 賽靈思發布自適應計算加速平臺芯片系列Versal
賽靈思發布自適應計算加速平臺芯片系列Versal
2018年10月16日,FPGA大廠賽靈思(Xilinx)在北京召開了一年一度的“Xilinx開發者大會 ”(XDF) 。在本次會議上,賽靈思發布了全球首款自適應計算加速平臺 (Adaptive Compute Acceleration Platform ,ACAP)芯片系列Versal。與此同時,賽靈思還針對云端和本地數據中心市場還發布了一款功能強大的加速器卡——Alveo。至此,賽靈思的轉型大幕正式開啟,而人工智能則是賽靈思轉型的最大推力。
AI推斷需求暴漲,推動FPGA市場加速增長
目前,人工智能可謂是非常的火爆。而數據的爆發式增長,人工智能算法的不斷完善以及芯片算力的快速增長,則是推動人工智能應用爆發的三大關鍵因素。
隨著人工智能計算的快速發展,自去年以來更是出現了一股AI芯片的熱潮。由于傳統的CPU、GPU已經開始難以滿足越來越多的新的需求,并且在AI計算能效上也開始處于劣勢。在此形勢之下,半定制的FPGA和定制型的ASIC開始迎來了高速的發展。
雖然ASIC芯片的計算能力和計算效率都直接根據特定的算法的需要進行定制的,可以實現體積小、功耗低、計算性能高、計算效率高等優勢,但是人工智能仍在快速發展,每天都會有不少新的算法/模型出現,很多領域都還沒有一個標準的算法。
而ASIC芯片則是針對特定算法的需要進行設計的,設計一旦完成就無法修改,通常一顆ASIC芯片從設計到量產一般都需要18-24個月的時間,這也意味著當這款ASIC芯片量產之時,可能就已經落后于當下算法發展的18-24個月的時間。相比之下,FPGA則沒有這個問題。
另外,在市場需求變化越來越快速的當下,客戶都希望產品能夠在快速創新的同時,盡可能的實現快速上市。FPGA作為一種可編程的半定制芯片,其與GPU一樣具有并行處理優勢,并且也可以設計成具有多內核的形態,當然其最大的優勢還是在于其可以通過軟件編程的手段更改、配置器件內部連接結構和邏輯單元,完成既定設計功能的數字集成電路。這也意味著即使是出廠后的FPGA的邏輯塊和連接,開發者若要適應新的AI算法或者實現新的功能應用,只需通過升級軟件就可重新配置這些芯片,可以更加快速的適應市場的需求。
雖然GPU也可靈活的適應各種AI算法,但是能效很低。而GPU雖然被廣泛的用于深度學習領域,但是需要指出的是,其主要被應用在深度學習的訓練環節,在推理時對于小批量數據,并行計算的優勢不能發揮出來。但而FPGA同時擁有流水線并行和數據并行,因此處理推理任務時候可以時延更低。
根據賽靈思在會上公布的來自Barclays Reseach于今年5月公布的數據顯示,目前人工智能市場主要來自于“訓練”的需求,不過自2019年開始來自“推斷”(包括數據中心和邊緣端)的需求將會持續快速爆發式增長。而“訓練”的需求增長將會逐漸放緩,并趨于停滯。到2021年來自“推斷”的市場規模將會首次超過“訓練”,之后2023年將達到“訓練”市場的三倍左右。
另外有數據顯示,未來至少95%的AI計算都是用于“推斷”,只有不到5%是用于模型“訓練”。
賽靈思軟件及IP產品執行副總裁Salil Raje
賽靈思軟件及IP產品執行副總裁Salil Raje也指出:“今后AI模型必須應用在云端和邊緣的模型上,所以未來的模式更多的是推斷,而不是訓練。賽靈思關注的就是推斷。”
而“推斷”則是FPGA的優勢。其可以在大幅提升推能效、降低功耗(韓國SK電訊的NUGU個人助理服務器原來采用的是GPU來進行AI加速,在采用賽靈思的FPGA之后,實現了每瓦性能比原本的GPU方案提升了16倍)的同時,還可降低精度損失,同時其還擁有出色的靈活性和低延時特性。不難想象,隨著AI“推斷”需求的快速增長,FPGA市場也有望迎來高速成長。
賽靈思VR Ramine在會后接受專訪時也表示:“雖然GPU現在在深度學習訓練這一塊應用非常多,但是它的功耗很高,而且這個市場已經處于比較飽和的狀態。而賽靈思并不是特別關注訓練這個市場,我們更多關注的是推斷這部分的市場,這個市場仍然處于初期上升期,尤其在推斷在加速應用這方面剛剛處于一個快速增長的階段,特別是在數據中心和邊緣計算領域。在推斷這塊市場,GPU用的并不多。雖然CPU有一定的市場份額,但是性能、能效和時延也并不好。所以為什么賽靈思在推斷這個領域,包括在智慧城市、自動駕駛車領域已經有了很多的客戶。”
