 如何通過速度匹配將雷達添加到融合管道中
如何通過速度匹配將雷達添加到融合管道中
自動駕駛中的環境感知傳統上采用傳感器融合的方法,將安裝在汽車上的各種傳感器的目標檢測組合成單一的環境表征。未經校準的傳感器會導致環境模型中的偽像和像差,這使得像自由空間探測這樣的任務更具挑戰性。在本研究中,我們改進了Levinson和Thrun的LiDAR和相機融合方法。我們依靠強度不連續性以及邊緣圖像的侵蝕和膨脹來增強對陰影和視覺模式的魯棒性,這是點云相關工作中反復出現的問題。此外,我們使用無梯度優化器而不是窮舉網格搜索來尋找外部校準。因此,我們的融合管道重量輕,能夠在車載計算機上實時運行。對于檢測任務,我們修改了快速R - CNN架構,以適應混合LiDAR -攝像機數據,從而改進目標檢測和分類。我們在KITTI數據集和本地收集的城市場景上測試我們的算法。
自動駕駛汽車依靠各種傳感器來感知環境。為了建立他們周圍世界的一致模型,并在其中安全地工作,需要融合不同傳感器的數據[1]。每種類型的傳感器都有自己的優點和缺點[ 2 ]。RGB攝像機能夠感知來自周圍世界的顏色和紋理信息,并能很好地完成目標分類任務,然而,它們的探測范圍有限,在有限的光照或惡劣的天氣條件下表現不佳。LiDARs提供精確的距離信息,其范圍可以超過100米,并且能夠探測到小物體。它們在夜間也能很好地工作,但不提供顏色信息,而且在大雨中它們的性能會下降[3][4]。雷達提供精確的距離和速度信息,在惡劣天氣條件下工作良好,但分辨率較低[5]。
如今,高級融合( HLF )是一種非常流行的傳感器融合方法,[ 1 ]。HLF分別用每個傳感器檢測對象,并隨后組合這些檢測。因此,對象檢測是在可用信息有限的地方進行的,因為如果存在多個重疊對象和工件,則HLF會丟棄置信值較低的分類。相反,低級融合(LLF)在原始數據級別結合了來自不同傳感器類型的數據,從而保留了所有信息,并潛在地提高了目標檢測的準確性。
LLF本質上是復雜的,伴隨著幾個挑戰,需要對傳感器進行非常精確的外部校準,以正確融合傳感器對環境的感知。此外,傳感器記錄需要時間同步并補償自我運動。然后,多模態輸入數據可以用于深度神經網絡的目標檢測。融合和檢測算法都必須能夠在公路駕駛場景中實時運行。近年來,LLF以其潛在的優勢引起了人們的關注。例如,Chen等人。[6]發展了一種用于LiDAR和攝像機數據的融合方法,這種方法在Kitti數據集的三維定位和三維檢測方面優于現有的方法[7]。
LevinsonandThrun[8]提出了一種用于LiDAR和攝像機外部標定的算法,但不使用融合的數據進行目標檢測。Geiger等人提出了一種基于三維目標標定的方法。[9]在同一場景中使用多個棋盤,并使用帶有距離傳感器或Microsoft Kinect的三目相機。對于我們的LLF方法,我們改進了LevinsonandThrun[8]的外部LiDAR相機標定方法,我們將沖蝕和膨脹應用于反距離變換的圖像邊緣,發現這些形態平滑了目標函數,提高了對場景中陰影和其他視覺模式的魯棒性。
定性的COM-Parison之間的方法和Kitti提供的外部SiC校準表明,我們的方法產生了一個更好的視覺擬合。此外,我們用無梯度優化算法代替了對變換參數的窮舉網格搜索。我們將LiDAR點云投影到RGB圖像上,對其進行采樣,然后從中提取特征。我們采用了更快的R - CNN架構[10]來處理融合的輸入數據。結果表明,使用融合的LiDAR和攝像機數據改善了Kitti數據集[ 7 ]上的目標檢測結果。我們的傳感器融合算法能夠以10Hz的頻率實時運行。此外,我們展望了激光雷達和雷達之間外部校準的新方法。
其余的工作安排如下。在第Ⅱ節中,我們概述了相關工作。在第III節中,我們推導了我們的算法。首先,我們討論了LiDAR與攝像機的融合;隨后,我們提出了我們對更快的R-CNN架構的修改,以利用融合的數據。在第Ⅳ節中,討論了我們的結果,最后對今后的工作進行了總結和展望。
Ⅱ.相關工作
