 LSTM和GRU的動態圖解
LSTM和GRU的動態圖解
編者按:關于LSTM,之前我們已經出過不少文章,其中最經典的一篇是chrisolah的《一文詳解LSTM網絡》,文中使用的可視化圖片被大量博文引用,現在已經隨處可見。但正如短視頻取代純文字閱讀是時代的趨勢,在科普文章中,用可視化取代文字,用動態圖取代靜態圖,這也是如今使知識更易于被讀者吸收的常規操作。
今天,論智給大家帶來的是AI語音助理領域的機器學習工程師Michael Nguyen撰寫的一篇LSTM和GRU的動態圖解:對于新手,它更直觀易懂;對于老手,這些新圖絕對值得收藏。
在這篇文章中,我們將從LSTM和GRU背后的知識開始,逐步拆解它們的內部工作機制。如果你想深入了解這兩個網絡的原理,那么這篇文章就是為你準備的。
問題:短期記憶
如果說RNN有什么缺點,那就是它只能傳遞短期記憶。當輸入序列夠長時,RNN是很難把較早的信息傳遞到較后步驟的,這意味著如果我們準備了一段長文本進行預測,RNN很可能會從一開始就遺漏重要信息。
出現這個問題的原因是在反向傳播期間,RNN的梯度可能會消失。我們都知道,網絡權重更新依賴梯度計算,RNN的梯度會隨著時間的推移逐漸減小,當序列足夠長時,梯度值會變得非常小,這時權重無法更新,網絡自然會停止學習。
梯度更新規則
根據上圖公式:新權重=權重-學習率×梯度。已知學習率是個超參數,當梯度非常小時,權重和新權重幾乎相等,這個層就停止學習了。由于這些層都不再學習,RNN就會忘記在較長序列中看到的內容,只能傳遞短期記憶。
解決方案:LSTM和GRU
LSTM和GRU都是為了解決短期記憶這個問題而創建的。它們都包含一種名為“控制門”的內部機制,可以調節信息流:
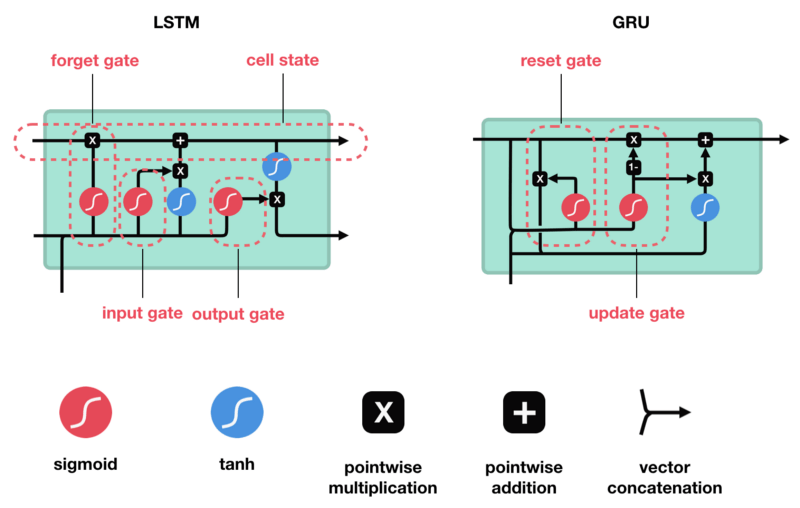
這些門能判斷序列中的哪些數據是重要的,哪些可以不要,因此,它就可以沿著長序列傳遞相關信息以進行預測。截至目前,基于RNN的幾乎所有實際應用都是通過這兩個網絡實現的,無論是語音識別、語音合成,還是文本生成,甚至是為視頻生成字幕。
在下文中,我們會詳細介紹它們背后的具體思路。
人類的記憶
讓我們先從一個思維實驗開始。雙11快到了,假設你想買幾袋麥片當早餐,現在正在瀏覽商品評論。評論區的留言很多,你的閱讀目的是判斷評論者是好評還是差評:
以上圖評論為例,當你一目十行地讀過去時,你不太會關注“this”“give”“all”“should”這些詞,相反地,大腦會下意識被“amazing”“perfectly balanced breakfast”這些重點詞匯吸引。糾結了一晚上,最后你下單了。第二天,你朋友問起你為什么要買這個牌子的麥片,這時你可能連上面這些重點詞都忘光了,但你會記得評論者最重要的觀點:“will definitely be buying again”(肯定會再光顧)。
就像上圖展示的,那些不重要的詞仿佛一讀完就被我們從腦海中清除了。而這基本就是LSTM和GRU的作用,它們可以學會只保留相關信息進行預測,并忘卻不相關的數據。
RNN綜述
為了理解LSTM和GRU是怎么做到這一點的,我們先回顧一下它們的原型RNN。下圖是RNN的工作原理,輸入一個詞后,這個詞會被轉換成機器可讀的向量;同理,輸入一段文本后,RNN要做的就是按照順序逐個處理向量序列。
按順序逐一處理
