 如何使用顯式核方法改進線性模型
如何使用顯式核方法改進線性模型
本文使用tf.contrib.learn(TensorFlow 的高階機器學習 API)Estimator 構建我們的機器學習模型。如果您不熟悉此 API,不妨通過Estimator 指南著手了解。我們將使用 MNIST 數據集。本文包含以下步驟:
加載和準備 MNIST 數據,以用于分類
構建一個簡單的線性模型,訓練該模型,并用評估數據對其進行評估
將線性模型替換為核化線性模型,重新訓練它,并重新進行評估
加載和準備用于分類的 MNIST 數據
運行以下實用程序命令,以加載 MNIST 數據集:
data = tf.contrib.learn.datasets.mnist.load_mnist()
上述方法會加載整個 MNIST 數據集(包含 7 萬個樣本),然后將數據集拆分為訓練數據(5.5 萬)、驗證數據(5 千)和測試數據(1 萬)。拆分的每個數據集均包含一個圖像 NumPy 數組(形狀為 [sample_size, 784])以及一個標簽 NumPy 數組(形狀為 [sample_size, 1])。在本文中,我們僅分別使用訓練數據和驗證數據訓練和評估模型。
要將數據饋送到tf.contrib.learn Estimator,將數據轉換為張量會很有幫助。為此,我們將使用input function 將操作添加到 TensorFlow 圖,該圖在執行時會創建要在下游使用的小批次張量。有關輸入函數的更多背景知識,請參閱輸入函數這一部分(https://tensorflow.google.cn/guide/premade_estimators?hl=zh-CN#create_input_functions)。在本示例中,我們不僅會將 NumPy 數組轉換為張量,還將使用tf.train.shuffle_batch操作指定 batch_size 以及是否在每次執行 input_fn 操作時都對輸入進行隨機化處理(在訓練期間,隨機化處理通常會加快收斂速度)。以下代碼段是加載和準備數據的完整代碼。在本示例中,我們使用大小為 256 的小批次數據集進行訓練,并使用整個樣本(5 千個條目)進行評估。您可以隨意嘗試不同的批次大小。
import numpy as npimport tensorflow as tfdef get_input_fn(dataset_split, batch_size, capacity=10000, min_after_dequeue=3000): def _input_fn(): images_batch, labels_batch = tf.train.shuffle_batch( tensors=[dataset_split.images, dataset_split.labels.astype(np.int32)], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue, enqueue_many=True, num_threads=4) features_map = {'images': images_batch} return features_map, labels_batch return _input_fndata = tf.contrib.learn.datasets.mnist.load_mnist()train_input_fn = get_input_fn(data.train, batch_size=256)eval_input_fn = get_input_fn(data.validation, batch_size=5000)
訓練一個簡單的線性模型
現在,我們可以使用 MNIST 數據集訓練一個線性模型。我們將使用tf.contrib.learn.LinearClassifierEstimator,并用 10 個類別表示 10 個數字。輸入特征會形成一個 784 維密集向量,指定方式如下:
image_column = tf.contrib.layers.real_valued_column('images', dimension=784)
用于構建、訓練和評估 LinearClassifier Estimator 的完整代碼如下所示:
import time# Specify the feature(s) to be used by the estimator.image_column = tf.contrib.layers.real_valued_column('images', dimension=784)estimator = tf.contrib.learn.LinearClassifier(feature_columns=[image_column], n_classes=10)# Train.start = time.time()estimator.fit(input_fn=train_input_fn, steps=2000)end = time.time()print('Elapsed time: {} seconds'.format(end - start))# Evaluate and report metrics.eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)print(eval_metrics)
下表總結了使用評估數據評估的結果。

注意:指標會因各種因素而異。
除了調整(訓練)批次大小和訓練步數之外,您還可以微調一些其他參數。例如,您可以更改用于最小化損失的優化方法,只需明確從可用優化器集合中選擇其他優化器即可。例如,以下代碼構建的 LinearClassifier Estimator 使用了 Follow-The-Regularized-Leader (FTRL) 優化策略,并采用特定的學習速率和 L2 正則化。
optimizer = tf.train.FtrlOptimizer(learning_rate=5.0, l2_regularization_strength=1.0)estimator = tf.contrib.learn.LinearClassifier( feature_columns=[image_column], n_classes=10, optimizer=optimizer)
無論參數的值如何,線性模型可在此數據集上實現的準確率上限約為93%。
結合使用顯式核映射和線性模型
線性模型在 MNIST 數據集上的錯誤率相對較高(約 7%)表明輸入數據不是可線性分隔的。我們將使用顯式核映射減少分類錯誤。
直覺:大概的原理是,使用非線性映射將輸入空間轉換為其他特征空間(可能是更高維度的空間,其中轉換的特征幾乎是可線性分隔的),然后對映射的特征應用線性模型。如下圖所示:
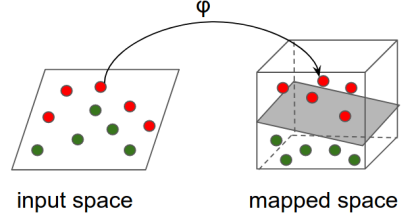
技術詳情
在本示例中,我們將使用 Rahimi 和 Recht 所著的論文 “Random Features for Large-Scale Kernel Machines”(大型核機器的隨機特征)中介紹的隨機傅里葉特征來映射輸入數據。隨機傅里葉特征通過以下映射將向量x∈Rd 映射到x′∈RD
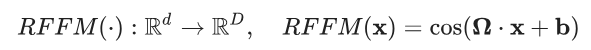
其中,Ω∈RD×d、x∈Rd,b∈RD和余弦值會應用到元素級別。
在本示例中,Ω和b條目是從分布中采樣的,使映射符合以下特性:
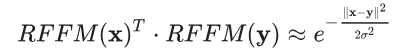
上述表達式右側的量也稱為 RBF(或高斯)核函數。此函數是機器學習中使用最廣泛的核函數之一,可隱式衡量比原始空間維度高得多的其他空間中的相似性。要了解詳情,請參閱徑向基函數核(https://en.wikipedia.org/wiki/Radial_basis_function_kernel)。
核分類器
tf.contrib.kernel_methods.KernelLinearClassifier是預封裝的tf.contrib.learnEstimator,集顯式核映射和線性模型的強大功能于一身。其構造函數與 LinearClassifier Estimator 的構造函數幾乎完全相同,但前者還可以指定要應用到分類器使用的每個特征的一系列顯式核映射。以下代碼段演示了如何將 LinearClassifier 替換為 KernelLinearClassifier。