而作為FPGA市場的老大(占據了近60%的市場份額),賽靈思也將成為最大的受益者。在AI異常火爆的當下,此次賽靈思的開發者大會也是備受行業內外的廣泛關注,會議現場更是人氣爆棚,近千人的會場是座無虛席。
超越FPGA,迎來全新物種ACAP
雖然FPGA擁有很多的優勢,但是不可否認的是,FPGA的基本單元的計算能力是有限的。為了實現可重構的特性,FPGA內部有大量極細粒度的基本單元,但是每個單元的計算能力(主要依靠LUT查找表)都遠遠低于CPU和GPU中的ALU模塊。另外,在計算的效率和功耗上FPGA也要低于ASIC。
隨著越來越多的應用趨向于既具高速處理又兼具靈活性的系統,FPGA廠商為了彌補單純采用FPGA的缺陷,開始推出整合了CPU/GPU/RF/FPGA的異構SoC的融合性方案。
比如賽靈思此前就曾推出了多處理器SoC(MPSoC,在FPGA上整合了Arm的CPU內核,還有Mali系列的GPU等)、RFSoC(將通信級RF采樣數據轉換器、SD-FEC內核、Arm處理器以及 FPGA 架構整合到單芯片器件中)。而為了能夠幫助更多的用戶和開發者提供更為強大的計算平臺,今年3月,賽靈思還發布了全新的超越FPGA功能的突破性新型產品——ACAP自適應計算加速平臺。
賽靈思軟件及IP產品執行副總裁Salil Raje表示:“賽靈思在過去三十年當中一直引領FPGA行業的發展。FPGA是非常強大的,靈活度非常好,但是現在我們面臨著海量的數據,摩爾定律已經不再有效了,現在沒有任何一個單一的計算架構能夠適應如此海量的數據。我們需要進入一個異構計算的時代,需要各種各樣的計算架構才能解決現在所面臨的挑戰。ACAP就是我們為了解決這項挑戰所推出的具有顛覆性的創新型產品。”
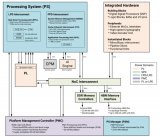
據介紹,ACAP結合了分布式存儲器與硬件可編程的DSP 模塊、一個多核SoC 以及一個或多個軟件可編程且同時又具備硬件自適應性的計算引擎,并全部通過片上網絡(NoC,Network on Chip)實現互連。
賽靈思在現場展示的112G高速收發器演示
ACAP還擁有高度集成的可編程I/O功能,根據不同的器件型號這些功能從集成式硬件可編程存儲器控制器,到先進的SerDes收發器技術(最高可支持112Gbps),前沿的RF-ADC/DAC和集成式高帶寬存儲器(HBM)。
軟件開發人員將能夠利用C/C++、OpenCL 和Python 等軟件工具應用ACAP系統。同時,ACAP也仍然能利用FPGA工具從RTL級進行編程。
賽靈思總裁兼首席執行官Victor Peng
賽靈思總裁兼CEOVictor Peng強調:“ACAP是一個全新的產品類別,它不是一個品牌的名稱,也不是FPGA。ACAP是可擴展的一體化程度非常高的計算平臺,它的硬件和軟件都是可編程的。也就是說,你可以用它來實現你想要的架構來優化網絡、優化算法,優化應用。也可以在幾秒甚至幾毫秒內改變這個架構,它能夠實現非常低的延時,非常高的通量,和原來產品類別有很大差異。”
全球首款ACAP——Versal系列
在此次的賽靈思開發者大會上,賽靈思正式發布了其歷時4年開放出的全球首款自適應計算加速平臺(ACAP)產品——Versal系列。其整合了標量處理引擎、自適應硬件引擎和智能引擎以及前沿的存儲器和接口技術,能為所有的應用提供強大的異構加速功能。
賽靈思稱Versal ACAP獨特架構針對云端、網絡、無線通信乃至邊緣計算和端點等不同市場的眾多應用提供了可擴展性和 AI 推斷功能,將為所有的開發者開發任何應用開啟了一個快速創新的新時代。
具體來說,Versal系列產品均基于臺積電最新的7nmFinFET工藝,是第一個將軟件可編程性與特定領域硬件加速和靈活應變能力相結合的平臺。該產品組合包括了6個系列的器件:基礎系列(Versal Prime),旗艦系列(Versal Premium旗艦)系列和HBM系列(能針對要求最嚴格的應用提供業界領先的性能、連接性、帶寬和集成功能)。此外,該產品組合還包括AI核心系列(AI Core),AI邊緣系列( AI Edge) 和AI射頻系列(AI RF),Versal AI系列均采用了突破性的AI引擎。
