") TrellisNet在CNN和RNN間架起了一座橋梁
TrellisNet在CNN和RNN間架起了一座橋梁
長期以來,序列建模一直是循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的天下。然而,近年來,卷積神經(jīng)網(wǎng)絡(luò)(CNN)開始入侵這一RNN的保留領(lǐng)地,在建模長距離上下文方面表現(xiàn)尤為出色。這兩年來,更出現(xiàn)了獨立于RNN和CNN之外的完全基于自注意力機(jī)制的模型。
CMU和Intel的研究人員Shaojie Bai、J. Zico Kolter、Vladlen Koltun剛剛(2018年10月15日)發(fā)布了論文Trellis Networks for Sequence Modeling,提出了一種新穎的架構(gòu)——網(wǎng)格網(wǎng)絡(luò)(TrellisNet)。網(wǎng)格網(wǎng)絡(luò)的結(jié)構(gòu)融合了CNN和RNN,因此可以直接吸收許多為CNN和RNN設(shè)計的技術(shù),從而在多項序列建模問題上戰(zhàn)勝了當(dāng)前最先進(jìn)的CNN、RNN、自注意力模型。
TrellisNet架構(gòu)
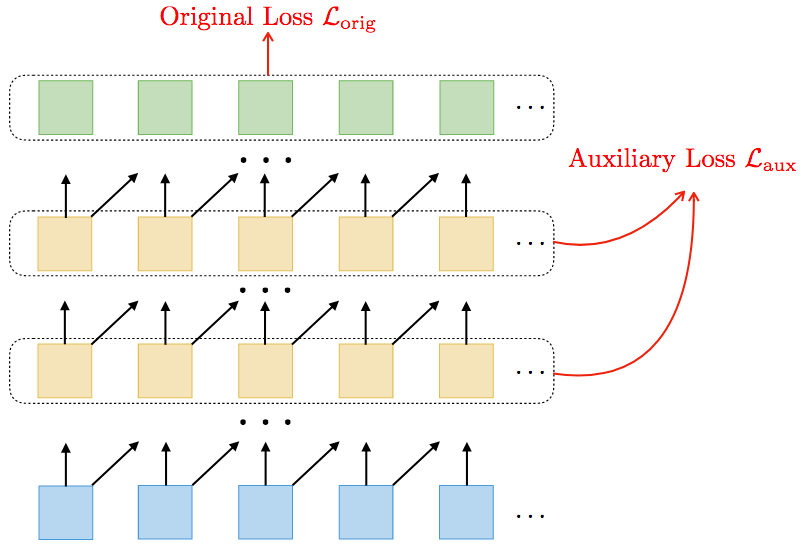
TrellisNet的基本單元如下圖所示:
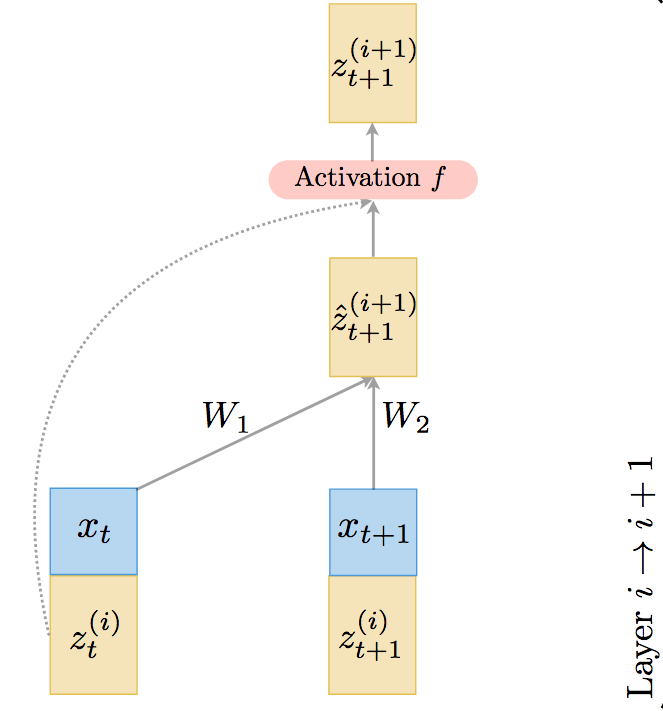
上圖中,t表示時刻,i表示網(wǎng)絡(luò)層,W表示權(quán)重,x表示序列輸入(藍(lán)色),z表示隱藏狀態(tài)(黃色)。可以看到,這一基本構(gòu)件的輸入是前一層i在t、t+1時刻的隱藏狀態(tài),以及t、t+1時刻的輸入向量。