# Specify the feature(s) to be used by the estimator. This is identical to the# code used for the LinearClassifier.image_column = tf.contrib.layers.real_valued_column('images', dimension=784)optimizer = tf.train.FtrlOptimizer( learning_rate=50.0, l2_regularization_strength=0.001)kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( input_dim=784, output_dim=2000, stddev=5.0, name='rffm')kernel_mappers = {image_column: [kernel_mapper]}estimator = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)# Train.start = time.time()estimator.fit(input_fn=train_input_fn, steps=2000)end = time.time()print('Elapsed time: {} seconds'.format(end - start))# Evaluate and report metrics.eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)print(eval_metrics)
傳遞到KernelLinearClassifier的唯一額外參數是一個字典,表示從 feature_columns 到要應用到相應特征列的核映射列表的映射。以下行指示分類器先使用隨機傅里葉特征將初始的 784 維圖像映射到 2000 維向量,然后在轉換的向量上應用線性模型:
kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( input_dim=784, output_dim=2000, stddev=5.0, name='rffm')kernel_mappers = {image_column: [kernel_mapper]}estimator = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)
請注意stddev參數。它是近似 RBF 核的標準偏差 (σ),可以控制用于分類的相似性指標。stddev通常通過微調超參數確定。
下表總結了運行上述代碼的結果。我們可以通過增加映射的輸出維度以及微調標準偏差,進一步提高準確率。

標準偏差
分類質量與標準偏差的值密切相關。下表顯示了分類器在具有不同標準偏差值的評估數據上達到的準確率。最優值為標準偏差 = 5.0。注意標準偏差值過小或過大會如何顯著降低分類的準確率。
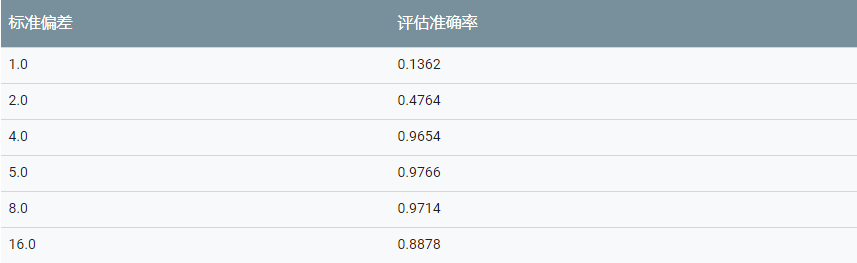
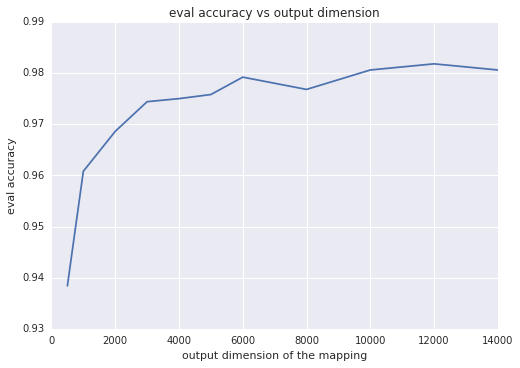
輸出維度
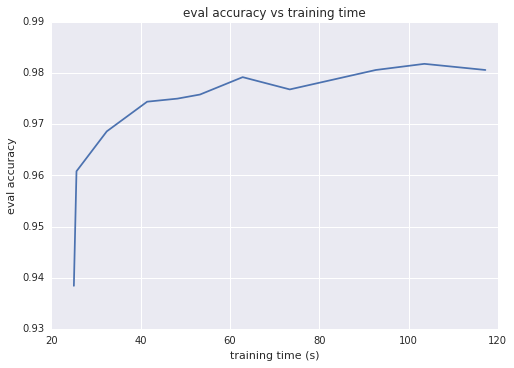
直觀地來講,映射的輸出維度越大,兩個映射向量的內積越逼近核,這通常意味著分類準確率越高。換一種思路就是,輸出維度等于線性模型的權重數;此維度越大,模型的 “自由度” 就越高。不過,超過特定閾值后,輸出維度的增加只能讓準確率獲得極少的提升,但卻會導致訓練時間更長。下面的兩個圖表展示了這一情況,分別顯示了評估準確率與輸出維度和訓練時間之間的函數關系。
總結
顯式核映射結合了非線性模型的預測能力和線性模型的可擴展性。與傳統的雙核方法不同,顯式核方法可以擴展到數百萬或數億個樣本。使用顯式核映射時,請注意以下提示:
隨機傅立葉特征對具有密集特征的數據集尤其有效
核映射的參數通常取決于數據。模型質量與這些參數密切相關。通過微調超參數可找到最優值
如果您有多個數值特征,不妨將它們合并成一個多維特征,然后向合并后的向量應用核映射
-
線性模型
+關注
關注
0文章
9瀏覽量
7801
原文標題:如何使用顯式核方法改進線性模型
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
介紹支持向量機與決策樹集成等模型的應用
八代酷睿核顯的尷尬,核顯遭遇研發瓶頸
一種改進的非線性亮度提升模型的逆光圖像恢復手段


cpu帶核顯和不帶核顯的區別
基于顯式反饋的改進協同過濾算法研究






 工商網監
工商網監
評論