相機和LiDAR之間外部校準的計算通常依賴于預先定義的標記,如棋盤或AR標簽,校準過程本身大多是離線的。Dhall等人的方法[ 11 ]使用特殊編碼的ArOco標記[ 12 ]來獲得LiDAR和相機之間的3D - 3D點對應關系。Velas等人的校準方法[ 13 ]也依賴于特定的3D標記。在[ 14 ] 中,Schneider等人提出了一種基于深度學習的端到端特征提取、特征匹配和全局回歸的體系結構。他們的方法能夠實時運行,并且可以針對在線錯誤校準誤差進行調整。然而,從頭開始訓練系統需要大量數據。此外,每輛車都需要單獨收集數據,因為傳感器的排列和內部結構可能會有所不同。Castlerena等人的研究[ 15 ]基于使用反射率值的光學相機和LiDAR數據之間的邊緣對齊,使用KITTI外部參數作為地面真實情況,他們實現了接近KITTI精度的無目標方法。Levinson和Thron [ 8 ]的無目標相機LiDAR校準方法適合圖像和點云數據中的邊緣,但使用了詳盡的網格搜索。我們的外部校準方法建立在此基礎上,但是在線工作,不需要對參數進行詳盡的計算搜索。
III.方法
這一部分概述了當前與相機和LiDAR傳感器數據融合相關的研究,包括內部傳感器校準、傳感器之間的外部校準和數據融合,以創建混合數據類型。傳感器融合可分為三類:LLF、中層融合( MLF )和HLF。HLF是汽車原始設備制造商最流行的融合技術,主要是因為它使用了供應商提供的傳感器對象列表,并將它們集成到環境模型[1]中。然而,由于傳感器沒有相互校準,這種方法會導致像差和重復物體。防止這些問題發生的一種方法是融合原始傳感器數據( LLF )。MLF是位于LLF之上的一種抽象,從多個傳感器數據中提取的特征被融合在一起。圖1顯示了我們車上的傳感器設置,圖2給出了整個融合管道的概述。以下各節將更詳細地解釋每個部分。
A.激光雷達和照相機的融合
在本節中,我們描述了LiDAR和相機的外部校準方法、LiDAR點云( PC )在圖像上的投影、其采樣和深度圖中的特征提取。為了確保同時捕獲PC和圖像,我們通過軟件觸發兩個傳感器的記錄,并使用Velodyne HDL - 64E S3作為我們的LiDAR傳感器,它以10Hz的頻率旋轉。為了減少捕獲的PC的失真,我們補償了傳感器記錄期間車輛的自我運動。
圖1.寶馬測試車的傳感器設置由LiDAR (紅色箭頭)、攝像機(藍色箭頭)和雷達(綠色箭頭)組成。
外部傳感器校準依賴于傳感器的精確內部校準。3 * 4相機固有矩陣定義了從相機到圖像坐標系的齊次坐標投影。我們遵循Datta等人的方法[ 16 ]并使用環形圖案校準板(見圖3 ),對參數進行迭代細化。與棋盤式照相機的標準校準方法相比,我們觀察到平均再投影誤差減少了70 %。本征LiDAR校準由制造商提供,該校準定義了從每個發射器到傳感器基座坐標系的轉換。
圖2.我們的傳感器融合和物體檢測管道概述。左圖顯示了傳感器之間的外部校準,并且僅在需要新校準時執行一次。右圖顯示了周期性運行的傳感器融合和目標檢測/定位的管道。
圖3.用于攝像機校準的環形花紋板。按照[16]的內稟攝像機標定方法,與[17]的標準標定方法相比,平均再投影誤差降低了70%。
圖4.LiDAR和照相機外定標的問題說明。計算兩個傳感器之間的外定標是指估計它們的坐標系之間的旋轉R和平移t。我們明確地計算從LiDAR到攝像機的距離,并且能夠推斷出另一個方向。
LiDAR和攝像機之間的外部校準對應于在它們的坐標系之間找到4*4變換矩陣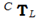 。
。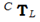 由旋轉和平移組成,因此具有六個自由度( DoFs ) (見圖4 )。為了找到LiDAR和攝像機之間的外部校準,我們通常遵循Levinson和Thron [ 8 ]的方法,但對其進行了一些調整,如下文所述。
由旋轉和平移組成,因此具有六個自由度( DoFs ) (見圖4 )。為了找到LiDAR和攝像機之間的外部校準,我們通常遵循Levinson和Thron [ 8 ]的方法,但對其進行了一些調整,如下文所述。
圖5. 圖5.由于沒有對提取的邊緣圖像應用侵蝕和膨脹而導致的非最佳校準估計。頂部(底部)圖像顯示了提取的邊緣圖像( RGB圖像),基于校準估計,該邊緣圖像沒有被投影的PC覆蓋。RGB圖像中來自右側汽車中心和下方樹木的小陰影會產生邊緣,PC數據中不存在相應的邊緣。因此,優化方法將產生非最優校準估計,這可以在右側的汽車輪胎上看到。ED能夠減少這種小紋理的影響。
基本概念是找到定義的六個參數,使得相機圖像中的邊緣匹配點云測量中的不連續性。出于這個原因,我們定義了一個相似性函數S。我們對投影點云圖像X的深度不連續性與邊緣圖像E進行元素乘法,并在所有像素i上返回該乘積的和。為了平滑目標函數并覆蓋更多場景,我們使用N對點云和圖像,并對它們的匹配分數求和。目標是找到最大化的變換:
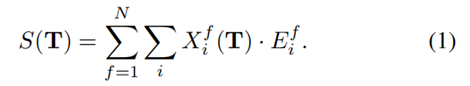
邊緣圖像E如下所示。我們將RGB圖像轉換成灰度,并用Sobel算子計算其邊緣。為了獎勵幾乎匹配的PC和圖像邊緣,我們模糊了圖像邊緣。Levinson和Thron [ 8 ]為此目的使用了逆距離變換( IDT )。另一種可能是應用高斯濾波器。結果表明,IDT與侵蝕擴張(ED)聯合應用效果最好。IDT ED提高了場景中陰影的魯棒性,這在駕駛場景中非常常見。圖5展示了IDT + ED的優勢。在此圖像中,ED尚未應用。圖像右側中央和汽車下方樹木的小陰影會產生圖像邊緣,PC中不存在相應的邊緣。然而,優化方法將試圖匹配這些邊緣,導致更差的校準估計。在這種情況下,缺少ED會產生校準誤差,這可以在車輛右側的輪胎上看到。ED能夠減少圖像中如此小的紋理差異的影響。如同在[ 8 ]中一樣,我們提取PC P中的范圍不連續性,產生不連續性P*的點云,具有
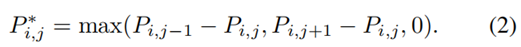
除了在[8]中,PI,j不僅可以表示深度,也可以表示i束Jth測量的強度。我們發現,利用強度值獲得的標定結果更好,因為具有邊緣和不同材料的平面表面不顯示范圍而是強度不連續。然后將新獲得的PC用估計變換到攝像機坐標系,然后用攝像機內稟矩陣投影到圖像平面上,得到投影點云圖像X。
相似函數S是非凸的,不能解析求解。Levinson和Thrun [ 8 ]在六個參數上使用一個計算成本高昂的窮舉網格搜索進行初始校準,然后在線逐步調整。由于我們如上所述對它們的方法進行了修改,我們能夠從參數的初始猜測開始使用無梯度優化方法來找到最優的。我們使用BOBYQA [ 18 ],這是一種迭代算法,用于在優化變量的邊界下找到黑體函數的最小值。BOBYQA依賴于具有信任區域的二次近似。我們能夠從最初幾厘米/度的猜測開始找到最佳參數。因此,我們的方法能夠考慮制造公差。
圖6.用匹配和不匹配的外部LiDAR相機校準比較與PC強度值重疊的圖像。上圖顯示了LiDAR相機外部與未對齊的圖像和PC邊緣不匹配。在底部圖像中,外部匹配良好,邊緣對齊良好。
通過利用正確外部校準周圍的局部凸性,有可能跟蹤外部校準估計的正確性,如[ 8 ]所示。想法是分析當前的校準C是否導致S的局部最大Sc。理想情況下,如果給定的校準C是正確的,那么與C的任何小偏差都會降低相似性分數。我們在所有6個維度上執行以給定校準C為中心的單位半徑網格搜索,得到36= 729個不同的相似度分數S。其中一個將是位于網格中心的Sc本身。FC是其他728個產生的S值低于SC的分數。如果外部校準C正確,這728個值中的大多數應該小于SC,導致FC接近1。圖7顯示了對于給定校準,相似性分數低于SC的校準百分比,從而得出了不同校準估計的一系列幀上的FC圖。我們可以看到,正確的外部校準對應于比不正確校準更大的FC。
圖7.給定校準估計值周圍的校準百分比,其相似性分數低于不同幀上實際估計值的相似性分數。紅色曲線對應于多個幀上正確校準的FC,而所有其他曲線對應于不正確校準。
PC用變換,隨后用投影到RGB圖像上,產生RGB圖像,其中深度是稀疏的。圖6顯示了具有匹配和非匹配外部校準的RGBD圖像的可視化。對于神經網絡在融合數據上的訓練和評估,我們需要標記數據。由于標簽價格昂貴,我們希望利用來自預先培訓的網絡的權重。對于圖像數據來說,這可以很容易地完成,因為大量標記數據是免費提供的。
然而,對于投影的LiDAR數據,情況并非如此。因此,我們的目標是以類似RGB圖像特征的方式對稀疏深度圖進行編碼。這種編碼方案允許我們也使用來自圖像數據的預先訓練的網絡權重,用于網絡中的深度通道。
我們通過首先使用Prebida等人提出的雙邊濾波器對稀疏深度圖進行上采樣來實現這種編碼。[ 19 ]得到了一張密集的深度圖。然后,我們可以從稠密的深度圖中提取類似圖像的特征。Etel等人提出的噴射著色產生了一組這樣的特征[ 20 ]。通過將噴射顏色映射應用于標準化深度值,可以簡單地獲得三通道編碼。此外,我們還提取了HHA(水平視差、離地高度、相對重力的角度)特征[21]。兩組三通道特征顯示出與RGB數據相似的結構。編碼深度數據的尺寸與攝像機數據的尺寸相匹配。RGB與JET / HHA結合產生總共六個數據通道,代表我們的融合數據。