這些輸入經(jīng)過前饋線性變換(省略了偏置):
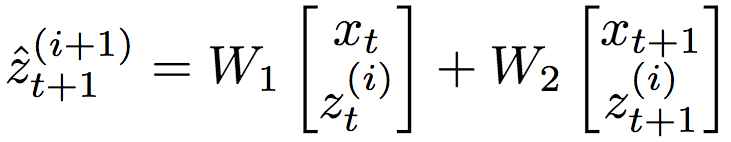
和前一層t時刻的隱藏狀態(tài)一起傳給非線性激活函數(shù)f:
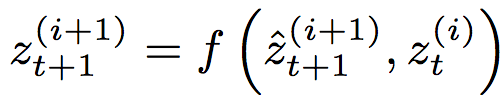
平鋪上述單元,我們就得到了完整的TrellisNet:
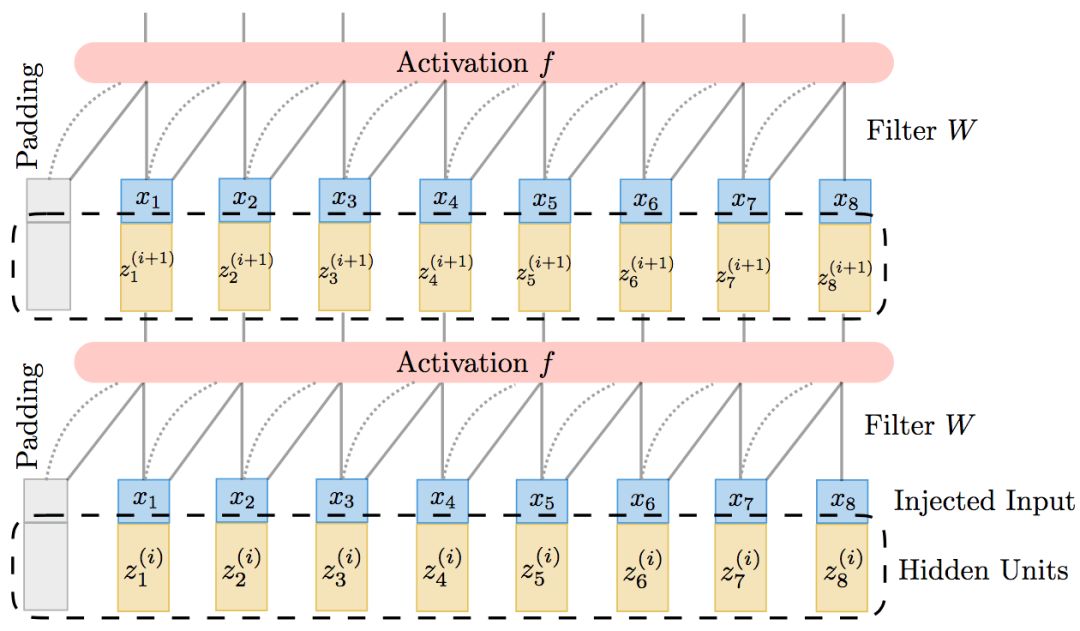
注意,所有時刻和網(wǎng)絡(luò)層的權(quán)重都是一樣的,這也是TrellisNet的一個重要特征。
順便提一下,由于TrellisNet每層都接受(相同的)輸入序列x1:T作為(部分)輸入,我們可以預(yù)先計算輸入序列的線性變換:
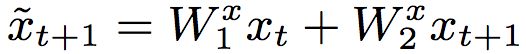
然后在所有網(wǎng)絡(luò)層使用。
TrellisNet和CNN
回過頭去看下完整的TrellisNet示意圖,可以看到,其實TrellisNet的每一層,都可以視為對隱藏狀態(tài)序列進(jìn)行一維卷積運算,然后將卷積輸出傳給激活函數(shù)。也就是說,TrellisNet的網(wǎng)絡(luò)層i的運算可以總結(jié)為:
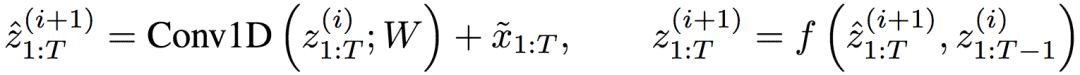
這就意味著TrellisNet可以看成一種特殊的CNN,隨著網(wǎng)絡(luò)層的加深,感受野也隨之增大。
不過,TrellisNet和一般的(時序)CNN有兩個地方不一樣:
