") 半定制化的FPGA芯片和全定制化的ASIC芯片
半定制化的FPGA芯片和全定制化的ASIC芯片
當(dāng)前階段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后隨著視覺、語音、深度學(xué)習(xí)的算法在 FPGA以及 ASIC芯片上的不斷優(yōu)化,此兩者也將逐步占有更多的市場份額,從而與GPU達(dá)成長期共存的局面。從長遠(yuǎn)看,人工智能類腦神經(jīng)芯片是發(fā)展的路徑和方向。本文主要介紹半定制化的FPGA芯片和全定制化的 ASIC芯片。
AI 芯片是人工智能時(shí)代的技術(shù)核心之一,決定了平臺的基礎(chǔ)架構(gòu)和發(fā)展生態(tài)。
芯片發(fā)展歷程
AI 芯片按技術(shù)架構(gòu)分類可分為GPU(Graphics Processing Unit,圖形處理單元)、半定制化的 FPGA、全定制化 ASIC和神經(jīng)擬態(tài)芯片等。
各個(gè)芯片的特點(diǎn)如下:
GPU 通用性強(qiáng)、速度快、效率高,特別適合用在深度學(xué)習(xí)訓(xùn)練方面,但是性能功耗比較低。
FPGA 具有低能耗、高性能以及可編程等特性,相對于 CPU 與 GPU 有明顯的性能或者能耗優(yōu)勢,但對使用者要求高。
ASIC 可以更有針對性地進(jìn)行硬件層次的優(yōu)化,從而獲得更好的性能、功耗比。但是ASIC 芯片的設(shè)計(jì)和制造需要大量的資金、較長的研發(fā)周期和工程周期,而且深度學(xué)習(xí)算法仍在快速發(fā)展,若深度學(xué)習(xí)算法發(fā)生大的變化,F(xiàn)PGA 能很快改變架構(gòu),適應(yīng)最新的變化,ASIC 類芯片一旦定制則難于進(jìn)行修改。
當(dāng)前階段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后隨著視覺、語音、深度學(xué)習(xí)的算法在 FPGA以及 ASIC芯片上的不斷優(yōu)化,此兩者也將逐步占有更多的市場份額,從而與GPU達(dá)成長期共存的局面。從長遠(yuǎn)看,人工智能類腦神經(jīng)芯片是發(fā)展的路徑和方向。
本文主要介紹半定制化的FPGA芯片和全定制化的 ASIC芯片。
半定制化的 FPGA
FPGA 是在 PAL、GAL、CPLD 等可編程器件基礎(chǔ)上進(jìn)一步發(fā)展的產(chǎn)物。用戶可以通過燒入 FPGA 配置文件來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,比如用戶可以把 FPGA 配置成一個(gè)微控制器 MCU,使用完畢后可以編輯配置文件把同一個(gè)FPGA 配置成一個(gè)音頻編解碼器。因此,它既解決了定制電路靈活性的不足,又克服了原有有可編程器件門電路數(shù)有限的缺點(diǎn)。
FPGA 可同時(shí)進(jìn)行數(shù)據(jù)并行和任務(wù)并行計(jì)算,在處理特定應(yīng)用時(shí)有更加明顯的效率提升。對于某個(gè)特定運(yùn)算,通用 CPU 可能需要多個(gè)時(shí)鐘周期;而 FPGA 可以通過編程重組電路,直接生成專用電路,僅消耗少量甚至一次時(shí)鐘周期就可完成運(yùn)算。
此外,由于FPGA的靈活性,很多使用通用處理器或 ASIC難以實(shí)現(xiàn)的底層硬件控制操作技術(shù),利用 FPGA 可以很方便的實(shí)現(xiàn)。這個(gè)特性為算法的功能實(shí)現(xiàn)和優(yōu)化留出了更大空間。同時(shí) FPGA 一次性成本(光刻掩模制作成本)遠(yuǎn)低于 ASIC,在芯片需求還未成規(guī)模、深度學(xué)習(xí)算法暫未穩(wěn)定,需要不斷迭代改進(jìn)的情況下,利用 FPGA 芯片具備可重構(gòu)的特性來實(shí)現(xiàn)半定制的人工智能芯片是最佳選擇之一。
