種對數(shù)值的特殊函數(shù)變換方法,也就是說假設(shè)原始的某個數(shù)值是x,套上一個起到規(guī)范化作用的函數(shù),對規(guī)范化之前的數(shù)值x進行轉(zhuǎn)換,形成一個規(guī)范化后的數(shù)值,即:
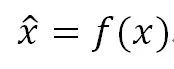
所謂規(guī)范化,是希望轉(zhuǎn)換后的數(shù)值x ?滿足一定的特性,至于對數(shù)值具體如何變換,跟規(guī)范化目標(biāo)有關(guān),也就是說f()函數(shù)的具體形式,不同的規(guī)范化目標(biāo)導(dǎo)致具體方法中函數(shù)所采用的形式不同。
其實我們生活中也有很多類似的規(guī)范化操作,知乎里面有個熱帖,主題是:“為什么人大附中的學(xué)生那么愛穿校服?”,里面有人打趣地問:“請問人大附中的學(xué)生洗澡的時候脫不脫校服?”。這個問題我回答不了,要我猜大概率夏天洗澡的時候是會脫的,要不然洗澡的時候天太熱人受不了,冬天則未必,穿著洗可能更保暖。跑題了,其實我想說的是:學(xué)校要求學(xué)生穿校服就是一種典型的規(guī)范化操作,學(xué)校的規(guī)范化目標(biāo)是要求學(xué)生著裝整齊劃一,顯得干練有風(fēng)貌,所以定義了一個規(guī)范化函數(shù):
就是說不論哪個學(xué)生,不論你平常的著裝變量x=”香奈兒”還是x=“麻袋片”,經(jīng)過這個規(guī)范化函數(shù)操作,統(tǒng)一都換成校服。這樣就達到了學(xué)校的規(guī)范化目的。
圖3. 神經(jīng)元
在介紹深度學(xué)習(xí)Normalization前,我們先普及下神經(jīng)元的活動過程。深度學(xué)習(xí)是由神經(jīng)網(wǎng)絡(luò)來體現(xiàn)對輸入數(shù)據(jù)的函數(shù)變換的,而神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)單元就是網(wǎng)絡(luò)神經(jīng)元,一個典型的神經(jīng)元對數(shù)據(jù)進行處理時包含兩個步驟的操作(參考圖3):
步驟一:對輸入數(shù)據(jù)進行線性變換,產(chǎn)生凈激活值
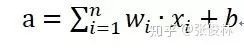
其中,x是輸入,w是權(quán)重參數(shù),b是偏置,w和b是需要進過訓(xùn)練學(xué)習(xí)的網(wǎng)絡(luò)參數(shù)。
步驟二:套上非線性激活函數(shù),神經(jīng)網(wǎng)絡(luò)的非線性能力來自于此,目前深度學(xué)習(xí)最常用的激活函數(shù)是Relu函數(shù)x=Relu(a)。
如此一個神經(jīng)元就完成了對輸入數(shù)據(jù)的非線性函數(shù)變換。這里需要強調(diào)下,步驟一的輸出一般稱為凈激活(Net Activation),第二步驟經(jīng)過激活函數(shù)后得到的值為激活值。為了描述簡潔,本文后續(xù)文字中使用激活的地方,其實指的是未經(jīng)激活函數(shù)的凈激活值,而非一般意義上的激活,這點還請注意。
至于深度學(xué)習(xí)中的Normalization,因為神經(jīng)網(wǎng)絡(luò)里主要有兩類實體:神經(jīng)元或者連接神經(jīng)元的邊,所以按照規(guī)范化操作涉及對象的不同可以分為兩大類,一類是對第L層每個神經(jīng)元的激活值或者說對于第L+1層網(wǎng)絡(luò)神經(jīng)元的輸入值進行Normalization操作,比如BatchNorm/LayerNorm/InstanceNorm/GroupNorm等方法都屬于這一類;
另外一類是對神經(jīng)網(wǎng)絡(luò)中連接相鄰隱層神經(jīng)元之間的邊上的權(quán)重進行規(guī)范化操作,比如Weight Norm就屬于這一類。廣義上講,一般機器學(xué)習(xí)里看到的損失函數(shù)里面加入的對參數(shù)的的L1/L2等正則項,本質(zhì)上也屬于這第二類規(guī)范化操作。L1正則的規(guī)范化目標(biāo)是造成參數(shù)的稀疏化,就是爭取達到讓大量參數(shù)值取得0值的效果,而L2正則的規(guī)范化目標(biāo)是有效減小原始參數(shù)值的大小。有了這些規(guī)范目標(biāo),通過具體的規(guī)范化手段來改變參數(shù)值,以達到避免模型過擬合的目的。
本文主要介紹第一類針對神經(jīng)元的規(guī)范化操作方法,這是目前DNN做Normalization最主流的做法。
圖4. Normalization加入的位置
那么對于第一類的Normalization操作,其在什么位置發(fā)揮作用呢?目前有兩種在神經(jīng)元中插入Normalization操作的地方(參考圖4),第一種是原始BN論文提出的,放在激活函數(shù)之前;另外一種是后續(xù)研究提出的,放在激活函數(shù)之后,不少研究表明將BN放在激活函數(shù)之后效果更好。本文在講解時仍然遵循BN原始論文,后續(xù)講解都可以看成是將Normalization操作放在激活函數(shù)之前進行。
