 機器學習和深度學習的工作步驟模板
機器學習和深度學習的工作步驟模板
1. 定義問題并裝載數據集(Defining the problem and assembling a dataset)
首先,你必須定義你手頭的問題:
輸入數據是什么?你希望預測什么?只有在能夠獲得訓練數據的情況下你才能進行預測:舉個例子,如果你同時又電影的影評和對應的情感注釋,你只能從中學習分類電影影評的情緒。因此,數據可用性是這個階段的限制因素(除非你有辦法雇人幫你收集數據)
你面臨什么類型的問題?它是二元分類嗎?還是多類分類?標量回歸?向量回歸?多類多標簽分類?或者其他的類型,例如聚類,生成問題或者增強學習?識別問題的類型能夠指導你選擇模型的構架,損失函數等等
直到你知道你的輸入和輸出是什么,以及你將使用哪些數據,你才能進入下一個階段。注意你在這個階段所做的假設:
你假設你可以根據給定的輸入預測輸出
你假設你的可用數據有足夠的信息用于學習輸入與輸出之間的關系
當然,這僅僅只是假設,直到你有一個確切的模型,這些假設才能被驗證或者被否定。并非所有問題都能解決。只是因為你僅僅收集了一些輸入X和目標Y,這并不意味著X包含足夠的信息去預測Y。舉個例子,如果你試圖通過股票的歷史價格去預測股票的價格,那么你不可能成果,因為股票的歷史價格不包含太多的預測信息。
非平穩問題是一種不可解決的問題,你應該注意此類問題。假設你正在嘗試建立一個衣服的推薦引擎,你在某一個月的數據上進行訓練(比如說,8月),你希望能夠在冬天的開始的時候推送你的推薦。這里有一個很大的問題:人們購買的衣服類型會根據季節的變化而變化。衣服的購買在幾個月的時間跨度中是一種非平衡現象。在這種情況下,正確的做法是不斷地對過去的數據訓練新的模型,或者在問題處于靜止的時間范圍內收集數據。對于想購買衣服這樣的周期性問題,幾年內的數據足以捕捉到季節的變化,但是記住要讓一年中的時間成為你模型的輸入。
請記住,機器學習只能記住訓練數據中存在的模式。你只能認識你已經看到過的東西。利用機器學習對過去的數據進行訓練,用于預測未來,這樣的做法假設未來的行為將于過去類似。但是,通常并非如此。
2. 選擇成功的衡量指標(Choosing a measure of success)
要控制某些東西,你需要能夠觀察到它。為了取得成功,你必須定義成功是什么,是正確率?精度或者召回率?還是客戶保留率?你的成功指標的定義將會指導你選擇損失函數,損失函數就是你模型將要優化的內容。損失函數應該能夠直接與你的目標保持一致,例如你業務的成功。
對于均衡分類問題,這類問題中每個類別都有相同的可能性,準確率和ROC AUC是常用的指標。對于類不平衡問題,你可以用精度和召回。對于排名問題或者多標簽問題,你可以用平均精度。定義你自己的評價指標并不罕見。要了解機器學習成功指標的多樣性以及它們是如何關系不同的問題域,有必要去了解Kaggle上的數據科學競賽,這些競賽展示了廣泛的問題和評價指標。
3. 決定一個驗證策略(Deciding on an evaluation protocol)
一旦你知道你的目標是什么,你必須確定你將如何衡量你當前的進度。
我們之前已經了解了三種常用的驗證策略:
保留一個hold-out驗證集,當你有足夠多的數據時,用這種方法
K-fold 交叉驗證。數據太少,不足以使用第一種驗證方法的使用,用這種方法。
迭代 K-fold 交叉驗證。只有很少的數據可用時,用于執行高度準確的模型評估。
選擇其中一個。在大多數情況下,第一種方法工作得很好。
4. 準備你的數據(Preparing your data)
一旦你知道你在訓練什么,你正在優化什么,如何評估你的方法,你幾乎已經準備好開始訓練模型。但是首先,你應該將數據格式化為機器學習模型所能接受的形式。這里,我們假設這個模型是一個深度學習模型,那么:
正如前面提到的那樣,你的數據應該格式化為張量
通常情況下,這些張量的值被縮小為較小的值,比如說縮放到[-1,1]或者[0,1]
如果不同的特征采取不同范圍的值,那么數據應該做歸一化處理
你可能想做一些特征工作,特別是對于數據集不大的問題
5. 開發一個比基線好的模型(Developing a model that does better than a baseline)
在這個階段,你的目標是做到statistical power(不會翻譯),也就是開發一個能夠擊敗基線的模型。在MNIST數字分類示例中,任何達到大于0.1精度都可以說是具有statistical power; 在IMDB的例子中,大于0.5就可以了。