我們都知道,RNN擁有“記憶”能力。處理向量時,它會把先前的隱藏狀態傳遞給序列的下一步,這個隱藏狀態就充當神經網絡記憶,它包含網絡以前見過的先前數據的信息。
將隱藏狀態傳遞給下一個時間步
那么這個隱藏狀態是怎么計算的?讓我們看看RNN的第一個cell。如下圖所示,首先,它會把輸入x和上一步的隱藏狀態組合成一個向量,使這個的向量具有當前輸入和先前輸入的信息;其次,向量經tanh激活,輸出新的隱藏狀態。
Tanh激活
激活函數Tanh的作用是調節流經網絡的值,它能把值始終約束在-1到1之間。
激活函數Tanh
當向量流經神經網絡時,由于各種數學運算,它會經歷許多次變換。假設每流經一個cell,我們就把值乘以3,如下圖所示,這個值很快就會變成天文數字,導致其它值看起來微不足道。
不用Tanh進行調節
而使用了Tanh函數后,如下圖所示,神經網絡能確保值保持在-1和1之間,從而調節輸出。
用Tanh進行調節
以上就是一個最基礎的RNN,它的內部構造很簡單,但具備從先前信息推斷之后將要發生的事的能力。也正是因為簡單,它所需的計算資源比LSTM和GRU這兩個變體少得多。
LSTM
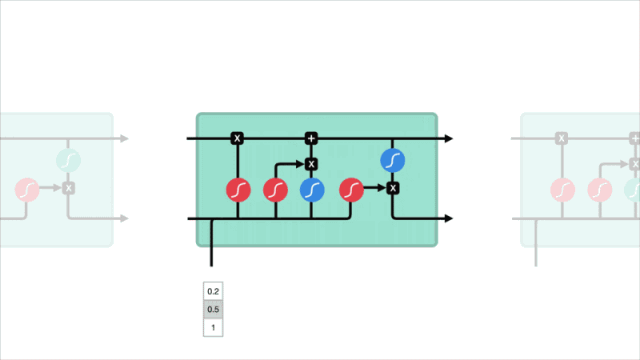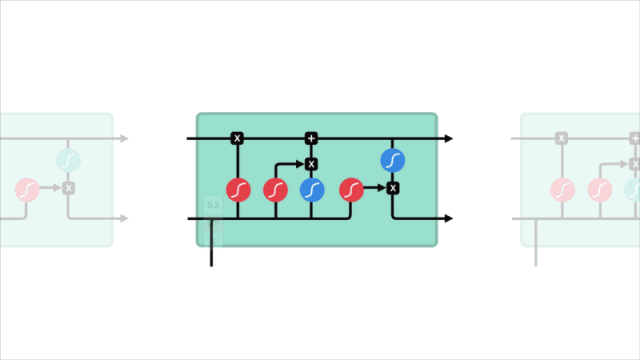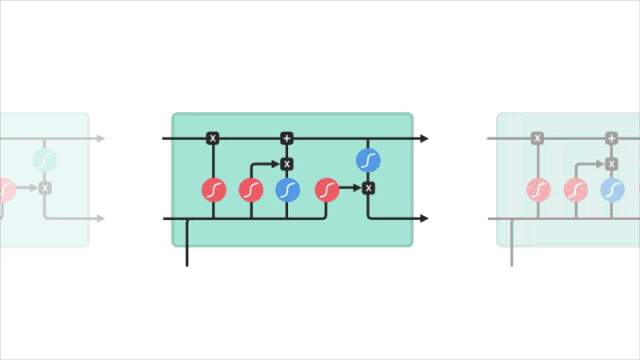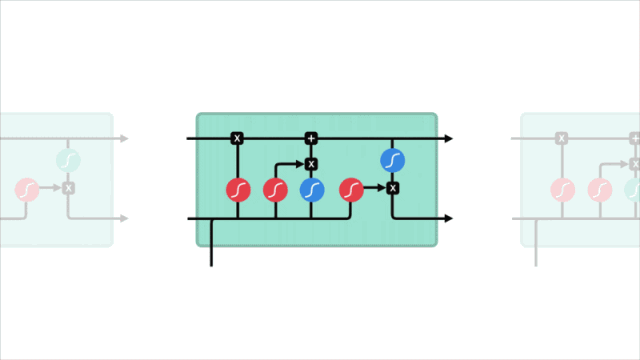
從整體上看,LSTM具有和RNN類似的流程:一邊向前傳遞,一邊處理傳遞信息的數據。它的不同之處在于cell內的操作:它們允許LSTM保留或忘記信息。
LSTM的神經元
核心概念
LSTM的核心概念是cell的狀態和各種控制門。其中前者是一個包含多個值的向量,它就像神經網絡中的“高速公路”,穿行在序列鏈中一直傳遞相關信息——我們也可以把它看作是神經網絡的“記憶”。從理論上來說,cell狀態可以在序列的整個處理過程中攜帶相關信息,它擺脫了RNN短期記憶的問題,即便是較早期的信息,也能被用于較后期的時間步。
而當cell狀態在被不斷傳遞時,每個cell都有3個不同的門,它們是不同的神經網絡,主要負責把需要的信息保留到cell中,并移除無用信息。
Sigmoid
每個門都包含sigmoid激活,它和Tanh的主要區別是取值范圍在0到1之間,而不是-1到1。這個特點有助于在cell中更新、去除數據,因為任何數字乘以0都是0(遺忘),任何數字乘以1都等于它本身(保留)。由于值域是0到1,神經網絡也能計算、比較哪些數據更重要,哪些更不重要。
激活函數Sigmoid
遺忘門
首先,我們來看3個門中的遺忘門。這個門決定應該丟棄哪些信息。當來自先前隱藏狀態的信息和來自當前輸入的信息進入cell時,它們經sigmoid函數激活,向量的各個值介于0-1之間。越接近0意味著越容易被忘記,越接近1則越容易被保留。
遺忘門的操作
輸入門
輸入門是我們要看的第二個門,它是更新cell狀態的重要步驟。如下圖所示,首先,我們把先前隱藏狀態和當前輸入傳遞給sigmoid函數,由它計算出哪些值更重要(接近1),哪些值不重要(接近0)。其次,同一時間,我們也把原隱藏狀態和當前輸入傳遞給tanh函數,由它把向量的值推到-1和1之間,防止神經網絡數值過大。最后,我們再把tanh的輸出與sigmoid的輸出相乘,由后者決定對于保持tanh的輸出,原隱藏狀態和當前輸入中的哪些信息是重要的,哪些是不重要的。
