") 如何選合適的AI硬件加速方案
如何選合適的AI硬件加速方案
從很多方面來看,AI加速熱潮與1990年代末期和2000年代初的DSP淘金熱很類似;在那個(gè)時(shí)候,隨著有線和無線通信起飛,市場(chǎng)上紛紛推出高性能DSP協(xié)同處理器(co-processor)以因應(yīng)基帶處理的挑戰(zhàn)。與DSP協(xié)同處理器一樣,AI加速器的目標(biāo)是找到最快速、最節(jié)能的方法來執(zhí)行所需的運(yùn)算任務(wù)。
從云端的大數(shù)據(jù)(big data)處理到邊緣端的關(guān)鍵詞識(shí)別和影像分析,人工智能(AI)應(yīng)用的爆炸式成長(zhǎng)促使專家們前仆后繼地開發(fā)最佳架構(gòu),以加速機(jī)器學(xué)習(xí)(ML)算法的處理。各式各樣的新興解決方案都凸顯了設(shè)計(jì)人員在選擇硬件平臺(tái)之前,明確定義應(yīng)用及其需求的重要性。
從很多方面來看,AI加速熱潮與1990年代末期和2000年代初的DSP淘金熱很類似;在那個(gè)時(shí)候,隨著有線和無線通信起飛,市場(chǎng)上紛紛推出高性能DSP協(xié)同處理器(co-processor)以因應(yīng)基帶處理的挑戰(zhàn)。與DSP協(xié)同處理器一樣,AI加速器的目標(biāo)是找到最快速、最節(jié)能的方法來執(zhí)行所需的運(yùn)算任務(wù)。
神經(jīng)網(wǎng)絡(luò)處理背后的數(shù)學(xué),涉及統(tǒng)計(jì)學(xué)、多元微積分(multivariable calculus)、線性代數(shù)、數(shù)值優(yōu)化(numerical optimization)和機(jī)率等;雖然很復(fù)雜,也是高度可平行化的(parallelizable)。但事實(shí)上這是令人尷尬的可平行化──與分布式計(jì)算不同,在路徑的輸出被重組并產(chǎn)生輸出結(jié)果之前,很容易被分解為沒有分支(branches)或從屬關(guān)系(dependencies)的平行路徑。
在各種神經(jīng)網(wǎng)絡(luò)算法中,卷積神經(jīng)網(wǎng)絡(luò)(CNN)特別擅長(zhǎng)對(duì)象識(shí)別類任務(wù)——也就是從影像中過濾篩選出感興趣的對(duì)象。CNN以多維矩陣(multidimensional matrices)──即張量(tensor)──架構(gòu)來理解資料,將超出第三個(gè)維度的每個(gè)維度都嵌入到子數(shù)組中(如圖1),每個(gè)添加的維度稱為“階”(order),因此,五階張量會(huì)有五個(gè)維度。
圖1:CNN以張量架構(gòu)攝取數(shù)據(jù),也就是可被可視化為3D立方體的數(shù)字矩陣(數(shù)據(jù)集);每個(gè)數(shù)組中還有一個(gè)子數(shù)組,該數(shù)字定義了CNN的深度。
與數(shù)學(xué)相關(guān)度不高,AI重點(diǎn)在于快速反復(fù)運(yùn)算
這種多維分層對(duì)于理解CNN所需之加速的本質(zhì)很重要,卷積過程使用乘法在數(shù)學(xué)上將兩個(gè)函數(shù)“卷繞”(roll)在一起,因此廣泛使用乘加(multiply-accumulate,MAC)數(shù)學(xué)運(yùn)算;舉例來說,在對(duì)象識(shí)別中,一個(gè)函數(shù)是源影像,另一個(gè)函數(shù)是用來識(shí)別特征然后將其映像到特征空間的過濾器(filter)。每個(gè)過濾器都要多次執(zhí)行這種“卷繞”,以識(shí)別影像中的不同特征,因此數(shù)學(xué)運(yùn)算變得非常重復(fù),且是令人尷尬(或令人愉悅)的可平行化。