對于神經(jīng)元的激活值來說,不論哪種Normalization方法,其規(guī)范化目標(biāo)都是一樣的,就是將其激活值規(guī)整為均值為0,方差為1的正態(tài)分布。即規(guī)范化函數(shù)統(tǒng)一都是如下形式:
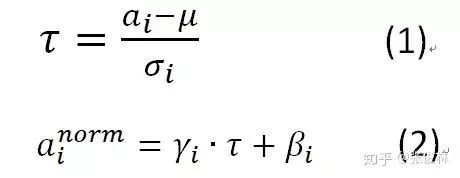
寫成兩步的模式是為了方便講解,如果寫成一體的形式,則是如下形式:
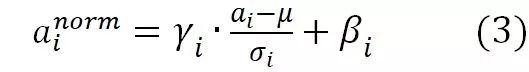
其中,a_i為某個神經(jīng)元原始激活值,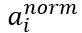 ?為經(jīng)過規(guī)范化操作后的規(guī)范后值。整個規(guī)范化過程可以分解為兩步,第一步參考公式(1),是對激活值規(guī)整到均值為0,方差為1的正態(tài)分布范圍內(nèi)。其中,μ是通過神經(jīng)元集合S(至于S如何選取讀者可以先不用關(guān)注,后文有述)中包含的m個神經(jīng)元各自的激活值求出的均值,即:
?為經(jīng)過規(guī)范化操作后的規(guī)范后值。整個規(guī)范化過程可以分解為兩步,第一步參考公式(1),是對激活值規(guī)整到均值為0,方差為1的正態(tài)分布范圍內(nèi)。其中,μ是通過神經(jīng)元集合S(至于S如何選取讀者可以先不用關(guān)注,后文有述)中包含的m個神經(jīng)元各自的激活值求出的均值,即:
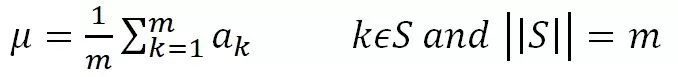
為根據(jù)均值和集合S中神經(jīng)元各自激活值求出的激活值標(biāo)準(zhǔn)差:
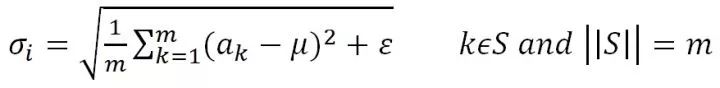
其中,ε是為了增加訓(xùn)練穩(wěn)定性而加入的小的常量數(shù)據(jù)。
第二步參考公式(2),主要目標(biāo)是讓每個神經(jīng)元在訓(xùn)練過程中學(xué)習(xí)到對應(yīng)的兩個調(diào)節(jié)因子,對規(guī)范到0均值,1方差的值進行微調(diào)。因為經(jīng)過第一步操作后,Normalization有可能降低神經(jīng)網(wǎng)絡(luò)的非線性表達能力,所以會以此方式來補償Normalization操作后神經(jīng)網(wǎng)絡(luò)的表達能力。
目前神經(jīng)網(wǎng)絡(luò)中常見的第一類Normalization方法包括Batch Normalization/Layer Normalization/Instance Normalization和Group Normalization,BN最早由Google研究人員于2015年提出,后面幾個算法算是BN的改進版本。不論是哪個方法,其基本計算步驟都如上所述,大同小異,最主要的區(qū)別在于神經(jīng)元集合S的范圍怎么定,不同的方法采用了不同的神經(jīng)元集合定義方法。
為什么這些Normalization需要確定一個神經(jīng)元集合S呢?原因很簡單,前面講過,這類深度學(xué)習(xí)的規(guī)范化目標(biāo)是將神經(jīng)元的激活值限定在均值為0方差為1的正態(tài)分布中。而為了能夠?qū)W(wǎng)絡(luò)中某個神經(jīng)元的激活值a_i規(guī)范到均值為0方差為1的范圍,必須有一定的手段求出均值和方差,而均值和方差是個統(tǒng)計指標(biāo),要計算這兩個指標(biāo)一定是在一個集合范圍內(nèi)才可行,所以這就要求必須指定一個神經(jīng)元組成的集合,利用這個集合里每個神經(jīng)元的激活來統(tǒng)計出所需的均值和方差,這樣才能達到預(yù)定的規(guī)范化目標(biāo)。
圖5. Normalization具體例子
圖5給出了這類Normalization的一個計算過程的具體例子,例子中假設(shè)網(wǎng)絡(luò)結(jié)構(gòu)是前向反饋網(wǎng)絡(luò),對于隱層的三個節(jié)點來說,其原初的激活值為[0.4,-0.6,0.7],為了可以計算均值為0方差為1的正態(tài)分布,劃定集合S中包含了這個網(wǎng)絡(luò)中的6個神經(jīng)元,至于如何劃定集合S讀者可以先不用關(guān)心,此時其對應(yīng)的激活值如圖中所示,根據(jù)這6個激活值,可以算出對應(yīng)的均值和方差。有了均值和方差,可以利用公式3對原初激活值進行變換,如果r和b被設(shè)定為1,那么可以得到轉(zhuǎn)換后的激活值[0.21,-0.75,0.50],對于新的激活值經(jīng)過非線性變換函數(shù)比如RELU,則形成這個隱層的輸出值[0.21,0,0.50]。這個例子中隱層的三個神經(jīng)元在某刻進行Normalization計算的時候共用了同一個集合S,在實際的計算中,隱層中的神經(jīng)元可能共用同一個集合,也可能每個神經(jīng)元采用不同的神經(jīng)元集合S,并非一成不變,這點還請留心與注意。
針對神經(jīng)元的所有Normalization方法都遵循上述計算過程,唯一的不同在于如何劃定計算統(tǒng)計量所需的神經(jīng)元集合S上。讀者可以自己思考下,如果你是BN或者其它改進模型的設(shè)計者,那么你會如何選取集合S?
三. Batch Normalization如何做?
