 從生產層面強調了深度學習項目開發中需要更加重視數據集的構建
從生產層面強調了深度學習項目開發中需要更加重視數據集的構建
深度學習的研究和生產之間存在較大差異,在學術研究中,人們一般更重視模型架構的設計,并使用較小規模的數據集。本文從生產層面強調了深度學習項目開發中需要更加重視數據集的構建,并以作者本人的親身開發經驗為例子,分享了幾個簡單實用的建議,涉及了數據集特性、遷移學習、指標以及可視化分析等層面。無論是對于研究者還是開發者,這些建議都有一定的參考價值。
本文還得到了 Andrej Karpathy 的轉發:
作者簡介:Pete Warden 是 Jetpac Inc 的 CTO,著有《The Public Data Handbook》和《The Big Data Glossary》兩本 O'Reilly 出版的書,并參與建立了多個開源項目,例如 OpenHeatMap 和 Data Science Toolkit 等。
圖片來源:Lisha Li
Andrej Karpathy 在 Train AI(https://www.figure-eight.com/train-ai/)進行演講時展示了這張幻燈片,我非常喜歡它!它完美地展現了深度學習的研究與實際的生產之間的差異。學術論文大多僅僅使用公開數據中的一小部分作為數據集而關注創造和改進模型。然而據我所知,當人們開始在實際的應用中使用機器學習時,對于訓練數據的擔憂占據了他們的大部分時間。
有很多很好的理由可以用來解釋為什么研究人員如此關注于模型的架構,但這也確實意味著,對那些專注于將機器學習應用于生產環境中的人員來說,他們可以獲取到的相關資源是很少的。為了解決這個問題,我在會議上進行了關于「the unreasonable effectiveness of training data」的演講,而在這篇博客中,我想進一步闡述為什么數據如此重要以及改進它的一些實用技巧。
作為我工作的一部分,我與很多研究人員還有產品團隊之間進行了密切的合作。我看到當他們專注于模型構建這一角度時可以獲得很好的效果,而這也讓我篤信于改進數據的威力。將深度學習應用到大多數應用中的最大障礙是如何在現實世界中獲得足夠高的準確率,而據我所知,提高準確度的最快途徑就是改進訓練集。即使你在其他限制(如延遲或存儲空間)上遇到了阻礙,在特定的模型上提高準確率也可以幫助你通過使用規模較小的架構來對這些性能指標做出權衡。
語音數據集
我無法將我對于生產性系統的大部分觀察分享給大家,但我有一個開源的例子可以用來闡釋相同的模式。去年,我為 TensorFlow 創建了一個簡單的語音識別示例(https://www.tensorflow.org/tutorials/audio_recognition),結果表明在現有的數據集中,沒有哪一個是可以很容易地被用作訓練數據的。多虧了由 AIY 團隊幫助我開發的開放式語音記錄站點(https://aiyprojects.withgoogle.com/open_speech_recording)我才得以在很多志愿者的慷慨幫助下,收集到了 6 萬個記錄了人們說短單詞的一秒鐘音頻片段。在這一數據訓練下的模型雖然可以使用,但仍然沒有達到我想要的準確度。為了了解我設計模型時可能存在的局限性,我用相同的數據集發起了一個 Kaggle 比賽(https://www.kaggle.com/c/tensorflow-speech-recognition-challenge/)。參賽者的表現比我的簡單模型要好得多,但即使有很多不同的方法,多個團隊的精確度最終都僅僅達到了 91%左右。對我而言,這意味著數據本身存在著根本性的問題,而實際上參賽者們也的確發現了很多問題,比如不正確的標簽或被截斷過的音頻。這些都激勵著我去解決他們發現的問題并且增加這個數據集的樣本數量。