B.融合數據上的目標檢測
LLF和MLF的基本思想是利用來自多感官融合數據的更明顯和更有區別的特征集,這可以提高檢測和分類的準確性。對于LLF,我們使用帶有VGG16 [ 10 ]的標準快速R - CNN管道,并修改其輸入層以容納6通道輸入數據。對于MLF,我們復制了快速R - CNN網絡的前四個卷積層,并為每個攝像機和LiDAR數據處理使用一個單獨的分支。我們將每個分支的第四卷積層之后的特征向量連接起來,并將其輸入到標準快速R - CNN架構的上部。我們使用轉移學習[ 22 ]并將權重從僅RGB網絡初始化到每個子網絡,用于基于MLF的檢測。對于LLF,我們保持卷積濾波器的數量與最初的快速R - CNN網絡相同。對于MLF,由于有兩個分支,前四層中的參數數量增加了一倍。
對“汽車”和“行人”類別進行檢測和分類。在我們的實驗中,我們將三種更快的R - CNN網絡架構用于僅RGB、RGB深度LLF和RGB深度MLF。RGB - only是標準的快速R - CNNN架構,僅使用相機數據作為輸入。我們用融合數據訓練RGB深度線性調頻和RGB深度線性調頻,并同時使用JET和HHA深度編碼。RGB深度LLF的輸入由六通道融合數據組成。RGB深度MLF的輸入包括RGB和到各個網絡分支的深度編碼數據。
Ⅳ.結果
結果部分分為傳感器校準以及LLF和MLF的目標檢測和定位結果。我們的方法已經在Kitti [ 7 ]和當地收集的城市場景數據集上進行了評估。在這里,我們只給出公開的KITTI數據集的結果。
寶馬測試車如圖1所示,用于記錄內部數據集,并在實踐中評估傳感器融合和檢測管道。這輛車包含一臺裝有用于融合的英特爾至強處理器的計算機和一張運行神經網絡的NVIDIA顯卡。本研究中使用的傳感器是Velodyne HDL - 64E S3、Point Gray Research公司的Grashhopper 2 GS2 - GE - 50S 5C - C攝像機和Axis通信P1214 - E網絡攝像機。傳感器融合以10Hz運行,與LiDAR同步。每個融合數據對的目標檢測推斷時間約為250毫秒。優化框架,如NVIDIA的TenSORT [ 23,可能會大大減少推理時間。
圖8.我們的圖像邊緣提取方法的可視化。(上)顯示RGB圖像,(中)顯示應用于圖像邊緣的IDT + DE結果,(下)顯示圖像邊緣與PC的擬合。
A.校準結果
使用IDT + DE進行邊緣提取和后續邊緣模糊環的結果如圖8所示。校準算法成功收斂,對初始猜測中的誤差具有魯棒性。IDT + DE處理成功平滑了邊緣圖像中的梯度,產生了更平滑的相似度函數,優化器可以找到全局最大值。或者,可以為此目的使用高斯平滑,這種平滑精度較低,但速度更快。更多細節在圖5中已有說明。
由于Kitti用于網絡訓練,因此有必要進行正確的外部校準。數據集包括外部校準,該校準是根據來自PC和圖像[ 24的手動選擇的點對應關系計算的。我們使用KITTI校準作為我們的初始猜測,運行我們的外部校準方法。表I顯示了我們計算的擠出物與提供的KITTI擠出物的偏差。一般來說,傳感器之間的外部校準沒有基礎事實。因此,我們無法提供絕對錯誤。然而,目視檢查(見圖9 )顯示,我們的樣品比Kitti提供的樣品更準確。

表一非本征激光雷達相機的絕對差異
KITTI的校準參數和我們的方法
V.結論和今后的工作
在本研究中,我們改進了Levinson和Thron [ 8 ]的現有校準方法,以提高物體的檢測和定位精度。我們通過使用LiDAR、IDT + DE和無梯度優化器的強度不連續性來估計旋轉和平移參數,從而在許多方面進行了改進。融合LiDAR和照相機的高級目標列表的流行方法缺乏適當的外部校準,因此在融合數據中產生像差和振鈴。我們的外部校準方法產生的結果比KITTI數據集的校準更準確,我們的融合實時運行、重量輕。我們對投影點云進行上采樣,并使用不同的深度編碼( HHA / JET )。我們展示了相機LiDAR部分的中低層融合RGB和深度數據的檢測和分類結果。
我們的工作可以通過將雷達集成到融合管道中來擴展。我們目前正在遵循一種基于速度跟蹤的激光雷達和雷達之間的外部校準方法。在LiDAR和雷達數據中,屬于單個對象的測量值被聚類,然后基于估計/測量的速度相互關聯。然后,對應關系產生變換矩陣的估計。這種方法中的幾個步驟,LiDAR數據的跟蹤、聚類和輪廓保持需要自動化和改進。