我們知道,目前最常用的深度學(xué)習(xí)基礎(chǔ)模型包括前向神經(jīng)網(wǎng)絡(luò)(MLP),CNN和RNN。目前BN在這些基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)都有嘗試,總體而言,BN在MLP和CNN是非常成功的,在RNN上效果不明顯。下面我們分述前向神經(jīng)網(wǎng)絡(luò)以及CNN中如何應(yīng)用BN,然后談?wù)凚N面臨的一些困境。正是這些困境引發(fā)了后續(xù)的一系列改進模型的提出。
3.1 前向神經(jīng)網(wǎng)絡(luò)中的BN
圖6. 前向神經(jīng)網(wǎng)絡(luò)中的BatchNorm
對于前向神經(jīng)網(wǎng)絡(luò)來說,BatchNorm在計算隱層某個神經(jīng)元k激活的規(guī)范值的時候,對應(yīng)的神經(jīng)元集合S范圍是如何劃定呢?圖6給出了示意。因為對于Mini-Batch訓(xùn)練方法來說,根據(jù)Loss更新梯度使用Batch中所有實例來做,所以對于神經(jīng)元k來說,假設(shè)某個Batch包含n個訓(xùn)練實例,那么每個訓(xùn)練實例在神經(jīng)元k都會產(chǎn)生一個激活值,也就是說Batch中n個訓(xùn)練實例分別通過同一個神經(jīng)元k的時候產(chǎn)生了n個激活值,BatchNorm的集合S選擇入圍的神經(jīng)元就是這n個同一個神經(jīng)元被Batch不同訓(xùn)練實例激發(fā)的激活值。劃定集合S的范圍后,Normalization的具體計算過程與前文所述計算過程一樣,采用公式3即可完成規(guī)范化操作。
3.2 CNN網(wǎng)絡(luò)中的BN
了解了前向神經(jīng)網(wǎng)絡(luò)中的BatchNorm ,接下來介紹CNN中的BatchNorm,讀者可以先自行思考下如果由你來主導(dǎo)設(shè)計,在CNN中究竟應(yīng)該如何確定神經(jīng)元集合S的勢力范圍。
我們知道,常規(guī)的CNN一般由卷積層、下采樣層及全連接層構(gòu)成。全連接層形式上與前向神經(jīng)網(wǎng)絡(luò)是一樣的,所以可以采取前向神經(jīng)網(wǎng)絡(luò)中的BatchNorm方式,而下采樣層本身不帶參數(shù)所以可以忽略,所以CNN中主要關(guān)注卷積層如何計算BatchNorm。
圖7. CNN中的卷積核
CNN中的某個卷積層由m個卷積核構(gòu)成,每個卷積核對三維的輸入(通道數(shù)*長*寬)進行計算,激活及輸出值是個二維平面(長*寬),對應(yīng)一個輸出通道(參考圖7),由于存在m個卷積核,所以輸出仍然是三維的,由m個通道及每個通道的二維平面構(gòu)成。
圖8. CNN中的BatchNorm過程
那么在卷積層中,如果要對通道激活二維平面中某個激活值進行Normalization操作,怎么確定集合S的范圍呢?圖8給出了示意圖。類似于前向神經(jīng)網(wǎng)絡(luò)中的BatchNorm計算過程,對于Mini-Batch訓(xùn)練方法來說,反向傳播更新梯度使用Batch中所有實例的梯度方向來進行,所以對于CNN某個卷積層對應(yīng)的輸出通道k來說,假設(shè)某個Batch包含n個訓(xùn)練實例,那么每個訓(xùn)練實例在這個通道k都會產(chǎn)生一個二維激活平面,也就是說Batch中n個訓(xùn)練實例分別通過同一個卷積核的輸出通道k的時候產(chǎn)生了n個激活平面。假設(shè)激活平面長為5,寬為4,則激活平面包含20個激活值,n個不同實例的激活平面共包含20*n個激活值。那么BatchNorm的集合S的范圍就是由這20*n個同一個通道被Batch不同訓(xùn)練實例激發(fā)的激活平面中包含的所有激活值構(gòu)成(對應(yīng)圖8中所有標(biāo)為藍色的激活值)。劃定集合S的范圍后,激活平面中任意一個激活值都需進行Normalization操作,其Normalization的具體計算過程與前文所述計算過程一樣,采用公式3即可完成規(guī)范化操作。這樣即完成CNN卷積層的BatchNorm轉(zhuǎn)換過程。
圖9. CNN中Batch Norm的另外一種角度的理解
描述起來似乎有些復(fù)雜,但是從概念上,其實可以把CNN中的卷積層想象成前向神經(jīng)網(wǎng)絡(luò)中的一個隱層,然后把對應(yīng)的某個卷積核想象成MLP隱層中的一個神經(jīng)元節(jié)點,無非其輸出是個二維激活平面而不像MLP的神經(jīng)元輸出是一個激活值,另外一個不同是這個神經(jīng)元覆蓋的輸入部分不同,CNN的卷積核是局部覆蓋輸入,通過滑動窗口來實現(xiàn)輸入的全覆蓋,而MLP的神經(jīng)元則是一步到位全局覆蓋輸入而已(參考圖9示意)。如果從這個角度思考CNN和MLP中的BatchNorm的話,其實兩者的做法是一致的。
從理論上講,類似的BatchNorm操作也可以應(yīng)用在RNN上,事實上也有不少研究做了嘗試,但是各種實驗證明其實這么做沒什么用,所以本文就不展開講RNN中的BN了。
BatchNorm目前基本已經(jīng)成為各種網(wǎng)絡(luò)(RNN除外)的標(biāo)配,主要是因為效果好,比如可以加快模型收斂速度,不再依賴精細的參數(shù)初始化過程,可以調(diào)大學(xué)習(xí)率等各種方便,同時引入的隨機噪聲能夠起到對模型參數(shù)進行正則化的作用,有利于增強模型泛化能力。
但是,BatchNorm這么好用的大殺器,仍然存在很多問題。
3.3 Batch Norm的四大罪狀
局限1:如果Batch Size太小,則BN效果明顯下降。
BN是嚴(yán)重依賴Mini-Batch中的訓(xùn)練實例的,如果Batch Size比較小則任務(wù)效果有明顯的下降。那么多小算是太小呢?圖10給出了在ImageNet數(shù)據(jù)集下做分類任務(wù)時,使用ResNet的時候模型性能隨著BatchSize變化時的性能變化情況,可以看出當(dāng)BatchSize小于8的時候開始對分類效果有明顯負(fù)面影響。之所以會這樣,是因為在小的BatchSize意味著數(shù)據(jù)樣本少,因而得不到有效統(tǒng)計量,也就是說噪音太大。這個很好理解,這就類似于我們國家統(tǒng)計局在做年均收入調(diào)查的時候,正好把你和馬云放到一個Batch里算平均收入,那么當(dāng)你為下個月房租發(fā)愁之際,突然聽到你所在組平均年薪1億美金時,你是什么心情,那小Mini-Batch里其它訓(xùn)練實例就是啥心情。