我查看了錯誤度量標準,以了解模型最常遇到的問題,結果發現「其他」類別(當語音被識別出來,但這些單詞不在模型有限的詞匯表內時)更容易發生錯誤。為了解決這個問題,我增加了我們捕獲的不同單詞的數量,以提供更加多樣的訓練數據。
由于 Kaggle 參賽者報告了標簽錯誤,我通過眾包的形式增加了一個額外的驗證過程:要求人們傾聽每個片段并確保其與預期標簽相符。由于 Kaggle 競賽中還發現了一些幾乎無聲或被截斷的文件,我還編寫了一個實用的程序來進行一些簡單的音頻分析(https://github.com/petewarden/extract_loudest_section),并自動清除特別糟糕的樣本。最后,盡管刪除了錯誤的文件,但由于更多志愿者和一些付費的眾包服務人員的努力,我們最終獲得了超過 10 萬的發言樣本。
為了幫助他人使用數據集(并從我的錯誤中吸取教訓!)我將所有相關內容以及最新的結果寫入了一篇 arXiv 論文(https://arxiv.org/abs/1804.03209)。其中最重要的結論是,在不改變模型或測試數據的情況下,(通過改進數據)我們可以將 top-1 準確率從 85.4% 提高到 89.7%。這是一個巨大的提升(超過了 4%),并且當人們在安卓或樹莓派的樣例程序中使用該模型時,獲得了更好的效果。盡管目前我使用的遠非最優的模型,但我確信如果我將這些時間花費在調整模型上,我將無法獲得這樣的性能提升。
在生產的配置過程中,我多次見證了上述這樣的性能提升。當你想要做同樣的事情的時候,可能很難知道應該從哪里開始。你可以從我處理語音數據的技巧中得到一些靈感,但在接下來的內容中,我將為你介紹一些我認為有用的具體的方法。
首先,觀察你的數據
這看起來顯而易見,但你首先最應該做的是隨機瀏覽你將要使用的訓練數據。將一些文件復制到本地計算機上,然后花幾個小時來預覽它們。如果您正在處理圖片,使用類似于 MacOS 的取景器的功能滾動瀏覽縮略圖,將可以讓你快速地瀏覽數千個圖片。對于音頻,你可以使用取景器播放預覽,或者將文本隨機片段轉儲到終端。正因為我沒有花費足夠的時間來對第一版語音命令進行上述處理,Kaggle 參賽者們才會在開始處理數據時發現了很多問題。
我總是覺得這個過程有點愚蠢,但我從未后悔過。每當我完成這些工作時,我都可以發現一些對數據來說非常重要的事情,比如不同類別之間樣本數量的失衡、數據亂碼(例如擴展名標識為 JPG 的 PNG 文件)、錯誤的標簽,或者僅僅是令人驚訝的組合。Tom White 在對 ImageNet 的檢查中獲得了許多驚人的發現,比如:標簽「太陽鏡」,實際上是指一種古老的用來放大陽光的設備。Andrej 對 ImageNet 進行手動分類的工作(http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/)同樣教會了我很多與這個數據集相關的知識,包括如何分辨所有不同的犬種,甚至是人。
你將要采取的行動取決于你的發現,但是在你做任何其他數據清理工作之前,你都應該先進行這種檢查,因為對數據集內容的直觀了解有助于你在其余步驟中做出更好的決定。
快速地選擇一個模型