如前所述,所有時刻和網(wǎng)絡(luò)層的權(quán)重是一樣的。換句話說,所有網(wǎng)絡(luò)層共享過濾矩陣。這樣的權(quán)重系聯(lián)大大降低了模型的尺寸,而且可以看成一種正則化(更穩(wěn)定的訓(xùn)練、更好的概括性)。
(線性變換后的)輸入序列直接插入每個隱藏層。輸入序列的插入混合了深層特征和原始序列。
相應(yīng)地,TrellisNet也可以直接應(yīng)用一些為CNN設(shè)計的技術(shù):
深度監(jiān)督。深度監(jiān)督技術(shù)使用CNN的中間層損失作為輔助,即
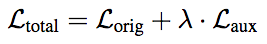
(λ是固定參數(shù),控制輔助損失的權(quán)重)。
例如,在訓(xùn)練一個L層TrellisNet的過程中,為了預(yù)測t時刻的輸出,除了最后一層的zt(L)外,我們可以同時在zt(L-l)、zt(L-2l)等隱藏狀態(tài)上應(yīng)用損失函數(shù)。
空洞卷積。在CNN中應(yīng)用空洞卷積可以更快地擴(kuò)大感受野。TrellisNet可以直接應(yīng)用這一技術(shù)。注意,如果我們改動了核大小或卷積設(shè)定,TrellisNet的激活函數(shù)f可能需要做相應(yīng)調(diào)整。例如,假設(shè)空洞為d,核大小為2,則激活函數(shù)需調(diào)整為
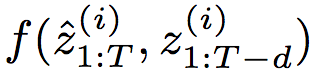
權(quán)重歸一化。在卷積核上應(yīng)用權(quán)重歸一化(WN)能起到正則化作用,并加速收斂。
并行。TrellisNet同樣可以利用并行卷積操作。
TrellisNet和RNN
RNN和CNN看起來完全不一樣。CNN的每個網(wǎng)絡(luò)層并行操作序列的所有元素,而RNN每次處理序列的一個元素,并在時間上展開。