為此,某些AI加速器的設(shè)計(jì)采用多個(gè)獨(dú)立的處理器核心(高達(dá)數(shù)百或上千個(gè)),與內(nèi)存子系統(tǒng)一起整合在單芯片中,以減輕數(shù)據(jù)存取延遲并降低功耗。然而,由于業(yè)界已設(shè)計(jì)了繪圖處理器(GPU)來對(duì)圖像處理功能進(jìn)行高度平行處理,因此它們對(duì)于AI所需的這種神經(jīng)網(wǎng)絡(luò)處理也可以實(shí)現(xiàn)很好的加速。AI應(yīng)用的多樣性和深度,特別是在語(yǔ)音控制、機(jī)器人、自動(dòng)駕駛和大數(shù)據(jù)分析等方面,已經(jīng)吸引了GPU供應(yīng)商將重點(diǎn)轉(zhuǎn)移到AI處理硬件加速的開發(fā)。
然而AI硬件加速的問題,在于有如此多的數(shù)據(jù),所需的準(zhǔn)確性和響應(yīng)時(shí)間又有如此大的差別,設(shè)計(jì)人員必須對(duì)于架構(gòu)的選擇非常講究。例如數(shù)據(jù)中心是數(shù)據(jù)密集型的,其重點(diǎn)是盡可能快速處理數(shù)據(jù),因此功耗并非特別敏感的因素——盡管能源效率有利于延長(zhǎng)設(shè)備使用壽命,降低設(shè)施的整體能耗和冷卻成本,這是合理的考慮。百度的昆侖(Kunlun)處理器耗電量為100W,但運(yùn)算性能達(dá)到260 TOPS,就是一款特別適合數(shù)據(jù)中心應(yīng)用的處理器。
接下來看另一個(gè)極端的案例。如關(guān)鍵詞語(yǔ)音識(shí)別這樣的任務(wù)需要與云端鏈接,以使用自然語(yǔ)言識(shí)別來執(zhí)行進(jìn)一步的命令。現(xiàn)在這種任務(wù)在采用法國(guó)業(yè)者GreenWaves Technologies之GAP8處理器的電池供電邊緣設(shè)備上就可以實(shí)現(xiàn);該處理器是專為邊緣應(yīng)用設(shè)計(jì),強(qiáng)調(diào)超低功耗。
介于中間的應(yīng)用,如自動(dòng)駕駛車輛中的攝影機(jī),則需要盡可能接近實(shí)時(shí)反應(yīng),以識(shí)別交通號(hào)志、其他車輛或行人,同時(shí)仍需要最小化功耗,特別是對(duì)于電動(dòng)車來說;這種情況或許需要選擇第三種方案。云端連結(jié)在此類應(yīng)用中也很重要,如此才能實(shí)時(shí)更新所使用的模型和軟件,以確保持續(xù)提高準(zhǔn)確度、反應(yīng)時(shí)間和效率。
ASIC還不足以托付AI加速任務(wù)
正因?yàn)檫@是一個(gè)在軟、硬件方面都迅速發(fā)展,需要在技術(shù)上持續(xù)更新的領(lǐng)域,并不建議將AI神經(jīng)網(wǎng)絡(luò)(NN)加速器整合到ASIC或是系統(tǒng)級(jí)封裝(SiP)中——盡管這樣的整合具有低功耗、占用空間小、成本低(大量時(shí))和內(nèi)存訪問速度快等優(yōu)點(diǎn)。加速器、模型和神經(jīng)網(wǎng)絡(luò)算法的變動(dòng)太大,其靈活性遠(yuǎn)超過指令導(dǎo)向(instruction-driven)方法,只有像Nvidia這種擁有先進(jìn)技術(shù)、資金雄厚的玩家才能夠負(fù)擔(dān)得起不斷在硬件,而在硬件上根據(jù)特定方法進(jìn)行迭代。
這種硬件加速器開發(fā)工作的一個(gè)很好的例子,就是Nvidia在其Tesla V100 GPU中增加了640個(gè)Tensor核心,每個(gè)核心在一個(gè)頻率周期內(nèi)可以執(zhí)行64次浮點(diǎn)(FP)融合乘加(fused-multiply-add,F(xiàn)MA)運(yùn)算,可為訓(xùn)練和推理應(yīng)用提供125 TFLOPS的運(yùn)算性能。借助該架構(gòu),開發(fā)人員可以使用FP16和FP32累加的混合精度(mixed precision)進(jìn)行深度學(xué)習(xí)訓(xùn)練,指令周期比Nvidia自家上一代Pascal架構(gòu)高3倍。