據賽靈思介紹,ACAP的AI引擎是一種新型硬件模塊,專為解決各種應用低時延 AI 推斷的新需求而設計,同時支持高級DSP實現方案,滿足無線和雷達等應用要求。它與Versal的自適應硬件引擎緊密結合,支持整體應用加速,也就是說軟硬件都能調節,從而確保最高性能和效率。
不過,此次開發者大會上,賽靈思只發布了Versal基礎系列和Versal AI核心系列,這兩款芯片有望在今年年底流片。而Versal旗艦系列和AI Edge將會在明年上半年發布;AI RF系列將會在明年下半年發布。至于Versal HBM系列可能要等到2021年下半年才會發布。
Versal AI核心系列
據賽靈思介紹,Versal AI核心系列可提供Versal AI系列當中最高的計算性能和最低的時延,可實現突破性的 AI 推斷吞吐量和性能。該系列主要針對云端、網絡和自動駕駛技術進行了優化(支持L4級別的自動駕駛),可提供業界最廣泛的 AI 和工作負載加速功能。
Versal AI 核心系列有5款產品,可提供128到400個AI引擎。
該系列還包括雙核 Arm Cortex-A72 應用處理器、雙核 Arm Cortex-R5 實時處理器、256KB片上ECC存儲器、超過1900個專為高精度低時延浮點運算而優化的 DSP引擎。
此外,它還包括 190 多萬個系統邏輯單元以及超過 130Mb 的 UltraRAM、高達 34Mb 的塊 RAM 和 28Mb 分布式 RAM 和 32Mb 新加速器 RAM 塊,任何引擎都能直接訪問,這也是 Versal AI 系列的獨特之處,而且都能支持定制存儲器架構。
該系列還包括 PCIe Gen4 8 信道和 16 信道以及 CCIX 主機接口、功耗優化型 32G SerDes、多達 4 個集成型 DDR4 存儲器控制器、多達 4 個多速率以太網 MAC、650 個高性能 I/O(用于 MIPI D-PHY)、NAND、存儲級內存接口和 LVDS、78 個多路復用 I/O(連接外部組件)和超過 40 個 HD I/O(3.3V 接口)。
以上所有器件均通過業界一流的片上網絡 (NoC) 實現互聯,具有多達 28 個主/從端口,以低時延提供每秒多 Tb 帶寬,而且提供高功率效率和原生軟件的可編程性。
Versal基礎系列
相對于Versal AI核心系列來說,Versal基礎系列最大的不同就是沒有了AI內核,取而代之的則是更大面積的DSP,并針對各種工作負載的連接性和在線加速進行了優化。適用于多個市場的廣泛應用。
Versal基礎系列包括 9 款產品,每款產品都采用雙核Arm Cortex-A72 應用處理器、雙核 Arm Cortex-R5 實時處理器、256KB 片上存儲器(帶 ECC)、超過 4000 個專為低時延高精度浮點運算優化的 DSP 引擎。
此外,它還包括 200 多萬個系統邏輯單元,結合 200Mb 以上 UltraRAM、超過 90Mb 的塊 RAM 以及 30Mb 分布式 RAM,能支持定制存儲器架構。該系列還包括 PCIe?Gen4 8信道和 16 信道以及 CCIX 主機接口、功耗優化型 32Gb 每秒的 SerDes 和主流 58Gb 每秒的 PAM4 SerDes、多達 6 個集成型 DDR4 存儲器控制器、多達 4 個多速率以太網 MAC、700 個高性能 I/O(支持 MIPI D-PHY)、NAND、存儲級內存接口和 LVDS、78 個多路復用 I/O(連接外部組件)和超過 40 個 HD I/O(3.3V 接口)。
以上均通過業界一流的片上網絡 (NoC) 實現互聯,具有多達 28 個主/從端口,以低時延提供每秒多 Tb 帶寬,而且提供高功率效率和原生的軟件可編程性。
性能對比
從上面的介紹來看,作為目前賽靈思ACAP的首款產品Versal系列,其各項指標和參數都很出色。那么其AI性能與目前主流的高端CPU和GPU相比又如何呢?
