 如何提升RT1050的代碼運行速度,使其發揮最大性能
如何提升RT1050的代碼運行速度,使其發揮最大性能
本文以RT1050為例,講解如何提升RT1050的代碼運行速度,使其發揮最大性能,并列出在提升性能過程中可能會遇到的問題以及解決辦法。
1.是誰影響了代碼運行速度?
在一般的MCU開發中,我們習慣性的將代碼直接下載到MCU的內部Flash中,并直接在內部Flash中運行,在I-CODE、D-CODE總線以及自帶的Flash加速器加持下,這么做似乎也沒什么問題。但作為一款高性能并擁有最高600M主頻的跨界MCU,RT1050并沒有內置Flash。那么在實際開發中,就必須外置一塊 NOR Flash用于代碼的存儲。
如果此時我們還像之前開發一般MCU那樣,讓代碼在Flash運行,就會受限于Flash的讀寫速度,以及MCU與Flash之間的通信速度。那感覺,就像開著V12引擎的布加迪,跑在限速40的公路上,完全發揮不出來600M主頻的性能,更別談讓代碼的運行速度飛起來了。
2. 如何讓代碼運行速度飛起來!
代碼必須存儲在Flash中實現掉電不丟失,而與此同時,我們又要求發揮600M主頻的最大性能,讓代碼的運行速度飛起來,可能你還沒想好怎么做,那就跟著小編一起,由淺到深,用實際可行的方案,一步步提升代碼運行速度,并解決在提升代碼速度時遇到的阻礙,最后讓代碼的運行速度飛起來。
2.1運行域和加載域的概念
既然在Flash中運行代碼效率不高,那我們首先想到的辦法,就是不讓代碼在Flash中運行,那就不得不提到運行域和加載域的概念。
代碼在通過編譯器鏈接器的處理后生成了固件文件,此時有兩個相關概念需要留意,就是加載域和運行域。
加載域的意思是代碼要下載到哪里。這里肯定要選擇下載到Flash中。運行域的意思是代碼在哪里運行。例如我們可以指定代碼在RAM中運行,那么在__main中,就會將相關代碼都拷貝到RAM中,在程序運行時,就會去RAM空間取指、譯碼、執行。加載域和運行域的定義可以在分散加載文件中完成。
聽起來是個不錯的想法,但是在實施的過程中,就會遇到一個問題,我們所說的代碼,也就是固件的CODE部分,也包含了中斷復位函數。我們知道,程序在上電時,硬件會去相對地址0x00處取棧指針,而后偏移一個字,取復位中斷函數地址,并在復位中斷函數中執行系統初始化函數SystemInit和__mian函數,并在__mian函數中實現不同運行域的代碼拷貝。按照這種硬件機制,有一些代碼是要在代碼拷貝之前運行的。
因此我們并不能將所有代碼的運行域都拷貝到RAM中運行。這也是為什么分散加載文件規定,加載域中的第一個運行域,其起始地址必須和該加載域起始地址相同。
一種可行的辦法是將不能更改運行域的代碼提出來,放在加載域的第一個運行域,用于上電啟動過程,然后將其他代碼段的運行域放在RAM中,這樣一來,在上電啟動過程完成,進入到mian函數后,代碼都是在RAM中運行的,其速度會有飛一樣的提升。分散加載文件中相關示例配置和注釋如圖1所示。
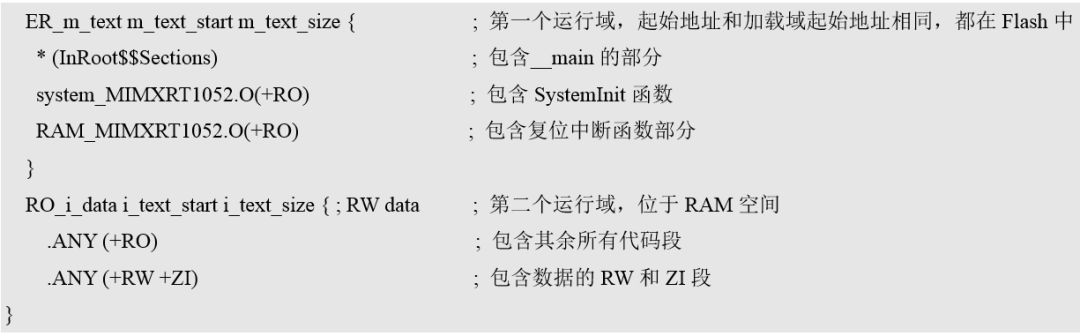
圖1 運行域分配
2.2RAM空間的優化
以為上述的配置完成之后就可以起飛了嗎?不,還差一點。如果再對RT1050的存儲結構多點了解,就會發現其內部的RAM空間被分成了三個部分。包括ITCM、DTCM和OCRAM。這三個部分共享512K的RAM空間。在默認配置下,ITCM和DTCM各占128K、OCRAM占256K。
根據RT1050的內部總線結構,將代碼段放在ITCM、數據段放在DTCM中,可以帶來更高的性能和更快的代碼速度。其分散加載的示例配置如圖2所示。
圖2 DTCM空間和ITCM空間分配
講道理,經過這樣的處理之后,我們已經將代碼和數據的運行域放在了整個RT1050運行最快的位置,其600M主頻的性能也能最大力度的發揮出來。但是這樣做是不是就大功告成了呢?可能還不是,在實際的項目開發中,還會遇到一些其他的問題。
2.3其他的一些問題
2.3.1 代碼和數據容量的問題
如果不考慮整個工程的代碼大小,之前所做的一切都是很OK的,但是往往會遇到一種情況,就是代碼量或者數據量太大,已經超出了范圍。