混合精度方法很重要,因?yàn)殚L(zhǎng)期以來人們已經(jīng)認(rèn)識(shí)到,雖然高性能運(yùn)算(HPC)需要使用32~256位FP的精確運(yùn)算,但深度神經(jīng)網(wǎng)絡(luò)(DNN)不需要這么高的精度;這是因?yàn)榻?jīng)常用于訓(xùn)練DNN的反向傳播算法(back-propagation algorithm)對(duì)誤差具有很強(qiáng)的彈性,因此16位半精度(FP16)對(duì)神經(jīng)網(wǎng)絡(luò)訓(xùn)練就足夠了。
此外,儲(chǔ)存FP16數(shù)據(jù)比儲(chǔ)存FP32或FP64數(shù)據(jù)的內(nèi)存效率更高,從而可以訓(xùn)練和部署更多的網(wǎng)絡(luò),而且對(duì)許多網(wǎng)絡(luò)來說,8位整數(shù)運(yùn)算(integer computation)就足夠了,對(duì)準(zhǔn)確性不會(huì)有太大影響。
這種使用混合精度運(yùn)算的能力在邊緣甚至?xí)鼘?shí)用,當(dāng)數(shù)據(jù)輸入的來源是低精度、低動(dòng)態(tài)范圍的傳感器——例如溫度傳感器、MEMS慣性傳感器(IMU)和壓力傳感器等——還有低分辨率視頻時(shí),開發(fā)人員可以折衷精度以取得低功耗。
AI架構(gòu)的選擇利用霧計(jì)算從邊緣擴(kuò)展至云端
可擴(kuò)充處理(scalable processing)的概念已經(jīng)擴(kuò)展到更廣泛的網(wǎng)絡(luò)——利用霧運(yùn)算(fog computing)概念,透過在網(wǎng)絡(luò)上的最佳位置執(zhí)行所需的處理,來彌補(bǔ)邊緣和云端之間的能力差距;例如可以在本地物聯(lián)網(wǎng)(IoT)網(wǎng)關(guān)或更接近應(yīng)用現(xiàn)場(chǎng)的本地端服務(wù)器上進(jìn)行神經(jīng)網(wǎng)絡(luò)圖像處理,而不必在云端進(jìn)行。這樣做有三個(gè)明顯的優(yōu)勢(shì):一是能減少由于網(wǎng)絡(luò)等待時(shí)間造成的時(shí)延,二來可以更安全,此外還能為必須在云端處理的數(shù)據(jù)釋出可用的網(wǎng)絡(luò)帶寬;在更高的層面上,這種方法也通常更節(jié)能。
因此,許多設(shè)計(jì)師正在開發(fā)內(nèi)建攝影機(jī)、影像預(yù)處理和神經(jīng)網(wǎng)絡(luò)AI信號(hào)鏈(signal chains)功能的獨(dú)立產(chǎn)品,這些產(chǎn)品僅在相對(duì)較閉回路(closed-loop)的運(yùn)作中呈現(xiàn)輸出,例如已識(shí)別標(biāo)志(自駕車)或人臉(家用安防系統(tǒng))。在更極端的案例中,例如設(shè)置在偏遠(yuǎn)或難以到達(dá)之處,以電池或太陽(yáng)能供電的設(shè)備,可能需要長(zhǎng)時(shí)間地進(jìn)行這種處理。
圖2:GreenWave的GAP8采用9個(gè)RISC-V處理器核心,針對(duì)網(wǎng)絡(luò)邊緣智能設(shè)備上的低功耗AI處理進(jìn)行了優(yōu)化。
為了幫助降低這種邊緣AI圖像處理的功耗,GreenWaves Technologies的GAP8處理器整合了9個(gè)RISC-V核心;其中一個(gè)核心負(fù)責(zé)硬件和I/O控制功能,其余8個(gè)核心則圍繞共享數(shù)據(jù)和指令內(nèi)存形成一個(gè)叢集(如圖2)。這種結(jié)構(gòu)形成了CNN推理引擎加速器,具備額外的RISC-V ISA指令來強(qiáng)化DSP類型的運(yùn)算。