然而,論文作者證明了,任何展開至有限長度的RNN等價于核矩陣W使用特別的稀疏結(jié)構(gòu)的TrellisNet:
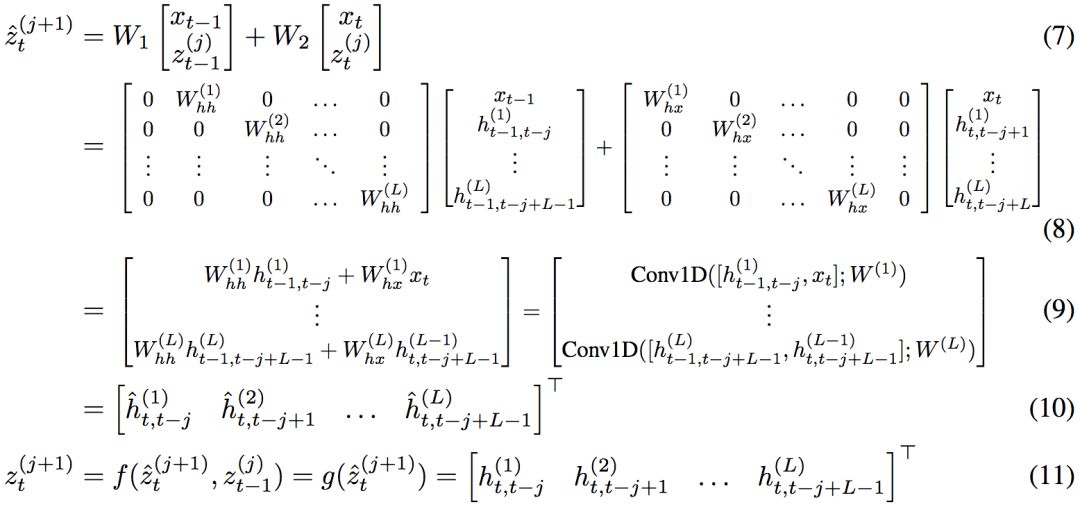
論文作者以一個雙層RNN為例,演示了兩者的等價性。TrellisNet的每個單元同時表示3個RNN單元(輸入xt、第一層的隱藏向量ht(1)、第二層隱藏向量ht(2))。
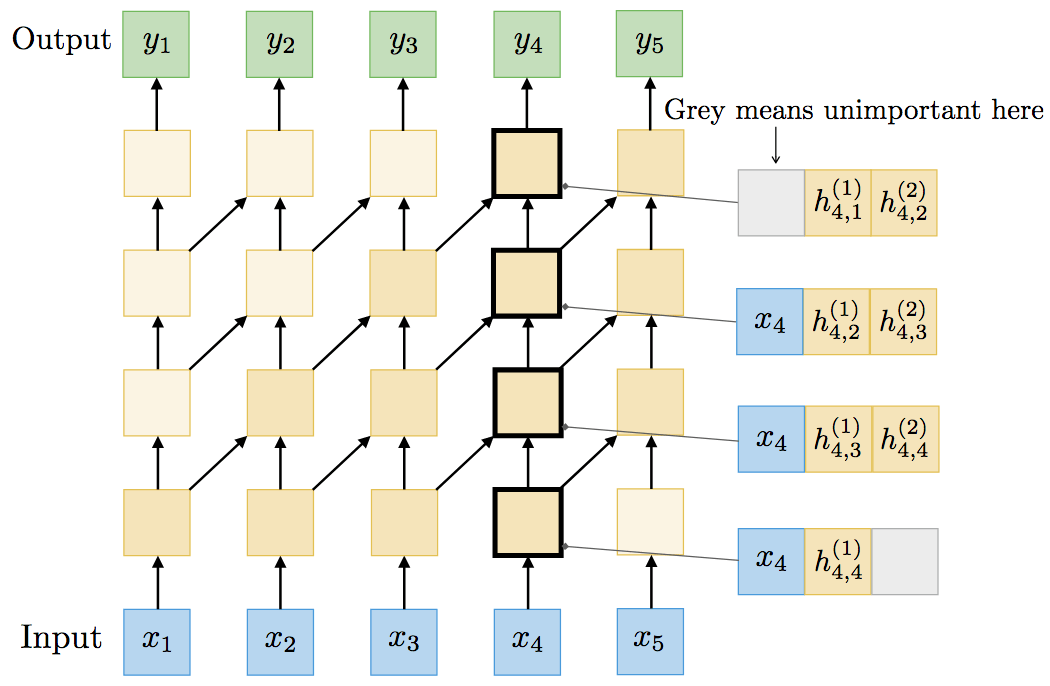
而層間線性變換構(gòu)成了混合分組卷積(mixed group convolution)——一種非常規(guī)的分組卷積,t時刻的分組k通過t+1時刻的分組k-1進(jìn)行卷積。應(yīng)用非線性g之后,便精確重現(xiàn)了原本的雙層RNN的輸出。
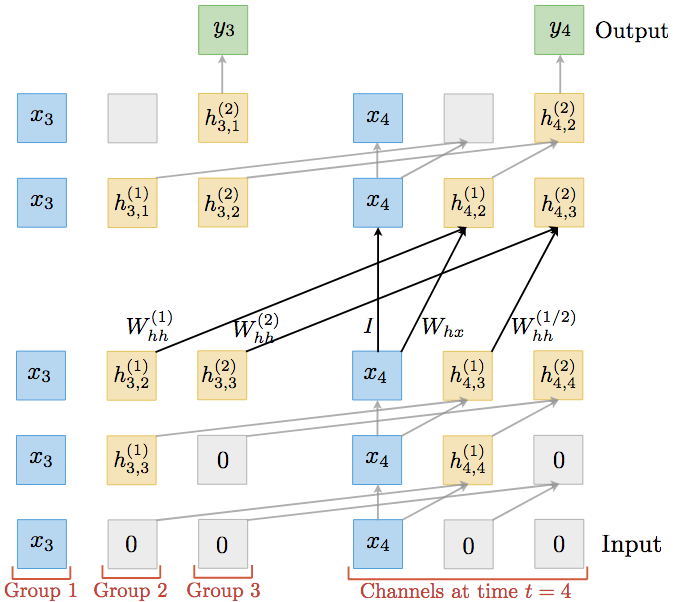
由于之前的等價性推導(dǎo)不涉及RNN的非線性變換g的內(nèi)在結(jié)構(gòu),因此,同樣適用于LSTM和GRU等RNN變體。例如,對LSTM而言:
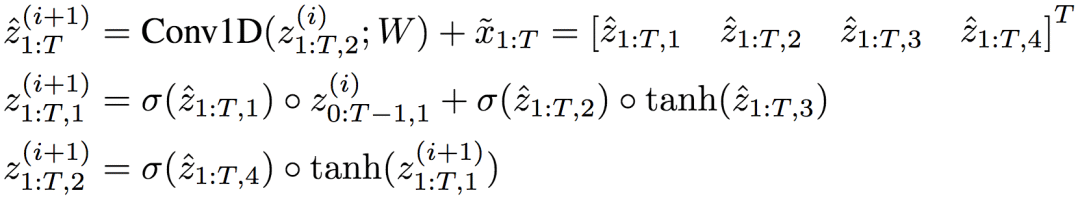
和之前的例子同理,一個雙層LSTM可以表達(dá)為使用混合分組卷積的TrellisNet:
另一方面,LSTM細(xì)胞可以作為TrellisNet的非線性激活。下一節(jié)的各項試驗中,論文作者就使用了LSTM細(xì)胞作為TrellisNet的激活。
同樣,TrellisNet也可以使用一些源自RNN的技術(shù):
