 淺談ug1292中的降低邏輯延遲的解決方案
淺談ug1292中的降低邏輯延遲的解決方案
在實現階段,Vivado會把最關鍵的路徑放在首位,這就是為什么在布局或布線之后可能出現邏輯級數低的路徑時序反而未能收斂。因此,在綜合或opt_design之后就要確認并優化那些邏輯級數較高的路徑。這些路徑可有效降低工具在布局布線階段為達到時序收斂而迭代的次數。同時,這類路徑往往邏輯延遲較大。因此,降低這類路徑的邏輯延遲對于時序收斂將大有裨益。
降低邏輯延遲的流程如下圖所示。不難看出,這一工作應在綜合或者opte_design階段完成。

在這個流程中,我們需要關注兩類路徑。一類路徑是由純粹的CLB中的資源(FF,LUT,Carry,MUXF)構成的路徑;另一類則是Block(DSP,BRAM,URAM,GT)之間的路徑。
無論是哪種路徑,首先要通過命令report_design_analysis進行定位,具體命令格式如下圖所示(也可在Vivado菜單Reports -> Report Design Analysis下執行)。
該命令可分析當前設計的邏輯級數分布情況,如下圖所示,從而便于找到邏輯級數較高的路徑。
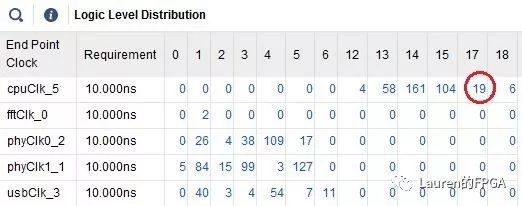
點擊邏輯級數分布報告中的數字,例如圖中的19,可生成相應的時序報告,從而確定屬于哪類路徑,并進一步觀察路徑特征。
對于級聯的小的LUT
如果路徑中包含多個級聯的小的LUT,檢查一下這些LUT是否是因為設計層次、綜合屬性(KEEP,KEEP_HIERARCHY,DONT_TOUCH,MARK_DEBUG)等導致無法合并。
對于路徑中存在單個的Carry
如果路徑中有單個的Carry(不是級聯的),檢查一下這個Carry是否限制了工具對LUT的優化,從而造成布局不是最優的。如果是,可嘗試在綜合時使用FewerCarryChains策略或者在opt_design階段對這個Carry設置CARRY_REMAP屬性(具體使用方法可查看ug904)。
對于終點是SRL的路徑
如果路徑的終點是SRL,可嘗試將SRL變為FF+SRL+FF或SRL+FF。這可在綜合時通過使用SRL_STYLE綜合屬性實現,也可在opt_design階段通過使用SRL_STAGES_TO_INPUT或SRL_STAGES_TO_OUTPUT實現。
對于終點是觸發器控制端的路徑
如果路徑的終點是由LUT輸出連接到觸發器的同步使能端或同步復位端,可嘗試將這類邏輯搬移到觸發器的數據端,這可在綜合時通過設置EXTRACT_ENABLE或EXTRACT_RESET綜合屬性實現,或者在opt_design階段通過設置CONTROL_SET_REMAP屬性(具體使用方法可查看ug904)實現。
使用Retiming
此外,還可以在綜合時對全局使用retiming(選中-retiming選項)或者采用模塊化綜合方式,對某個模塊使用retiming。
對于Block到Block的路徑
對于Block到Block的路徑,最好將其優化為Block + FF + Block。這里的FF可以是Block內部自帶的觸發器(如果有的話),也可以是Slice中的觸發器。
如果數據由Block RAM輸出,可采用如下命令觀察使能Block RAM自帶的寄存器之后是否對時序有所改善。這里要注意,如下命令用于評估,因為已造成設計功能改變,所有不要在此基礎上生成bit文件。
set_property –dict {DOA_REG 1 DOB_REG 1} [get_cellsxx/ramb18_inst]
該命令等效于
set_property DOA_REG 1
[get_cells xx/ramb18_inst]
set_property DOB_REG 1
[get_cells xx/ramb18_inst]
-
邏輯
+關注
關注
2文章
832瀏覽量
29449 -
觸發器
+關注
關注
14文章
1996瀏覽量
61055 -
ug1292
+關注
關注
0文章
3瀏覽量
2317
原文標題:深度解析ug1292(5)
文章出處:【微信號:Lauren_FPGA,微信公眾號:FPGA技術驛站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ug1292時序收斂快速參考手冊

ug1292深度解析
UG1292使用之初始設計檢查使用說明

深度解析ug1292:降低布線延遲
數據采集系統中降低功耗的解決方案

DC1292A DC1292A評估板
AD1292R芯片手冊
【虹科方案】西部數據超低延遲NVMe存儲解決方案

UltraFast設計方法時序收斂快捷參考指南(UG1292)







 工商網監
工商網監
評論