 深度解讀Gating類型自動混音技術(2)
深度解讀Gating類型自動混音技術(2)
在上一篇 “Gating自動混音器(一)“,我們已經了解了Gating自動混音器是干什么用的,它主要解決的問題是什么。在有多個麥克風的場景下,傳統的做法是將多個麥克風混音輸出到音箱。這樣的做法不可取,它可能導致的問題是,一、及其容易產生嘯叫,因為2路信號混音,總輸出增加3dB,更何況多支呢。二、即使可以通過增益比例去控制每只麥克風在總輸出中占的比例,以達到總輸出不增加的目的,也非常容易導致說話人說話的聲音太小,聽不清楚。基于以上原因,才會有自動混音的出現,自動混音徹徹底底地解決了根本問題。自動混音分為Gain-Sharing(增益共享)和Gating(門限)兩種類型,現在所講的是Gating類型自動混音。
上一期已經講了Gating自動混音所應具備的一些基本參數及含義,留下了一個關鍵點,自適應噪聲閾值如何獲取?在開始之前,先來看看為什么門限自動混音可以解決上邊提到的問題。
從圖中可以看出,每只麥克風都有個Gate(門),當麥克風信號超過這個門限以后,才會導通信號。通過的信號和普通混音無異,混音之后通過一個由NOM(打開的麥克風數量)控制的衰減因子,達到總輸出不變的目的。 在多只麥克風的情況下,不會存在每個人都會在同時說話,正在同時說話的麥克風只有那么1-3只而已。其他未說話的麥克風將被關閉,不會被導通。這樣既可以保證總輸出不產生反饋,每只麥克風說話的聲音又可以聽得清楚。
NOM:Number Of Open Mics. 算法實時計算打開的麥克風數量,如果大于NOM Limits 設定的數量,新打開的麥克風將從已經打開的麥克風中搶占優先級最低的一個, 如果沒有找到,該麥克風不會被導通, NOM Limits起到一個限制作用。
在這里面,Gate是關鍵,如何保證麥克風有信號的時候被打開,沒有人說話就不會被打開。簡單一點,可以采用對每一只麥克風設置一個開關閾值,信號超過閾值的時候就導通,小于閾值就關閉。 在很久以前,就是這么做的,并且使用了很長的一段時間。此方法不是特別的方便,環境噪音提高了,必須得手動去調整閾值。
在嘗試中,我考慮了2種方法:
1. 人聲檢測 , 只有說話的時候才被打開,不說話關閉 。
2. RMS電平檢測。
在DSP系統中,除了能實現模塊功能,另一個最重要的就是資源了。這個算法占用的CPU資源類不應超過5%, 人聲檢測不能采用太過復雜的基于統計模型的算法,一個麥克風需要檢測一次,共有32個麥克風,這將勢必不可取。后來嘗試了短時過零率和短時能量等方法。結果不太理想,應該來說檢測結果不太理想,有時說話了確不出聲,一句話的前面幾個字像被吃掉了一樣。 總結來說,短時過零率等方法并不能準確判斷語音,第二個這類檢測方法都需要延時緩沖,大概10ms檢測數據,吃字也是正常的。 被拋棄的想法就不細說了,有興趣的可以看看相關資料。
采用RMS檢測方法, RMS我們都知道,就是均方根嘛。相對來說算法簡單易實現, 根據過去一段時間的RMS值作為該麥克風的參考噪聲閾值。這里面最重要的就是時間的選取,要反應的是過去的噪聲水平,而不是有信號的狀態。語音信號屬于非平穩信號,利用這一特點應取最小值。記為瞬態RMS, N取值30ms對應的采樣值。 T為噪聲閾值,等于過去的K幀RMS最小值, K值根據實際情況調節。
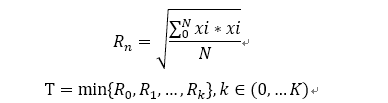
K 取值依據,應大于說話尾音所能持續的時間,正常說話一個字也就100多ms,字與字之間會出現停頓,噪聲閾值的依據也就是停頓期間的噪聲水平。說一個情況,同事在測試期間,一個字不停的拖尾音,喂……….,持續10幾秒。這種情況導致算法提高了噪聲閾值,剛開始可以導通,之后的喂出不了聲。 那么這個K值應取得更大,K*30ms 需要大于最大能持續的時間才能檢測到空隙。
根據測試情況,RMS方法可以作為自適應噪聲閾值判斷的方法。在測試中,會存在另外一種情況,一只麥克風說話時,另一只麥克風采集到了音箱擴聲的信號被打開。如果NOM Limit設置成1,只允許一個麥克風打開。采集信號的麥克風就會搶占說話的麥克風,引起兩個麥克風互相切換。此時,應調節2個參數,一是保持時間,第二個靈敏度。
保持時間,停止說話后,該麥克風保持多久才關閉,改時間要設置得比混響傳遞時間大一點。
靈敏度,實際上信號超過自適應噪聲閾值+靈敏度才能判定為可以打開麥克風。靈敏度需要設置高一點,即使有反饋也不會輕易打開話筒。
以上就是Gating自動混音的全部內容,代碼就不貼了,也沒什么意義,關鍵還是思路吧。
-
麥克風
+關注
關注
15文章
633瀏覽量
54772 -
混音
+關注
關注
0文章
6瀏覽量
7697 -
混音器
+關注
關注
2文章
26瀏覽量
13032
原文標題:Gating 自動混音(二)
文章出處:【微信號:ddongcloud,微信公眾號:嵌入式DSP】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
clock-gating的綜合實現
淺析clock gating模塊電路結構
基于數字語音教室的多路混音算法及應用Multi-Point

構建一個簡單的模擬音頻混音器

深度解讀智能汽車車載傳感器標定技術
AND GATE的clock gating check簡析





 工商網監
工商網監
評論