History repackaging:理論上,RNN可以表示無限長度的歷史。但在許多應(yīng)用中,序列長度太長,會導(dǎo)致反向傳播難以為繼(梯度消失)。經(jīng)典的解決方案是將序列分為較小的子序列,在每個子序列上進(jìn)行截斷BPTT。在序列邊界處,重新打包隱藏狀態(tài)ht并傳給下一個RNN序列。因此梯度流停在序列邊界處。TrellisNet也可以利用這一技術(shù)。如下圖所示,在RNN中傳遞壓縮歷史向量ht等價于在TrellisNet的混合分組卷積中指定非零補齊,也就是在TrellisNet中使用先前序列上最后一層的最后一步作為補齊(“歷史”補齊)。
門控激活如前所述,TrellisNet可以使用LSTM的門控函數(shù)作為激活。實際上,GRU等其他門控激活同樣可以應(yīng)用于TrellisNet。
變分dropoutRNN的變分dropout(VD)是一種在每層的所有時步應(yīng)用相同掩碼的正則化方案(參見下圖,每種顏色代表一種dropout掩碼)。如果直接翻譯這一技術(shù)到TrellisNet的話,需要為網(wǎng)絡(luò)的每條對角線和混合分組卷積的每個分組創(chuàng)建不同掩碼。論文作者轉(zhuǎn)而采用了一種極其簡單的替代方案,在每次迭代中,時間維度和深度維度上的每一時步都應(yīng)用相同的掩碼。論文作者的試驗表明,這一方案效果優(yōu)于其他dropout方案。
循環(huán)權(quán)重dropout/DropConnectDropConnect推廣了dropout,dropout歸零隨機(jī)選擇的激活子集,而DropConnect歸零隨機(jī)選擇的權(quán)重子集(如下圖所示)。
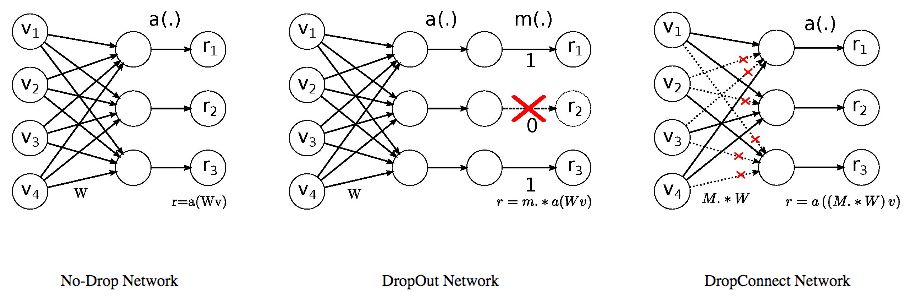