圖10. BN的Batch Size大小對ImageNet分類任務(wù)效果的影響(From GN論文)
BN的Batch Size大小設(shè)置是由調(diào)參師自己定的,調(diào)參師只要把Batch Size大小設(shè)置大些就可以避免上述問題。但是有些任務(wù)比較特殊,要求batch size必須不能太大,在這種情形下,普通的BN就無能為力了。比如BN無法應(yīng)用在Online Learning中,因為在線模型是單實例更新模型參數(shù)的,難以組織起Mini-Batch結(jié)構(gòu)。
局限2:對于有些像素級圖片生成任務(wù)來說,BN效果不佳;
對于圖片分類等任務(wù),只要能夠找出關(guān)鍵特征,就能正確分類,這算是一種粗粒度的任務(wù),在這種情形下通常BN是有積極效果的。但是對于有些輸入輸出都是圖片的像素級別圖片生成任務(wù),比如圖片風(fēng)格轉(zhuǎn)換等應(yīng)用場景,使用BN會帶來負(fù)面效果,這很可能是因為在Mini-Batch內(nèi)多張無關(guān)的圖片之間計算統(tǒng)計量,弱化了單張圖片本身特有的一些細節(jié)信息。
局限3:RNN等動態(tài)網(wǎng)絡(luò)使用BN效果不佳且使用起來不方便
對于RNN來說,盡管其結(jié)構(gòu)看上去是個靜態(tài)網(wǎng)絡(luò),但在實際運行展開時是個動態(tài)網(wǎng)絡(luò)結(jié)構(gòu),因為輸入的Sequence序列是不定長的,這源自同一個Mini-Batch中的訓(xùn)練實例有長有短。對于類似RNN這種動態(tài)網(wǎng)絡(luò)結(jié)構(gòu),BN使用起來不方便,因為要應(yīng)用BN,那么RNN的每個時間步需要維護各自的統(tǒng)計量,而Mini-Batch中的訓(xùn)練實例長短不一,這意味著RNN不同時間步的隱層會看到不同數(shù)量的輸入數(shù)據(jù),而這會給BN的正確使用帶來問題。假設(shè)Mini-Batch中只有個別特別長的例子,那么對較深時間步深度的RNN網(wǎng)絡(luò)隱層來說,其統(tǒng)計量不方便統(tǒng)計而且其統(tǒng)計有效性也非常值得懷疑。另外,如果在推理階段遇到長度特別長的例子,也許根本在訓(xùn)練階段都無法獲得深層網(wǎng)絡(luò)的統(tǒng)計量。綜上,在RNN這種動態(tài)網(wǎng)絡(luò)中使用BN很不方便,而且很多改進版本的BN應(yīng)用在RNN效果也一般。
局限4:訓(xùn)練時和推理時統(tǒng)計量不一致
對于BN來說,采用Mini-Batch內(nèi)實例來計算統(tǒng)計量,這在訓(xùn)練時沒有問題,但是在模型訓(xùn)練好之后,在線推理的時候會有麻煩。因為在線推理或預(yù)測的時候,是單實例的,不存在Mini-Batch,所以就無法獲得BN計算所需的均值和方差,一般解決方法是采用訓(xùn)練時刻記錄的各個Mini-Batch的統(tǒng)計量的數(shù)學(xué)期望,以此來推算全局的均值和方差,在線推理時采用這樣推導(dǎo)出的統(tǒng)計量。雖說實際使用并沒大問題,但是確實存在訓(xùn)練和推理時刻統(tǒng)計量計算方法不一致的問題。
上面所列BN的四大罪狀,表面看是四個問題,其實深入思考,都指向了幕后同一個黑手,這個隱藏在暗處的黑手是誰呢?就是BN要求計算統(tǒng)計量的時候必須在同一個Mini-Batch內(nèi)的實例之間進行統(tǒng)計,因此形成了Batch內(nèi)實例之間的相互依賴和影響的關(guān)系。如何從根本上解決這些問題?一個自然的想法是:把對Batch的依賴去掉,轉(zhuǎn)換統(tǒng)計集合范圍。在統(tǒng)計均值方差的時候,不依賴Batch內(nèi)數(shù)據(jù),只用當(dāng)前處理的單個訓(xùn)練數(shù)據(jù)來獲得均值方差的統(tǒng)計量,這樣因為不再依賴Batch內(nèi)其它訓(xùn)練數(shù)據(jù),那么就不存在因為Batch約束導(dǎo)致的問題。在BN后的幾乎所有改進模型都是在這個指導(dǎo)思想下進行的。
但是這個指導(dǎo)思路盡管會解決BN帶來的問題,又會引發(fā)新的問題,新的問題是:我們目前已經(jīng)沒有Batch內(nèi)實例能夠用來求統(tǒng)計量了,此時統(tǒng)計范圍必須局限在一個訓(xùn)練實例內(nèi),一個訓(xùn)練實例看上去孤零零的無依無靠沒有組織,怎么看也無法求統(tǒng)計量,所以核心問題是對于單個訓(xùn)練實例,統(tǒng)計范圍怎么算?
四. Layer Normalization、Instance Normalization及Group Normalization
4.1 Layer Normalization
為了能夠在只有當(dāng)前一個訓(xùn)練實例的情形下,也能找到一個合理的統(tǒng)計范圍,一個最直接的想法是:MLP的同一隱層自己包含了若干神經(jīng)元;同理,CNN中同一個卷積層包含k個輸出通道,每個通道包含m*n個神經(jīng)元,整個通道包含了k*m*n個神經(jīng)元;類似的,RNN的每個時間步的隱層也包含了若干神經(jīng)元。那么我們完全可以直接用同層隱層神經(jīng)元的響應(yīng)值作為集合S的范圍來求均值和方差。這就是Layer Normalization的基本思想。圖11、圖12和圖13分示了MLP、CNN和RNN的Layer Normalization的集合S計算范圍,因為很直觀,所以這里不展開詳述。
圖11. MLP中的LayerNorm
圖12. CNN中的LayerNorm
圖13. RNN中的LayerNorm
前文有述,BN在RNN中用起來很不方便,而Layer Normalization這種在同隱層內(nèi)計算統(tǒng)計量的模式就比較符合RNN這種動態(tài)網(wǎng)絡(luò),目前在RNN中貌似也只有LayerNorm相對有效,但Layer Normalization目前看好像也只適合應(yīng)用在RNN場景下,在CNN等環(huán)境下效果是不如BatchNorm或者GroupNorm等模型的。從目前現(xiàn)狀看,動態(tài)網(wǎng)絡(luò)中的Normalization機制是非常值得深入研究的一個領(lǐng)域。
4.2 Instance Normalization
