 索尼發布新的方法,在ImageNet數據集上224秒內成功訓練了ResNet-50
索尼發布新的方法,在ImageNet數據集上224秒內成功訓練了ResNet-50
深度神經網絡訓練速度越來越快已經不是新鮮事,但是,將ImageNet訓練時間降低到200秒級別仍然讓人震撼!近日,索尼發布新的方法,在ImageNet數據集上,使用多達2176個GPU,在224秒內成功訓練了ResNet-50,刷新了紀錄。
隨著用于深度學習的數據集和深度神經網絡模型的規模增大,訓練模型所需的時間也在增加具有數據并行性的大規模分布式深度學習可以有效縮短訓練時間。
然而,由于大型 mini-batch 訓練的不穩定性和梯度同步的開銷,將分布式深度學習擴展到大規模的GPU集群級別很有挑戰性。
日本索尼公司的Hiroaki Mikami等人近日提出一種新的大規模分布式訓練方法,通過控制batch size解決了大型mini-batch訓練的不穩定性,用2D-Torus all-reduce解決了梯度同步的開銷。
具體而言,2D-Torus all-reduce將GPU排列在一個邏輯2D網格中,并以不同的方向執行一系列操作。
這兩種技術都是基于索尼的神經網絡庫NNL(Neural Network Libraries)實現的。最終,索尼的研究人員在224秒內(使用多達2176個GPU)成功訓練了ImageNet/ResNet-50,并在ABCI 集群上沒有明顯的精度損失。
在ImageNet數據集上訓練ResNet-50是用于測量深度學習分布式學習速度的一般行業基準,該研究刷新了這個基準的速度。

論文地址:
https://arxiv.org/pdf/1811.05233.pdf
224秒!刷新深度學習紀錄
在大型GPU集群中,大規模分布式深度學習存在兩個技術問題。第一個問題large mini-batch訓練造成的收斂精度下降。第二個問題是GPU間梯度同步的通信開銷。解決這兩個問題需要一種新的分布式處理方法。
近年來,許多研究人員提出了多種方案來解決這兩個問題(見原文參考文獻)。這些工作利用ImageNet/ResNet-50訓練來衡量訓練效果。ImageNet/ResNet-50分別是最流行的數據集和最流行的DNN模型,用于對大規模分布式深度學習進行基準測試。
表1比較了近期一些工作的訓練時間和top-1驗證精度。其中,Facebook使用256個Tesla P100 GPU,在1小時內訓練完ResNet-50,是加速了這一任務的著名研究。
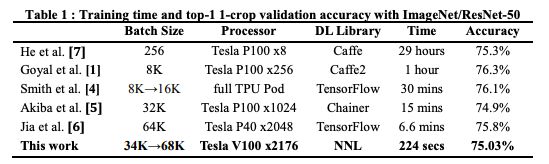
表1:ImageNet/ResNet-50訓練時間及top-1 -crop驗證精度
之前的其他一些業界最好水平來自:
日本Perferred Network公司Chainer團隊,15分鐘訓練好ResNet-50 [5]
騰訊機智團隊,6.6分鐘訓練好ResNet-50 [6]
索尼團隊的研究著重于解決大型mini-batch訓練的不穩定性和梯度同步開銷,他們使用2176 個Tesla V100 GPU,將訓練時間縮短至224秒,驗證精度為75.03%。
研究人員還嘗試在不造成明顯精度損失的情況下提高GPU scaling效率,使用1088個Tesla V100 GPU將GPU scaling效率提高到91.62%(表2)。

表2:ImageNet/ResNet-50訓練的GPU scaling 效率
2大方法解決不穩定問題
大規模分布式訓練有兩個主要問題:大型mini-batch訓練的不穩定性和同步通信的開銷。
眾所周知, large mini-batch訓練是不穩定的,會產生泛化差距。
數據并行分布式訓練需要在每個訓練迭代之間增加一個步驟,以便在參與的GPU之間同步和平均梯度。這個步驟是使用一個all-reduce的集合操作來實現的。在一個大型GPU集群中,all-reduce集合操作的開銷使得線性縮放變得非常具有挑戰性。
針對這兩個問題,我們使用Batch Size控制技術來解決不穩定問題,并開發了2D-Torus all-reducing方案,有效地跨GPU交換梯度。
Batch Size Control
以往的工作已經證明,在訓練期間逐漸增加總的mini-batch size可以減少大型 mini-batch訓練的不穩定性。直觀地說,隨著訓練的損失情況變得“平坦”而增加批大小有助于避免局部最小值。
在這項工作中,我們采用 Batch Size Control來減少精度下降, batch size超過了32K。在訓練期間采用了預定的batch-size來更改調度。
2 D-Torus All- reduce
有效的通信拓撲對于減少集體操作的通信開銷至關重要。
為了解決這個問題,我們開發了2D-Torus all-reduce。2D-Torus拓撲結構如圖1所示。集群中的GPU排列在2D網格中。在2D-torus拓撲中,all-reduce由三個步驟組成:reduce-scatter,all-reduce和all-gather。
圖1:2D-Torus拓撲由水平和垂直方向的多個環組成。
2D-Torus all-reduce的示例如圖2所示。
圖2:在2x2網格中,一個4-GPU集群的2D-Torus all-reduce步驟
評估:實驗設置和訓練設置
實驗設置
軟件:使用神經網絡庫(NNL)及其CUDA擴展,作為DNN訓練框架。通信庫使用NCCL和OpenMPI。2D-Torus all-reduce在NCCL上實現。以上軟件打包在Singularity容器中,用于運行分布式DNN訓練。
硬件:使用AI橋接云基礎設施(ABCI)作為GPU集群。ABCI是日本先進工業科技研究所(AIST)運營的GPU集群。它包括1088個節點,每個節點有4個NVIDIA Tesla V100 GPU,2個Xeon Gold 6148處理器,376 GB內存。同一節點的GPU由NVLink互連,而節點由2個InfiniBand EDR互連。
數據集和模型:使用ImageNet數據集。使用ResNet-50作為DNN模型。模型中的所有層都由[9]中描述的值初始化。
訓練設置:
使用LARS [9],系數為0.01,eps為1e-6更新權重。學習率(LR)通過以下公式計算:
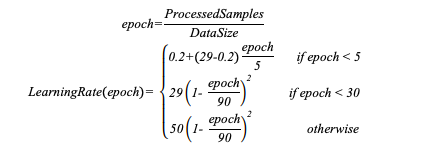
用以下公式計算出總的mini-batch size和學習率。