Merity等表明,在隱藏層之間的權(quán)重Whh上應(yīng)用DropConnect,可以優(yōu)化LSTM語言模型的表現(xiàn)(arXiv:1708.02182)。受此啟發(fā),TrellisNet的卷積核應(yīng)用了DropConnect。
另外,如前所述,等價于RNN的TrellisNet的權(quán)重矩陣使用了特別的稀疏結(jié)構(gòu)。那么,有理由相信,去除了這一權(quán)重矩陣限制的TrellisNet應(yīng)該具有更強的表達(dá)能力,可以建模比原本的RNN更廣的變換。
試驗結(jié)果
論文作者在單詞層面和字符層面的語言建模問題上的測試表明,TrellisNet表現(xiàn)優(yōu)于當(dāng)前最先進(jìn)模型。
單詞層面的語言建模測試是在Penn Treebank(PTB)數(shù)據(jù)集和WikiText-103(WT103)數(shù)據(jù)集上進(jìn)行的。PTB是相對較小的數(shù)據(jù)集,因此比較容易出現(xiàn)過擬合現(xiàn)象,需要應(yīng)用前兩節(jié)提到的一些正則化技術(shù)。
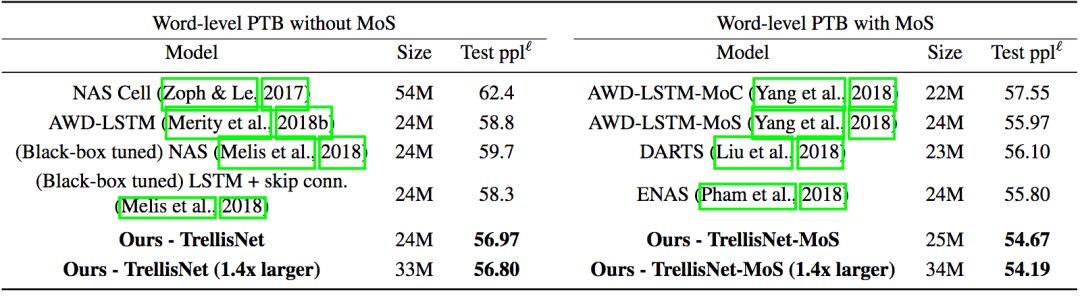
在PTB上的測試結(jié)果(MoS指混合softmax)
而WT103規(guī)模比PTB大一百倍,過擬合風(fēng)險較低,但268K的詞匯量使得訓(xùn)練很有挑戰(zhàn)性。參照之前研究的成果,論文作者在TrellisNet上應(yīng)用了自適應(yīng)softmax,提高了內(nèi)存效率。
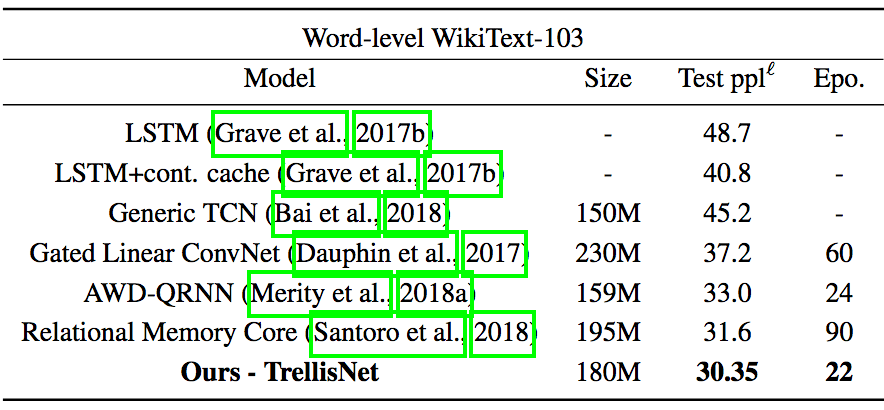
在WT103上的測試結(jié)果