從上述內(nèi)容可以看出,Layer Normalization在拋開對Mini-Batch的依賴目標(biāo)下,為了能夠統(tǒng)計均值方差,很自然地把同層內(nèi)所有神經(jīng)元的響應(yīng)值作為統(tǒng)計范圍,那么我們能否進一步將統(tǒng)計范圍縮小?對于CNN明顯是可以的,因為同一個卷積層內(nèi)每個卷積核會產(chǎn)生一個輸出通道,而每個輸出通道是一個二維平面,也包含多個激活神經(jīng)元,自然可以進一步把統(tǒng)計范圍縮小到單個卷積核對應(yīng)的輸出通道內(nèi)部。圖14展示了CNN中的Instance Normalization,對于圖中某個卷積層來說,每個輸出通道內(nèi)的神經(jīng)元會作為集合S來統(tǒng)計均值方差。對于RNN或者MLP,如果在同一個隱層類似CNN這樣縮小范圍,那么就只剩下單獨一個神經(jīng)元,輸出也是單值而非CNN的二維平面,這意味著沒有形成集合S,所以RNN和MLP是無法進行Instance Normalization操作的,這個很好理解。
圖14 CNN中的Instance Normalization
我們回想下圖8代表的CNN中的Batch Normalization,可以設(shè)想一下:如果把BN中的Batch Size大小設(shè)定為1,此時和Instance Norm的圖14比較一下,是否兩者是等價的?也就是說,看上去Instance Normalization像是Batch Normalization的一種Batch Size=1的特例情況。但是仔細思考,你會發(fā)現(xiàn)兩者還是有區(qū)別的,至于區(qū)別是什么讀者可自行思考。
Instance Normalization對于一些圖片生成類的任務(wù)比如圖片風(fēng)格轉(zhuǎn)換來說效果是明顯優(yōu)于BN的,但在很多其它圖像類任務(wù)比如分類等場景效果不如BN。
4.3 Group Normalization
從上面的Layer Normalization和Instance Normalization可以看出,這是兩種極端情況,Layer Normalization是將同層所有神經(jīng)元作為統(tǒng)計范圍,而Instance Normalization則是CNN中將同一卷積層中每個卷積核對應(yīng)的輸出通道單獨作為自己的統(tǒng)計范圍。那么,有沒有介于兩者之間的統(tǒng)計范圍呢?通道分組是CNN常用的模型優(yōu)化技巧,所以自然而然會想到對CNN中某一層卷積層的輸出或者輸入通道進行分組,在分組范圍內(nèi)進行統(tǒng)計。這就是Group Normalization的核心思想,是Facebook何凱明研究組2017年提出的改進模型。
圖15展示了CNN中的Group Normalization。理論上MLP和RNN也可以引入這種模式,但是還沒有看到相關(guān)研究,不過從道理上考慮,MLP和RNN這么做的話,分組內(nèi)包含神經(jīng)元太少,估計缺乏統(tǒng)計有效性,猜測效果不會太好。
圖15. CNN中的Group Normalization
Group Normalization在要求Batch Size比較小的場景下或者物體檢測/視頻分類等應(yīng)用場景下效果是優(yōu)于BN的。
4.4 用一個故事來總結(jié)
為了能夠更直觀地理解四種Normalization的異同,大家可以體會下面的故事以做類比:
很久很久以前,在遙遠的L國內(nèi)有一個神奇的理發(fā)館,理發(fā)館里面有很多勤勞的理發(fā)師,來這里理發(fā)的顧客也很奇特,他們所有人都會要求理發(fā)師(神經(jīng)元)理出和其他人差不多長的頭發(fā)(求均值)。那么和其他人差不多長究竟是多長呢?這可難不倒我們可愛又聰明的理發(fā)師,于是理發(fā)師把自己最近24個小時服務(wù)過的顧客(Mini-Batch)進入理發(fā)店時的頭發(fā)長度求個平均值,這個均值就是“和其他人差不多長”的長度。來這里的每個顧客都很滿意,時間久了,人們尊稱這些理發(fā)師為:BatchNorm理發(fā)師。
不幸總是突然的,有一天,理發(fā)館里發(fā)生了一件怪事,所有理發(fā)師的記憶只能維持1分鐘,他們再也記不住過去24小時中發(fā)生的事情了,自然也記不住過去服務(wù)客人的頭發(fā)長度。但是每個顧客仍然要求剪出和其他人差不多長的頭發(fā)長度,這可怎么辦?聰明的理發(fā)師們又想出了一個辦法:他們相互大聲報出同一時刻在理發(fā)館里自己手上客人的頭發(fā)長度,每個理發(fā)師就可以用這些人的頭發(fā)長度均值作為滿足自己手上客人條件的長度。盡管這是一群得了失憶綜合證的理發(fā)師,但是顧客對他們的服務(wù)仍然非常滿意,于是人們改稱他們?yōu)椋篖ayerNorm理發(fā)師。
不幸總是突然的,有一天,理發(fā)館里又發(fā)生了一件怪事,理發(fā)師們不僅得了失憶癥,這次都突然失聰,再也聽不到其它理發(fā)師的口頭通知,而固執(zhí)的客人仍然堅持要理出“和其他人差不多長”的頭發(fā)。對了,忘了介紹了,理發(fā)館是有隔間的,每個隔間有K個理發(fā)師同時給顧客理發(fā),雖然我們可愛又聰明的理發(fā)師現(xiàn)在失憶又失聰,但是再大的困難也難不倒也叫不醒這群裝睡的人,他們醒來后群策群力又發(fā)明了一個新方法:同一個隔間的理發(fā)師通過相互打手勢來通知其它理發(fā)師自己手上顧客的頭發(fā)長度。于是同一個隔間的理發(fā)師又可以剪出顧客滿意的頭發(fā)了。人們稱這些身殘志堅的理發(fā)師為:GroupNorm理發(fā)師。
不幸總是突然的,有一天,理發(fā)館里又發(fā)生了一件怪事,不過這次不是天災(zāi)是人禍,理發(fā)館老板出于好心,給每位理發(fā)師單獨開個辦公室給顧客理發(fā),但是好心辦了壞事,這樣一來,失憶失聰又無法相互打手勢的理發(fā)師們怎么應(yīng)對頑固的顧客呢?怎樣才能繼續(xù)理出“和其他人差不多長”的頭發(fā)呢?想必一般人這個時候基本無路可走了,但是我們可愛又聰明,同時失聰又失憶的理發(fā)師仍然想出了解決辦法:他們看了看客人頭上的頭發(fā),發(fā)現(xiàn)不同地方有長有短,于是就把同一個客人所有頭發(fā)的平均長度作為難題的答案(CNN的InstanceNorm)。聽起來這個解決方案匪夷所思,但是出人意料的是,有些客人居然仍然非常滿意。人們管這些傳說中的神奇理發(fā)師為:InstanceNorm理發(fā)師。
五. Normalization操作的Re-Scaling不變性