不要在選擇模型上花費太多時間。如果你正在進行圖像分類任務,請查看 AutoML,或查看 TensorFlow 的模型存儲庫(https://github.com/tensorflow/models/)或 Fast.AI 收集的樣例(http://www.fast.ai/)來找到你產品中面對的類似問題的模型。重要的是盡可能快地開始迭代,這樣你就可以盡早且經常性地讓實際用戶來試用你的模型。你隨時都可以上線改進的模型,并且可能會看到更好的結果,但你必須首先對數據進行合適的處理。深度學習仍然遵循「輸入決定輸出」的基本計算規律,所以即使是最好的模型也會受到訓練集中數據缺陷的限制。通過選擇模型并對其進行測試,你將能夠理解這些缺陷從而開始改進數據。
為了進一步加快模型的迭代速度,你可以嘗試從一個已經在大型現有數據集上預訓練過的模型開始,使用遷移學習來利用你收集到的(可能小得多的)一組數據對它進行微調。這通常比僅在較小的數據集上進行訓練的結果要好得多,而且速度更快,這樣一來你就可以快速地了解到應該如何調整數據收集策略。最重要的是,你可以根據結果中的反饋調整數據收集(和處理)流程,以便適應你的學習策略,而不是僅僅在訓練之前將數據收集作為單獨的階段進行。
在做到之前先假裝做到(人工標注數據)
建立研究和生產模型最大的不同之處在于,研究通常在開始時就有了明確的問題定義,而實際應用的需求潛藏在用戶的頭腦中,并且只能隨著時間的推移而逐漸獲知。例如,對于 Jetpac,我們希望找到好的照片并展示在城市的自動旅行指南中。剛開始我們要求評分者給他們認為好的照片打上標簽,但我們最終卻得到了很多張笑臉,因為這就是他們對這個問題的理解。我們將這些內容放入產品的展示模型中,來測試用戶的反應,結果發現這并沒有給他們留下什么深刻的印象。為了解決這個問題,我們將問題修改為「這張照片是否讓你想要前往它所展示的地方?」。這很大程度上提高了我們結果的質量,然而事實表明,來自東南亞的工作人員,更傾向于認為充滿了在大型酒店中穿西裝的人和酒杯的會議照片看起來令人驚嘆。這種不匹配是對我們生活的泡沫的一個提醒,但它同時也是一個實際問題,因為我們產品的目標受眾是美國人,他們看到會議照片會感到壓抑和沮喪。最終,我們六個 Jetpac 團隊的成員自己為超過 200 萬張照片進行了評分,因為我們比任何可以被訓練去做這件事的人都更清楚標準。
這是一個極端的例子,但它表明標注過程在很大程度上依賴于應用程序的要求。對于大多數生產用例來說,找出模型正確問題的正確答案需要花費很長的一段時間,而這對于正確地解決問題至關重要。如果你正在試圖讓模型回答錯誤的問題,那么將永遠無法在這個不可靠的基礎上建立可靠的用戶體驗。
圖片來自 Thomas Hawk
我發現能夠判斷你所問的問題是否正確的唯一方法是對你的應用程序進行模擬,而不是使用有人參與迭代的機器學習模型。因為在背后有人類的參與,這種方法有時被稱為「Wizard-of-Oz-ing」。在 Jetpac 的案例中,我們讓人們為一些旅行指南樣例手動選擇照片,而不是訓練一個通過測試用戶的反饋來調整挑選圖片的標準的模型。一旦我們可以很可靠地從測試中獲得正面反饋,我們接下來就可以將我們設計的照片選擇規則轉化為標注指導手冊,以便用這樣的方法獲得數百萬個圖像用作訓練集。然后,我們使用這些數據訓練出了能夠預測數十億張照片質量的模型,但它的 DNA 來自我們設計的原始的人工規則。
在真實數據上進行訓練
