 企業如何實現對工業大數據的預處理?
企業如何實現對工業大數據的預處理?
數據分析,包括大數據分析,在企業的業務中,特別是在傳統的商務行業,已有多年的應用實踐,在消費者市場的營銷中已成了必不可缺的技術。隨著工業互聯網和智能制造的興起和發展,工業大數據技術也越來越受到各方關注。在“中國制造2025”的技術路線圖中,工業大數據是作為重要突破點來規劃的,而在未來的十年,以數據為核心構建的智能化體系會成為支撐智能制造和工業互聯網的核心動力。
對制造企業而言,不論是新實施的系統還是老舊系統,要實施大數據分析平臺,就需要先弄明白自己到底需要采集哪些數據。因為考慮到數據的采集難度和成本,大數據分析平臺并不是對企業所有的數據都進行采集,而是相關的、有直接或者間接聯系的數據,企業要知道哪些數據是對于戰略性的決策或者一些細節決策有幫助的,分析出來的數據結果是有價值的。
比如企業只是想了解產線設備的運行狀態,這時候就只需要對影響產線設備性能的關鍵參數進行采集。
再比如,在產品售后服務環節,企業需要了解產品使用狀態、購買群體等信息,這些數據對支撐新產品的研發和市場的預測都有著非常重要的價值。
因此,建議企業在進行大數據分析規劃的時候針對一個項目的目標進行精確的分析,比較容易滿足業務的目標。明確目標以后,就要著手開始搜集數據并進行預處理了。本期格物匯將跟大家介紹,企業如何實現對工業大數據的預處理。
數據采集
首先我們看看數據是如何獲取的,在現實生活中,我們所面對的問題,往往都是抽象復雜的。我們來看如下兩個例子:
如何提升產品的良率
可能這是制造業最為普遍的一個問題,如果我們要分析解決這個問題,常常就會問到:什么產品?有多少條產線在生成?經過了哪些機臺?影響產品良率的因素有哪些?我們可能會提出很多很多這樣的問題,解決這些問題需要對相關業務知識非常了解,盡可能多的找出與問題有關的數據。
如何進行人臉識別
這問題更加復雜一些,雖然我們每個人的大腦每天都在做人臉識別,但是大腦如何工作的卻異常難懂。我們可能需要做很多科研工作,去挖掘到底哪些數據會影響到人臉識別的正確率。如果這些數據本身沒有,很可能還需要進行測量采集,比如兩眼之間的距離,嘴的寬度和長度等等。當然,我們還會評估采集的成本,并對這些數據有效性進行評估,驗證我們的成本是否值得去花費精力測量。
數據預處理簡介
數據采集以后,數據往往存放在數據庫或文件系統中,我們需要把他們導入到算法模型中進行訓練,得到我們想要的模型。但是我們的數據往往雜亂無章,總的來說,數據一般存在如下幾類問題:
數據類型多種多樣
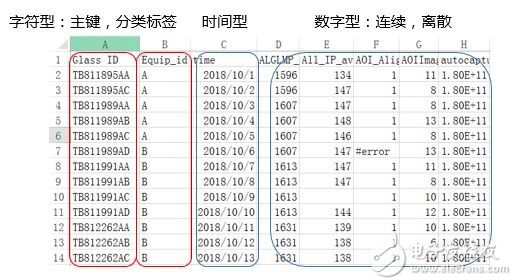
我們的數據中常常出現字符型,時間型,數字型等多種數據類型。其中:字符型是無法代入模型計算的,所以我們根據需要,可以對字符型數據進行編碼轉換。常用的編碼方法有:
數字編碼:對于有大小比較的字符型數據,可以直接轉換成數字編碼。比如:
Onehot編碼:對于沒有大小比較的字符型數據,可以使用Onehot獨熱編碼。比如:
時間類型往往是一類特殊的數據,把時間簡單看成一個實數的話,往往不符合邏輯。對于帶時間的數據,我們通常使用時間序列的分析方法進行分析。有時候我們更加關注的是兩列時間的差值,這時我們可以構建時間差值列作為新的變量加入模型之中。
數字型往往是導入模型進行訓練的主要部分,數字型又可以細分為離散型和連續型,因為離散與連續的數據分布顯著不同,我們可以對其進行分開處理。數字型之間各個列常存在量綱差異,有的數據可能很大,有的數據可能很小,我們需要去除數據量綱,防止模型對數據較大的列進行偏倚(數據值較大時通常方差也較大)。常用的數據去量綱的方法有最大最小值歸一化法,均值標準差標準化法等等。
數據格式不對
我們期望數據格式是表結構,矩陣格式,或者是張量格式。然而我們拿到的數據往往不是格式化的數據,比如機臺的日志數據,圖像數據,音頻視頻數據。我們需要對上述數據轉換,把數據格式轉換成我們想要的格式。
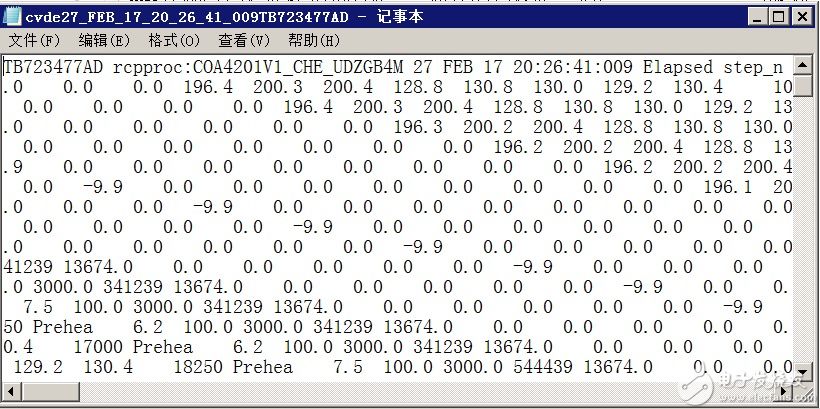
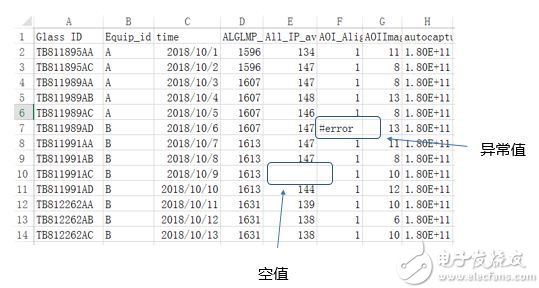
數據中存在異常
數據中還會出現缺失值,異常值等異常,這些情況也會強烈影響到模型的訓練,我們需要對空值進行補值。如何補值需要我們對數據非常了解,才能推斷出該用什么值來補值,才不會改變原有的數據分布。一般的補值方法有:0值補值,均值補值,中位數補值,按上一個數補值,移動平均補值,線性插值,相關列補值法等等,對于缺失值比例較大的列,可以采取直接刪除的方法。異常值則需要創建規則,對異常值進行識別,再用正常的值進行替換,故異常值也有類似于缺失值的替換方法。
本文作者:格創東智OT團隊
-
大數據
+關注
關注
64文章
8863瀏覽量
137295 -
智能制造
+關注
關注
48文章
5481瀏覽量
76261 -
工業互聯網
+關注
關注
28文章
4299瀏覽量
94050
發布評論請先 登錄
相關推薦
小鵬汽車榮獲2024年機械工業大型重點骨干企業
機器學習中的數據預處理與特征工程
工業大數據云平臺在設備預測性維護中的作用
特征工程與數據預處理全解析:基礎技術和代碼示例

信號的預處理包括哪些環節
工業路由器如何助力企業實現數字化轉型?
大數據技術是干嘛的 大數據核心技術有哪些
GPU:大數據時代的強力引擎
基于工業大數據和物聯網的智能工廠如何實現
誠邀報名|黃向東邀您共話開源工業物聯網大數據

C語言有哪些預處理操作?

誠邀報名|黃向東邀您共話開源工業物聯網大數據






 工商網監
工商網監
評論