我們知道,當(dāng)神經(jīng)網(wǎng)絡(luò)深度加深時,訓(xùn)練有較大困難,往往其原因在于隨著網(wǎng)絡(luò)加深,在反向傳播訓(xùn)練模型時,存在梯度爆炸或者梯度消失問題,Loss信息不能有效傳導(dǎo)到低層神經(jīng)網(wǎng)絡(luò)參數(shù),所以導(dǎo)致參數(shù)無法更新,模型無法收斂或者收斂速度慢。而很多環(huán)節(jié)可能導(dǎo)致梯度爆炸或者梯度消失問題,比如非線性函數(shù)及其導(dǎo)數(shù)是什么形式以及網(wǎng)絡(luò)參數(shù)是否過大過小等,以非線性函數(shù)來說,比如RELU是能極大緩解這個問題的(因為它的導(dǎo)數(shù)是個常數(shù)),這也是為何目前RELU大行其道的根本原因。從神經(jīng)網(wǎng)絡(luò)參數(shù)角度看,如果神經(jīng)網(wǎng)絡(luò)中的參數(shù)具備Re-Scaling 不變性,意味著參數(shù)值過大或者過小對神經(jīng)元輸出沒什么影響,無疑這對緩解梯度爆炸或者梯度消失也有極大幫助作用,而Normalization確實具備幾個不同角度的Re-Scaling不變性,這也許是Normalization為何應(yīng)用在深度學(xué)習(xí)有效的原因之一,雖然可能并非本質(zhì)原因。本節(jié)即講述Normalization為何具備Re-Scaling 不變性這種優(yōu)良特性。
我們考慮神經(jīng)網(wǎng)絡(luò)中的三種Re-Scaling情形:權(quán)重向量(Weight Vector)Re-Scaling,數(shù)據(jù)Re-Scaling和權(quán)重矩陣(Weight Matrix)Re-Scaling。
圖16. 權(quán)重向量Re-Scaling
對于網(wǎng)絡(luò)中某個神經(jīng)元i來說,其對應(yīng)的邊權(quán)重向量假設(shè)為W_i,所謂權(quán)重向量(Weight Vector)Re-Scaling,就是將W_i 乘上一個縮放因子φ,如果神經(jīng)元 i 在進行權(quán)重向量 Re-Scaling 之前和之后兩種不同情況下做 Normalization 操作,若 Normalization 之后神經(jīng)元 i 對應(yīng)的激活值沒發(fā)生變化,我們就說這種 Normalization 具備權(quán)重向量 Re-Scaling 不變性(參考圖16)。
圖17. 數(shù)據(jù)Re-Scaling
所謂數(shù)據(jù)Re-Scaling,指的是把輸入X乘上一個縮放因子φ,同樣的,如果對輸入做縮放前后兩種情況下進行Normalization操作,若Normalization之后所有隱層神經(jīng)元對應(yīng)的激活值沒發(fā)生變化,我們說這種Normalization具備數(shù)據(jù)Re-Scaling不變性(參考圖17)。
圖18. 權(quán)重矩陣 Re-Scaling
而權(quán)重矩陣 Re-Scaling 指的是:對于某兩個隱層(L 層 vs L+1 層)之間的所有邊的權(quán)重參數(shù) W_ij 同時乘上相同的縮放因子φ,如果在權(quán)重矩陣 Re-Scaling 之前和之后兩種情形下對 (L+1) 層隱層神經(jīng)元做 Normalization 操作,若兩種情況下隱層所有神經(jīng)元激活值沒有變化,我們說這種 Normalization 具備權(quán)重矩陣 Re-Scaling 不變性(參考圖18)。
在了解了三種Re-Scaling的含義及Normalization對應(yīng)的三種不變性特性后,我們先歸納各種Normalization操作所對應(yīng)的三種Re-Scaling的不變性特性如下表所示(Layer Normalization原始論文分析了LayerNorm及BatchNorm的Re-Scaling不變性,本文作者補充了InstanceNorm及GroupNorm的情況以及細化了推導(dǎo)過程):
由表中可見,這四種不同的Normalization操作都同時具備權(quán)重矩陣Re-Scaling不變性和數(shù)據(jù)Re-Scaling不變性,但是不同的操作在權(quán)重向量Re-Scaling不變性這方面有差異,Batch Norm和Instance Norm具備權(quán)重向量Re-Scaling不變性,而另外兩種Normalization不具備這個特性。
我們以Batch Normalization為例來說明為何BN具備權(quán)重向量Re-Scaling不變性。
對于某個神經(jīng)元i的激活a來說,其值為:
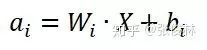
(對于MLP和CNN來說,是一樣的,都是這個公式,區(qū)別在于CNN是局部連接,MLP是全局連接,也就是說只有的數(shù)量規(guī)模不同而已。)
其中,是與神經(jīng)元i相連的邊權(quán)重向量(Weight Vector),X是輸入數(shù)據(jù)或是多層網(wǎng)絡(luò)中前一層的輸出向量,是偏置。我們可以把偏置看作輸入數(shù)據(jù)值為1的特殊邊的權(quán)重,所以可以并入前項,簡寫上述公式為:
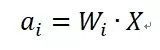
現(xiàn)在假設(shè)我們開始re-scale邊權(quán)重向量W_i,使得這些邊的權(quán)重縮放因子為φ,其對應(yīng)的新的激活得到相同的縮放比例:
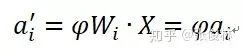
而邊的權(quán)重縮放后對應(yīng)的均值變?yōu)椋?/p>
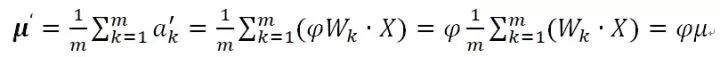
也就是說均值也被同比例縮放,這里的關(guān)鍵是因為BN的統(tǒng)計量取值范圍是來自于同一個Mini-Batch的實例,所以經(jīng)過的是用一個神經(jīng)元,于是對應(yīng)了相同的邊權(quán)重向量,那么縮放因子相同,就可以提到求和公式之外。
類似的,如果我們忽略噪音因子,邊權(quán)重縮放后對應(yīng)的方差變?yōu)椋?/p>
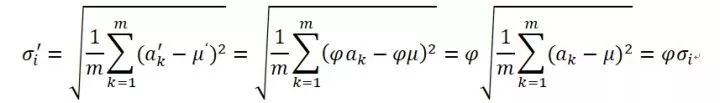
可見方差也被同比例縮放,因為
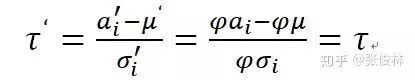
這是為何說BN具備權(quán)重向量Re-Scaling不變性的原因。