在 Jetpac 案例中,我們用于訓練模型的圖像和我們希望應用模型的圖像來源相同(主要是 Facebook 和 Instagram),但是我發現的一個常見問題是,訓練數據集與模型最終輸入數據的一些關鍵差異最終會體現在生產中。例如,我經常會看到基于 ImageNet 訓練的模型在被嘗試應用到無人機或機器人中時會遇到問題。這是因為 ImageNet 大多為人們拍攝的照片,而這些照片存在著很多共性,比如:用手機或照相機拍攝,使用中性鏡頭,大致在頭部高度,在白天或人造光線下拍攝,標記的物體居中并位于前景中等等。而機器人和無人機使用視頻攝像機,通常配有高視野鏡頭,拍攝位置要么是在地面上要么是在高空中,同時缺乏光照條件,并且由于沒有對于物體輪廓的智能判定,通常只能進行裁剪。這些差異意味著,如果你只是在 ImageNet 上訓練模型并將其部署到某一臺設備上,那么將無法獲得較好的準確率。
訓練數據和最終模型輸入數據的差異還可能體現在很多細微的地方。想象一下,你正在使用世界各地的動物數據集來訓練一個識別野生動物的相機。如果你只打算將它部署在婆羅洲的叢林中,那么企鵝標簽被選中的概率會特別低。如果訓練數據中包含有南極的照片,那么模型將會有很大的機會將其他動物誤認為是企鵝,因而模型整體的準確率會遠比你不使用這部分訓練數據時低。
有許多方法可以根據已知的先驗知識(例如,在叢林環境中大幅度降低企鵝的概率)來校準結果,但使用能夠反映產品真實場景的訓練集會更加方便和有效。我發現最好的方法是始終使用從實際應用程序中直接捕獲到的數據,這與我上面提到的「Wizard of Oz」方法之間存在很好的聯系。這樣一來,在訓練過程中使用人來進行反饋的部分可以被數據的預先標注所替代,即使收集到的標簽數量非常少,它們也可以反映真實的使用情況,并且也基本足夠被用于進行遷移學習的一些初始實驗了。
混淆矩陣
當我研究語音指令的例子時,我看到的最常見的報告之一是訓練期間的混淆矩陣。這是一個顯示在控制臺中的例子:
[[258 0 0 0 0 0 0 0 0 0 0 0] [ 7 6 26 94 7 49 1 15 40 2 0 11] [ 10 1 107 80 13 22 0 13 10 1 0 4] [ 1 3 16 163 6 48 0 5 10 1 0 17] [ 15 1 17 114 55 13 0 9 22 5 0 9] [ 1 1 6 97 3 87 1 12 46 0 0 10] [ 8 6 86 84 13 24 1 9 9 1 0 6] [ 9 3 32 112 9 26 1 36 19 0 0 9] [ 8 2 12 94 9 52 0 6 72 0 0 2] [ 16 1 39 74 29 42 0 6 37 9 0 3] [ 15 6 17 71 50 37 0 6 32 2 1 9] [ 11 1 6 151 5 42 0 8 16 0 0 20]]
這可能看起來很嚇人,但它實際上只是一個表格,顯示網絡出錯的詳細信息。這里有一個更加美觀的帶標簽版本:
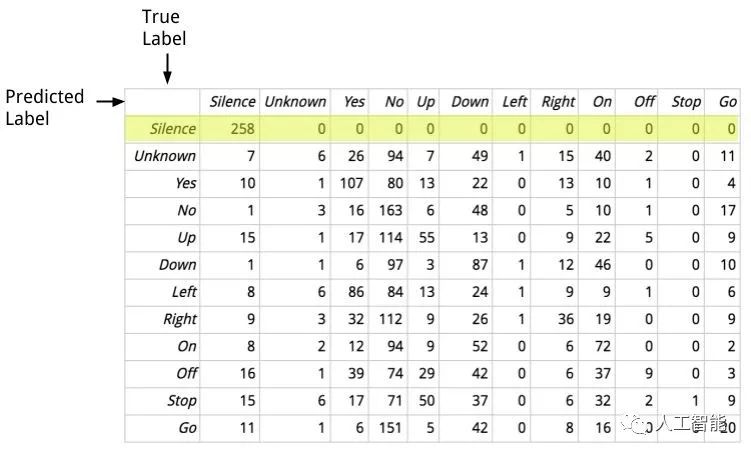
表中的每一行代表一組與真實標簽相同的樣本,每列顯示標簽預測結果的數量。例如,高亮顯示的行表示所有無聲的音頻樣本,如果你從左至右閱讀,則可以發現標簽預測的結果是正確的,因為每個標簽都落在」Silence」一欄中。這表明,該模型可以很好地識無聲的音頻片段,不存在任何一個誤判的情況。從列的角度來看,第一列顯示有多少音頻片段被預測為無聲,我們可以看到一些實際上是單詞的音頻片段被誤認為是無聲的,這其中有很多誤判。這些知識對我來說非常有用,因為它讓我更加仔細地觀察那些被誤認為是無聲的音頻片段,而這些片段事實上并不總是安靜的。這幫助我通過刪除音量較低的音頻片段來提高數據的質量,而如果沒有混淆矩陣的線索,我將無從下手。