請注意,達到statistical power并不總是可能的。如果在嘗試了多個合理的體系構架之后,仍然無法打敗一個隨機基線,那么可能是你要求的問題的答案無法從輸入數據中獲得。記住你提出的兩個假設:
你假設你可以根據給定的輸入預測輸出
你假設你的可用數據有足夠的信息用于學習輸入與輸出之間的關系
這些假設有可能是錯誤的,在這種情況下你必須重新開始。
假設目前為止一切都很順利,你需要作出三個關鍵的選擇來建立你的第一個工作模型:
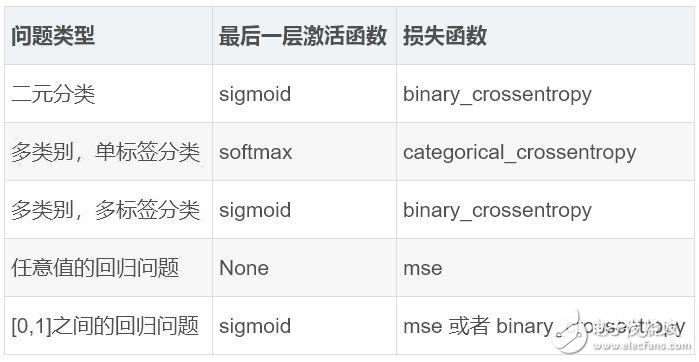
最后一層的激活函數,這為網絡的輸入設定了限制。例如,在IMDB分類問題中,最后一層使用了sigmoid; 在回歸問題中,最后一層沒有使用任何激活函數
損失函數,這應該與你正在嘗試解決的問題的類型相匹配。例如在IMBD二元分類問題中,使用了binary_crossentropy,回歸問題中使用了mse等等。
優化配置,你將使用什么優化器?學習率是多少?在大多數情況在,使用rmsprop和默認的學習率是安全的。
關于損失函數的選擇,請注意,并不總是可以直接優化metric。有時候,沒有簡單的方法可以將metric轉換為損失函數;損失函數畢竟只需要一個小批量的數據就能計算(理想情況下,損失函數只需要一個數據就能計算),并且損失函數必須是可微分的(否則,你不能使用反向傳播來訓練你的網絡)。例如,廣泛使用的分類度量ROC AUC就不能直接優化。因此,在分類問題中,通常針對ROC AUC的代理指標(例如,交叉熵)進行優化,一般來說,你希望如果越低的交叉熵,你就能獲得更高的ROC AUC。
下面的表格可以幫助為幾種常見的問題選擇最后一層激活函數和損失函數
6. 全面升級:開發一個過擬合的模型
一旦你的模型達到了statistical power,那么問題就變成了:你的模型是否足夠強大?你是否有足夠多的網絡層和參數來正確建模你的問題?例如,具有兩個神經元的單層網絡在MNIST具有statistical power,但是不能很好的解決MNIST分類問題。
請記住,機器學習中最困難的就是在優化和泛華之間取得平衡;理想的模型就是站在欠擬合與過擬合之間。要弄清楚這個邊界在哪里,你必須先穿過它。
要弄清楚你需要多大的模型,你必須先開發一個過擬合的模型。這很容易:
- 1. 增加網絡層
- 2. 讓網絡層變大
- 3. 訓練更多次
始終監視著訓練誤差和驗證誤差,以及你所關心的metrics。當你看到模型在驗證集上性能開始下降,就達到了過擬合。下個階段是開始正則化和調整模型,盡可能的接近既不是欠擬合又不是過擬合的理想模型。
7. 正則化你的模型并調整你的超參數(Regularizing your model and tuning your hyperparameters)
這一步將花費大量時間,你將重復修改你的模型,并對其進行訓練,在驗證集上進行評估,再次修改,如此重復,知道模型達到所能達到的最佳效果。以下是你應該嘗試做的一些事情:
添加Dropout
嘗試不同的體系結構的網絡:添加或者刪除網絡層
添加 L1/L2 正則化
嘗試不同的超參數(例如每一層的神經元個數或者優化器學習率),以獲得最佳的參數選擇
(可選)迭代特征工程:添加新特征,或者刪除似乎沒有提供信息的特征
請注意以下幾點:每次使用驗證集來調整模型參數時,都會將有關驗證的信息泄露在模型中。重復幾次是無害的;但是如果重復了很多很多次,那么最終會導致你的模型在驗證集上過擬合(即使沒有直接在驗證集上進行訓練),這使得驗證過程不太可靠。
一旦你開發出令人滿意的模型,你可以根據所有可用的數據(訓練集和驗證集)來訓練你最終的模型。如果測試集的結果明顯低于驗證集上結果,那么可能意味著你的驗證過程不太可靠,或者你的模型在驗證集中已經過擬合了。在這種情況下,你可能需要更為靠譜的驗證策略(例如迭代K-fold驗證)
-
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
發布評論請先 登錄
相關推薦
探討機器學習與深度學習基本概念與運算過程

5分鐘內看懂機器學習和深度學習的區別
機器學習與深度學習之間比較
深度學習與機器學習的區別是什么
機器學習和深度學習有什么區別?







 工商網監
工商網監
評論