類似的,BN也具備數(shù)據(jù)Re-Scaling不變性,其推導(dǎo)過程與上述推導(dǎo)過程基本一樣。因為如果將原始輸入X乘以縮放因子,等價于某個神經(jīng)元i的激活變?yōu)?/p>
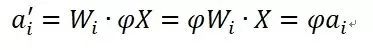
其余推導(dǎo)類似上述的權(quán)重向量ReScaling的后續(xù)推導(dǎo)過程,其對應(yīng)的均值和方差也會同比例縮放,于是得到了BN的數(shù)據(jù)Re-Scaling不變性。
同樣的,很容易推出BN也具備權(quán)重矩陣Re-Scaling不變性,因為權(quán)重矩陣中所有邊權(quán)重會使用相同的縮放因子φ,意味著某個隱層所有神經(jīng)元對應(yīng)的權(quán)重向量都使用相同的縮放因子,而在進行BN操作時,同隱層內(nèi)的神經(jīng)元相互獨立沒什么關(guān)系,因為上面推導(dǎo)了對于某個神經(jīng)元i來說,其具備權(quán)重向量Re-Scaling不變性,所以對于所有隱層神經(jīng)元來說,整個權(quán)重矩陣縮放后,任意神經(jīng)元的激活與未縮放時相同,所以BN具備權(quán)重矩陣Re-Scaling不變性。
對于其它三類Normalization,也就是Layer Norm/Instance Norm/Group Norm來說,都同時具備權(quán)重矩陣 Re-Scaling不變性及數(shù)據(jù)Re-Scaling不變性,推導(dǎo)過程也與上述推導(dǎo)過程類似,此處不贅述。
那么為何 Layer Norm 不具備權(quán)重向量 Re-Scaling 不變性呢?因為 Layer Norm 是在同隱層的神經(jīng)元之間求統(tǒng)計量,我們考慮一種比較極端的情況,假設(shè) MLP 的隱層只包含兩個神經(jīng)元:神經(jīng)元 i 和神經(jīng)元 j,而神經(jīng)元 i 對應(yīng)的邊權(quán)重向量 W_i 縮放因子是φ_i,神經(jīng)元 j 對應(yīng)的邊權(quán)重向量 W_j 縮放因子是φ_j。于是得出各自經(jīng)過縮放后的激活值為:
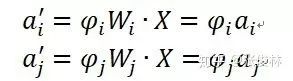
對應(yīng)的縮放后的均值為:
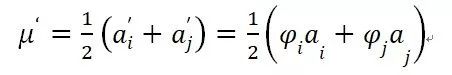
均值是無法提出公共縮放因子的,類似的方差也提不出公共縮放因子,所以不具備權(quán)重向量Re-Scaling不變性。那這又是為什么呢?根本原因是要進行求統(tǒng)計量計算的范圍不是同一個神經(jīng)元,而是不同的神經(jīng)元,而每個神經(jīng)元對應(yīng)權(quán)重向量縮放因子不同,所以難以抽出公共縮放因子并相互抵消。除非同一隱層所有隱層神經(jīng)元共享相同的縮放因子,這個情形其實就是權(quán)重矩陣 Re-Scaling能夠滿足的條件,所以可以看出Layer Norm具備權(quán)重矩陣 Re-Scaling不變性而不具備權(quán)重向量Re-Scaling不變性。Group Norm也是類似情況。
六. Batch Normalization為何有效?
正如上文所述,BN在提出后獲得了巨大的成功,目前在各種深度學(xué)習(xí)場景下廣泛應(yīng)用,因為它能加快神經(jīng)網(wǎng)絡(luò)收斂速度,不再依賴精細的參數(shù)初始化過程,可以使用較大的學(xué)習(xí)率等很多好處,但是我們應(yīng)該意識到,所講的這些好處僅僅是引用BN帶來的結(jié)果,那么更深層次的問題是:為什么BN能夠給深度學(xué)習(xí)帶來如此多的優(yōu)點呢?它背后起作用的深層原因是什么呢?上文盡管從Normalization操作的Re-Scaling不變性角度有所說明,但其實還有更深層或更本質(zhì)的原因。
原始的BN論文給出的解釋是BN可以解決神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中的ICS(Internal Covariate Shift)問題,所謂ICS問題,指的是由于深度網(wǎng)絡(luò)由很多隱層構(gòu)成,在訓(xùn)練過程中由于底層網(wǎng)絡(luò)參數(shù)不斷變化,導(dǎo)致上層隱層神經(jīng)元激活值的分布逐漸發(fā)生很大的變化和偏移,而這非常不利于有效穩(wěn)定地訓(xùn)練神經(jīng)網(wǎng)絡(luò)。
圖19. BN和ICS問題的關(guān)系
但是能夠解決ICS問題其實并不是BN為何有效背后真正的原因,最近有一些研究對此作了探討。那么ICS問題真實存在嗎?ICS問題在較深的網(wǎng)絡(luò)中確實是普遍存在的,但是這并非導(dǎo)致深層網(wǎng)絡(luò)難以訓(xùn)練的根本原因。另外,BN解決了ICS問題了嗎?其實也沒有。實驗一方面證明:即使是應(yīng)用了BN,網(wǎng)絡(luò)隱層中的輸出仍然存在嚴(yán)重的ICS問題;另一方面也證明了:在BN層輸出后人工加入噪音模擬ICS現(xiàn)象,并不妨礙BN的優(yōu)秀表現(xiàn)(參考圖19)。這兩方面的證據(jù)互相佐證來看的話,其實側(cè)面說明了BN和ICS問題并沒什么關(guān)系。
圖20. 損失曲面
那么BN有效的真正原因到底是什么呢?這還要從深度網(wǎng)絡(luò)的損失曲面(Loss Surface)說起,在深度網(wǎng)絡(luò)疊加大量非線性函數(shù)方式來解決非凸復(fù)雜問題時,損失曲面形態(tài)異常復(fù)雜,大量空間坑坑洼洼相當(dāng)不平整(參考圖20),也有很多空間是由平坦的大量充滿鞍點的曲面構(gòu)成,訓(xùn)練過程就是利用SGD在這個復(fù)雜平面上一步一步游走,期望找到全局最小值,也就是曲面里最深的那個坑。所以在SGD尋優(yōu)時,在如此復(fù)雜曲面上尋找全局最小值而不是落入局部最小值或者被困在鞍點動彈不得,可想而知難度有多高。
有了損失曲面的基本概念,我們回頭來看為何BN是有效的。研究表明,BN真正的用處在于:通過上文所述的Normalization操作,使得網(wǎng)絡(luò)參數(shù)重整(Reparametrize),它對于非線性非凸問題復(fù)雜的損失曲面有很好的平滑作用,參數(shù)重整后的損失曲面比未重整前的參數(shù)損失曲面平滑許多。我們可以用L-Lipschitz函數(shù)來評估損失曲面的平滑程度,L-Lipschitz函數(shù)定義如下:
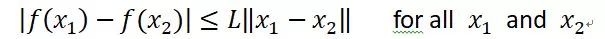