功耗方面,從體系結(jié)構(gòu)而言,F(xiàn)PGA 也具有天生的優(yōu)勢。傳統(tǒng)的馮氏結(jié)構(gòu)中,執(zhí)行單元(如 CPU 核)執(zhí)行任意指令,都需要有指令存儲器、譯碼器、各種指令的運(yùn)算器及分支跳轉(zhuǎn)處理邏輯參與運(yùn)行,而 FPGA 每個(gè)邏輯單元的功能在重編程(即燒入)時(shí)就已經(jīng)確定,不需要指令,無需共享內(nèi)存,從而可以極大的降低單位執(zhí)行的功耗,提高整體的能耗比。
由于 FPGA 具備靈活快速的特點(diǎn),因此在眾多領(lǐng)域都有替代 ASIC 的趨勢。FPGA 在人工智能領(lǐng)域的應(yīng)用如圖所示。
FPGA在人工智能領(lǐng)域的應(yīng)用
全定制化的 ASIC
目前以深度學(xué)習(xí)為代表的人工智能計(jì)算需求,主要采用 GPU、FPGA 等已有的適合并行計(jì)算的通用芯片來實(shí)現(xiàn)加速。在產(chǎn)業(yè)應(yīng)用沒有大規(guī)模興起之時(shí),使用這類已有的通用芯片可以避免專門研發(fā)定制芯片(ASIC)的高投入和高風(fēng)險(xiǎn)。但是,由于這類通用芯片設(shè)計(jì)初衷并非專門針對深度學(xué)習(xí),因而天然存在性能、功耗等方面的局限性。隨著人工智能應(yīng)用規(guī)模的擴(kuò)大,這類問題日益突顯。
GPU 作為圖像處理器,設(shè)計(jì)初衷是為了應(yīng)對圖像處理中的大規(guī)模并行計(jì)算。因此,在應(yīng)用于深度學(xué)習(xí)算法時(shí),有三個(gè)方面的局限性:
第一,應(yīng)用過程中無法充分發(fā)揮并行計(jì)算優(yōu)勢。深度學(xué)習(xí)包含訓(xùn)練和推斷兩個(gè)計(jì)算環(huán)節(jié),GPU 在深度學(xué)習(xí)算法訓(xùn)練上非常高效,但對于單一輸入進(jìn)行推斷的場合,并行度的優(yōu)勢不能完全發(fā)揮;
第二,無法靈活配置硬件結(jié)構(gòu)。GPU 采用 SIMT 計(jì)算模式,硬件結(jié)構(gòu)相對固定。目前深度學(xué)習(xí)算法還未完全穩(wěn)定,若深度學(xué)習(xí)算法發(fā)生大的變化,GPU 無法像 FPGA 一樣可以靈活的配制硬件結(jié)構(gòu);
第三,運(yùn)行深度學(xué)習(xí)算法能效低于 FPGA。
盡管 FPGA 倍受看好,甚至新一代百度大腦也是基于 FPGA 平臺研發(fā),但其畢竟不是專門為了適用深度學(xué)習(xí)算法而研發(fā),實(shí)際應(yīng)用中也存在諸多局限:第一,基本單元的計(jì)算能力有限。為了實(shí)現(xiàn)可重構(gòu)特性,F(xiàn)PGA 內(nèi)部有大量極細(xì)粒度的基本單元,但是每個(gè)單元的計(jì)算能力(主要依靠 LUT 查找表)都遠(yuǎn)遠(yuǎn)低于 CPU 和 GPU 中的 ALU 模塊;第二,計(jì)算資源占比相對較低。為實(shí)現(xiàn)可重構(gòu)特性,F(xiàn)PGA 內(nèi)部大量資源被用于可配置的片上路由與連線;第三,速度和功耗相對專用定制芯片(ASIC)仍然存在不小差距;第四,F(xiàn)PGA 價(jià)格較為昂貴,在規(guī)模放量的情況下單塊 FPGA 的成本要遠(yuǎn)高于專用定制芯片。
因此,隨著人工智能算法和應(yīng)用技術(shù)的日益發(fā)展,以及人工智能專用芯片ASIC產(chǎn)業(yè)環(huán)境的逐漸成熟,全定制化人工智能ASIC也逐步體現(xiàn)出自身的優(yōu)勢,從事此類芯片研發(fā)與應(yīng)用的國內(nèi)外比較有代表性的公司如表 1 所示。
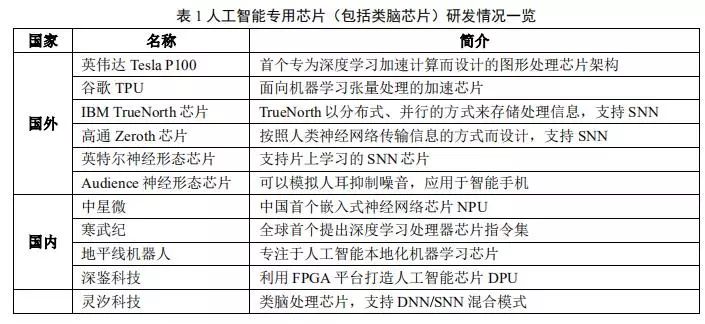
ASIC 芯片非常適合人工智能的應(yīng)用場景。