GAP8是為網(wǎng)絡(luò)邊緣的智能設(shè)備量身打造,在功耗僅幾十毫瓦(mW)的情況下可實(shí)現(xiàn)8GOPS運(yùn)算,或者在1mW時(shí)可實(shí)現(xiàn)200 MOPS運(yùn)算;它完全可以用C/C++語(yǔ)言來編程,最小待機(jī)電流為70nA。
AI處理器架構(gòu)比一比:RISC-V vs. Arm
RISC-V開放性硬件架構(gòu)在一開始遭到質(zhì)疑,因?yàn)槟切枰粋€(gè)忠實(shí)穩(wěn)固的使用者社群,以提供一系列豐富的支持工具和軟件;而隨著該架構(gòu)透過各種測(cè)試芯片和硬件實(shí)作吸引更多開發(fā)者加入,那些質(zhì)疑也逐漸消退。RISC-V吸引人之處在于它正成為Arm處理器的強(qiáng)勁對(duì)手,特別是在超低功耗、低成本應(yīng)用上;只要談到低成本就會(huì)錙銖必較,因此免費(fèi)方案總是會(huì)感覺比需要支付授權(quán)費(fèi)的方案更好。
不過雖然RISC-V架構(gòu)的GAP8可以節(jié)能并且針對(duì)邊緣神經(jīng)網(wǎng)絡(luò)處理進(jìn)行了高度優(yōu)化,從系統(tǒng)開發(fā)的角度來看仍然需要考慮周邊功能,例如攝影機(jī)傳感器本身和網(wǎng)絡(luò)通訊接口,以及是采用有線還是無線技術(shù)等;依據(jù)系統(tǒng)通訊和處理影像的次數(shù)頻率,這些功能占用的功耗比例可能較高。根據(jù)GreenWaves的說法,GAP8若采用3.6Wh的電池供電,能以每3分鐘分類一張QVGA影像的頻率持續(xù)工作長(zhǎng)達(dá)10年;但該數(shù)字并未考慮整體系統(tǒng)中其他因素的影響。
GreenWaves將其GAP8處理器與采用Arm Cortex-M7核心、運(yùn)作頻率216MHz的意法半導(dǎo)體(ST)處理器STM32 F7進(jìn)行了直接比較(圖3);兩者以CIFAR-10數(shù)據(jù)集的影像進(jìn)行訓(xùn)練,權(quán)重量化為8位定點(diǎn)(fixed point)。
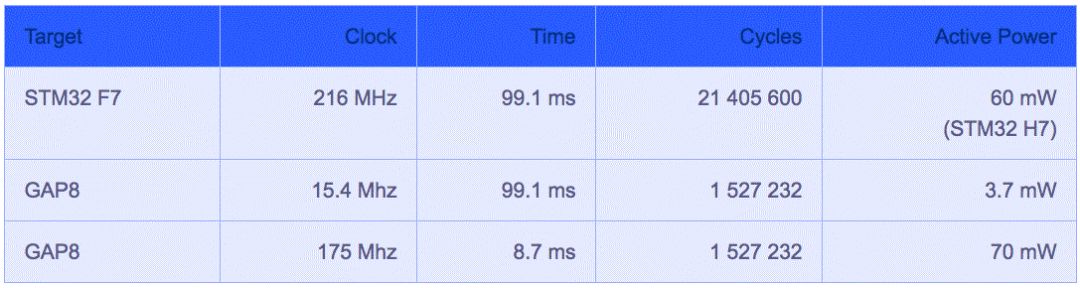
圖3:GreenWaves Technologies的GAP8與ST的STM32 F7處理器性能比較。
雖然GAP8因?yàn)閾碛邪撕诵募軜?gòu)而呈現(xiàn)更高效率,并能以較低時(shí)鐘速率與更少的周期實(shí)現(xiàn)推理,Arm架構(gòu)也不遑多讓──Arm已經(jīng)發(fā)表了針對(duì)行動(dòng)設(shè)備和其他相鄰、網(wǎng)絡(luò)邊緣應(yīng)用的機(jī)器學(xué)習(xí)(ML)處理器,其應(yīng)用場(chǎng)景包括AR/VR、醫(yī)療、消費(fèi)性電子產(chǎn)品以及無人機(jī)等;該架構(gòu)采用固定功能引擎(fixed-function engines)來執(zhí)行CNN層,并采用可程序化層(programmable layer)引擎來執(zhí)行非卷積層以及實(shí)現(xiàn)所選基元(primitive)和運(yùn)算符(operator),參考圖4。
圖4:Arm的ML處理器設(shè)計(jì)用于CNN類型固定功能以及可程序化層引擎的低功耗邊緣處理。
有趣的是,ML處理器是以高度可擴(kuò)充架構(gòu)為基礎(chǔ),因此同一處理器和工具可用于開發(fā)從物聯(lián)網(wǎng)到、嵌入式工業(yè)和交通,到網(wǎng)絡(luò)處理和服務(wù)器等各種應(yīng)用,運(yùn)算性能要求從20 MOPS到70 TOPS以上不等。