如果只是超過了RAM默認的配置范圍,那可以將RAM的空間重新分配,以32K為單位,可以按照實際需要調整ITCM和DTCM的空間大小,不過有兩點需要注意,一是OCRAM至少要保留32K的空間大小、二是一定要在__main之前調整好RAM的分區,否則在__mian函數中拷貝函數拷貝代碼時就會因為空間不足而產生硬件錯誤。
一種可行的辦法是在復位中斷函數的起始位置通過匯編指令去調整RAM的分區,示例代碼如圖3所示。主要是修改三個寄存器中內容,詳細信息可查閱參考手冊中相關的部分。
圖3 通過匯編指令調整RAM分區
如果代碼或者數據的容量已經超出了RAM區域能調整的范圍,那就不能將代碼和數據的運行域都放在RAM中了。例如使用libpng解碼庫解碼png圖片,可能需要1M以上的堆空間。在這種情況下,可以使用一塊大容量的SDRAM作為輔助,雖然代碼運行的速度沒有在RAM中高,但是解決了RAM空間本身不是很充足的問題,且在SDRAM中運行代碼肯定會比在Flash中運行代碼要快上很多。
有了SDRAM的加持,就可以選擇性的將需要高速運行的代碼或者關鍵數據放在RAM的空間。一些不需要高速運行的代碼或者數據放在SDRAM的空間。如果需要使用的堆太大,也可以將堆的空間放在SDRAM中。
通過這種策略靈活的調整之后,在最佳性能和代碼量之間能找到一個平衡點,以更好的應用于一些大型的工程,例如帶了操作系統、lwip協議棧、emWin等。
2.3.2 中斷響應的問題
在前面的操作中,我們一直沒有留意中斷這個對嵌入式系統十分重要的部分。由前面的操作可知,我們將中斷向量表加載到了Flash中用于上電啟動,而后就一直沒有管它,只是專注于代碼的運行域。但是如果中斷向量表還在Flash中,那么當產生中斷的時候,硬件還是會到Flash中的中斷向量表位置去查找相應的中斷服務函數,這樣一去一回,無疑就拖慢了中斷的響應速度,要知道,在零等待的情況下,RT1050的中斷響應時間可是能達到20ns的。
可以將中斷向量表也拷貝到RAM中,然后重新對中斷向量表的地址進行映射。一種可行的方式是修改啟動文件。在啟動文件中再命名一個中斷向量表,該中斷向量表中添加原中斷向量表中除復位中斷函數之外的其他部分,而原中斷向量表中只保留復位中斷函數和棧指針。將新做的中斷向量表的運行域放在RAM的起始位置。這樣在程序上電的時候。__main會將該中斷向量表拷貝到RAM的起始地址,而后在main函數的開頭,對中斷向量表進行重映射。不過需要注意的是,這種操作有一個弊端,就是需要保證在復位到執行中斷向量表重映射期間,不能產生除了復位中斷之外的其他中斷,否則會造成硬件異常。
3. 代碼運行速度已經起飛
經過上面的處理之后,怎么能不感受一下實際的起飛效果,可做一個LED燈翻轉的小例程用于測試,在例程中用軟件延時的方式翻轉小燈。先在Flash中運行,讓軟件延時達到200ms左右的延時效果。能正常顯示之后,不改變代碼內容,只是將代碼運行域放在RAM中,再次運行代碼,就能看到,此時小燈翻轉的頻率,已經達到了起飛的效果。
-
mcu
+關注
關注
146文章
17019瀏覽量
350375 -
代碼
+關注
關注
30文章
4753瀏覽量
68369 -
編譯器
+關注
關注
1文章
1618瀏覽量
49057
原文標題:如何讓RT1050的代碼運行速度飛起來
文章出處:【微信號:Zlgmcu7890,微信公眾號:周立功單片機】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大聯大品佳 NXP i.MX RT1050試用申請】基于 NXP i.MX RT1050工業機器人開發
【大聯大品佳 NXP i.MX RT1050試用申請】i.MX RT1050 3D打印機控制器
【大聯大品佳 NXP i.MX RT1050試用申請】使用NXP i.MX RT1050開發板設計一款低成本CAN數據采集儀
i.MX RT1050平臺的相關資料推薦
如何使用J-link在沒有EVB的情況下調試RT1050?
有人在RT1050或RT1060上用過PN7160嗎?
請問如何測量RT1050的USB性能?
i.MX RT系列(例如 RT1050/1060)有多少個PWM通道?
【044】SylixOS 正式支持 i.MX RT1050平臺

基于 NXP i.MX RT1050 的 3D 打印機方案





 工商網監
工商網監
評論