幾乎所有對結果的總結都可能是有用的,但是我發現混淆矩陣是一個很好的折衷方案,它提供的信息比單個的準確率更多,同時也不會涵蓋太多我無法處理的細節。在訓練過程中觀察數字變化也很有用,因為它可以告訴你模型正在努力學習什么類別,并可以讓你在清理和擴充數據集時專注于某些方面。
可視化模型
可視化聚類是我最喜歡的用來理解我的網絡如何解讀訓練數據的方式之一。TensorBoard 為這種探索提供了很好的支持,盡管它經常被用于查看詞嵌入,但我發現它幾乎適用于與任何嵌入有類似的工作方式的網絡層。例如,圖像分類網絡在最后的全連接或 softmax 單元之前通常具有的倒數第二層,可以被用作嵌入(這就是簡單的遷移學習示例的工作原理,如 TensorFlow for Poets(https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#0))。嚴格意義上來說,這些并不是嵌入,因為我們并沒有在訓練過程中努力確保在真正的嵌入具有希望的空間屬性,但對它們的向量進行聚類確實會產生一些有趣的結果。
舉例來說,之前一個同我合作過的團隊對圖像分類模型中某些動物的高錯誤率感到困惑。他們使用聚類可視化來查看他們的訓練數據是如何分布到各種類別的,當他們看到「捷豹」時,他們清楚地發現數據被分成兩個彼此之間存在一定間隔的不同的組。
他們所看到的的圖表如上所示。一旦我們將每個聚類的圖片展示出來,結果就變得顯而易見:很多捷豹品牌車輛被錯誤地標記為捷豹(動物)。一旦他們知道了這一問題,他們就能夠檢查標注過程,并意識到工作人員的指導和用戶界面是令人困惑的。有了這些信息,他們就能夠改善標注者的訓練過程并修復工具中存在的問題,從而將所有汽車圖像從捷豹類別中刪除,進而讓模型在該類別上獲得更好的效果。
通過深入了解訓練集中的內容,聚類提供了與僅僅觀察數據相同的好處,但網絡實際上是通過根據自己的學習理解將輸入分組來指導你的探索。作為人類,我們非常善于從視覺上發現異常情況,所以將我們的直覺和計算機處理大量輸入的能力相結合為追蹤數據集質量問題提供了一個高可擴展的解決方案。關于如何使用 TensorBoard 來完成這樣的工作的完整教程超出了本文的范圍,但如果你真的想要提高結果,我強烈建議你熟悉這個工具。
持續收集數據
我從來沒有見過收集了更多的數據,但最終沒有提高模型準確性的情況,事實證明,有很多研究都支持我的這一經驗。
該圖來自「重新審視數據的不合理的有效性(https://ai.googleblog.com/2017/07/revisiting-unreasonable-effectiveness.html)」,并展示了在訓練集的規模增長到數以億計的情況下圖像分類的模型準確率如何持續增加。Facebook 最近進行了更進一步的探索,使用數十億有標注 Instagram 圖像在 ImageNet 圖像分類任務上取得了最優的準確率(https://www.theverge.com/2018/5/2/17311808/facebook-instagram-ai-training-hashtag-images)。這表明,即使對于已有大型、高質量數據集的任務來說,增加訓練集的大小仍然可以提高模型效果。
這意味著,只要任何用戶可以從更高的模型準確率中受益,你就需要一個可以持續改進數據集的策略。如果可以的話,找到創造性的方法利用微弱的信號來獲取更大的數據集(是一個可以嘗試的方向)。Facebook 使用 Instagram 標簽就是一個很好的例子。另一種方法是提高標注過程的智能化程度,例如通過將模型的初始版本的標簽預測結果提供給標注人員,以便他們可以做出更快的決策。這種方法的風險是可能在標注早期造成某種程度的偏見,但在實踐中,所獲得的好處往往超過這種風險。此外,通過聘請更多的人來標記新的訓練數據來解決這個問題,通常也是一項物有所值的投資,但是對這類支出沒有預算傳統的組織可能會遇到阻礙。如果你是非營利性組織,讓你的支持者通過某種公共工具更方便地自愿提供數據,這可能是在不增加開支的情況下增加數據集大小的可取方法。