此外,我們預計使用即將推出的Flash LiDArs會帶來更好的效果。Flash LiDArs將有助于消除補償PC中許多基于自我運動的異常,也有助于傳感器之間更好的時間同步。
REFERENCES
[1] M. Aeberhard and N. Kaempchen,“High-level sensor data fusion architecture for vehicle surround environmentperception,” in Proc. 8th Int. Workshop Intell. Transp, 2011.
[2] J.-r. Xue, D. Wang, S.-y. Du, D.-x. Cui,Y. Huang, and N.-n. Zheng,“A vision-centered multi-sensor fusing approach to self-localization andobstacle perception for robotic cars,” Frontiers of Information Technology& Electronic Engineering, vol. 18, no. 1, pp. 122–138,2017.
[3] J. Lu, H. Sibai, E. Fabry, and D. A.Forsyth, “NO need to worry about adversarial examples in object detection inautonomous vehicles,” CoRR, vol. abs/1707.03501, 2017. [Online]. Available:http://arxiv.org/abs/1707.03501
[4]“Velodyne64,”http://velodynelidar.com/lidar/products/manual/HDL64E\%20S3\%20manual.pdf,[Online; accessed Nov 15, 2017].
[5] “Continental radar user manual,” https://www.continental
automotive.com/getattachment/bffa64c8-8207-4883-9b5c-85316165824a/Radar[1]PLC-Manual-EN.pdf.aspx,[Online; accessed Nov 15, 2017].
[6] X. Chen, H. Ma, J. Wan, B. Li, and T.Xia, “Multi-view 3d object detection network for autonomous driving,” in IEEECVPR, 2017.
[7] A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,” inComputer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE,2012,pp. 3354–3361.
[8] J. Levinson and S. Thrun, “Automaticonline calibration of cameras and lasers.” in Robotics: Science and Systems,2013, pp. 24–28.
[9] A. Geiger, F. Moosmann, . Car, and B.Schuster, “Automatic camera and range sensor calibration using a single shot,”in 2012 IEEE International Conference on Robotics and Automation, May 2012, pp.3936–3943.
[10] S. Ren, K. He, R. Girshick, and J.Sun, “Faster r-cnn: Towards real[1]timeobject detection with region proposal networks,” in Advances in neuralinformation processing systems, 2015, pp. 91–99.