根據賽靈思公布的數據顯示,在時延不敏感的AI推斷上,基于GoogleNet-V1網絡模型測試,Versal的CNN性能是英特爾Xeon Platinum8124 CPU的43倍,是Nvidia V100 GPU的兩倍。
如果要將時延控制在7ms以內,那么Versal系列的CNN性能優勢將會進一步提升,達到英特爾XeonPlatinum8124Skylake CPU的72倍,Nvidia V100 GPU的2.5倍。
如果將時延控制在更低的2ms之內,那么Versal系列的CNN性能將達到Nvidia V100 GPU的8倍。
以基于GoogleNet-V1網絡低于2ms時延的圖片識別測試下,Versal核心系列可以實現每秒22500張圖片的識別,相比Nvidia今年發布的TeslaT4 GPU的性能(每秒3500張)高出約6.5倍。
如果再加上賽靈思收購的深鑒科技的“剪枝技術”的加持,Versal核心系列在2ms以內的低時延圖像識別上的性能可進一步提升至每秒29250張,相比Nvidia TeslaT4 GPU的性能可高出8倍以上。
Versal工具和軟件
軟件開發者、數據科學家和硬件開發者均可通過C/C++、OpenCL 和Python 等軟件工具應用對Versal ACAP的硬件和軟件進行編程和優化,同時,ACAP也仍然能利用FPGA工具從RTL級進行編程。開發者用一個界面就可以接入和控制各種引擎。這都要歸功于其符合業界標準設計流程的一系列工具、軟件、庫、IP、中間件和框架。
不過,具體的軟件編程工具需要等到明年才會發布。
供貨情況
賽靈思目前正通過早期試用計劃與多家關鍵客戶合作。Versal基礎系列和Versal AI核心系列將于今年年底流片,預計2019年下半年上市。
加碼數據中心,Alveo速器卡發布
除了發布了全新的Versal系列之外,賽靈思此次還首次推出了針對數據中心設計的功能強大的加速器卡——Alveo。用戶在通過Alveo運行實時機器學習推斷以及視頻處理、基因組學、數據分析等關鍵的數據中心應用時,有望以較低時延實現突破性的性能提升。
此次賽靈思發布了兩款Alveo加速卡:Alveo U200和AlveoU250。不過這兩款產品并不是采用Versal系列芯片,而是采用的是賽靈思UltraScale+FPGA方案。不過,其與所有賽靈思技術一樣,客戶能對硬件進行重配置,從而針對工作負載遷移、新標準和更新的算法進行優化,而且無需支付替代產品衍生的成本。
據賽靈思介紹稱,Alveo加速器卡針對各種類型的應用提供顯著的性能優勢。就機器學習而言,在GoogLeNet V1網絡下,Alveo U250實時推斷吞吐量比英特爾Xeon Platinum Skylake CPU(c5.18xlarge 實例)高出20倍,相對于Nvidia V100 GPU等固定功能的加速器,能讓2ms以下的低時延應用性能提升4倍以上。