如果開發(fā)團(tuán)隊(duì)希望從云端往下擴(kuò)充,或從邊緣往上擴(kuò)充,那么這種可擴(kuò)充性比較適合之前討論的霧運(yùn)算概念。此外該處理器本身與主流神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)框架緊密整合,例如Google的TensorFlow和TensorFlow Lite,以及Caffe和Caffe 2;它還針對(duì)Arm Cortex CPU和Arm Mali GPU進(jìn)行了優(yōu)化。
在異構(gòu)處理體系架構(gòu)中部署AI
透過ML處理器,Arm還強(qiáng)調(diào)了異質(zhì)(heterogenous)方法對(duì)AI應(yīng)用之神經(jīng)網(wǎng)絡(luò)的重要性,但僅限于其CPU和GPU的狹窄范圍內(nèi)。從更廣泛的角度來看,英特爾(Intel)的OpenVINO (Visual Inference & Neural Network Optimization,視覺推理和神經(jīng)網(wǎng)絡(luò)優(yōu)化)工具套件可以實(shí)現(xiàn)異質(zhì)混合架構(gòu)的開發(fā),包括CPU、GPU與FPGA,當(dāng)然還有英特爾自家的Movidius視覺處理器(VPU)和基于Atom的圖像處理器(IPU)。利用通用API以及針對(duì)OpenCV和OpenVX優(yōu)化的呼叫(call),英特爾聲稱其深度學(xué)習(xí)性能可以提高19倍。
異質(zhì)方法對(duì)于針對(duì)AI的神經(jīng)網(wǎng)絡(luò)處理既有好處又不可或缺;當(dāng)從頭開始一個(gè)設(shè)計(jì),這種方法能開啟更多的處理可能性和潛在的優(yōu)化機(jī)會(huì)。但許多嵌入式系統(tǒng)已經(jīng)部署了相關(guān)硬件,通常是混合了MCU、CPU、GPU和FPGA,因此如果有開發(fā)工具可以在這樣的已設(shè)置硬件基礎(chǔ)上開發(fā)AI應(yīng)用,并透過單一API進(jìn)行相對(duì)應(yīng)的優(yōu)化(假設(shè)像OpenVINO這樣的工具套件是與底層硬件兼容),可以解決很多問題。
百度將AI處理性能推向新高
在今年7月初于北京舉行的百度開發(fā)者大會(huì)Create 2018上,該公司發(fā)表了昆侖(圖5),號(hào)稱是中國(guó)首款從云端到邊緣的AI芯片組,包括818-300訓(xùn)練芯片和818-100推理芯片。
圖5:百度的昆侖是中國(guó)第一款從云端到邊緣的AI處理器芯片組,雖然其架構(gòu)細(xì)節(jié)尚未公布,但號(hào)稱比百度2011年發(fā)表、基于FPGA的AI加速器快30倍。
昆侖號(hào)稱比百度2011年發(fā)表、基于FPGA的AI加速器快30倍,達(dá)到260 TOPS@100W;該芯片將采用三星(Samsung)的14納米工藝,內(nèi)存帶寬為512GB/s。雖然百度尚未公布其架構(gòu)參數(shù),但它可能包含數(shù)千個(gè)核心,能為百度自己的數(shù)據(jù)中心進(jìn)行巨量數(shù)據(jù)的高速平行處理;該公司也有計(jì)劃針對(duì)各種客戶端設(shè)備和邊緣處理應(yīng)用推出低性能版本。
在百度的昆侖發(fā)表前不久,Google于5月份也發(fā)表了TPU 3.0;Google并未透露該芯片細(xì)節(jié),只說速度比去年的版本快8倍,達(dá)到100 PFLOPS。
使用現(xiàn)有技術(shù)來啟動(dòng)AI設(shè)計(jì)
雖然還有許多其他新興的神經(jīng)網(wǎng)絡(luò)處理架構(gòu),如果是對(duì)“運(yùn)算性能vs.實(shí)時(shí)性能要求”有合理期望,目前也有許多處理器和工具套件能充分滿足邊緣運(yùn)算需求。例如,基本的家用保全系統(tǒng)可能包括一臺(tái)攝影機(jī),負(fù)責(zé)人臉識(shí)別處理并透過Wi-Fi連接到家庭網(wǎng)關(guān)或路由器,這用市面上現(xiàn)有的處理器或工具套件就可以實(shí)現(xiàn)。