在WT103上,TrellisNet不僅表現(xiàn)優(yōu)于當(dāng)前最先進(jìn)的基于自注意力機(jī)制的RMC模型(提升約4%),而且收斂速度比RMC要快很多:TrellisNet在22個epoch內(nèi)收斂,而RMC需要90個epoch。
對于字符層面的語言建模而言,PTB算是中等規(guī)模的數(shù)據(jù)集。因此,論文作者使用了更深的TrellisNet,同時采用了權(quán)重歸一化和深度監(jiān)督技術(shù)。
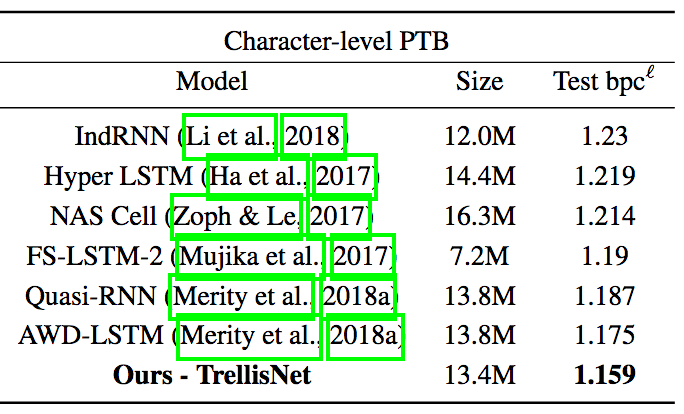
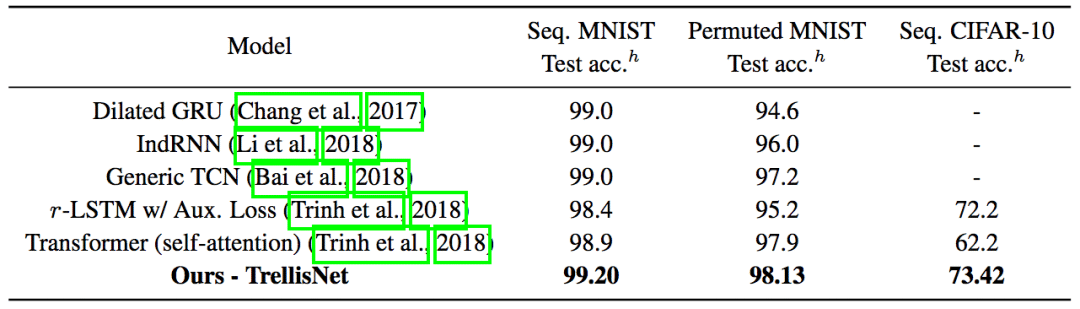
論文作者也評估了TrellisNet建模長期依賴的能力。序列化MNIST、PMNIST、序列化CIFAR-10任務(wù),將圖像視作長序列,每次處理一個像素。論文作者為此實現(xiàn)的TrellisNet模型有八百萬參數(shù),和之前的研究所用的模型規(guī)模相當(dāng)。為了覆蓋更多上下文,論文作者在TrellisNet的中間層應(yīng)用了空洞卷積。同樣,TrellisNet在這些任務(wù)上的表現(xiàn)超過了之前的成果。
如前所述,不同任務(wù)的TrellisNet采用了不同的超參數(shù)和設(shè)定,詳見下表:
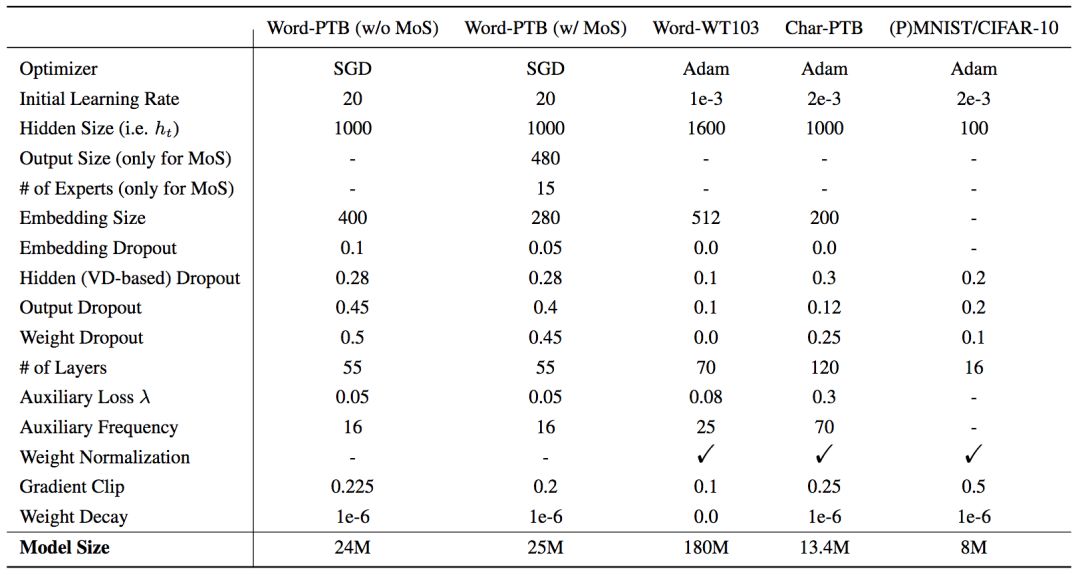
“-”表示未使用
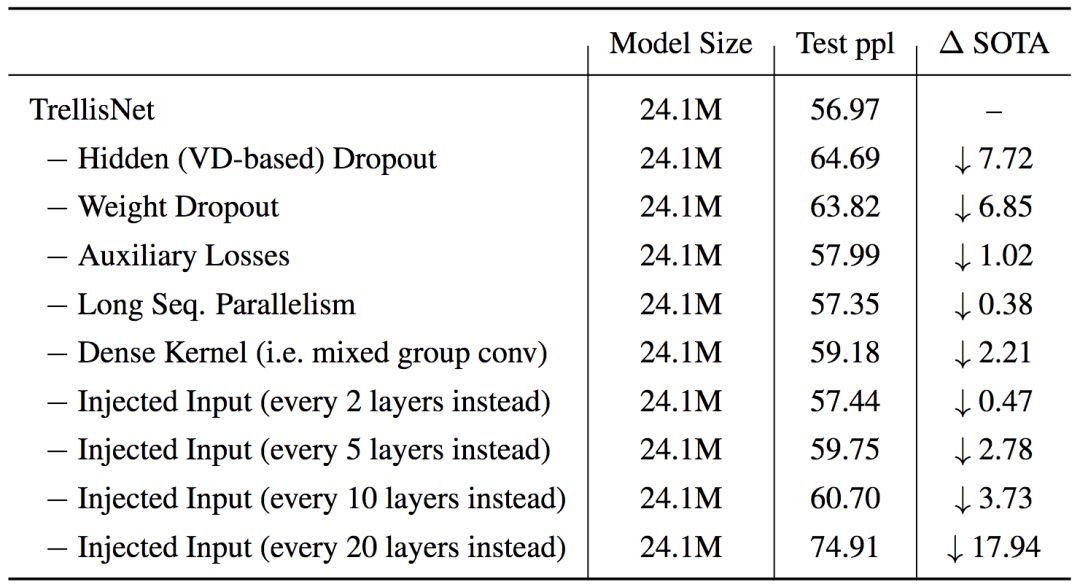
為了驗證吸收自CNN和RNN的各種技術(shù)的效果,論文作者在單詞層面的PTB數(shù)據(jù)集上進(jìn)行了消融測試:
結(jié)語