[11] A. Dhall, K. Chelani, V.Radhakrishnan, and K. M. Krishna,“Lidar-camera calibration using 3d-3d point correspondences,” CoRR, vol.abs/1705.09785, 2017. [Online]. Available: http://arxiv.org/abs/ 1705.09785
[12] S. Garrido-Jurado, R. M. noz Salinas,F. Madrid-Cuevas, and M. Mar′?n-Jimenez, “Automatic generation and detection ofhighly ′ reliable fiducial markers under occlusion,” Pattern Recognition, vol.47, no. 6, pp. 2280 – 2292, 2014. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0031320314000235
[13] M. Velas, M. Spanel, Z. Materna, andA. Herout, “Calibration of rgb camera with velodyne lidar,” in Comm. PapersProc. International Conference on Computer Graphics, Visualization and ComputerVision (WSCG), 2014, pp. 135–144.
[14] N. Schneider, F. Piewak, C. Stiller,and U. Franke, “Regnet: Multimodal sensor registration using deep neuralnetworks,” CoRR, vol. abs/1707.03167, 2017. [Online]. Available:http://arxiv.org/abs/ 1707.03167
[15] J. Castorena, U. S. Kamilov, and P. T.Boufounos, “Autocalibration of lidar and optical cameras via edge alignment,”in 2016 IEEE International Conference on Acoustics, Speech and SignalProcessing (ICASSP), March 2016, pp. 2862–2866.
[16] A. Datta, J.-S. Kim, and T. Kanade,“Accurate camera calibration using iterative refinement of control points,” inComputer Vision Workshops (ICCVWorkshops), 2009 IEEE 12th International Conference on. IEEE, 2009, pp.1201–1208.
[17] Z. Zhang, “A flexible new techniquefor camera calibration,” IEEE Transactions on pattern analysis and machineintelligence, vol. 22, no. 11, pp. 1330–1334, 2000.
[18] M. J. Powell, “The bobyqa algorithmfor bound constrained op[1]timizationwithout derivatives,” Cambridge NA Report NA2009/06, University of Cambridge,Cambridge, 2009.
[19] C. Premebida, J. Carreira, J. Batista,and U. Nunes, “Pedestrian detection combining rgb and dense lidar data,” inIntelligent Robots and Systems (IROS 2014), 2014 IEEE/RSJ InternationalConference on. IEEE, 2014, pp. 4112–4117.
[20] A. Eitel, J. T. Springenberg, L.Spinello, M. Riedmiller, and W. Bur[1]gard,“Multimodal deep learning for robust rgb-d object recognition,” in IntelligentRobots and Systems (IROS), 2015 IEEE/RSJ Interna[1]tionalConference on. IEEE, 2015, pp. 681–687.
[21] S. Gupta, R. Girshick, P. Arbelaez,and J. Malik, “Learning rich ′ features from rgb-d images for object detectionand segmentation,” in European Conference on Computer Vision. Springer, 2014,pp. 345–360.
[22] Y. Wei, Y. Zhang, and Q. Yang,“Learning to transfer,” CoRR, vol. abs/1708.05629, 2017. [Online]. Available:http://arxiv.org/abs/1708. 05629
[23] “Nvidia tensorrt,”https://developer.nvidia.com/tensorrt, [Online; ac[1]cessedNov 15, 2017].
[24] A. Geiger, P. Lenz, C. Stiller, and R.Urtasun, “Vision meets robotics: The kitti dataset,” International Journal ofRobotics Research (IJRR), 2013.
[25] M. Everingham, L. Van Gool, C. K. I.Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc)challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp.303–338,Jun 2010. [Online]. Available: https://doi.org/10.1007/s11263-009-0275-4
-
自動駕駛
+關注
關注
783文章
13684瀏覽量
166147 -
LIDAR
+關注
關注
10文章
323瀏覽量
29358
原文標題:自動駕駛中相機和LiDAR數據融合方法與目標檢測
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何將AXI VIP添加到Vivado工程中
Mentor PADS將PCB封裝直接添加到PCB的教程

如何使用vhdl將這種東西添加到TEMAC上?
將新庫添加到Petalinux rootfs的最簡單方法是什么
如何將TDM業務添加到WiMAX平臺上
如何將Crosswalk添加到Cordova應用程序中
Verizon將達拉斯和奧馬哈添加到其5G組合中
如何將WizFi360 EVB Mini添加到樹莓派Pico Python






 工商網監
工商網監
評論