想嘗試這種設(shè)計(jì)的開發(fā)人員不必從零開始,而是只要選擇一個(gè)已經(jīng)獲得廣泛支持的平臺(tái),具備各種CPU、視頻與圖片處理GPU、高速內(nèi)存、內(nèi)建無線和有線通訊模塊,還有恰當(dāng)?shù)?a target="_blank">操作系統(tǒng)支持和廣泛、活躍的用戶生態(tài)系統(tǒng)。
圖6:NXP的i.MX 8M解決了快速啟動(dòng)開發(fā)的問題,同時(shí)還可以使用基于Arm的處理器來擴(kuò)展AI應(yīng)用。
恩智浦半導(dǎo)體(NXP)的i.MX 8M就是一個(gè)合適的起點(diǎn)(圖6)。該方案實(shí)際上是一系列處理器,配備最多達(dá)四個(gè)的1.5GHz Arm Cortex-A53和Cortex-M4核心;內(nèi)含兩個(gè)GPU類型處理器,一個(gè)可用于影像預(yù)處理,另一個(gè)用于神經(jīng)網(wǎng)絡(luò)加速。
另一個(gè)關(guān)鍵設(shè)計(jì)需求是現(xiàn)場(chǎng)使用壽命要夠長(zhǎng),也就是系統(tǒng)要能夠耐受惡劣使用環(huán)境,特別像是安裝在室外的攝影機(jī);還要能隨著時(shí)間持續(xù)更新。后者特別重要,因?yàn)樵O(shè)計(jì)人員得確保設(shè)計(jì)中預(yù)留足夠的空間,以便在功能增加時(shí)實(shí)現(xiàn)更高的處理性能要求;同時(shí)還要保證低功耗,特別是對(duì)電池供電產(chǎn)品來說。
AI加速的重要性在于,其處理能力需求正從傳統(tǒng)的CPU和FPGA轉(zhuǎn)移到GPU和VPU,或者所有以上處理器的異質(zhì)組合;當(dāng)然這取決于應(yīng)用。在此同時(shí),即使針對(duì)越來越龐大數(shù)據(jù)集的AI加速成為主流,CPU的關(guān)鍵控制功能仍將保持不變。
-
無線通信
+關(guān)注
關(guān)注
58文章
4520瀏覽量
143414 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268421
原文標(biāo)題:如何針對(duì)不同的應(yīng)用,選合適的AI硬件加速方案?
文章出處:【微信號(hào):worldofai,微信公眾號(hào):worldofai】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

TDA4VM上的硬件加速運(yùn)動(dòng)恢復(fù)結(jié)構(gòu)算法

AM62A SoC通過硬件加速視覺處理改進(jìn)條形碼讀取器
適用于數(shù)據(jù)中心應(yīng)用中的硬件加速器的直流/直流轉(zhuǎn)換器解決方案
西門子推出Catapult AI NN軟件,賦能神經(jīng)網(wǎng)絡(luò)加速器設(shè)計(jì)
PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解決方案技術(shù)日在成都和西安站成功舉辦
Elektrobit利用其首創(chuàng)的硬件加速軟件優(yōu)化汽車通信網(wǎng)絡(luò)的性能
用DE1-SOC進(jìn)行硬件加速的2D N-Body重力模擬器設(shè)計(jì)

【國(guó)產(chǎn)FPGA+OMAPL138開發(fā)板體驗(yàn)】(原創(chuàng))7.硬件加速Sora文生視頻源代碼
音視頻解碼器硬件加速:實(shí)現(xiàn)更流暢的播放效果






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論