含義也很直觀,對于定義區(qū)間內(nèi)的任意取值x_1 和 x_2,用它們的距離去和經(jīng)過函數(shù)映射后的值(就是深度網(wǎng)絡(luò)表達的損失函數(shù))的距離進行比較,如果存在值L滿足上述公式條件,也就是說函數(shù)映射后的距離一定在任意兩個x差值的L倍以內(nèi),那么這個函數(shù)稱為L-Lipschitz函數(shù)。而L的大小代表了函數(shù)曲面的平滑程度,很明顯,L越小曲面越平滑,L越大,則曲面越凹凸不平,時而高峰時而波谷不斷顛倒跳躍。舉個例子,假設(shè)你一出門邁出一步才1米,假設(shè)你一出門邁出一步才 1 米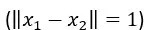 ,就突然掉到一個 100 米深的深溝
,就突然掉到一個 100 米深的深溝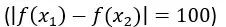 ,那么要滿足公式條件,L 最小得是 100;而假設(shè)你一出門邁出一步
,那么要滿足公式條件,L 最小得是 100;而假設(shè)你一出門邁出一步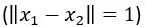 踏上了一個 0.3 米的小臺階
踏上了一個 0.3 米的小臺階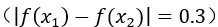 ,那么 L 最小等于 0.3 即可。
,那么 L 最小等于 0.3 即可。
圖21. 帶BN與不帶BN操作的L-Lipschitz情況
圖21展示了用L-Lipschitz函數(shù)來衡量采用和不采用BN進行神經(jīng)網(wǎng)絡(luò)訓(xùn)練時兩者的區(qū)別,可以看出未采用BN的訓(xùn)練過程中,L值波動幅度很大,而采用了BN后的訓(xùn)練過程L值相對比較穩(wěn)定且值也比較小,尤其是在訓(xùn)練的初期,這個差別更明顯。這證明了BN通過參數(shù)重整確實起到了平滑損失曲面及梯度的作用。
前文提到了Normalization對參數(shù)的Re-Scaling不變性,這也是參數(shù)重整達到的效果之一,所以也許其Re-Scaling特性和Loss曲面平滑作用是Normalization的一體兩面,共同發(fā)揮作用或者其實本身是一回事。事實的真相很可能是:Normalization通過對激活值進行正態(tài)分布化的參數(shù)重整,產(chǎn)生參數(shù)Re-Scaling不變的效果,因此緩解梯度消失或梯度爆炸問題,與其對應(yīng)的重整后的損失曲面及梯度也因此變得更平滑,更有利于SGD尋優(yōu)找到問題好的解決方案。當(dāng)然這只是本文作者根據(jù)幾方面研究現(xiàn)狀做出的推測,目前并沒有相關(guān)實證研究,還請讀者謹(jǐn)慎對待此觀點。
七. 結(jié)束語
本文歸納了目前深度學(xué)習(xí)技術(shù)中針對神經(jīng)元進行Normalization操作的若干種模型,可以看出,所有模型都采取了類似的步驟和過程,將神經(jīng)元的激活值重整為均值為0方差為1的新數(shù)值,最大的不同在于計算統(tǒng)計量的神經(jīng)元集合S的劃分方法上。BN采用了同一個神經(jīng)元,但是來自于Mini-Batch中不同訓(xùn)練實例導(dǎo)致的不同激活作為統(tǒng)計范圍。而為了克服Mini-Batch帶來的弊端,后續(xù)改進方法拋棄了Mini-Batch的思路,只用當(dāng)前訓(xùn)練實例引發(fā)的激活來劃分集合S的統(tǒng)計范圍,概括而言,LayerNorm采用同隱層的所有神經(jīng)元;InstanceNorm采用CNN中卷積層的單個通道作為統(tǒng)計范圍,而GroupNorm則折衷兩者,采用卷積層的通道分組,在劃分為同一個分組的通道內(nèi)來作為通道范圍。
至于各種Normalization的適用場景,可以簡潔歸納如下:
對于RNN的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)來說,目前只有LayerNorm是相對有效的;
如果是GAN等圖片生成或圖片內(nèi)容改寫類型的任務(wù),可以優(yōu)先嘗試InstanceNorm;
如果使用場景約束BatchSize必須設(shè)置很小,無疑此時考慮使用GroupNorm;
而其它任務(wù)情形應(yīng)該優(yōu)先考慮使用BatchNorm。
看上去其實Normalization的各種改進模型思路都很直觀,問題是:還有其它劃分集合S的方法嗎?很明顯還有很多種其它方法,建議讀者可以仔細思考下這個問題,如果你能找到一種新的集合劃分方法且證明其有效,那么恭喜你,這意味著你找到了一種新的Normalization模型。還等什么,趕緊去發(fā)現(xiàn)它們吧!
-
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132409 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120977
原文標(biāo)題:深度學(xué)習(xí)中的Normalization模型
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
AUTOCAD中各線形所代表的含義
Test Stand batch test result issue
如何去使用STM32 Batch Programmer量產(chǎn)燒錄軟件呢
請問在rknn_yolov5_demo中batch設(shè)置和推理時間長短有何關(guān)系
在PCS7中配置Batch步驟
一文看懂神經(jīng)網(wǎng)絡(luò)之Epoch、Batch Size和迭代

Batch的大小、災(zāi)難性遺忘將如何影響學(xué)習(xí)速率
Batch Norm的工作原理2018年被MIT的研究人員推翻
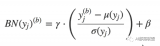
batch normalization時的一些缺陷
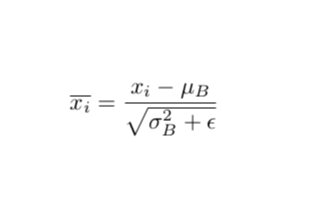
如何去掉batch normalization層來加速神經(jīng)網(wǎng)絡(luò)

有關(guān)batch size的設(shè)置范圍
Spring Batch 批處理框架編程設(shè)計
MES與DCS+Batch數(shù)據(jù)交互與超融合應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論