此外,Alveo 加速器卡相對于 GPU 能將時延減少 3 倍,在運行實時推斷應用時提供顯著的性能優勢。比如在CNN+BLSTM 語音轉文本應用時,可從根本上得到加速(Alveo U250 或 U200 +Intel Xeon CPU E5-2686 v4 的運行速度是 Nvidia P4 + Xeon CPU E5-2690v4 的 4 倍);數據庫搜索等一些應用可從根本上得到加速,性能比CPU(EC2 C4.8xlarge 實例)高90倍以上。
“Alveo加速器卡第一是速度快;第二是架構和算法靈活多變;第三是容易訪問、易于使用。”對于Alveo加速器卡的特點Victor Peng總結到。
據賽靈思介紹,Alveo已經得到了合作伙伴和 OEM 廠商生態系統的支持,OEM 廠商開發和認證的關鍵應用涵蓋 AI/ML、視頻轉碼、數據分析、金融風險建模、安全和基因組學等。Algo-Logic Systems Inc、Bigstream、BlackLynx Inc.、CTAccel、Falcon Computing、Maxeler Technologies、Mipsology、NGCodec、Skreens、SumUp Analytics、Titan IC、Vitesse Data、VYUsync 和 Xelera Technologies等14家生態系統合作伙伴開發完成的應用可立即投入部署。此外,頂級 OEM 廠商也在同賽靈思合作,認證采用 Alveo 加速器卡的多個服務器 SKU,包括 Dell EMC、Fujitsu Limited 和 IBM 等,此外還有 OEM 廠商會加入進來。
賽靈思的數據中心副總裁 Manish Muthal 指出:“Alveo加速器卡的推出進一步推進了賽靈思向平臺公司的轉型,使不斷增長的應用合作伙伴生態系統以比以往更快的速度加速創新。我們很高興客戶對Alveo加速器的高度興趣,也很高興與我們的應用生態系統展開合作,共同向客戶推出采用Alveo的各種可產品化的的解決方案。”
另外值得一提的是,在此次賽靈思開發者大會上,華為和浪潮也發布了基于賽靈思的FPGA打造自己加速卡產品。
轉型平臺廠商
賽靈思總裁兼首席執行官(CEO)Victor Peng 表示:“自從賽靈思發明FPGA到現在已經有三十多年的時間,FPGA也變得越來越強大和復雜,我們現在已經超越了FPGA。賽靈思已經不再是一家FPGA的企業,我們已經轉型為一家面向靈活應變、萬物智能世界的平臺公司,而且我們這個轉型也要超越FPGA這個器件來打造整個平臺,因為這將使得我們能夠更好的滿足客戶的需求,尤其是在當今這個高速變化時代。”