我們還采用了[15]中介紹的混合精度訓練。前向/后向計算和同步梯度的通信在半精度浮點(FP16)中進行。
我們調整每個worker和總batch size,如表3所示,直到將總batch size增到最大。通過增加GPU的數量(Exp.1到Exp.4)來嘗試提高最大總batch size。
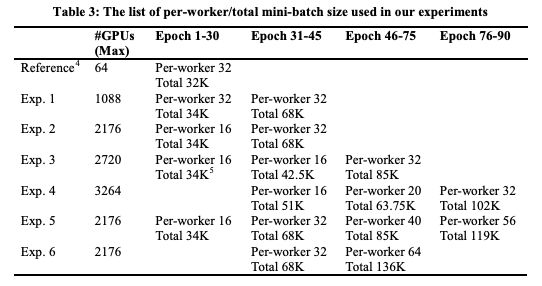
表3:per-worker/total mini-batch size
但是,當使用超過2176個GPU時,訓練效率變低了。因此,由于這個問題, Exp. 5 和Exp. 6僅使用2176個GPU。

表4:實驗中使用的2D-Torus拓撲的網格尺寸。
結果:精度無損失,訓練時間只需224秒
我們在224秒內完成了ResNet-50的訓練,沒有明顯的精度損失,如表5所示。
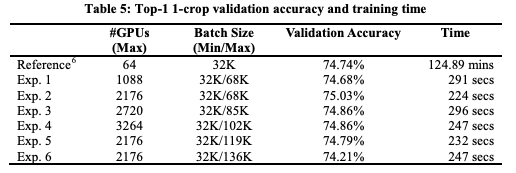
表5:Top-1 1-crop 驗證精度和訓練時間
訓練誤差曲線與參考曲線非常相似(圖3)。雖然最大的batch size可以增加到119K也不會造成明顯的精度損失,但進一步增大會使精度降低約0.5%(表5中的實驗6)。
圖3:訓練誤差曲線
我們描述了與單個節點(4個GPU)相比的訓練速度和GPU縮放效率。
表6顯示了當每個worker的批大小設置為32時的GPU數量和訓練吞吐量。雖然當使用超過2176個GPU時,GPU scaling效率降低到70%,但當使用1088 GPU時,scaling效率超過了90%。
在之前的研究[6]中,當使用1024個Tesla P40,每個worker的批大小設置為32時,GPU scaling效率為87.9%。因此,與之前的研究相比,我們的通信方案通過更快、更多的GPU實現了更高的GPU scaling效率。
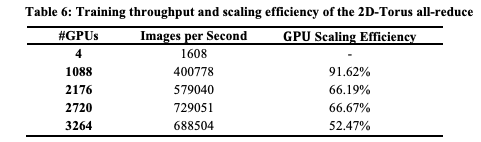
表6:2D-Torus all-reduce的訓練吞吐量和scaling效率
結論
大規模分布式深度學習是減少DNN訓練時間的有效方法。我們采用了多種技術來減少精度下降,同時在使用一個龐大的GPU集群進行訓練的同時保持了較高的GPU scaling效率。
這些技術是用神經網絡庫(NNL)實現的,我們使用了2176個 Tesla V100 GPU,訓練時間224秒,驗證精度75.03%。我們還通過1088個Tesla V100 GPU達到了90%以上的GPU擴展效率。
-
索尼
+關注
關注
18文章
3163瀏覽量
104743 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100537 -
深度學習
+關注
關注
73文章
5492瀏覽量
120976
原文標題:224秒訓練ImageNet!這次創紀錄的是索尼大法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種具有混合精度的高度可擴展的深度學習訓練系統

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
YOLOv6中的用Channel-wise Distillation進行的量化感知訓練
深度學習上演“皇帝的新衣”如何剖析CoordConv?
華為云刷新深度學習加速紀錄
什么是TensorFlow Serving?構建CPU優化服務二進制代碼
富士通實驗室在74.7秒內完成了ImageNet上訓練ResNet-50網絡







 工商網監
工商網監
評論