首先,ASIC的性能提升非常明顯。例如英偉達(dá)首款專門為深度學(xué)習(xí)從零開始設(shè)計(jì)的芯片 Tesla P100 數(shù)據(jù)處理速度是其 2014 年推出GPU 系列的 12 倍。谷歌為機(jī)器學(xué)習(xí)定制的芯片 TPU 將硬件性能提升至相當(dāng)于當(dāng)前芯片按摩爾定律發(fā)展 7 年后的水平。正如 CPU 改變了當(dāng)年龐大的計(jì)算機(jī)一樣,人工智能 ASIC 芯片也將大幅改變?nèi)缃?AI 硬件設(shè)備的面貌。如大名鼎鼎的 AlphaGo 使用了約 170 個(gè)圖形處理器(GPU)和 1200 個(gè)中央處理器(CPU),這些設(shè)備需要占用一個(gè)機(jī)房,還要配備大功率的空調(diào),以及多名專家進(jìn)行系統(tǒng)維護(hù)。而如果全部使用專用芯片,極大可能只需要一個(gè)普通收納盒大小的空間,,且功耗也會(huì)大幅降低。
第二,下游需求促進(jìn)人工智能芯片專用化。從服務(wù)器,計(jì)算機(jī)到無人駕駛汽車、無人機(jī)再到智能家居的各類家電,至少數(shù)十倍于智能手機(jī)體量的設(shè)備需要引入感知交互能力和人工智能計(jì)算能力。而出于對實(shí)時(shí)性的要求以及訓(xùn)練數(shù)據(jù)隱私等考慮,這些應(yīng)用不可能完全依賴云端,必須要有本地的軟硬件基礎(chǔ)平臺支撐,這將帶來海量的人工智能芯片需要。
目前人工智能專用芯片的發(fā)展方向包括:主要基于 FPGA 的半定制、針對深度學(xué)習(xí)算法的全定制和類腦計(jì)算芯片 3 個(gè)方向。
在芯片需求還未形成規(guī)模、深度學(xué)習(xí)算法暫未穩(wěn)定,AI 芯片本身需要不斷迭代改進(jìn)的情況下,利用具備可重構(gòu)特性的 FPGA 芯片來實(shí)現(xiàn)半定制的人工智能芯片是最佳選擇之一。這類芯片中的杰出代表是國內(nèi)初創(chuàng)公司深鑒科技,該公司設(shè)計(jì)了“深度學(xué)習(xí)處理單元”(Deep Processing Unit,DPU)的芯片,希望以 ASIC 級別的功耗達(dá)到優(yōu)于 GPU 的性能,其第一批產(chǎn)品就是基于 FPGA 平臺開發(fā)研制出來的。這種半定制芯片雖然依托于 FPGA 平臺,但是抽象出了指令集與編譯器,可以快速開發(fā)、快速迭代,與專用的 FPGA 加速器產(chǎn)品相比,也具有非常明顯的優(yōu)勢。
深度學(xué)習(xí)算法穩(wěn)定后,AI 芯片可采用 ASIC 設(shè)計(jì)方法進(jìn)行全定制,使性能、功耗和面積等指標(biāo)面向深度學(xué)習(xí)算法做到最優(yōu)。
-
芯片
+關(guān)注
關(guān)注
454文章
50460瀏覽量
421979 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
783文章
13694瀏覽量
166168 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120999
原文標(biāo)題:自動(dòng)駕駛芯片之——FPGA和ASIC介紹
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
cogoask講解fpga和ASIC是什么意思
FPGA和ASIC芯片解密有哪些性能分析
定制型加密芯片這是一款采用隨機(jī)變量交換系統(tǒng)的認(rèn)證加密芯片,請問定制化加密芯片優(yōu)勢在哪里?
定制化加密芯片優(yōu)勢和產(chǎn)品特點(diǎn)
對于CV181系列芯片的SDK定制化疑問求解
全定制和半定制簡易IC設(shè)計(jì)流程介紹
聯(lián)發(fā)科成功拿下HomePodWiFi定制化芯片(ASIC)訂單
什么是ASIC芯片?與CPU、GPU、FPGA相比如何?
車載芯片的發(fā)展趨勢(CPU-GPU-FPGA-ASIC)
淺析GPU、FPGA、ASIC三種主流AI芯片的區(qū)別
中國FPGA芯片行業(yè)綜述

元宇宙浪潮下,AR芯片將走向定制化
自動(dòng)駕駛主流芯片:GPU、FPGA、ASIC
半定制快速芯片ASIC可實(shí)現(xiàn)高達(dá)9GHz的射頻功能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論