輸入門操作
cell狀態
到現在為止,我們就可以更新cell狀態了。首先,將先前隱藏狀態和遺忘門輸出的向量進行點乘,這時因為越不重要的值越接近0,原隱藏狀態中越不重要的信息也會接近0,更容易被丟棄。之后,利用這個新的輸出,我們再把它和輸入門的輸出點乘,把當前輸入中的新信息放進cell狀態中,最后的輸出就是更新后的cell狀態。
計算cell狀態
輸出門
最后是輸出門,它決定了下一個隱藏狀態應該是什么。細心的讀者可能已經發現了,隱藏狀態和cell狀態不同,它包含有關先前輸入的信息,神經網絡的預測結果也正是基于它。如下圖所示,首先,我們將先前隱藏狀態和當前輸入傳遞給sigmoid函數,其次,我們再更新后的cell狀態傳遞給tanh函數。最后,將這兩個激活函數的輸出相乘,得到可以轉移到下一時間步的新隱藏狀態。
總而言之,遺忘門決定的是和先前步驟有關的重要信息,輸入門決定的是要從當前步驟中添加哪些重要信息,而輸出門決定的是下一個隱藏狀態是什么。
代碼演示
對于更喜歡讀代碼的讀者,下面是一個Python偽代碼示例:
python偽代碼
首先,把先前隱藏狀態prev_ht和當前輸入input合并成combine
其次,把combine輸入遺忘層,決定哪些不相關數據需要被剔除
第三,用combine創建候選層,其中包含能被添加進cell狀態的可能值
第四,把combine輸入輸入層,決定把候選層中哪些信息添加進cell狀態
第五,更新當前cell狀態
第六,把combine輸入輸出層,計算輸出
最后,把輸出和當前cell狀態進行點乘,得到更新后的隱藏狀態
如上所述,LSTM網絡的控制流程不過是幾個張量操作和一個for循環而已。
GRU
現在我們已經知道LSTM背后的工作原理了,接下來就簡單看一下GRU。GRU是新一代的RNN,它和LSTM很像,區別是它擺脫了cell狀態,直接用隱藏狀態傳遞信息。GRU只有兩個門:重置門和更新門。
GRU
更新門
更新門的作用類似LSTM的遺忘門和輸入門,它決定要丟棄的信息和要新添加的信息。
重置門
重置門的作用是決定要丟棄多少先前信息。
相比LSTM,GRU的張量操作更少,所以速度也更快。但它們之間并沒有明確的孰優孰劣,只有適不適合。
小結
以上就是LSTM和GRU的動態圖解。總而言之,它們都是為了解決RNN短期記憶的問題而創建的,現在已經被用于各種最先進的深度學習應用,如語音識別、語音合成和自然語言理解等。
-
可視化
+關注
關注
1文章
1177瀏覽量
20889 -
機器學習
+關注
關注
66文章
8377瀏覽量
132411
原文標題:動態可視化指南:一步步拆解LSTM和GRU
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在網上看到泰克,rigol,安泰信測試1M的信號的動態圖,大....
請問為什么動態圖對滑動手勢沒有反應?
基于門限方案的動態圖軟件水印算法
動態圖和線程關系的混合軟件水印算法分析
基于快照的大規模動態圖相似節點查詢算法
周期性動態圖像的傅里葉表達
RNN及其變體LSTM和GRU
超生動圖解LSTM和GPU,讀懂循環神經網絡!
STM32GUI使用TouchGFX動態圖片功能實現動態更換表盤背景功能






 工商網監
工商網監
評論