為了順利的轉型為一家平臺型公司,Victor Peng將“數據中心優先”、加速核心市場發展和驅動靈活應變的計算這三個方面作為了賽靈思公司戰略轉型的進一步深入。
在此次開發者大會上,賽靈思發布的全球首款自適應異構計算加速平臺ACAP Versal以及針對數據中心的Alveo加速器卡,也正是賽靈思轉型平臺廠商新戰略的進一步深化。特別是ACAP更是被賽靈思寄予厚望。而后續賽靈思也必定會推出基于ACAP的加速卡。而這又將進一步助力賽靈思的數據中心優先戰略。
“ACAP將實現高通量、可擴展、低延遲的性能,目前可以應用在很多的應用場景當中。我們認為ACAP未來將會幾乎進入到每一個市場當中。”Victor Peng在賽靈思開發者大會上非常有信心的說到。
-
賽靈思
+關注
關注
32文章
1794瀏覽量
130957 -
AI芯片
+關注
關注
17文章
1828瀏覽量
34661
原文標題:AI芯片迎來”新物種“,賽靈思Versal ACAP詳解
文章出處:【微信號:icsmart,微信公眾號:芯智訊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
第二代AMD Versal Prime系列自適應SoC的亮點
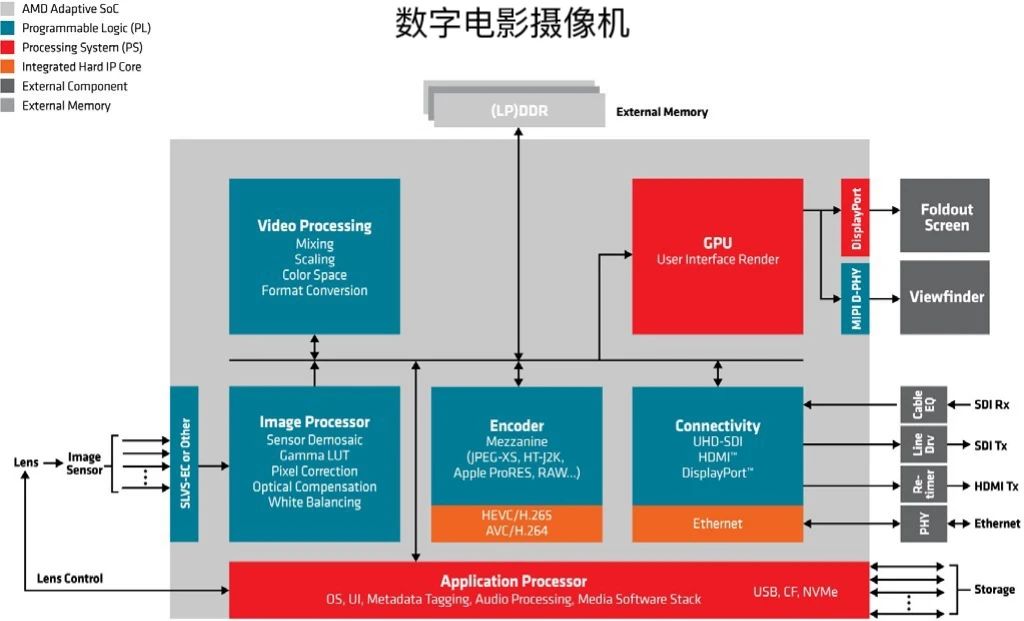
ALINX受邀參加AMD自適應計算峰會
PMP22165.1-適用于 Xilinx 通用自適應計算加速平臺 (ACAP) 的電源 PCB layout 設計

AMD發布第二代Versal自適應SoC,AI嵌入式領域再提速
在Vivado中構建AMD Versal可擴展嵌入式平臺示例設計流程
AMD Versal AI Edge自適應計算加速平臺之PL通過NoC讀寫DDR4實驗(4)

AMD Versal AI Edge自適應計算加速平臺之PL LED實驗(3)
AMD Versal AI Edge自適應計算加速平臺PL LED實驗(3)

【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之 Versal 介紹(2)
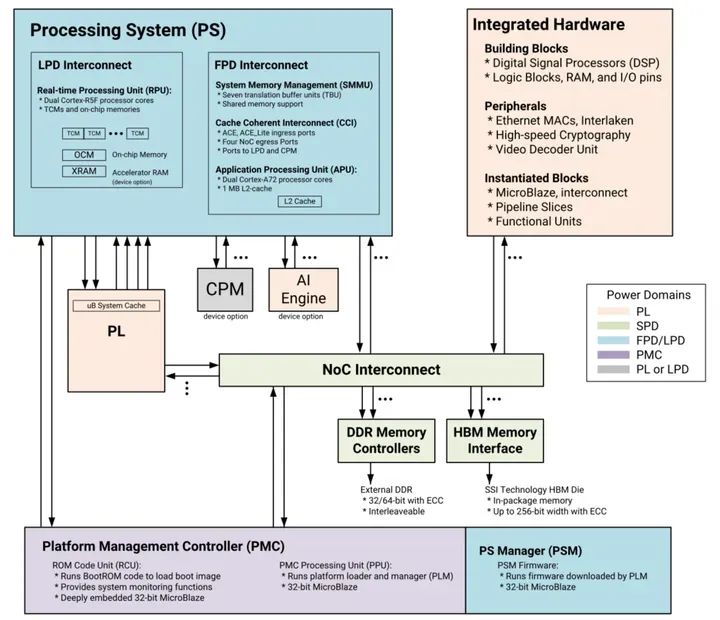
【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之準備工作(1)
AMD Versal AI Edge自適應計算加速平臺之Versal介紹(2)
AMD Versal系列CIPS IP核介紹





 工商網監
工商網監
評論