當然,對于任何組織來說,最優的解決方案都是應該有一種產品,它可以在使用時自然生成更多的有標注數據。雖然我不會太在意這個想法,它在很多真實的場景中都不適用,因為人們只是想盡快得到答案,而不希望參與到復雜的標注過程中來。而對于初創公司來說,這是一個很好的投資熱點,因為它就像是一個改進模型的永動機,當然,在清理或增強數據時總是無法避免產生一些單位成本,所以經濟學家最終經常會選擇一種比真正免費的方案看起來更加便宜一點的版本。
潛在的風險
幾乎所有的模型錯誤對應用程序用戶造成的影響都遠大于損失函數可以捕獲的影響。你應該提前考慮可能的最糟糕的結果,并嘗試設計模型的后盾以避免它們發生。這可能只是一個因為誤報的成本太高而不想讓模型去預測的類別的黑名單,或者你可能有一套簡單的算法規則,以確保所采取的行動不會超過某些已經設定好的邊界參數。例如,你可能會維持一個你不希望文本生成器輸出的臟話詞表,即便它們存在于訓練集中。因為它們對于你的產品來說是很不合適的。
究竟會發生什么樣的不好結果在事前總是不那么明顯的,所以從現實世界中的錯誤中吸取教訓至關重要。最簡單的方法之一就是在一旦你有一個半成品的時候使用錯誤報告。當人們使用你的應用程序時,你需要讓他們可以很容易地報告不滿意的結果。要盡可能獲得模型的完整輸入,但當它們是敏感數據時,僅僅知道不良輸出是什么同樣有助于指導你的調查。這些類別可被用于選擇收集更多數據的來源,以及你應該去了解其哪些類別的當前標簽質量。一旦對模型進行了新的調整,除了正常的測試集之外,還應該對之前產生不良結果的輸入進行單獨的測試。考慮到單個指標永遠無法完全捕捉到人們關心的所有內容,這個錯例圖片庫有點像回歸測試,并且為你提供了一種可以用來跟蹤你改進用戶體驗程度的方式。通過查看一小部分在過去引發強烈反應的例子,你可以得到一些獨立的證據來表明你實際上正在為你的用戶提供更好的服務。如果因為過于敏感而無法獲取模型的輸入數據,請使用內部測試或內部實驗來確定哪些輸入可以產生這些錯誤,然后替換回歸數據集中的那些輸入。
在這篇文章中,我希望設法說服你在數據上花費更多時間,并給你提供一些關于如何改進它的想法。目前這個領域還沒有得到足夠的關注,我甚至覺得我在這里的建議是在拋磚引玉,所以我感謝每一個與我分享他們的策略的人,并且我希望未來我可以從更多的人那里了解到更多有成效的方法。我認為會有越來越多的組織分配工程師團隊專門用于數據集的改進,而不是讓機器學習研究人員來推動這一方向的進展。我期待看到整個領域能夠得益于在數據改進上的工作。我總是為即使在訓練數據存在嚴重缺陷的情況下模型也可以良好運作而感到驚嘆,所以我迫不及待地想看到在改進數據以后我們可以取得的效果!
-
數據集
+關注
關注
4文章
1205瀏覽量
24641 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:生產級深度學習的開發經驗分享:數據集的構建和提升是關鍵
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用tensorflow快速搭建起一個深度學習項目





 工商網監
工商網監
評論