TrellisNet在CNN和RNN間架起了一座橋梁。在理論層面,這可能有助于我們得到對序列建模更深入、更統(tǒng)一的理解。在實踐層面,通過吸收源自CNN和RNN的技術(shù),TrellisNet的表現(xiàn)超越了當(dāng)前最先進(jìn)模型。而且,TrellisNet的表現(xiàn)仍有優(yōu)化空間。例如,相比經(jīng)典的LSTM細(xì)胞,其他門控激活可能帶來更好的效果。同理,其他超參數(shù)調(diào)整也可能進(jìn)一步提升TrellisNet的表現(xiàn)。
另外,如果能夠建立TrellisNet和基于自注意力機(jī)制的架構(gòu)(如Transformers)的連接,就可以統(tǒng)一時序建模的三大主要范式。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100541 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22170
原文標(biāo)題:CNN和RNN混血兒:序列建模新架構(gòu)TrellisNet
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Multiphysics Simulation模擬軟件怎么解決設(shè)計問題
TEXTIO及其在VHDL仿真中的應(yīng)用
一座橫跨世界的技術(shù)橋梁
CNN和RNN結(jié)合與對比,實例講解
Oracles正在為物質(zhì)世界和區(qū)塊鏈之間架起一座橋梁
ADI幫你實現(xiàn)現(xiàn)實與數(shù)字世界之間架起橋梁
穩(wěn)定幣的現(xiàn)狀是怎樣的





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論